元記事
Python学習記録_プログラミングガチ初心者がKaggle参加を目指す日記
7日目です。
ざっくりと決定木の実装の仕方とかを見れてモチベーションが回復した状態なのでゴリゴリ進めていきたいところです。
今日も頑張りましょう。
グリッドサーチでハイパーパラメータを最適化 25m
これは4日目にやったグリッドサーチの発展編ですね。
たしかハイパーパラメータなるものの最適な値を見つけてくれる、とかそんな感じだったかと。
まあ見ていった方が早そうですね
ハイパーパラメータとは
機械学習のアルゴリズムにおいて、人が調整する必要のあるパラメータのことをハイパーパラメータと呼びます。
このハイパーパラメータは学習の時には決定されませんので人が調整する必要があります。
この章では、scikit-learnに実装されている GridSearchCVを使ってハイパーパラメータを最適化します。
グリッドサーチ
グリッドサーチはハイパーパラメータの候補を指定し、それぞれのハイパーパラメータで学習を行いテストデータセットに対する予測がもっとも良い値を選択する手法です。
代表的なチューニング方法としてグリッドサーチ以外にもランダムサーチと呼ばれる手法もありますがこの章ではグリッドサーチのみを説明します。
サンプルプログラム
scikit-learnではGridSearchCVを使うことで利用可能です。
GridSearchCVの引数には、分類器とハイパーパラメータの候補を渡します。
その上でデータセットに対して学習 (fit) させることで、最も汎化性能の高い組み合わせを得ることが出来ます。(best_params_に代入されます。)
また合わせて交差検証を組み合わせる方法は今後もよく使用しますので合わせて押さえておきましょう。
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
dataset = datasets.load_iris()
X = dataset.data
y = dataset.target
model = DecisionTreeClassifier()
# 試行するパラメータの羅列
params = {
'max_depth': list(range(1, 20)),
'criterion': ['gini', 'entropy'],
}
# cv=10は10分割の交差検証を実行
grid_search = GridSearchCV(model, param_grid=params, cv=10)
grid_search.fit(X, y)
print(grid_search.best_score_) # 最も良かったスコアを出力
print(grid_search.best_estimator_) # 最適なモデルを出力
print(grid_search.best_params_) # 上記を記録したパラメータの組み合わせを出力
0.96
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=3,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter='best')
{'criterion': 'gini', 'max_depth': 3}
…なるほど、前回決定木のお勉強をした際の例文には載ってませんでしたが
実際に使う時にはこんな形でparamsを指定してあげる必要があると…
その最適値を見つけてくれるのがグリッドサーチで、これを使うことで
このパラメータは○○、このパラメータは△△、このパラメータは××に設定するとスコアが一番よくなるよ!
って教えてくれると
人が調整する必要があるパラメータって言ってましたがここの調整すらも機会がやってくれるんですね、すげー…
NumPy応用 30m
numpyの実用的な関数の紹介。
実務的な話になりそう。
ユニバーサル関数
ユニバーサル関数(universal function / ufunc)とは、全要素のndarrayを対象に演算等の操作を行い、その結果をndarrayで返す関数です。
指数関数(exp)や平方根(sqrt)などの様々な数学関数を扱うことができます。
ndarrayっていうのはnumpyで扱うデータ構造のことで、リストとの違いはざっくり言って処理がめちゃくちゃ早いこと…らしいです。
ユニバーサル関数ってやつを使うとこの配列全体を対象に計算やらなんやらをしてくれて
さらに結果も配列で返してくれる便利な関数のこと、という理解。
で、ここからはどんな関数があるのかを紹介していく感じですね。
import numpy as np
sample_data = np.arange(10)
print(np.sqrt(sample_data))
print(np.exp(sample_data))
sample_multi_array_data1 = np.arange(9).reshape(3,3)
print(sample_multi_array_data1)
print("平均:",sample_multi_array_data1.mean())
print("最大値:",sample_multi_array_data1.max())
print("合計:",sample_multi_array_data1.sum())
print("列の合計:",sample_multi_array_data1.sum(axis=0))
print("行の合計:",sample_multi_array_data1.sum(axis=1))
[0. 1. 1.41421356 1.73205081 2. 2.23606798
2.44948974 2.64575131 2.82842712 3. ]
[1.00000000e+00 2.71828183e+00 7.38905610e+00 2.00855369e+01
5.45981500e+01 1.48413159e+02 4.03428793e+02 1.09663316e+03
2.98095799e+03 8.10308393e+03]
[[0 1 2]
[3 4 5]
[6 7 8]]
平均: 4.0
最大値: 8
合計: 36
列の合計: [ 9 12 15]
行の合計: [ 3 12 21]
sqrtは平方根を返してくれてexpは指数関数を返してくれるユニバーサル関数。
ユニバーサルなので配列を引数に指定すると配列で返してくれる、っていうデモなのかなこれは。
sumも普通に使うだけだと要素全部の合計を出すけどこいつもじつはユニバってるのでaxis(0で列ごと、1で行ごと)を指定すると配列で返してくれると。
