自分用メモ
Section1 勾配消失問題
誤差+=逆伝播法が下位置に進んでいくにつれて、勾配がどんどん緩やかになっていく。
そのため、勾配降下法による更新では下位置のパラメータはほとんど変わらず、訓練は最適値に収束しなくなる。
シグモイド関数は勾配消失問題を起こす代表的な関数

活性化関数を微分したとき

最大でも0.25となり、入力層側の値がどんどん小さくなってしまう。
- 確認テスト
Q:シグモイド関数を微分したとき、入力値が0の時に最大値をとる。その値として正しいものを選べ。
A:0.25
勾配消失の解決法
- 活性化関数の選択
解決してくれる関数にRelu関数がある。
f(x) = \left\{
\begin{array}{ll}
x & (x > 0) \\
0 & (x \leqq
0)
\end{array}
\right.
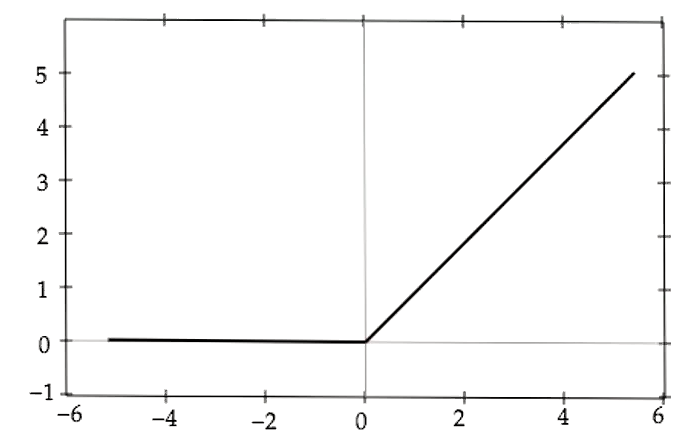
xが1の場合、重みは積極的に使われる。
xが0以下の場合、微分値が0の場合は必要な部分の重みしか残らず、モデルの効果的な動きを自力で見つけられるようになる。
- 重みの初期値設定
逆伝播の値が0に近いと重みの更新量が小さくなり、重みが停滞してしまい、学習が進まなくなってしまうことを指す。
この原因の一つが重みの初期値によるものである。
そのため、適切な初期値の設定が求められる。
Xaiver(ザビエル)の初期値
→重みの要素を、前の層のノード数の平方根で除算した値
使える活性化関数シグモイド関数
Xavierの初期化を行うと、各レイヤーを通ったあとの値はどれもある程度のバラツキを持ちつつ、0や1に値が偏ることもない。活性化関数の表現力を保ったまま、勾配消失への対策が取れている。

Heの初期値
→正規分布の重みを√2/√nで割る
使える活性化関数Relu
ある程度の表現力を保った状態となる。

- 確認テスト
Q:重みの初期値に0を設定すると、どのような問題が発生するか。
A:重みを0に初期化すると正しい学習が行えない。
→すべての重みの値が均一に更新されるため、多数の重みを持つ意味がなくなる。
- バッチ正規化
ミニバッチ単位で入力値のデータの偏りを抑制する手法。
バッチ正規化の使い所とは?
活性化関数に値を渡す前後に、バッチ正規化の処理を孕んだ層を加える。
学習の安定化。過学習を抑えることができる。
- 数学的記述
ミニバッチの平均
\mu_t=\frac{1}{N_t}\sum_{i=1}^{N_t}x_{ni}
ミニバッチの分散
\sigma_t^{2}=\frac{1}{N_t}\sum_{i=1}^{N_t}(x_{ni}-\mu_t)^2
ミニバッチの正規化
\hat {x}_{ni}= \frac{x_{ni}-\mu_t}{\sqrt{{\sigma_t}^2+\theta}}
変倍・移動
y_{ni}=\gamma x_{ni}+\beta

