はじめに
この記事はプログラミング初学者による備忘録用の記事であり、また、少しでも他の初学者のお役に立てればと思い書いています。
今回は、データベースを扱う上で重要となるインデックスについて色々と調べたので、すぐに見返すことができるように備忘録としてまとめておきたいと思います。内容は全てInnoDBを前提としています。
間違いなどがございましたら、ご指摘のほどよろしくお願い致します。
インデックスとは
インデックスとは、データベース内から特定の値がある行をすばやく見つけるために使用されます。
データの本体は表という形式ですが、インデックスはカラムの値とその値を持っている行へのポインタの組となっています。
しかし、無駄なインデックスを作成した場合、膨大な容量を使われパフォーマンスが低下する場合もあるので、本当に必要な箇所にだけ使うようにします。
インデックスが無い場合、MySQLは関連する行を見つけるために、先頭行からテーブル全体を読み取る必要があります。テーブル全体を読み取るということは、テーブルの大きさに比例して読み取るコストも大きくなり、処理に時間がかかります。
MySQLインデックスは、一般的にB+treeと呼ばれるツリーデータ構造が使用されます。
B+tree構造は、常にソートされ続け、正確な一致 (等号演算子) および範囲 (大なり、小なり、BETWEEN演算子など) の高速化を可能にします。
※B+treeについては下記の補足欄で説明
特徴
インデックスの特徴を簡単に述べると、下記のような点が挙げられます。
・インデックスはツリー構造(B+tree)になっている
・テーブル全体をスキャンする必要がないため、データアクセスを高速化する
・カーディナリティが低いと効果が出ない場合がある
・更新機能・キャッシュの効率を低下させる可能性がある
・複合インデックスの場合、複数条件の右側に位置する列のみを指定してアクセスをしてもインデックスが無効になる
・Like検索で先頭に'%'を使用する後方一致、部分一致検索を行うと、インデックスが無効になる
InnoDBにおける主なB+treeインデックス
InnoDBにおける主なB+treeインデックスにはクラスタインデックスとセカンダリインデックスの
2種類があります。
クラスタインデックス
クラスタインデックスとは、主キー(PRIMARY KEY)のリーフノードに全てのデータが含まれるという構造のことを指します。
テーブル上で主キー(PRIMARY KEY)を定義すると、InnoDB ではそれがクラスタ化されたインデックスとして使用されます。(作成するテーブルごとに主キーを定義します)
PRIMARY KEYに論理的に一意で、Null以外のカラムまたはカラムのセットが存在しない場合は、自動的に値が入力される自動インクリメントカラム(AUTO_INCREMENT)を設定します。
InnoDBがクラスタインデックスとして使用するキーを決める手順
1.定義された主キーを使用する
主キーがない場合、手順2を選択
2.すべてのキーカラムがNOT NULLのUNIQUEインデックスを使用する
MySQLはテーブルにPRIMARY KEYが定義されていない場合、すべてのキーカラムがNOT NULLのUNIQUEインデックスを最初に検索し、InnoDBはそれをクラスタインデックスとして使用します。
3.GEN_CLUST_INDEXという名前の非表示のクラスタインデックスを、行ID値を含む合成カラムに内部的に生成する
テーブルにPRIMARY KEYインデックスまたは適切なUNIQUEインデックスがない場合、GEN_CLUST_INDEXという名前の非表示のクラスタインデックスを、行ID値を含む合成カラムに内部的に生成します。(隠れた主キーを自動で定義し、その主キーを用いてクラスタ化)
そのようなテーブルでは、InnoDBが行に割り当てるIDに基づいて行の順序付けが行われます。
クラスタインデックスのメリット
・主キーの値で検索をすると、主キーのリーフノードにたどり着いたときには、データのフェッチも完了しているため、処理が高速です。
・クラスタインデックスから行にアクセスすると、インデックス検索がすべての行データを持つページで直接実行されるため、高速になります。
・InnoDB テーブルの記憶域は、主キーカラムの値に基づいて編成され、主キーカラムに関連するクエリおよびソートを高速化します。
クラスタインデックスのデメリット
・主キーが長くなると、セカンダリインデックスで使用される領域も大きくなります。
