元記事
Python学習記録_プログラミングガチ初心者がKaggle参加を目指す日記
こちらの2日目の学習内容まとめ。
前半は前提知識というか概念とかの話が多かったのでかなりサクサク進めることができました。
for文で思い切り躓きました。
これが独学の辛いところ…
scikit-learn 10m …
scikit-learnとは
scikit-learn(サイキット・ラーン)はPython用の機械学習ライブラリです。
scikit-learnはオープンソースで公開されており、個人・商用問わず、誰でも無料で利用することが出来ます。
また、教師あり学習、教師なし学習に関するアルゴリズム(サポートベクターマシン、ランダムフォレスト、回帰、クラスタリングなど)が一通り利用出来る上、別章でも紹介しますがサンプルのデータセット(トイデータセットと呼びます)が豊富に揃っています。
そのためscikit-learnを用いるとすぐさま機械学習プログラミングを試すことが可能です。
ライブラリ…Choromeのアドインみたいに拡張機能を追加するものですかね
なぜscikit-learnを学ぶのか
なぜPythonを用いて機械学習を活用する際に、scikit-learnを学ぶのでしょうか。
それはscikit-learnは、Pythonで(統計的)機械学習プログラミングを行う場合、世界的にもデファクトスタンダードになっているからです。
scikit-learnは無料で利用する事が出来ますので、機械学習を扱うのであればしっかりと使いこなせるようにしましょう。
皆使ってるから使おうね!ってことですね
人工知能 15m …
人工知能とは
人工知能(Artificial Intelligence)とは、人間の知能をコンピュータで再現することです。
ここで押さえておきたいポイントとして、実際は専門家の中でも「人工知能」の定義が異なっています。
また「知能」とはどのような事を指すのでしょうか。
「知能」とは日常的に行なっている知的処理の事を指します。
例えば、ある動物を見て「この動物は可愛い」と感じたり、「あの場所に車が止まっている」などと「認識」したり、ある英語の試験の問題を解く際に、「この問題の答えはこれかな?」と「推論」したり、ある本を読んで「この文章は大変わかりやすい文章だなぁ」と「判断」したりするような事です。
人間の知的処理能力の場合、論理的に思考したり、五感(視覚、聴覚、臭覚、触覚、味覚)など様々な処理能力があります。
ですが、現在、人間のように考えるコンピュータはまだできていません。
現在の「人工知能(AI)」は人間の知的な活動の一面を模倣している技術を指しています。
機械学習のやることは認識・推論・判断の機能を機械に持たせること、という理解。
強いAIと弱いAI

AIは、「強いAI」と「弱いAI」という大きく2つにわけることができます。
弱いAIは、特化型人工知能(Narrow AI , Weak AI)と汎用人工知能(AGI / Artificial General Intelligence)に分けられます。
特化型人工知能とは、人間同等もしくは人間以上の特定の決まった作業を遂行するAIのことを指します。
例えば、囲碁のAlphaGo(DeepMind Inc)やチェスのAI、将棋のAIや自動運転車などです。
汎用型人工知能は、特定のタスクなどに限定せず、人間と同様もしくは人間以上の汎化能力を持ち合わせているAIのことを指します。
「強いAI」というのは、人間のように「心を持つ」AIのことです。
「強いAI」は、人間のように自意識や感情を持ち合わせています。
例えば、ドラえもん、鉄腕アトム、C-3POなどは「強いAI」に属されます。
「弱いAI」は、心を持つ必要はなく、限定された知能により、知的な問題解決ができるAIのことです。今あるAIは全てこの弱いAIに該当します。
