この資料は2019年ウォンテッドリーの新人研修資料です。インフラ研修における「Production Ready」の考え方についてまとめたものです。マイクロサービス化が進む中で、個々人またはチームで自信を持ってローンチして、コア・バリューの体験をちゃんとユーザに届けるための最低限品質を確保するための考え方です。
はじめに
弊社では、1つの施策に対して仮説検証や新機能、分析などのマイクロサービスがいくつかリリースされます。リリースするためには、Production Readyとして運用できることが求められます。サービス開発者や新しいメンバーにとって基準となるドキュメントがないとProduction Readyな環境を実現することは難しいです。 こういった分野について、SRE本では、Production Readiness Review(PRR)があります。これらのドキュメントを読むことで、レビューとレビュアーは品質を確認することができます。
Why Production Ready?
成長中のサービスは、さまざまな要因でエンジニアの期待どおりにコードを動かすことが難しいです。成長中のサービスの場合、「データ量」・「トラフィック量」の増加、「インフラの増強」、「他マイクロサービスのローンチ」、「スパイク」などによる状況が常に変わります。そのような環境下では、突然あるAPIに繋がらない、DBのタイムアウト、想定外の同時アクセスで過負荷や障害が発生します。このようなさまざまな要因から書いたコードが常に期待どおりに動くとは限りません。
そのため、うまくコードを動かす仕組みをインフラチームや運用チームが責任をもつことが多いでしょう。うまくコードを動かすとは、どういう状態を期待しているのかを言語化し、そのために必要なマシンリソースを考え、適切な運用を行います。
SREはPRRを通じ、プロダクション環境におけるサービスの信頼性を保証するために自分たちが学んだことや経験を適用しようと努力します。PRRは、SREチームがサービスのプロダクション環境での管理を引き受けるための必要条件と見なされています。
抜粋: Betsy Beyer; Chris Jones; Jennifer Petoff; Niall Richard Murphy. SRE サイトリライアビリティエンジニアリング.
PRRは、非常によくまとめられているため学びが多いですが、そのまま反映させるのは組織の規模が違いすぎて実用的ではありません。そこで自社用としてProduction Readyとして、ローンチコーディネーションチェックとモニタリングをドキュメントにします。