・クラスタインデックスはインデックスのサイズが大きくなってしまうことや、セカンダリインデックスを用いた検索が遅くなってしまう可能性があります。
セカンダリインデックス
主キー以外の特定のカラムに張るインデックスのことを指し、1つまたは複数のセカンダリインデックスを含めることができます。
要するに、ALTER TABLE table_name ADD INDEXを用いて能動的に生成するインデックスは全てセカンダリインデックスに該当します。
InnoDBでは、セカンダリインデックス内の各レコードに、必ず行の主キーカラムとセカンダリインデックスに指定されたカラムが含まれます。要するに、セカンダリインデックスはリーフノードにインデックスのキーとクラスタインデックスのキー(主キーの値)の組を持っています。
従来、セカンダリインデックスの作成および削除には、InnoDBテーブルのすべてのデータのコピーによる大きなオーバーヘッドが伴いましたが、高速インデックス作成機能(オンラインDDL)を使用すると、セカンダリインデックスに対するCREATE INDEX ステートメントと DROP INDEX ステートメントが高速化されます。
※オンラインDDLについてはリンク先に詳細が書かれているので参照して下さい
セカンダリインデックスを用いたデータ検索
B+treeを2回検索する必要があり、下記の通りとなります。
・検索対象のデータ(セカンダリインデックスのカラム値)と共に存在する主キーを取得
・取得した主キーを用いてクラスタ化インデックスのB+treeを辿り、対象データを取得
クラスタインデックスを用いた検索時に比べ、単純計算で処理数が倍になってしまいます。
図で表すと、下記のようなルートを辿り、主キーを用いた二段階の処理(セカンダリインデックス -> クラスタインデックス)でデータの検索を行います。
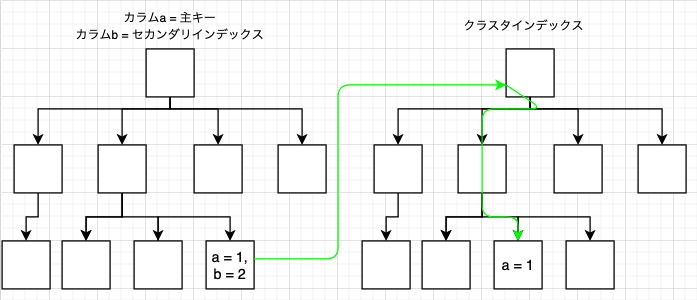
セカンダリインデックスに必要な情報が全て格納されていれば、クラスタインデックスを辿る必要がないため高速です。
このようにレコードを取得する際にセカンダリインデックスで完結する場合のことをカバリングインデックスと呼びます。
インデックスの注意点
・インデックスを作成すると必ず処理速度が高速化されるとは限らない
インデックスがあれば、表の全ノード走査よりも短時間で1つのデータを特定することができますが、すべてのカラムに対してインデックスを作成すれば良いということではありません。
~処理速度が低下する例~
1.インデックスを作成したカラム内の行データが追加・更新される場合
表のデータ構造だけでなく該当するカラムのインデックスのデータ構造も更新する必要があります。
従って、表に作成されているインデックスの個数が多いほど更新性能が低下します。
2.表データの多くの割合にアクセスする場合(集計や分析)
該当するデータ件数が多いと、いつか表ノードを全走査(フルスキャン)するよりもインデックスノードにアクセスした分だけ処理量が多くなります。このような場合、インデックスアクセスではなく表ノードを全走査するSQL実行計画が選択される場合があります。
・カーディナリティが高いカラムを選択する
カーディナリティが高いとは、カラムの値の取りうる種類がテーブルのレコード数に対して多いことを指します。
何故、カーディナリティが高いカラムに対してインデックスを作成することが推奨されているかというと、カーディナリティが低いカラムと比較すると、レコードが絞り込みやすく、相対的にインデックスの効果が高くなる為です。
※カーディナリティが低い場合でも、データに偏りがあるとインデックスは機能します。
・複合インデックスを使用する場合、設定するカラムの順番に気をつける
複合インデックスとして、カラムA、カラムBの順でインデックスを設定した状態で、カラムBのみをWHERE句で指定した場合、インデックスが無効になってしまいます。
何故かというと、データベースは複合インデックスのエントリーをソートする際、インデックスの定義に書かれている順序に従ってカラムを識別するためです。
上記の設定の場合、カラムAに同じ値が複数ある場合にカラムBもソートされ、検索の場合も「カラムA => カラムB」という順で実施される為、カラムBのみWHERE句で指定してもインデックスが無効となります。
プログラム側で、WHERE句の内容を予め調べた上でそれに沿った複合インデックスを作成することが重要になります。
~例~
--カラムごとにインデックスを設定
ALTER TABLE indexA1 ADD INDEX index_indexA1_on_col1(col1);