現在、強いAI・汎用人工知能はまだ実用化されておらず、実用化されているのは、弱いAI・特化型AIのみです。
ペルソナ3のアイギスが強いAIですね、Fesでワイルド使えるようになるしいろんな意味で強い
機械学習の3つの種類 10m …
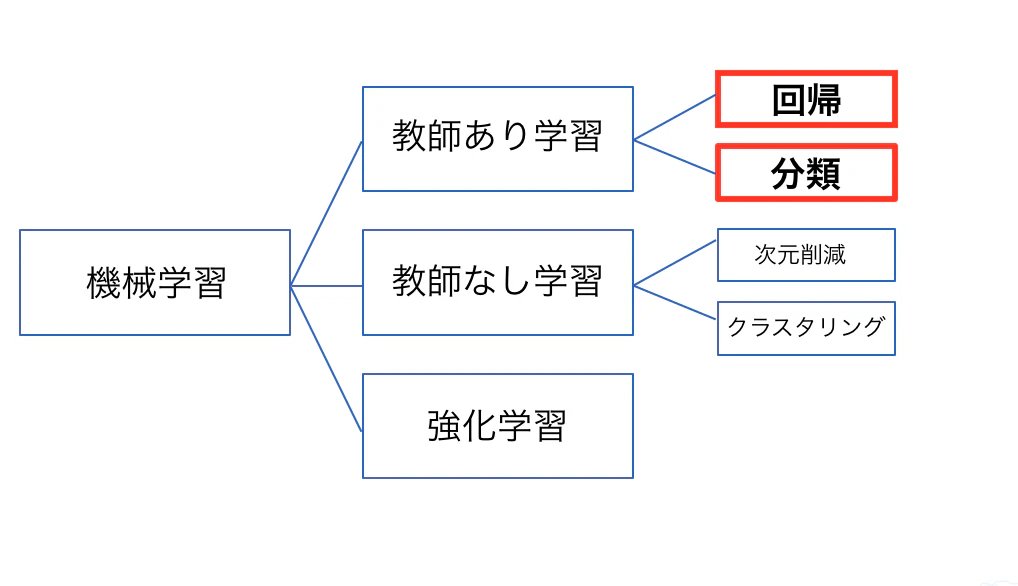
教師ありと教師なし学習
教師あり学習は未知のデータに対する予測を行います。(入出力の関係を学習)
この章では詳しくは触れませんが、教師なし学習は、正解データが与えられておらず、未知のデータから規則性を発見する手法です。
両者の教師あり学習と教師なし学習の違いは、ラベルづけされたデータがあるかないかです。
クラスタリング分析が教師なし、行動予測が教師ありみたいなイメージ
強化学習
強化学習(Reinforcement learning)とは、機械が試行錯誤して「価値を最大化するような行動」が何かを学習するものです。
教師あり学習とよく似た問題設定ですが、与えられた正解の出力をそのまま学習すれば良いわけではなく、一言で言えば、「価値」を最大化する行動を学習しなければなりません。
囲碁や将棋といったゲームは、本質的に将来の価値(つまり今その手を打つことにより、最終的に勝つのか負けるのか)を最大化することが目的なので、強化学習とは相性が良い問題です。
こういった「価値」を最大化することが強化学習の目的とされています。
売上だったりCVだったりの数字が高ければ高いほど良い系のものに相性が良い、ということなのか…
カードゲームのAIとか作れたら面白そうだけどデッキの内容と相手の札見て構築予想して…みたいに要素が沢山あるから難しそうでもある
分類と回帰 10m …
分類と回帰
機械学習の教師あり学習の手法には、分類と回帰の2種類に大別されます。
教師あり学習では、入出力の関係を学習し、未知のデータに対する予測を行います。
分類と回帰の違いとして、分類は離散値(クラス)を予測することで、回帰は連続値(数値)を予測します。
離散値というのは、0、1、2といった連続していない数値のことです
サイコロの出る目や、トランプのカードをランダムに1枚引いた時に出る数字の大きさなどです。
一方の連続値は、175cmという身長の場合、175.1cmや175.08cmなどもあり得ます。
このように連続値は、値と値の間に無限に数値を取りうる連続した数値を連続値と呼びます。
それぞれが予測する値
分類の目的は、データが属するクラス(犬 or 猫など)を予測することです。
予測するクラス数が2クラスの場合、2値分類と呼ばれます。
具体例として、個人ローン審査の場合、取引情報や個人信用情報などを入力とし、その人に融資を承認するか否かかを予測します。
2クラスより多い分類問題は、多クラス分類と呼ばれます。
実際には犬や猫を予測する場合、どちらかを0、もう一方を1などという数値に置き換えます。回帰の目的は、連続値の予測になります。
具体例として、部屋の広さから家賃を予測したり、過去の広告費用からクリック数を予測します。
機械学習の一連の流れ 5m …
機械学習の一連の流れをここでは説明します。
それと同時に、機械学習プロジェクトを行う上では、「機械学習で何をさせたいのか(ゴール設定)」を明確にすることが非常に重要です。
ゴールの設定(決定)の上で機械学習プロジェクトは以下のようなフローで案件は進められます。
(厳密には一連が上から下へ流れるというよりも、行ったり来たりします。)
- データを収集する
- データを理解する&データの前処理
(データクレンジングとも呼ばれ、データの重複やあるべきデータがない欠損データなどを取り除いてデータの精度を高めること。)- 特徴量、教師データの設計
- 機械学習アルゴリズムの選択と学習(機械学習)