ローンチコーディネーションチェック
弊社では、専任のリリースエンジニアはおらず、ドキュメントとテンプレートを使ってセルフサービスでデプロイまで行い、ローンチ前にインフラチームでProduction Readyかどうかを確認することが多いです。確認することは、まとめると次の項目になります。
- Why
- そのサービスが生まれるまでの背景はなにか
- そのサービスのコア・バリューはなにか
- そのサービスの重要なエンドポイントはなにか
- 価値を満たすためのパフォーマンスはどのくらいか
- アーキテクチャの概要
- そのサービスは、どんな依存関係をもつアーキテクチャか
- そのサービスは、他のマイクロサービスから依存されるアーキテクチャか
- そのサービスのスケールポイントはどこか
- そのサービスは、何を重視したアーキテクチャか(トラフィック、I/O、レイテンシー、データ量、オーダー)
- 自動化と手作業のタスク
- そのサービスは、CI/CDが整っているか
- そのサービスのBatch処理(Cronjobか手動か)はなにか
- そのサービスは、カナリアリリースできるか
- そのサービスは、障害復旧方法はまとまっているか
- トラフィック量の推定、キャパシティ、パフォーマンス
- そのサービスは、どのくらいトラフィックが流れる予定なのか
- そのサービスのCPU/Memoryのキャパシティプランはあるか
- そのサービスは、何をトリガーに何をオートスケールさせるか
- そのサービスがオートスケールを行った場合に、次にボトルネックになるところはどこか
- そのサービスのストレステストによる限界値がわかっているか
- システムの信頼性とフェイルオーバー
- そのサービスの関連サービス・マネージドサービスの障害時に何が起こるか
- ミドルウェアとしてマネージドサービスを利用する際のデータのバックアップ/リストアはあるか
- 構成するサーバのバックエンドの関係
- バックエンドが過負荷の場合における対処はどうするか
- クライアントやユーザーに影響を与えずに終了もしくは再起動する方法があるか
- タイムアウト、リトライ、エラー処理は設計されているか
- モニタリングとサーバー管理
- そのサービスの内部状態のモニタリングはされているか
- そのサービスのエンドツーエンドの挙動のモニタリングはされているか
- そのサービスのアラートの管理はされているか
- そのサービスにおけるビジネスKPIに関連するモニタリングはされているか
- 成長に関連する問題