ALTER TABLE indexA2 ADD INDEX index_indexA1_on_col2(col2);
--(col1, col2)の順で複合インデックスを設定
ALTER TABLE indexB ADD INDEX index_indexB_on_col1_col2(col1, col2);
--(col2, col1)の順で複合インデックスを設定
ALTER TABLE indexC ADD INDEX index_indexC_on_col2_col1(col2, col1);
| WHERE句の指定内容 | WHERE col1 = 'a' | WHERE col2 = 'a' | WHERE col1 = 'a' AND col2 = 'a' |
|---|---|---|---|
| indexA | indexA1が使用される | indexA2が使用される | indexA1, indexA2のどちらかが使用される |
| indexB | indexBが使用される | インデックスは使用されない | indexBが使用される |
| indexC | インデックスは使用されない | indexCが使用される | indexCが使用される |
**・複合インデックスでは走査範囲を意識した上で適切にカラムを設定する** 例えば、特定のユーザーを検索する際にWHERE句を使用する場合、走査する範囲や順序を意識した上で複合インデックスを作成すべきです。 「所属するチーム名、誕生日」カラムを複合インデックスとして指定する場合、先に所属するチーム名を指定してから誕生日を複合インデックスに設定することで走査する範囲が小さくなることは明らかです。
インデックスの作成基準
・インデックスは、クエリーが指定した検索条件に合致するデータが全データの中で割合が少ない場合に効果が発揮されます。
従って、インデックスを作成するカラムは、クエリーの選択率が小さいカラムが候補となります。
・スロークエリが発見された時、解決策の1つとしてインデックスを作成するかどうかを考えます。1秒以上かかっているクエリーがあれば、インデックスの作成を検討します。
・多く実行されるクエリーにはインデックを作成すべきです。1日に1000回実行される1秒のクエリーは、1日に数回実行される10秒のクエリよりも大きな負担がかかります。
注意点
数千レコード未満のテーブルにインデックスを作成しないようにします。パフォーマンスの改善を目的としてインデックスを作成したとしても、数千程度のレコードしか存在しないテーブルはインデックスを使うメリットはほとんどありません。
インデックスを作成すべき例
・テーブル内のデータ量が多く、少量のレコードを検索する場合
前提として、インデックスはある程度の規模のあるテーブルに作成することが推奨されます。
データ量が少ない場合、フルスキャンした方が早いケースもあります。
・カーディナリティが高い場合
例えば、商品IDのカラムには商品の数だけ値の種類が存在するので、カーティナリティは高いと言えます。
商品が100個あると仮定すると、単一の商品IDで全体の1%に絞り込むことができます。
このように、対象となるカラムをキーで絞り込みを行った結果、全体の1~5%程度に絞れる状態を、カーディナリティが高いといいます。
・WHERE句の条件、または結合の条件として頻繁に使用する場合
WHERE句に条件を指定する検索が中心となる表にはインデックスが必要となります。
フルスキャンが目的の場合、インデックスは不要です。
・NULL値が多く、NULL値以外の値を検索する場合
Indexは、NULL値を含まないので、NULL値以外の値の検索には効果があります。
・外部キーとなるカラム
MySQLの場合、外部キーを作成すると自動的にインデックスが作成されます。
インデックスを作成すべきでない例
・カーディナリティが低い場合
例えば、性別のカラムに男性と女性の2種類のデータしか存在しない場合、インデックスを経由しても半分までしか絞り込めず、また、インデックスを経由することによるオーバーヘッドが発生して逆効果になる可能性があります。
注意点
カーディナリティが低いカラムであっても、例えば2種類のデータが存在して片方にデータが偏るような場合は効果は大きくなります。
・カラムのデータの更新、削除、追加頻度が高い場合
カラムデータが更新等されると、自動的にインデックスも更新等が行われ、更新、削除、追加の処理ではインデックス分の処理が増える為、処理速度が低下してしまいます。