- テストデータを使った性能評価
- ハイパーパラメーターチューニング
- サービスに組み込む
上記フローの中でも、データを集めることや、データを使える形に前処理するといった工程に非常に多くの時間が必要になります。
実際、機械学習を行っているのは4に当たります。
1,2の部分ではSQLを活かせそうですね。
4~6ができるようになりたいところだな、と再認識。
Python リスト型と辞書型 15m …
リスト型
変数は、1つのデータしか管理できませんでしたが、リスト型は複数のデータ(変数)を管理できます。
他の言語では配列と呼ばれたりします。
Pythonのlistは、格納する型の定義は必要ありません。
複数のデータを管理したい場合にリストを用います。
変数で型の宣言をする必要がないのと同様にリストにも宣言は不要と。
一つの箱に複数のデータを入れたい時に使うものっぽい。
リスト型を定義する
li=[10,20,30]
print(li)
# 出力結果[10, 20, 30]
li2=[10,"Hello",30.7]
print(li2)
# 出力結果[10, 'Hello', 30.7]
変数名=[値1,値2,値3…]
で指定することが可能。
1つのリストの中に異なるデータ型のものを格納することもできる。
リストの変数名をつける時の注意点
ざっくり言ってlistは関数名で存在するのでリスト型の名前つけるときに使っちゃいけないよ、という感じ。
最初に習った予約語の1種みたいなものだと思っておいた方が良さそう。
定義したリストから特定の要素を取り出す
要素とは定義したリストに格納された1つ1つの値の事です。
先ほど定義したリストliでは10,20,30の3つの要素を保持しております。
print()関数を用いた場合、全ての要素が出力されてしまいます。
リストを扱っていると全ての値ではなく、特定の要素のみを取り出したい事があるかと思います。
そのような時に用いられるのが添字になります。
添字はindexとも呼ばれ、要素の値に0から始まる番号で定義されています。
ここで1から数えるのではなく、0から始まる番号が割り当てられていることに中止しましょう。
li=[10,20,30]
print(li[0])
# 出力結果 10
li2=[10,"Hello",30.7]
print(li2[1])
# 出力結果 Hello
要素を指定して出力する時はprint(リスト名[添字])
リスト内の要素を指定して取り出すとき、文字列での検索はできないので注意。
(そのような使い方をしたい場合は↓の辞書型を使った方が良い?)
リストに要素を追加する
li=[10,20,30]
print(li)
# 出力結果[10, 20, 30]
li.append(40)
print(li)
# 出力結果[10, 20, 30, 40]
リストに要素を追加したい時には
要素名.append(追加要素)
でリストの末尾に要素を追加できる。
辞書型
辞書型(ディクショナリー型)とは、KeyとValueという2つの値をペアで保持するデータ型です。
リスト型はインデックス番号が0から始まり0から順に値が格納されていましたが、辞書型は{}を使い囲います。
その点は、辞書型と書き方は似ていますが、辞書型にはインデックス0から値が割り当てられていません。
そのため、リストはインデックス番号で値にアクセスできるのに対し、辞書型では任意のキー文字列で値にアクセスすることができます。
profile={"name":"tanaka","email":"test@xx"}
print(profile["name"])
# 出力結果 tanaka
辞書名={Key1:Value1,Key2:Value2,…}
で定義。
イメージとしてはkey名はカラム名って認識でいいのか…?
