1. 初めに
初めに断りを入れておくと、大学時代から一応軽く統計を学んできたがいまいち自信がない
何か間違っていたり、勘違いをしていそうでしたらどんどんご指摘をいただきたいです
2. 背景
emacsのpython設定も(なんとか?)終了し、kaggleを物色していたところSpotifyのデータを見つけた。このデータの中身は2010年〜2019年のtop100のデータが入っている
https://www.kaggle.com/datasets/muhmores/spotify-top-100-songs-of-20152019
面白そうだなーとなんか分析できないかなーと考えた結果、年を1つの標本として差がありそうなところをt検定してみることにした。(この時点で無作為抽出ではないのではないかとヒヤヒヤしている)
3. データ観察
ということで、時系列とデータに分けてグラフに書き出してみた
横軸は年の推移を表しており、縦軸にそれぞれの属性の値の平均値が入る
縦の棒は標準偏差を表している
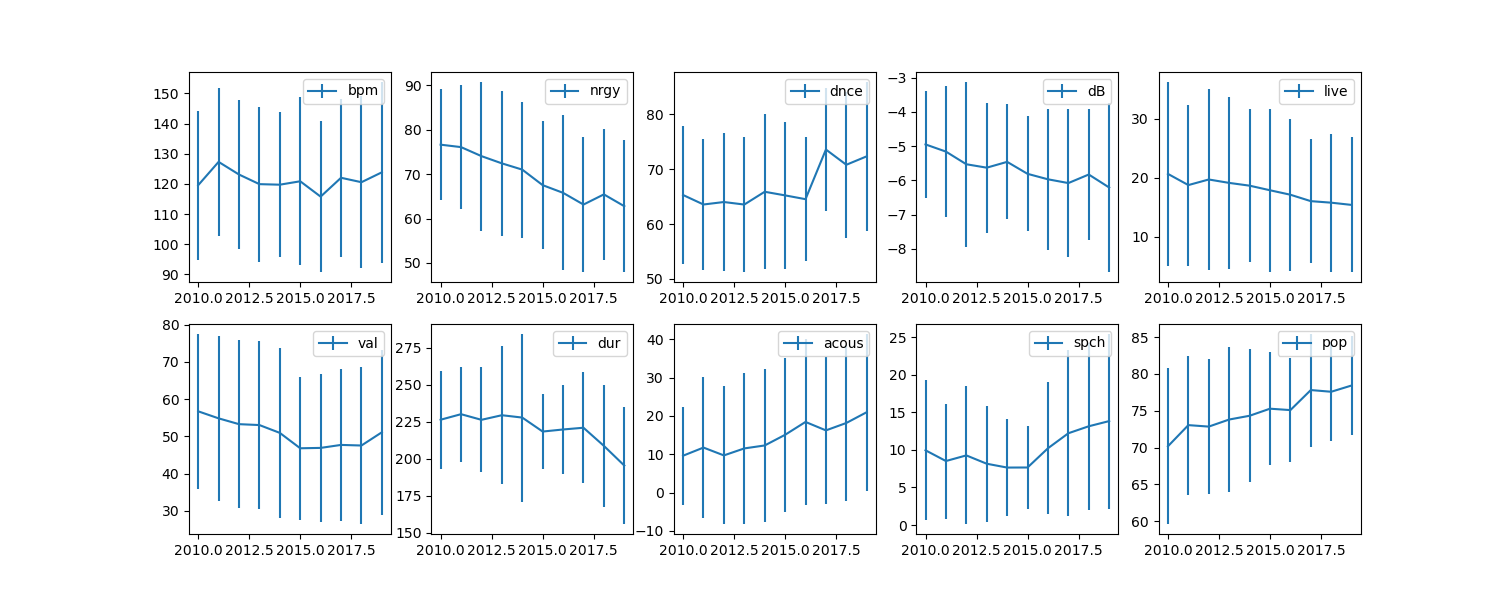
うーーん...ばらつきすぎかな??