・表の規模が小さいか、表から大部分のレコードを検索する場合
・WHERE句の条件としてあまり使用されないカラム
・WHERE句の条件として使用されるが、カラムが式の一部として参照される場合
~例~
SELECT *
FROM test
WHERE col*2 = 10;
上記のようにWHERE句の計算式に使われるカラムではインデックスが使用されません。
インデックスを追加する方法
基本的な書式は下記の通りです。
ALTER TABLE table_name ADD INDEX index_name(column_name);
--例
ALTER TABLE users ADD INDEX index_users_on_updated_at(updated_at);
複合インデックスを追加する場合
対象となる複数のカラム名をカンマで区切ります。
複合インデックスとは(公式ドキュメントへのリンク)
注意点
複合インデックスには、クエリ文がINDEX作成時のカラム順に基づいていないと、INDEXが使えないという制約が存在します。従って、カラム名を指定する順は、使用されるWHERE句の内容を把握した上で指定する必要があります。
--複合インデックスの場合
ALTER TABLE table_name ADD INDEX index_name(column_name,column_name);
--例
ALTER TABLE users ADD INDEX index_users_on_created_at_updated_at(created_at,updated_at);
インデックスの削除
ALTER TABLE table_name DROP INDEX index_name;
インデックスが使用されているかの確認方法
MySQLでは、EXPLAINを使用して、クエリー実行計画(MySQLがクエリーをどのように実行するかの説明) を取得します。
EXPLAIN SELECT * FROM users WHERE name = 'boo';
--実行結果
+----+-------------+-------+------------+-------+-------------------+-------------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+-------------------+-------------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | users | NULL | const | users_name_unique | users_name_unique | 1022 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+-------+-------------------+-------------------+---------+-------+------+----------+-------+
上記の結果から分かるように、EXPLAINでは、使用されるキーおよび使用可能なキーに関する情報が提供され、rowsカラムには、テーブル内の行の合計数が表示されます。
また、EXPLAINを使用して非パーティションテーブルに対するクエリーを調べる場合、エラーは生成されませんが、partitionsカラムの値は常にNULLです。
どのテーブルから処理するのかということが最も重要であり、EXPLAINの出力の順序がどのテーブルから処理するかということを反映しています。
クエリの実行計画を確認する手順
・id/select_type/tableフィールドを見て、どのテーブルがどの順序でアクセスされるのかを知る。これらはクエリの構造を示すフィールドであると言える。サブクエリが含まれている場合にはEXPLAINの表示順とアクセスされる順序が異なる場合があるので気をつける必要がある。
・type/key/ref/rowsフィールドを見て、各テーブルから行がどのようにフェッチされるのかを知る。どのテーブルへのアクセスが最も重いか(クエリの性能の足を引っ張っているのか)を、これらのフィールドから判断することが出来る。
・Extraフィールドを見て、オプティマイザがどのように判断して、各々のテーブルへのアクセスにおいて何を実行しているのかを知る。Extraフィールドはオプティマイザの挙動を示すものであり、クエリの全体像を把握するのに役立つ。
引用:MySQLのEXPLAINを徹底解説!!
