はじめに
この記事はプログラミング初学者による備忘録用の記事であり、また、少しでも他の初学者のお役に立てればと思い書いています。
今回は、正規化について調べたので、備忘録としてまとめておきたいと思います。(新しい情報を見つけ次第、随時更新します)
間違いなどがございましたら、ご指摘のほどよろしくお願い致します。
正規化とは
正規形とは、DB上で扱うデータの重複をなくし、一貫性と効率性を保持するためのデータ形式です。
正規化は、テーブルを無損失分解となるように分割します。
無損失分解とは、1つのテーブルを複数に分解した際に、その分解されたテーブル同士を自然結合することで元テーブルを過不足なく復元できる特性のことを言います。
正規化のメリット
データの追加・更新・削除などに伴うデータの不整合性(矛盾)の発生を防ぎ、設計レベルでメンテナンス効率を高めることができます。
要するに正規化を行うことで、検索の効率が良くなったり、変更に強いテーブルを作ることでデータベースの保守がしやすくなります。
正規化のデメリット
正規化を行うと、テーブルが分割され、パフォーマンスの悪化を引き起こす場合があります。
正規化により、テーブルの分割数が増加すると、増加分だけデータ検索の際にテーブルの結合が発生します。
従って、全てのテーブルにおいて正規化が正しいとは言い切れません。
正規化を行った場合は、正規化の実行後、その都度パフォーマンスチューニングの結果を見て正規化が悪影響を及ぼしているかどうか判断すべきだと思います。
非正規化のテーブルで起こり得ること
正規化が行われていない場合、データの変更が発生した際に、不整合性(矛盾)が発生する可能性があります。
例えば、野球選手の球団名を管理するテーブル(非正規化)があるとします。
| 名前 | 年齢 | 球団名 |
|---|---|---|
| 田中 | 23 | 南海ホークス |
| 鈴木 | 32 | ロッテオリオンズ |
| 佐藤 | 35 | 南海ホークス |
球団名が「南海ホークス」から「福岡ダイエーホークス」に変わるとします。
| 名前 | 年齢 | 球団名 |
|---|---|---|
| 田中 | 23 | 福岡ダイエーホークス |
| 鈴木 | 32 | ロッテオリオンズ |
| 佐藤 | 35 | 南海ホークス(変更忘れ) |
上記のようなテーブルでは、該当するデータを1個ずつ更新する必要があり、球団名のレコード全てを「南海ホークス」から「福岡ダイエーホークス」に更新しないと矛盾が発生してしまいます。
RDBにおいて矛盾が発生する原因は、上記のようなテーブル設計におけるデータの重複です。
このような非正規化のテーブルを正規化することで、データの重複を排除し、不整合性(矛盾)が発生しないテーブル設計ができます。
正規形の種類と手順
正規形の種類
正規形には第1正規形から第5正規形までの5種類と、ボイスコッド正規形を合わせた6種類があります。
順にテーブルの正規化を実行することでデータの整合性が高まり、DB設計が良化します。
基本的にデータベースの正規化で重要とされている正規形は、第1正規形から第3正規形までなので、今回は第1正規形から第3正規形までをまとめておきたいと思います。
第1正規形
第1正規形はスカラ値の原則に基づいて正規化します。
スカラ値の原則とは、1つのセルに1つの値のみ設定されている状態のことを指します。
テーブルを作成する際は、1つのセルに1つの値のみ格納されるようになっていれば、第1正規形の第一条件を満たしていると捉えて大丈夫だと思います。
何故、スカラ値の原則を厳守すべきかというと、セルに複数の値を許してしまった場合、主キーが各列の値を一意に決定できない為です。
上記の条件を満たした上で、第一正規形では、繰返し項目の分離、導出項目の削除という作業を行います。
第2正規形
主キーの一部によって一意に決まる項目を別のテーブルに分離します。
テーブルのすべての候補キーにおいて、部分関数従属性という状態を解消し、完全関数従属性のみに整理します。
第3正規形
主キー以外の項目で従属関係がある場合に別の表に分離します。
推移的関数従属性という状態を解消します。
正規化の手順
基本的にデータベースの正規化は、下記のように第1正規形から第3正規形までの3段階に分けて行います。
1.第1正規形
繰返し項目の分離と導出項目の削除
2.第2正規形
部分関数従属性の解消
3.第3正規形
推移的関数従属性の解消
第3正規形まで正規化して設計する目的は、冗長性を排除することによって更新時異状(矛盾)を回避し、データベースの一貫性を確保するためです。
正規化の具体例
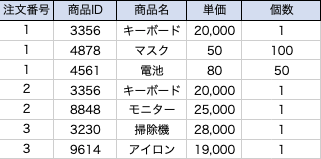
下記のような購入履歴テーブル(非正規化)を仮定して、正規化を行いたいと思います。