- そのサービスの次のキャパシティプランニングはいつどういう状態で行うか
- そのサービスのリクエストとデータが3,5,10倍に耐えられるか
モニタリング
モニタリング 101
ユーザに価値を提供できている状態をモニタリングとアラートで管理します。はじめに考えることは、ユーザ視点での監視をするところからです。「なぜ問題が起きているか」はわからないけど、「どんな問題が起きているか」が分かる状態になり、ふりかえりの際に必要に応じて改善ができます。入門 監視が非常に参考になります。
- そもそもアクセスできるか(死活監視)
- エンドポイントのHTTP レスポンスコードは意図したものになっているか(エラーレート)
- リクエスト時間は想定どおりの時間か(レイテンシ)
- エラーはどんなものか(Exception Monitoring)
- 適切に知らせてくれるか(On-call)
エンドポイントについて、闇雲に設定しても効果がないため必要な箇所にフォーカスします。ビジネス上やユーザのコアな体験となる部分を中心に設定します。これらは、ビジネスKPIとなっていることが多いです。たとえば、次のようなものです。
- ユーザーのログインと新規登録
- 募集を閲覧できる
- 応募ができる
- メッセージが送れる
- コア・バリューから守る
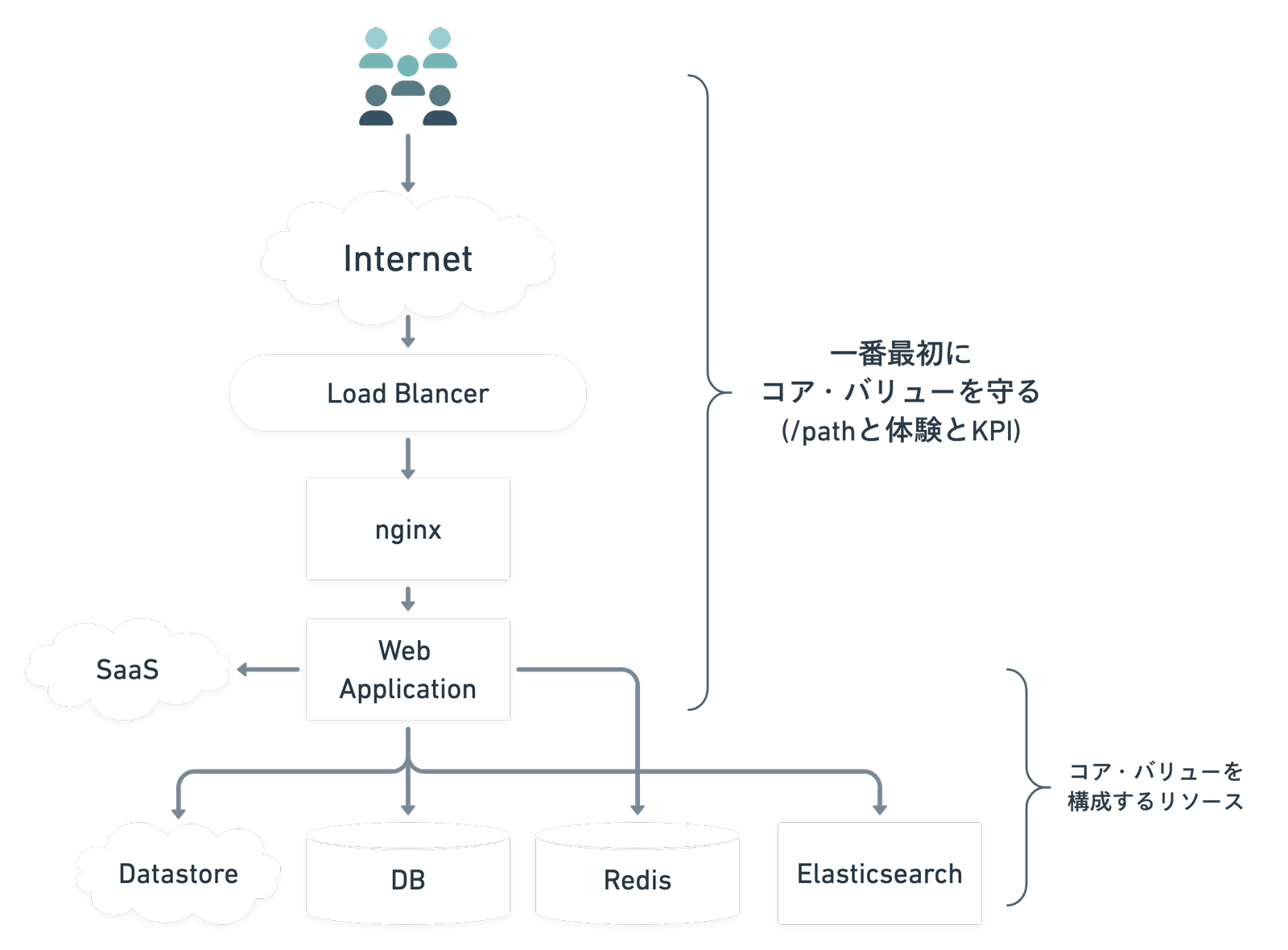
深掘りする
Datadogのblogを参考に、深掘りしてアラートを設定していくと、今問題になっている部分の根本原因を分析することができます。次の図を元に考えていきます。
問題のブレイクダウン
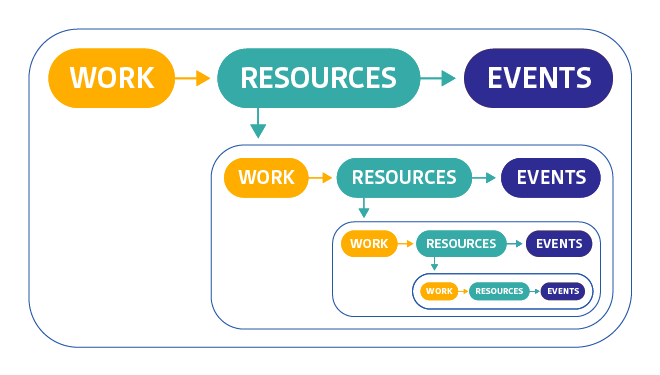
- Work
- システムのトップレベルの健全性
- Resource
- システムが依存しているリソースの使用率、飽和度、エラー、または可用性を定量化
- Events
- コード変更、内部アラート、スケーリングイベントなど、システム内のイベント
コアな体験を行うエンドポイントでアラートが発生したときを想定して、深掘りできるようにモニタリングを設定します。
- Work(/path)から見る
- レスポンスタイム < 150ms
- Error Rate < 5%
- Workが依存するResourceを確認
- WebのCPUやメモリやpod数やリクエスト数
- External ServiceのResponse
- ElastiCacheのResponse
- ElasticsearchのResponse
- Eventsを見る