実行計画で確認すべき内容
1.id/select_typeの確認
idとselect_typeはEXPLAINの最初の2つのフィールドであり、セットで考えます。
select_typeはクエリの種類を表すものであり、ツリーの構造にそのまま反映されます。
select_typeには、JOIN、サブクエリ、UNIONおよびそれらの組み合わせから導き出されたものが表示されます。
・JOINの場合
| select_type 値 | 意味 |
|---|---|
| SIMPLE | 単純な SELECT(UNION やサブクエリーを使用しません)。 クエリがUNIONやサブクエリーを使用せず、JOINのみで構成されます(複雑なJOINも含む)。 |
**・サブクエリの場合** サブクエリが絡むと次のselect_typeには下記5種類のうちいずれかが表示されます。
| select_type 値 | 意味 |
|---|---|
| PRIMARY | もっとも外側のSELECT。外部クエリを示す。 |
| SUBQUERY | サブクエリ内の最初のSELECT。相関関係の内のサブクエリ。 |
| DEPENDENT SUBQUERY | サブクエリ内の最初の SELECT で、外側のクエリーに依存。相関関係のあるサブクエリの仕様を示します。 外部コンテキストの変数の異なる値の各セットにつき、一回だけサブクエリーが再評価されます。 |
| UNCACHEABLE SUBQUERY | 結果をキャッシュできず、外側のクエリーの行ごとに再評価される必要があるサブクエリ。 実行する度に結果が変わります。外部コンテキストの行ごとにサブクエリーが再評価されます。 |
| DERIVED | 派生テーブル SELECT (FROM句内のサブクエリ)。 |
サブクエリの場合は実行順序に気をつける必要があります。
DERIVEDの場合 : サブクエリ→外部クエリの順番でクエリが実行されます
その他の場合 : 外部クエリ→サブクエリの順番でクエリが実行されます
**SUBQUERYの場合 :**サブクエリが実行されるのは最初の1回だけで、それ以降はキャッシュされた実行結果が利用されます。
・UNIONの場合
クエリにUNIONが含まれる場合、下記5種類のいずれかがselect_typeに表示されます。
| select_type 値 | 意味 |
|---|---|
| PRIMARY | UNIONにおいて最初にフェッチされるテーブル |
| UNION | UNION 内の 2 つめ以降の SELECT ステートメント。2番目以降にフェッチされるテーブル |
| UNION RESULT | UNIONの実行結果 |
| DEPENDENT UNION | UNION 内の 2 つめ以降の SELECT ステートメントで、外側のクエリーに依存します。 (DEPENDENT SUBQUERYがUNIONになっている場合) |
| UNCACHEABLE UNION | キャッシュ不可能なサブクエリーに属する UNION 内の2つめ以降の SELECT (UNCACHEABLE SUBQUERYがUNIONになっている場合) |
**2.typeの確認**
レコードアクセスタイプとも呼ばれ、対象のテーブルに対してどのような方法でアクセスするかを示します。
不適切なクエリはこのフィールドを見ればすぐに分かるので重要なフィールドです。
index、ALLが表示されている場合、改善の余地があるのでクエリをチューニングしてください。
タイプ 一覧
| type | 意味 |
|---|---|
| const | PRIMARY KEYまたはUNIQUEインデックスのルックアップによるアクセス。最速。 |