- 例題チャレンジ
Q:
def train(data_x, data_t, n_epoch, batch_size):
"""
data_x: training data (features)
data_t: training data (labels)
n_epoch: number of epochs
batch_size: mini batch size
"""
N = len(data_x)
for epoch in range(n_epoch):
shuffle_indx = np.random.permutation(N)
for i in range(0, N, batch_size):
i_end = i + batch_size
batch_x, batch_t = (き) あ
_update(batch_x, batch_t)
(き)に入るプログラムは?
A: data_x[i:i_end],data[i:i_end]
Section2 学習率最適化問題
勾配降下法を利用してパラメータを最適化
w^{(t+1)} = w^{(t)} - \epsilon\nabla{E} \\
\nabla E= \frac{\partial E}{\partial w}= \biggl[\frac{\partial E}{\partial w_1} ... \frac{\partial E}{\partial w_M}\biggr]
モメンタム
V_t =\mu V_{t-1} -\epsilon \nabla E \\
w^{(t+1)} = w^{(t)} +V_t \\
慣性:\mu
誤差をパラメータで微分したものと学習率の積を減算した後w,現在の重みに前回の重みを減算した値と慣性の積を加算する。
- メリット
局所的最適解にはならず、大域的最適解となる。
谷間についてから最も低い位置(最適解)にいくまでの時間が早い。
AdaGrad
h_0= \theta\\
h_t=h_{t-1}+(\nabla E)^2\\
w^{(t+1)}=w^{(t)}-\epsilon\frac{1}{\sqrt{h_t}+\theta}\nabla E
誤差をパラメータで微分したものと再定義した学習率の積を減算する。
- メリット
勾配の緩やかな斜面に対して、最適値に近づける
課題
学習率が徐々に小さくなるので、鞍点問題を引き起こすことがあった。
RMSProp
h_t=\alpha h_{t-1}+(1-\alpha)(\nabla E)^2 \\
w^{(t+1)}=w^{(t)}-\epsilon\frac{1}{\sqrt{h_t}+\theta}\nabla E
誤差をパラメータで微分したものと再定義した学習率の積を減算する
- メリット
局所的最適解にはならず、大域的最適解となる。
ハイパーパラメータの調整が必要な場合が少ない。
Adam
- モメンタムの過去の勾配の指数関数的減衰平均
- RMSPropの過去の勾配の2乗の指数関数的減衰平均
上記をそれぞれ孕んだ最適化アルゴリズムである。
- メリット
モメンタムおよびRMSPropのメリットを孕んだアルゴリズムである。
Section3 過学習
テスト誤差と訓練誤差とで学習曲線が乖離すること。
- 原因
パラメータの数が多い
パラメータの値が適切でない
ノードが多い
→ネットワークの自由度(層数、ノード数、パラメータの値etc...)が高い。
正則化
ネットワークの自由度(層数、ノード数、パラメータの値etc...)を制約すること
- Weight decay(荷重減衰)
過学習の原因
重みが大きい値を取ることで、過学習が発生することがある。
→学習させていくと、重みにばらつきが発生する。
解決策
誤差に対して、正則化項を加算することで、重みを抑制
→過学習がおこりそうな重みの大きさ以下で重みをコントロールし、かつ重みの大きさにばらつきを出す必要がある。
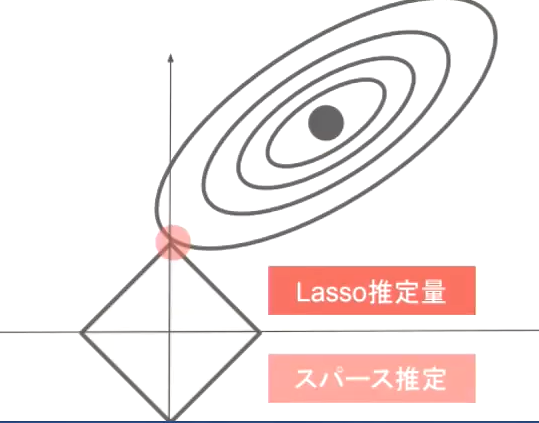
L1,L2正則化
E_n(w)=\frac{1}{p}\lambda ||x||_p :誤差関数にpノルムを加える\\
||x||_p=(|x_1|^p+...+|x_p|^p)^{\frac{1}{p}} :pノルムの計算
p=1の場合、L1正則化
p=2の場合、L2正則化と呼ぶ。
誤差関数に正則化項を加えることにより、重みの最小化する場所を操作できる。
- 確認テスト
Q: L1正則化を表しているグラフはどれか。
A:
- 例題チャレンジ
Q:
深層学習において、過学習の抑制。汎化性能の向上のために正則化が用いられる。そのひとつにL2ノルム正則化(Ridge,Weigh Decay)がある。以下はL2正則化を適用した場合にパラメータの更新を行うプログラムである。あるパラメータparamと正則化がないときに伝播される誤差の勾配gradが与えられたとする。
最終的な勾配を計算する(え)にあてはまるのはどれか。ただしrateはL2正則化の係数を表すとする。
def ridge(param, grad, rate):
"""
param: target parameter
grad: gradients to param
rate: ridge coefficient
"""
grad += rate *(え)
A:
sign(param)
L1ノルムは|param|なのでその勾配が誤差の勾配に加えられる。
つまり、sigh|param|である。signは符号関数である。
ドロップアウト
ランダムにノードを削除して学習させること。
- メリット
データ量を変化させずに、異なるモデルを学習させていると解釈できる。
Section4 畳み込みニューラルネットワークの概念
CNNの構造図(例)
入力層→畳み込み層→プーリング層→畳み込み層→プーリング層→全結合層→出力層
主に画像で使われる。
LeNetの構造