ちなみにaxisは和約で軸という意味。へー
anyとall
anyとallを利用することで、要素に不正な値が含まれているか、期待する結果になっているか調べることが出来ます。
anyは対象となる範囲で、1つでもTrueがある場合にTrueを返します。
anyの返り値は、bool値を要素にもつ配列が返ります。
bool値ってなんだよ…
ブール値 (bool値)とは
用語の中身としては
「そうだよ!(真:true)」か「違うよ!(偽:false)」のどちらかが入ってますよ!な値のこと
なるほど、TrueかFalseで表せるやつがbool値ですね。
import numpy as np
a = np.random.randint(6, size=(2,3))
print(a)
d = np.any(a==2, keepdims=True)
print(d)
[[0 4 1]
[3 1 0]]
[[False]]
ぱっと見た感じだと値がFalse1つしか入ってないので配列感はないんですが要素が一つしかなくても配列になると。
ところでしれっと出てきてるkeepdimsってなんだコレ
keepdimsは要素が1となった次元でも削除したりせずにそのまま保持しておくように指定できる引数です。
他のページも見てみましたがざっくり次元数を保持しておくためのものらしいです。
これを入れておかないといけない理由が今のところ分からないですがきっとのちのちわかることなんでしょう、うん。
次にallを見ていきます。
allは配列を引数に渡すことで、bool値を要素に持つ配列を返します。
axisには、条件の検索範囲を指定し、その結果を格納する先をoutで指定します。
出力を配列と同じ次元にする場合、keepdimsを指定します。
import numpy as np
a = np.array([0,1,1])
b = np.array([1,1,1])
print(np.all(a))
print(np.all(b))
c = np.array([
[0,0,1],
[1,1,2],
[0,1,2]
])
d = np.all(c, axis=0)
d2 = np.all(c, axis=1)
print(d)
print(d2)
False
True
[False False True]
[False True False]
…なんのこっちゃコレ……
anyがどれか一つでも○○っていう条件にTrueかFalseを返す関数ならallも条件設定必要じゃないのか…?
出力結果見る感じ0が含まれてなければTrueになってるっぽいんだけど
何も条件指定しなければそういう条件設定になるのがallなのか…?
NumPy配列の全要素が条件を満たすか確認するall()の使い方
Pythonでは、数値の 0 は ブール値 False と同値です。そのため、渡した配列の中に数値の 0 が 含まれている場合も、False と判定されます。
知らんわ!!!
初出の情報を当たり前のように予備知識として求められてきてます。つらい。
ちなみに条件設定ももちろんできるみたいで
import numpy as np
c = np.array([
[0,0,1],
[1,1,2],
[0,1,2]
])
d = np.all(c>0, axis=0)
d2 = np.all(c>0, axis=1)
print(d)
print(d2)
[False False True]
[False True False]
こうしてあげれば全てに1以上の値が入ってるもの、みたいな指定の仕方ができるようです。
逆に何も条件設定をしなかった場合、0が含まれてるかどうかではなくFalseがあるかどうかを見るみたいです。
random
numpy.randomのrand関数は、乱数を生成できます。
numpy.random.rand() で 0〜1 の一様乱数を生成します。
引数を指定すれば複数の乱数を生成できます。
import numpy as np
np.random.rand() # 0〜1の乱数を1個生成
token = np.random.rand(100) # 0〜1の乱数を100個生成
print(token)
token2 = np.random.rand(10,10) # 0〜1の乱数で 10x10 の行列を生成
print(token2)
token3 = np.random.rand(100) * 40 + 30 # 30〜70の乱数を100個生成
print(token3)
引数を一つだけ指定すると個数、2つ指定すると配列の構造を指定できると。
一番下の30~70の乱数を作るやつとかちょっと面白いですね。
randには色々種類があって
randn()→平均0、標準偏差1の乱数
normal(a,b)→平均がa、標準偏差がbの正規分布
poisson(lam=a)→λ=aのポアソン分布
randint()→整数値で乱数
等々あるようです。
copy()
配列を書き換えたり成形したりする際、オリジナルのデータを残しておきたい場合はcopy()を使い、新しい配列にオリジナルのデータをコピーして使います
import numpy as np
x = np.arange(10)
array_copy = np.copy(x)
zeros()
すべての要素が0の配列を生成します。
import numpy as np
zero_array = np.zeros(10) #[0,0,0,0,0,0,0,0,0,0]
linspace()
linspace(start, stop, n)はある範囲start~stopをn等分したデータを生成したい場合に使えます。
例えばlinspace (0,100,1000)で1から100までの範囲を1000等分したデータが生成されます。
つまり、0~100の区間を0.1ずつ刻んだ点(0.1, 0.2, 0.3, …, 99.9, 100)が生成されるということです。
また、endpointにFalseを渡すことで、stopを含まないデータが生成されます。
import numpy as np
data = np.linspace(0, 100, 10)
print(data)
data2 = np.linspace(0, 100, 10, endpoint=False)
print(data2)
[ 0. 11.11111111 22.22222222 33.33333333 44.44444444
55.55555556 66.66666667 77.77777778 88.88888889 100. ]
[ 0. 10. 20. 30. 40. 50. 60. 70. 80. 90.]