- Deployやその他アラート通知
- Jobが大量発生してないか見る
- Resourceから後続のWorkと相関していそうなResourceを見つける
- External ServiceのWork
- ElastiCacheのcache hit率やメモリやCPU等
- ElasticsearchのCPUやメモリ等
モニタリングで用意すること
問題に対して、原因・分析・改善を行うために、さまざまなツールを駆使します。必要なことは「何が起きたか?」、「なぜ起きたか?」という2つの疑問に答えることが必要です。これらを実現するために次の構成が必要になります。
| 症状 | 原因 |
|---|---|
| HTTP 5xx 100% | データベースサーバーが接続を拒否している |
| レスポンスの速度低下 | 同時アクセスの量を越えるアクセスが来て、スケールアウトが間に合わず待ち時間がかかっている |
| 特定ユーザーでエラー画面になる | オーダーが想定の10倍の負荷を与えるユーザのため、レスポンスを返せずタイムアウト |
期間を指定して分析できるか
- データベースはどういったペースで大きくなってきているのか
- リクエスト数のトレンドはどうなっているか
- 日次のアクティブユーザーの増加のペースはどうなっているか
グループ間での比較ができるか
- ヒット率の推移とサイトの速度は相関して落ちていないか
- リクエストの流れが把握できるか
アラートとして検知できるか
- 何かが壊れていて、誰かがすぐに修復しなければならないか
- もうすぐ何かが壊れるかもしれないから、誰かが早めに確認すべきか
ダッシュボードはいつでも見られるか
- サービスに関する基本的な疑問に答えられる状態か
- 通知が来たときに役に立つ情報がまとまっているか
- レイテンシ
- リクエストを処理してレスポンスを返すまでにかかる時間が分かるか
- 処理の内容がアプリケーション、ミドルウェア、外部サービスなのか分かるか
- テイルレイテンシを把握できるか
- トラフィック
- リクエスト数、セッション数、キュー、トランザクションはいくらか、
- エラーレート
- 5xxの割合はいくらか
- サチュレーション(飽和状態)
- メモリ使用率、I/O、ディスク、同時アクセス数、Pod数
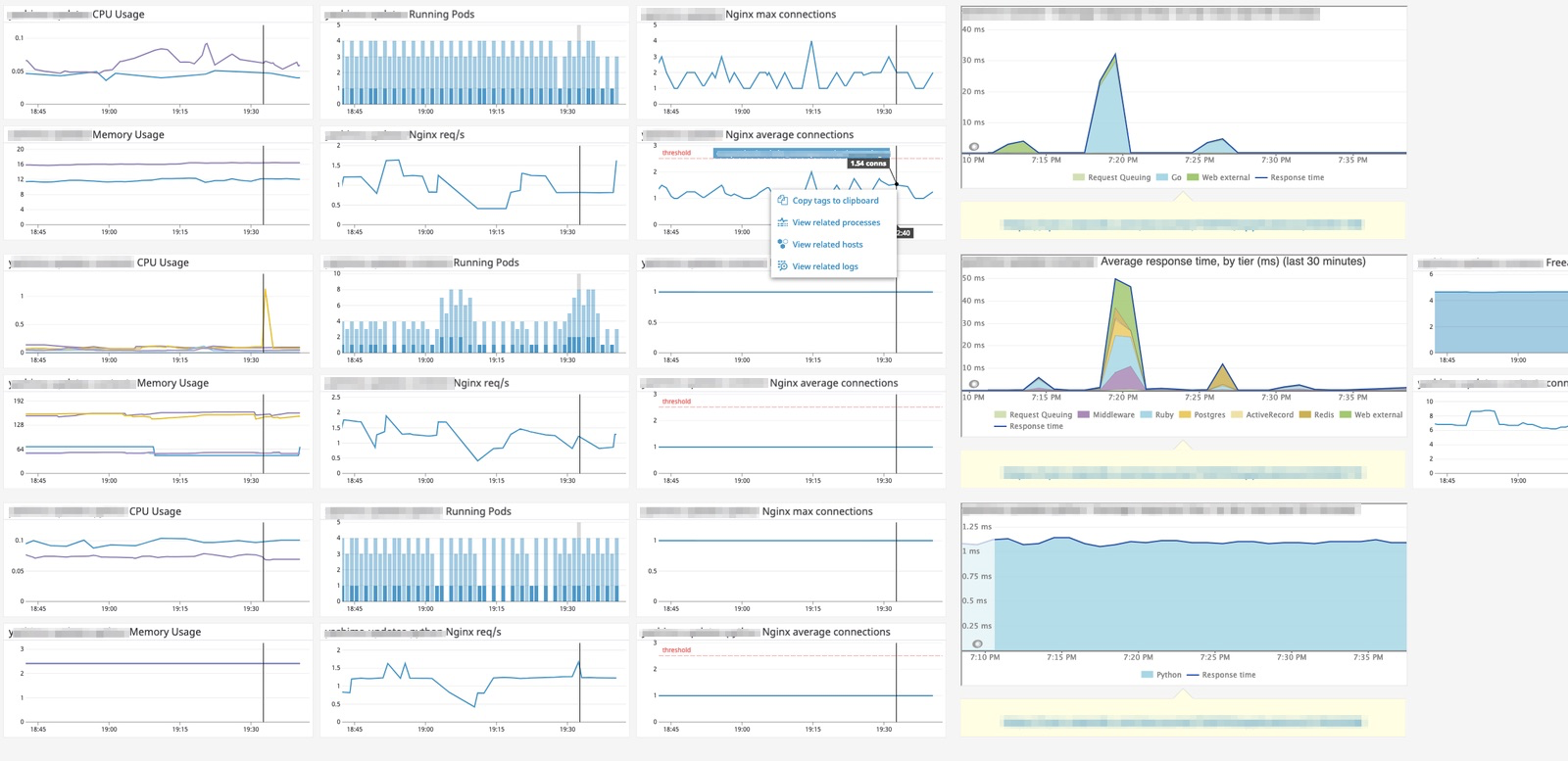
トリアージ可能になっているか
- まとめて障害起きたときに優先順位がつけられるか
- レイテンシが急上昇したが、他に何か相関して悪くなっていないか?
リクエストの流れが分かるか?