| eq_ref | JOINにおいてPRIARY KEYまたはUNIQUE KEYが利用される時のアクセスタイプ。 constと似ているがJOINで用いられるところが違う。 |
| ref | ユニーク(PRIMARY or UNIQUE)でないインデックスを使って等価検索(WHERE key = value)を行った時に使われるアクセスタイプ。 |
| range | インデックスを用いた範囲検索。 |
| index | フルインデックススキャンであり、インデックス全体をスキャンする必要があるのでとても遅い。 |
| ALL | フルテーブルスキャン。インデックスがまったく利用されていないことを示す。 OLTP系の処理では改善必須。 |
**3.possible_keysの確認**
MySQL がこのテーブル内の行の検索に使用するために選択できるインデックスを示します。
このカラムがNULLの場合は、関連するインデックスがないということです。
NULLの場合、WHERE句を調査してWHERE句がインデックス設定に適したカラムを参照しているかどうかをチェックすることで、クエリーのパフォーマンスを向上できることがあります。
テーブルにあるインデックスを確認するには、SHOW INDEX FROM table_nameを使用します。
4.keyの確認
keyカラムは、MySQLが実際に使用することを決定したキー(インデックス)を示します。
MySQLが行をルックアップするために、possible_keysインデックスを使用することを決定した場合、キー値としてそのインデックスが一覧表示されます。
keyがNULLの場合、MySQLがクエリーを効率的に実行するために使用するインデックスが存在しないことを示します。
5.refの確認
検索条件で、keyとともに使用されるカラムまたは定数を示します。
定数が指定されている場合はconstと表示され、JOINが実行されている時は、結合する相手側のテーブルで検索条件として利用されているカラムが表示されます。
6.kye_lenの確認
選択されたキーの長さを示します。
インデックスの走査は、キー長が短い方が高速です。
インデックスを作成する場合、キー長が短い方が高速であることを念頭に置いてインデックスを作成すべきです。
7.Extraの確認[重要]
Extraには、MySQLがクエリーを解決する方法に関する追加情報が含まれます。
Extraは、そのクエリを実行するためにオプティマイザがどのような戦略を選択したかということを示すフィールドでもあります。
クエリーを可能なかぎり高速にしたい場合は、Using filesortおよびUsing temporaryといったExtra値に注意します。
・Using where・・・頻繁に出力される追加情報である。WHERE句に検索条件が指定されており、なおかつインデックスを見ただけではWHERE句の条件を全て適用することが出来ない場合に表示される。
・Using index・・・クエリがインデックスだけを用いて解決できることを示す。Covering Indexを利用している場合などに表示される。
・Using filesort・・・filesort(クイックソート)でソートを行っていることを示す。
・Using temporary・・・JOINの結果をソートしたり、DISTINCTによる重複の排除を行う場合など、クエリの実行にテンポラリテーブルが必要なことを示す。
・Using index for group-by・・・MIN()/MAX()がGROUP BY句と併用されているとき、クエリがインデックスだけを用いて解決できることを示す。
・Range checked for each record (index map: N)・・・JOINにおいてrangeまたはindex_mergeが利用される場合に表示される。