vstackとhstack
Numpy の vstackとhstackは配列を連結することができます。
vstackは配列を縦(vstack)に連結し、hstack は横(hstack)に連結します。
import numpy as np
data1 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
data2 = np.array([[11, 12, 13], [14, 15, 16], [17, 18, 19]])
print(np.vstack((data1, data2)))
print(np.hstack((data1, data2)))
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[11 12 13]
[14 15 16]
[17 18 19]]
[[ 1 2 3 11 12 13]
[ 4 5 6 14 15 16]
[ 7 8 9 17 18 19]]
これは便利そう。
結合条件とか設定できる関数とかもありそうですね…
というかコレあったら便利そうだなーって関数はもうだいたい組まれてるんだろうなと思います。
Seaborn入門 25m
Seabornとは
Seaborn (シーボーン) はPythonの可視化ライブラリの一つです。
SeabornはMatplotlibの機能をより美しく、より簡単に実現するための可視化ライブラリです。
Seabornの特徴として、Matplotlibベースで作られているため、折れ線グラフや棒グラフ、散布図などの基本的なグラフ描画はMatplotlibの機能を利用していることが挙げられます。
Matplotlibとの使い分け
SeabornはMatplotlibに比べ綺麗に描画でき、基本的に同じような描画が可能です。
そのため両者を使い分ける際に参考にすると良いのが、描画したい内容をSeabornの関数で用意されてるのであればSeabornを使い、用意されていなのであればMatplotlibを使うと良いです。
つまり綺麗さ特化したのがSeaborn、機能特化したのがMatplotlibみたいな感じですね。
散布図行列
まずはチュートリアルとして、Seabornがあらかじめ用意してあるデータを使って可視化をしていきます。
今回はアイリスデータに対して、散布図行列で可視化します。
散布図行列とは複数の変数がある場合に、全ての2変数同士の組み合わせに対して散布図を作成し、行列の形式に並べたものです。
散布図行列は、複数の変数の相関関係を視覚的に捉えることができます。
Seabornで散布図行列を可視化する場合、pairplot()を用います。
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
iris = sns.load_dataset("iris")
sns.pairplot(iris, hue="species")
plt.show()
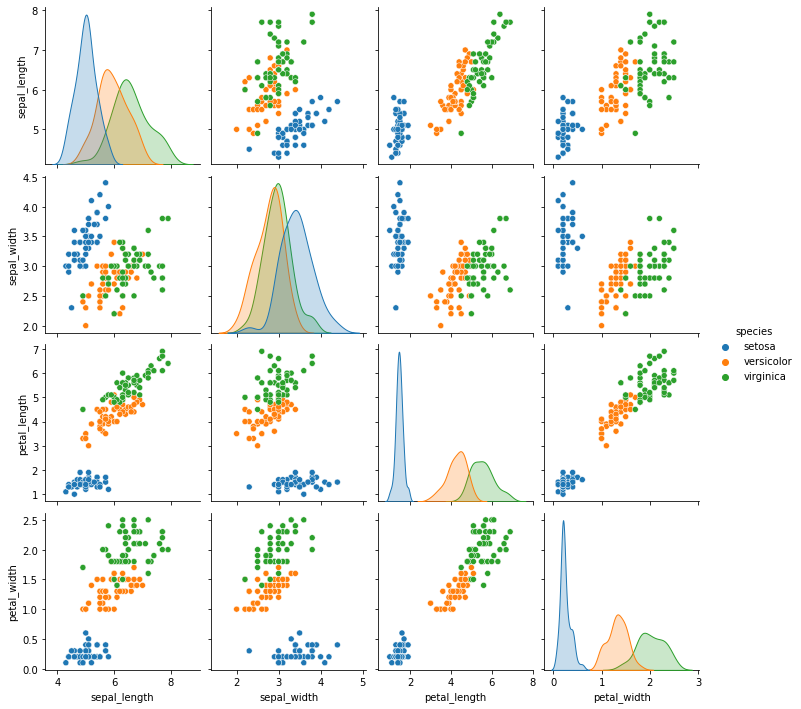
しゅんごい…
これ以前手動で作ったことあるんですけどすごい面倒だった記憶があります。
もうこの機能だけでかなり魅力感じますね、色々な業務の効率化ができそうです…
他にもいろんなメソッドありましたがmatplotlibのところと同じようなものばかりだったので割愛。
とにかく全体的にくっきりしていて見やすさはたしかにこちらの方が上だなと思いましたが
最初の内はmatplotlibメインでやっていってもよさそうだなと感じました。
7日目の感想
numpyの実務的な関数やSeabornの散布図行列等の今の業務に活かせそう、取り入れられそうなものが多くややテンションがあがりました。
ただ当初の目的は既存の業務効率化ではなく機械学習のモデル作成をできるようになること、なので
そこは忘れずにやっていきたいと思います。
明日はpandasの応用とのことでこれも色々と楽しみです。
明日もがんばれ