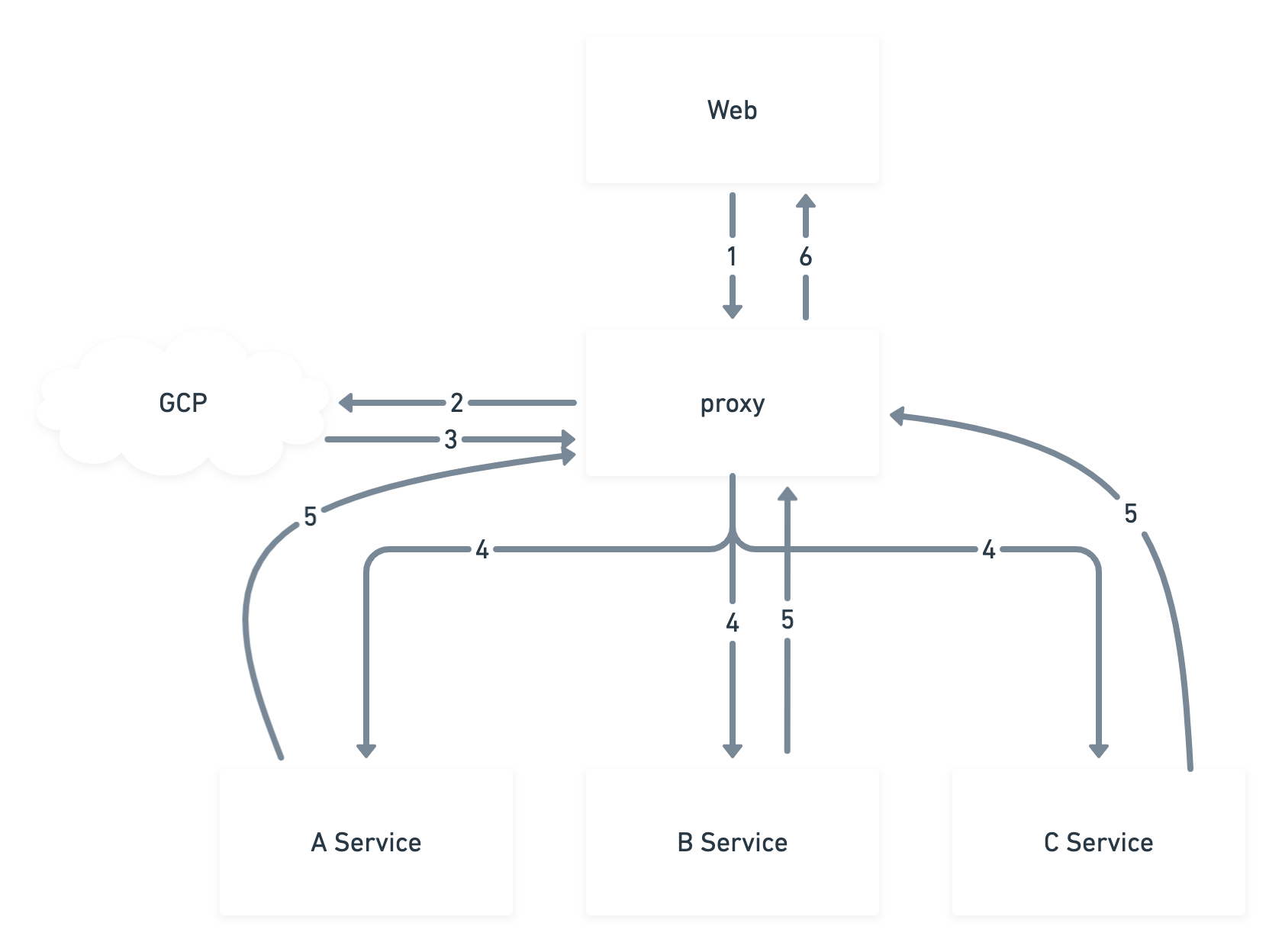
マイクロサービス化が進むとリクエストがどこから来ているのかを把握することが難しくなり、またFault Toleranceな設計にするほどどのくらい問題なのかがわかりにくくなります。リクエストの流れを把握するために、分散トレーシングを使って表現します。また統計的にエラーの数を把握するために、ログから分析できる基盤を作って確認します。
Production Readyチェックリスト
- コア・バリューの体験はなにか
- コア・バリューのエンドポイントはどこか
- KPIに紐づくモニタリングはされているか
-
コア・バリューを体験するためには、どういう状態が必要か
- レスポンスコード 200
- レスポンス時間が XX ms 以内
- Cacheなどのデータが必要か
- Push通知によるスパイクにも耐えられる
- コア・バリューを体験できない場合、どうなるか
- SLIの優先順位に変わりはないか
- SLIの変更が必要か
- 依存関係はあるか(Redisなどのcache用途が使えないだけで落ちたりしないか)
- 依存されてしまうサービスはないか(このサービスが落ちると他のサービスが落ちたりしないか)
-
社内共通ライブラリを導入しているか
- ログの送信
- モニタリングツール設定
- 分散トレーシングの調査方法
- ストレステストが行われているか
- 想定リクエストを把握しているか
-
1Podあたりの同時アクセスはいくつか
- worker 数
- process 数
- HPA(Autoscale)の設定がされているか
- アーキテクチャのどこからボトルネックを迎えるか
- キャパシティプランニングはいつ行うか
- マネージドサービスのバックアップ・リストア
-
障害復旧方法
- restart 可能か、起動順序があるか
- scale させることができるか
- 縮退運転可能か
-
New Relic Application Monitoring
- 処理内容に、アプリケーション、ミドルウェア、トランザクション、外部サービスと区別されているか