年別に見ていくとnrgyとdnceとpopの2010 vs 2019がいいのかなあと思い、そこを分析していく
要素説明(かなりそのまま)
nrgy:enrgic the song is
dnce:danceability of the song
pop :populality of the song
4. ヒストグラム
分布を見るためにnrgyとdnceとpopの2010 vs 2019の個数をヒストグラムに書き出してみた
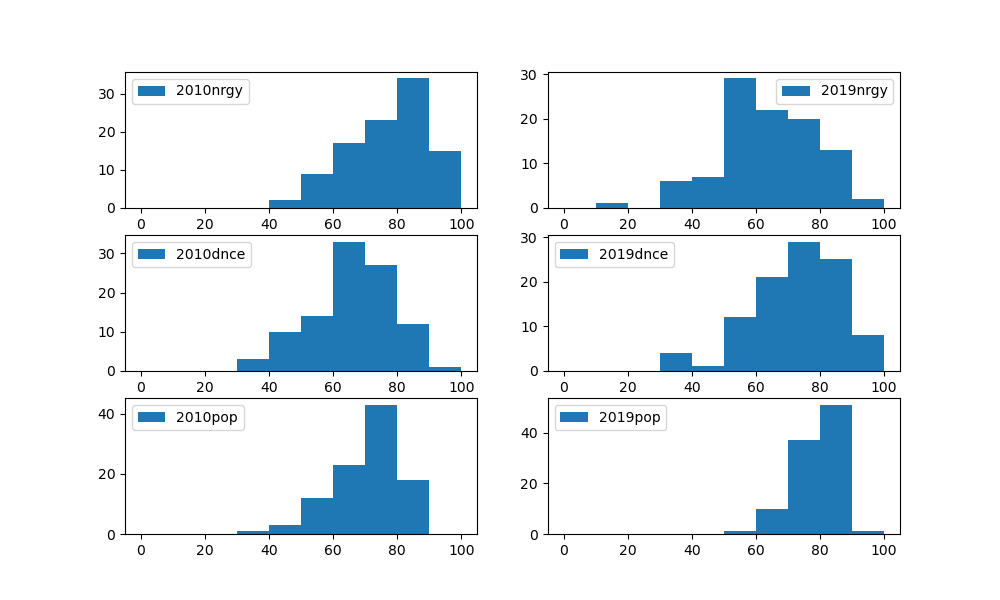
あ、でもなんか正規分布っぽさがありそうな気がしないでもない...
中心極限定理で正規分布に従うと仮定する(ここも完璧な理解では無い)
そしてここからは有意差が出る可能性があるnrgyについて検定を行っていこうと思う
5. F検定
分散によってウェルチを使うかスチューデントを使うか変化するので調べる
ソースコードは以下
from typing import Any
import pandas as pd
import numpy as np
import scipy.stats as st
data = pd.read_csv("Spotify2010-2019Top100.csv")
data: Any
d_2010 = data[["topyear","nrgy"]].query("topyear == 2010")
d_2019 = data[["topyear","nrgy"]].query("topyear == 2019")
d_2010 = d_2010[["nrgy"]]
d_2019 = d_2019[["nrgy"]]
d_2010 = d_2010.values
d_2019 = d_2019.values
d_2010Var = np.var(d_2010,ddof=1)
d_2019Var = np.var(d_2019,ddof=1)
d_2010df = len(d_2010)-1
d_2019df = len(d_2019)-1
f = d_2010Var/d_2019Var
one_sided_pval1 = st.f.cdf(f, d_2010df, d_2019df) # 片側検定のp値 1
one_sided_pval2 = st.f.sf(f, d_2010df, d_2019df) # 片側検定のp値 2
two_sided_pval = min(one_sided_pval1, one_sided_pval2) * 2 # 両側検定のp値
print("F: ",round(f,3))
print("p-value:",round(two_sided_pval,3))
F検定は以下のようになった
F:0.71 ,p-value: 0.09
0.05 < p なので、スチューデントのt検定かな
6. t検定
先ほどのデータに追加して以下を記述
print(st.ttest_ind(d_2010,d_2019))
結果は以下のようになった
Ttest_indResult(statistic=array([7.11047038]), pvalue=array([2.05645336e-11]))
一般的な有意水準は5%なので
p<0.05で有意差ありと
つまり2010のSpotify Top100 の方が 2019のSpotify Top100より曲がエネルギッシュということが示された(多分)
7. 感想
なんとか一通りのt検定を行った。
ツッコミどころだらけだと思いますので、何かあればコメントをよろしくお願いします。
8. 参考文献
https://www.kaggle.com/datasets/muhmores/spotify-top-100-songs-of-20152019
https://qiita.com/suaaa7/items/745ac1ca0a8d6753cf60
https://qiita.com/code0327/items/a96dd2fbd8a491d2eeaa