1.第一正規化
第一正規化では、繰返し項目の分離、導出項目の削除という作業を行います。
購入履歴テーブルでは、商品ID~金額までが繰返し項目であり、これらのデータを別テーブルに分離します。
また、導出項目の削除という作業では、金額カラム、合計金額カラムが該当します。
金額と合計金額は、単価×個数で算出可能なので削除します。
第一正規化後のテーブルは下記の通りです。
注文履歴テーブル

注文詳細テーブル
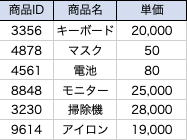
第二正規化
第2正規形は、主キー以外の項目(非キー)の情報に依存している(部分従属関係にある)データの分離を行います。
今回の場合では、注文詳細テーブルのうち、[商品名、単価]は商品ID(非キー)によって一意に決まるので、分離対象となります。
注文詳細テーブル

商品テーブル
第3正規化
主キーに依存しているが、データとして独立できるデータを別のテーブルに分離します。
テーブル内の非キー属性->非キー属性の関数従属、つまり推移関数従属性を排除します。
今回の場合では、注文履歴テーブルのうち、[購入者名、年齢、住所、電話番号]は購入者IDによって一意に決まるので別テーブルに分離します。
注文履歴テーブル
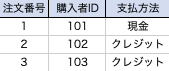
購入者テーブル

注文詳細テーブル
商品テーブル
最終的には、上記4つのテーブルが作成されます。
補足 正規化で使われる用語 まとめ
候補キーとは
候補キーとはテーブル上で任意のレコードを特定するためのカラムの集合です。
つまり、主キーやユニークキーのことを指します。
非キー属性とは
候補キーに含まれないカラムのことを指します。
関数従属性とは
あるレコードにおいて、特定のカラムAの値が決まれば、別のカラムBも特定できるような関係のことを指します。
この場合、カラムBはカラムAに関数従属しているといえます。
この時、カラムAを決定項、カラムBを被決定項と呼びます。
~例~
従業員IDを確認すれば、従業員名を特定することができる状態のことを指します。
| 従業員ID | 従業員名 | 年齢 |
|---|---|---|
| 001 | 田中 | 24 |
| 002 | 鈴木 | 35 |
上記のようなテーブルがあると仮定すると、従業員を一意に識別する従業員IDを[001]と指定すれば、1レコード目のデータであり、従業員名は田中、年齢は24と決まります。
つまり、従業員IDが決まれば従業員名と年齢が決まります。
これを関数従属性と呼び、従業員ID->年齢や従業員ID->従業員名と表現されます。
・繰り返し項目の分離とは
繰り返し項目とは、関連性のある2つのデータXとYがあった際、Xに対してYの値が複数存在することを指します。
そのような項目は、元テーブル上で主キーであるカラムを外部キー制約として別テーブルに分離したデータ(繰り返し項目)と紐付けて別テーブル上で管理します。
・導出項目の削除とは
導出項目とは、同じテーブルの中で、「値が他のカラムから導くことができる」値のことを指します。
例えば、消費税項目の値は、合計金額項目に消費税10%として0.1をかけることで値を求めることができます。
この消費税項目のような項目を、導出項目と呼び、正規化を行う際は、このような余分な項目を削除していく必要があります。
部分関数従属性とは
候補キーの一部に関数従属している状態を「部分関数従属している」といいます。
~例~
購入者テーブル
| 商品ID | 購入者ID | 購入者名 |
|---|---|---|
| 1 | 001 | 田中 |
| 2 | 003 | 鈴木 |
| 3 | 005 | 佐藤 |
| 上記のようなテーブルがあったと仮定すると、候補キー{商品ID、購入者ID}の一部である購入者IDに購入者名が関数従属しています。 |
このように、候補キーの一部に関数従属している状態を「部分関数従属している」といいます。
推移関数従属性とは
すべての列が主キーに従属していて、関数従属性が推移的に行われる、[1]X(主キー)→Y、[2]Y→Z、(かつX→Zでは無い)を全て満たす性質を、推移的関数従属性といいます。
要は、主キーに従属している主キー以外のカラムで関数従属があるということです。
~例~
購入者テーブル
| 社員ID | 名前 | 部署ID | 部署名 |
|---|---|---|---|
| 1 | 田中 | 001 | 経理 |
| 2 | 鈴木 | 003 | 人事 |
| 3 | 佐藤 | 005 | 営業 |
| 上記のようなテーブルでは、全てのカラムが社員ID[主キー]に従属しています。 | |||
| しかし{部署ID}->{部署名}では関数従属となっています。 |
つまり、社員ID[主キー]->{部署ID}->{部署名}という推移的関数従属になっています。
この{部署ID}->{部署名}を別テーブルに分離することで推移関数従属性は解消されます。