- 死活監視
- Error Rate 何%か
- Apdex スコアはいくつか
- 期待するresponse timeはいくらか
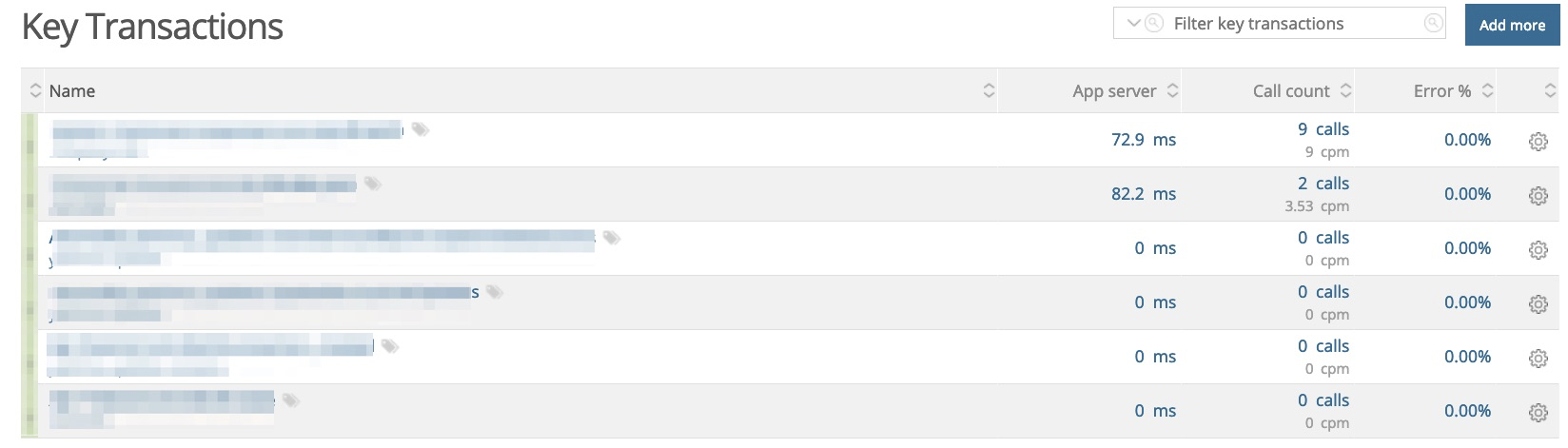
- 重要エンドポイントのKey transactionの設定
- 通知先が適切か
-
Datadog System Monitoring
- マネージドサービスの追加が漏れていないか
- 内部の死活監視ができているか
- Dashboardに追加しているか
-
PagerDuty Notification and On-call
- 通知を受け取りたい場合に必要
-
Honey Badger Exception Monitoring
- 適切にエラーを受信しているか
- error 数のアラートは設定されているか
おわりに
マイクロサービスが進むと一見複雑に見えますが、このような品質を守ることで、1つ1つがPOC・MVPを得て、Production Readyなシンプルなアーキテクチャの集合体になります。守られそうにないと感じたらJohn Gallの「発想の法則」が原点に立ち返らせてくれます。最後にご紹介して終わりにします。
“A complex system that works is invariably found to have evolved from a simple system that worked. A complex system designed from scratch never works and cannot be patched up to make it work. You have to start over with a working simple system. ”
"正常に動作する複雑なシステムは、例外なく正常に動作する単純なシステムから発展したものである。ゼロから作り出された複雑なシステムが正常に動作することはなく、またそれを修正して動作させるようにもできない。正常に動作する単純なシステムから構築を始めなければならない。"