でも要素を追加(横に広げる)ことはできてもレコードの追加(縦に広げる)ができなさそうな予感…
辞書型に要素を追加する
profile={"name":"tanaka","email":"test@xx"}
print(profile["name"])
# 出力結果 tanaka
profile["gender"] = "male"
print(profile["gender"])
# 出力結果 male
要素を追加する際には
辞書名[Key] = Value
で追加可能。
リスト型でのappendのような書き方もあって
profile={"name":"tanaka","email":"test@xx"}
print(profile["name"])
# 出力結果 tanaka
profile.update({"gender":"male"})
print(profile["gender"])
# 出力結果 male
辞書名.update({Key:Value})
でも同様の処理が可能。updateって値の更新じゃないのか…
好みで使い分けして良いらしい。
リスト型と辞書型の違いと共通点
ざっくりまとめて、どちらも異なる型のデータを複数入れることができるということ。
違いは辞書型はキーで要素にアクセスしてリスト型は添字でアクセスすることとどのカッコを使うのか。
[]と{}の違いは覚えるまで苦労しそうな気配がしてますね…
辞書のKey指定する時に[]使うのがややこしすぎる…
演習問題
1.2017年から2021年までの要素を持ったyears_listという名前のリストを作ってください。
2.years_listから2020年を取り出して、printで出力してください。
3.years_listから2021年をprintで出力してください。
4.好きな文字列3つを要素にして、自由な変数名でリストを作ってください。
5.4で作った文字列3つを持つリストの末尾に新しく文字列を1つappend()を用いて追加してください。
6.名前と年齢のペアが3つある辞書型を作ってください。
(名前と年齢は自由につけてください)keyが名前で、valueが年齢とする
# 1
year_list=["2017年","2018年","2019年","2020年","2021年"]
print(year_list)
#出力結果 ['2017年', '2018年', '2019年', '2020年', '2021年']
# 2
year_list=["2017年","2018年","2019年","2020年","2021年"]
print(year_list[3])
#出力結果 2020年
# 3
year_list=["2017年","2018年","2019年","2020年","2021年"]
print(year_list[4])
#出力結果 2021年
# 4,5
tumige_list=["有翼のフロイライン","魔女と百騎兵2","カリギュラ2"]
tumige_list.append("十三機兵防衛圏")
print(tumige_list)
#出力結果 ['有翼のフロイライン', '魔女と百騎兵2', 'カリギュラ2', '十三機兵防衛圏']
#6
profile={"山田":15,"田中":52,"中山":21}
print(profile)
出力結果 {'山田': 15, '田中': 52, '中山': 21}
Python 関数 15m …
関数とは
関数とはあるデータを受け取り、定められた独自の処理を実行し、その結果を返す命令のことです。
関数は大きく2種類あります。
1つ目は独自関数、2つ目は標準関数(組み込み関数)です。
独自関数は、プログラマーが変数を作るのと同じように自由に名前と処理を考え、プログラマーが作ることが出来る関数です。
標準関数は、Pythonインストール時から最初から利用できる関数です。
多分今までに使ったことのある標準関数はprintだけな気がするぞ…
うっすらとした記憶では独自関数はdefで定義してた記憶があるから多分これからやるのはそれ
標準関数を使ってみよう
a=(10,20,30,40,50)
len(a)
#出力結果 5
まず使ったのが標準関数のlenでこれはデータの要素数を取得する関数。
len(リスト名)で要素の数を取得してくれる模様。
a=(10,20,30,40,50)
print(len(a))
#出力結果 5
例文は↑になっていたがprintを使わなくても同じ結果に。
len関数には結果を出力する機能もついてるのか…?
あとリストを囲むのって[]じゃないとダメだった気がしたんだけど()でも処理が走ったのはなんでだろう
関数を使うメリット・デメリット
関数を使うメリットを大きく2つ紹介します。
1)コードがわかりやすくなる
関数を使うことのメリットとして、まずコードがわかりやすくなります。
各機能をまとめておくことで見やすくなるだけではなく、デバッグ作業も効率良くなります。
2)関数でコードの重複を減らすことができる。
コードの保守性が上がります。
次は、デメリットですが、細かい説明をするといくつかピックアップできますが、
そこまでデメリットというデメリットはあまりあげられません。
ですので、積極的に関数を作って使う習慣を作って頂けるとプログラミングの幅も広がります。
独自関数を作ってみよう
独自関数を定義するためには、defというキーワードを使います。
そのためオリジナルの関数(独自関数)を作るためにはdefを用いるものだと考えください。
また作った独自関数を呼び出すには関数名()とします。
def hello():
print("Hello!")
hello()
#出力結果 Hello!