・Not exists・・・LEFT JOINにおいて、左側のテーブルからフェッチされた行にマッチする行が右側のテーブルに存在しない場合、右側のテーブルはNULLとなるが、右側のテーブルがNOT NULLとして定義されたフィールドでJOINされている場合にはマッチしない行を探せば良い・・・ということを示す。
引用:MySQLのEXPLAINを徹底解説!!
その他のEXPLAINに関する詳細な情報は、下記リンク先の公式ドキュメントを参照して下さい。
リンク先 一覧
パーティションに関する情報を取得する
EXPLAIN ステートメント
EXPLAIN 出力フォーマット
拡張 EXPLAIN 出力形式
補足
B+treeとは
B+treeを説明する前に、線形探索と二分探索木、AVL木について説明する必要があります。
分かりやすいように、例題を出しつつまとめたいと思います。
例題
[1,2,3,4,5,6,7]の7つの値があると仮定します。
この7つの値から6という値を取得する必要がある場合の方法を考えます。
線形探索とは
特定の値をデータの頭から検索していく方法です。
二分探索木とは
左の子の値 ≤ 親の値 ≤ 右の子の値というルールで構成されており、検索したい値が中央値より小さい場合は左に進み、大きい場合は右に進みながら検索していくアルゴリズムです。
親の左側のノードの値が必ず親よりも小さく、右側のノードの値が必ず親よりも大きくなっています。
下記図にて、線形探索と比較すると分かるように、二分探索しやすいように値を大小で振り分けたデータ構造になっている為、計算回数が少なくなります。
しかし、二分探索木はデータの挿入や削除により木の高さが変わった場合、検索回数が増えてしまう可能性があります。
その課題に対応したのが、次に述べるAVL木となっています。

AVL木(平衡二分探索木)とは
AVL木は、木の高さに変更があった場合、二分探索木に回転という操作を行うことで木の高さを一定にするデータ構造のことです。
二分探索木における木の回転とは
二分探索木の各ノードが持つ値の大小関係の条件を満たしたまま木を変形する操作である。
~例~
右回転の場合は下記図のように、親と子の位置関係を変えることで、木の高さを一定にします。
・左にある部分木は、位置が1段高くなる
・中央の部分木は、親の値が変わる(縦の位置は変わらない)
・右にある部分木は、位置が1段低くなる
このように回転することで、木の高さを一定にするデータ構造を持っています。
右回転の図
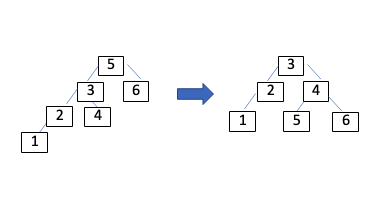
このAVL木をベースとして多分岐の平衡木構造を保持しているのがB+treeと呼ばれています。
B+treeとは
B+treeとは、1つのノードがm個(m>=2) の子ノードを持つことができる平衡木構造のことです。
※ m=2の場合が二分検索木
平衡木構造というデータ構造に関しては、AVL木と同じ構造ですが、B+treeが優れている点は、2以上の子ノードを持つ事が可能であるという点になります。
多数の子ノードを持つことで、木の深さを抑えて読み取り回数を減らすような構造になっており、高速なデータ検索が可能になっています。
ノードの読み取り回数は木の深さに関連していて、AVL木の場合、log n 回なのに対して、B-treeの場合、log n / log m 回になります。そのためmが大きくなるほど、処理時間に差が出てきます。
t = log n / log m 回の式から分かるように、「入力される数列の長さn」を「mで割り続けて1になった時の割った回数」が「探索回数(t)」となる。
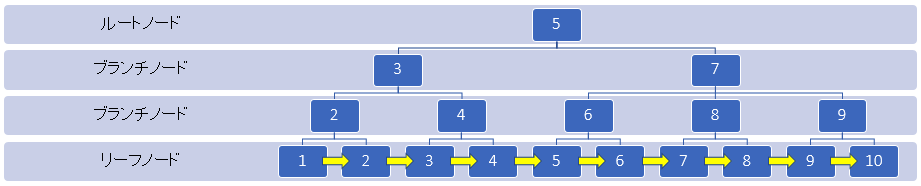
B+treeインデックスの基本構造
B+tree構造に基づくインデックスは、ルートノードとブランチノード、そしてリーフノードで構成されています。
特徴