(32,32) (28,28,6) (14,14,6) (10,10,16) (5,5,16) (120) (84) (10)
1024個 4704個 1176個 1600個 400個 120個 84個 10個
畳み込み層の全体像

畳み込み層
画像の場合、縦、横、チャンネルの3次元のデータをそのまま学習し、次に伝えることができる。
畳み込み演算概念(バイアス)

畳み込み演算概念(パディング)
出力画像を入力画像の大きさに揃える。

畳み込み演算概念(ストライド)
出力画像を小さくする

畳み込み演算概念(チャンネル)
フィルターの数

- 全結合層のデメリット
画像の場合、縦、横、チャンネルの3次元データだが、1次元のデータとして処理される。
→RGBの各チャンネル間の関連性が、学習に反映されないということ。
- 確認テスト
Q:
サイズ6x6の入力画像を、サイズ2x2のフィルタで畳み込んだ時の出力画像のサイズを答えよ。
なおスライドとパディングは1とする。
A:
7x7
Section5 最新のCNN
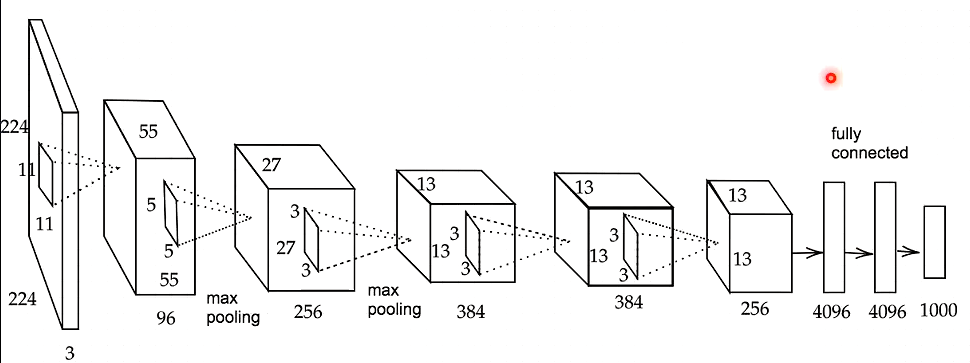
AlexNet
モデルの構造
5層の畳み込み層およびプーリング層など、それに続く3層の全結合層から構成される。
過学習を防ぐ施策
サイズ4096の全結合層の出力にドロップアウトを使用している。