def 関数名():
で名前を決めて、インデントを開けてから内容を定義するという文法。
つまり独自関数って四則演算とか標準関数とかモジュールとかを掛け合わせて作るものって感じなのかな
関数名と命名規則
関数名は、開発者が自由に名前をつけることが出来ますが、いくつか注意点があります。
注意点として関数名を定義する際に、予約語などで関数名をつけないことです。
また、Pythonで関数名を独自で定義する際に2単語以上の関数名にする場合は、以下のように、小文字で下線(_)を挟むスタイルが推奨されています。
変数のとこでもあったけど2単語以上使うときは_が推奨されてるらしい。
SQLでもその風潮はあった気がするから割とプログラミング言語ではメジャーなルールなのかもしれない
pass
関数は、空のリスト型や空の辞書型を定義するときのように、中身の処理のない関数を定義することができます。
とりあえず関数を宣言しておいて、関数の処理としては何もしない時は、「pass」を使います。
何に使うんだこの機能…
条件分岐によって処理変えるときとか?
標準入力
標準入力とはコンピューター内で動作するプログラムが、データを受け取る手段の1つです。
input()を用いることで、標準入力が可能です。
つまり、ユーザからの入力を受け取ることが可能です。
print("名前を入力してください")
name = input()
print("あなたの名前は"+name+"です")
#出力結果 名前を入力してください 入力ボックスに名前入れると
#あなたの名前は名前です
なおinputで受けとった値は文字型として扱われるとのこと。
数字を入力してもらって数値型として使いたいときはint関数を使ってあげる必要あり。
Python 例外処理 25m …
例外処理
例外処理とはプログラムがある処理を実行している途中で、なんらかの異常が発生した場合に現在の処理を中断させ別の処理を行うことです。
例外処理を記述することで、予期していなかったエラーに対応できるプログラムを書くことができます。
予期していないエラーとはなんでしょうか。
実は、エラーは大きく分けて2種類あります。
- 構文エラー(Syntax Error、IndentationError)
- 例外(Exception)
構文エラーは致命的なエラーであり、構文エラーがある場合プログラムは実行できません。
ファイル名及び、行数などを知らせてくれるためにエラーがどこかは発見しやすいです。
カンマ打ち忘れたり文字型と数値型間違えたりすると出るやつですね
SQLのエラーメッセージで親の顔より見ました。
予期せぬエラーというのは、つまり想定外の事象によりプログラムが動作しなくなってしまうことです。
これを例外と呼びます。
例外には、IndexErrorやKeyError、TypeError、NameError、ZeroDivisionErrorなどがあります。
これらの例外エラーは構文エラーとは違って致命的ではないので、例外処理を記述していればプログラムは実行し続けることが出来ます。
例外処理のサンプルプログラム
try:
i = input()
input_num = int(i)
result = 5 / input_num
print(result)
except ZeroDivisionError:
print('ZeroDivisionError!!')
例外処理を組み込むときは
try:
プログラム内容
exept エラー内容:
例外処理用のプログラム内容
で記述する。(インデントがなぜか反映されない…)
exceptのあとにつづくエラー内容はOSErrorやValueError,ZeroDivisionError, NameError, TypeErrorなどを記述することができる。
例外オブジェクトを捕捉する
try:
a = "a"
b = 5
print(a+b)
except (TypeError, ZeroDivisionError, KeyError) as e:
print(type(e))
#出力結果 <class 'TypeError'>
例外に関する情報をas 一時変数名(ここではe)で取得することができる。
ここでは数値型のデータと文字列型のデータを結合しようとしてるので
TypeErrorのエラーだよ、と教えてくれている。
try:
a = "a"
b = 5
print(a+b)
except (TypeError, ZeroDivisionError, KeyError) as e:
print(e)
#出力結果 can only concatenate str (not "int") to str
ちなみに例文でprint(type(e))になっていたところをprint(e)に変えたら普通にエラーメッセージが出てきた。
エラーメッセージをtype関数で囲うとエラーの分類を返してくれる、ってことなのか…?