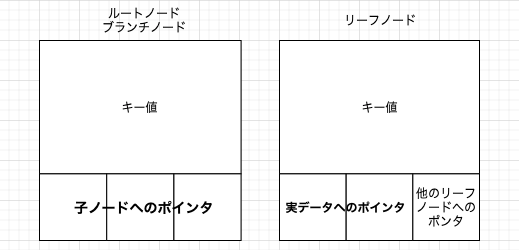
・ルートノードとブランチノードは、インデックス対象のキー値と子ノードへのポインタ情報を持つ
・ブランチノードはキー値しか持たないため、ページ(ブロック)に載せられるキーが多い。これにより、Orderが高くなるためTreeの階層が少なくなり計算量が減ります
・リーフノードは、インデックス対象のキー値と実データへのポインタ情報を持つ
・リーフノードには、自身と他のリーフノードを結ぶポインタがあるので、範囲検索に優れている
・対象のリーフノードに辿り着いたら、リーフノード内で保持するポインタ情報を経由して実テーブルにアクセス後、データを取得する
・データベースのデータ値を持つのはリーフノードだけであり、リーフノード以外のノードには、データ値を格納しない。
簡易的なB+tree全体図
各ノードの詳細図
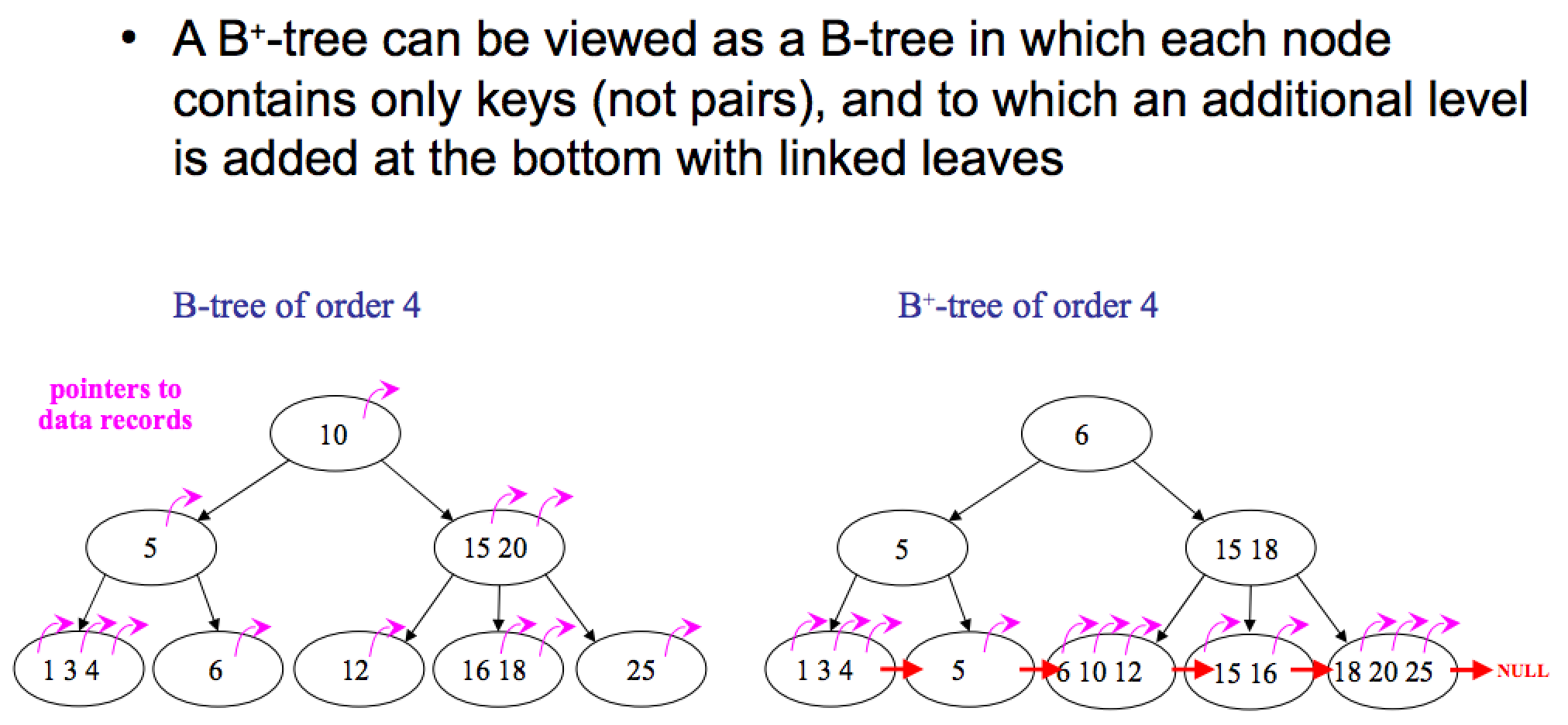
B+treeとB-treeの違い
B+tree
・B+treeは、内部ノードに関連するデータを持たないため、より多くのキーをメモリの1ページに収めることができます。そのため、リーフノードにあるデータにアクセスするためのキャッシュミスが少なくて済みます。
・B+ツリーのリーフノードはリンクされているので、ツリー内のすべてのオブジェクトをフルスキャンする場合は、すべてのリーフノードを1回だけ線形探索する必要があります。
・リーフノードには、自身と他のリーフノードを結ぶポインタがあるので、範囲検索やorder by、group by等の対応に優れています。
B-tree
B-treeは、キーごとにデータが格納されているため、頻繁にアクセスされるノードはルートに近い位置にあり、より迅速にアクセスすることができます。
B-treeでは、ツリー内のすべてのオブジェクトをフルスキャンする場合は、ツリーすべてのレベルを走査する必要があります。B+treeのリーフノードを線形探索するよりも多くのキャッシュミスを引き起こす可能性があります。
出典:What are the differences between B trees and B+ trees?
カーディナリティとは
RDBにおいて、あるテーブルの同一のカラムに含まれる異なる値の数(バリエーション)のことを指し、バリエーションの数でカーディナリティが低いか高いかを区別します。
カーディナリティが低い例
・性別 男性と女性の2種類
・学年 小学校であれば1-6年の6種類
このように、カラムのデータの種類が少なく、同じ値が何度も登場する度合いが高いことをカーディナリティが低いと表します。
カーディナリティが高い例
・氏名 同姓同名以外は性別、苗字と名前は一致せず値の種類が多くなる
・登録日時 年-月-日-時で表すと値の種類が多くなる
このように、カラムのデータの種類がテーブルのレコード数に比べて多いことをカーディナリティが高いと表します。
※複数のカラムにインデックスを作成する場合、カーディナリティが高いか低いかは、そのデータの種類の合計値をベースとして考えます。
参考文献
ヤフー社内でやってるMySQLチューニングセミナー大公開
MySQL 用語集
DBでデータの位置を高速に特定する「索引(インデックス)」とは? 索引の仕組みと注意点
パーティションに関する情報を取得する
EXPLAIN ステートメント
EXPLAIN 出力フォーマット
拡張 EXPLAIN 出力形式
マルチカラムインデックス
漢のコンピュータ道 MySQLのEXPLAINを徹底解説!!
クラスタインデックスとセカンダリインデックス
StackOverflow What are the differences between B trees and B+ trees?
なぜBTreeがIndexに使われているのか