else / finally
try:
print('処理')
except KeyError as e:
print('KeyError')
except ZeroDivisionError as e:
print('ZeroDivisionError')
else:
print('問題なく処理が実行されました')
finally:
print('処理2')
#出力結果
#処理
#問題なく処理が実行されました
#処理2
tryブロックが例外なく処理された場合だけ実行されるのがelse。
例外が出ようが出まいが必ず実行されるのがfinallyで、
例外が出てた場合は例外処理のあとで実行されるとのこと
Python 繰り返し処理(for文) 20m …
for文
for i in ["apple","banana","melon"]:
print(i)
#出力結果
#apple
#banana
#melon
for ループ内変数 in リスト名:
実行する処理
が書式で、どんな処理がされているかというと
リストをfor文内に渡す
↓
for文内の変数に格納される
↓
リストの値一つ一つが変数に代入される
↓
全ての値で処理が実行される
↓
リスト内最後の要素で処理が終わるとfor文の処理が終了
という流れ。
range関数
for i in range(10):
print(i)
for文で一定回数の繰り返し処理を行うにはrange()関数を用いることが多いです。
range()関数は次のような役割を持ちます。
range(x): 0からx-1までの連番のリストを返す
range(x,y): xからy-1までの連番のリストを返す
range(x,y,z): xからy-1までの連番のリストをz刻みで返す
ということらしい。わからなすぎて泣いた。
↑の例文でやりたいことって0から9までの数字を表示することだと思うんだけど
a=[range(10)]
print(a)
で同じことできるのではと思ったら出力結果は[range(0, 10)]になって違いが分からない…
for i in リスト名
が書式ってことは↑↑のサンプルで行くとrange(10)がリスト名ってことになると思うんだけど…
それともfor 変数名 in range()までが一つの書式なのか…
追記:
自分でいろいろ調べて解決しました。
range関数で作成されるものは「range型のオブジェクト」であってリストになっていない。
なのでリストとして扱い要素として使用する場合はlist関数を使い
a=range(10)
print(list(a))
#出力結果 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
とすればOK!
for文で使えるのはリストだけではない(この後辞書型も扱うからその時点で気付けたよね…)ので
変数 in リスト名 オブジェクト名
ということらしい。
あとは出力結果一緒じゃね?という疑問については
「要素一覧を出力する」のか「要素を1つ出力する処理を繰り返すのか」で違うということにも気付けました。
スゲーッ爽やかな気分だぜ. 新しいパンツをはいたばかりの 正月元旦の朝のよーによォ~~~
enumerate関数
for i,name in enumerate(["apple", "banana", "melon"]):
print(i,name)
#出力結果
#0 apple
#1 banana
#2 melon
enumerate()を使うと要素と同時にインデックス番号を出力可能。
for 変数名1(インデックス番号),変数名2(値) in enumerate(リスト名)
という書式で変数名2を指定しなかったら、要素が()付きで出力されました。(エラーにはならないけど想定してる処理と違う)
変数名をどちらも指定してprint()に入れるのを変数名1だけにしたらインデックス番号だけが出力されたので別の使い方もできそう。
辞書型のデータをループする
辞書型のデータをループするには次のようにitems()を利用します。
items()を用いることで、各要素のキー(key)と値(value)に対して、forループを適用することが出来ます。
data = {"tani": 30, "kazu": 32, "python": 100}
for key,value in data.items():
print("キーは{},値は{}です".format(key,value))
#出力結果
#キーはtani,値は30です
#キーはkazu,値は32です
#キーはpython,値は100です
format関数なるものもでてきたので少しややこしめ。
format()は{}を含む文字列に連結して、()内の要素を{}に順番に出力してくれる。
なので↑の例文での流れは
data.items()でキーと値がそれぞれkey,valueに代入される
↓
format関数によって一つ目の{}にkeyが、二つ目の{}にvalueが出力される
↓
出力された結果を受けてprint関数が処理される
↓
要素の数だけ繰り返される
という流れ。
この文は
data = {"tani": 30, "kazu": 32, "python": 100}
for key,value in data.items():
print("キーは"+key+",値は"+str(value)+"です")
とformat関数を使わずに書くこともできるけど
可読性が高いコードにするためにformatを使おうね、という話でした。
結合で書こうとしたらstr()を忘れてTypeErrorが出ましたが
format関数を使う場合は結合じゃないから数値型のデータも文字列に入れられる、みたいなところでも便利そうだなあと思いました。
演習問題
1) 3 2 1 Go! と出力するプログラムをfor文を使って記述してください。
2) 1 - 100までの数字の中から偶数の値を持つ値だけのListを作成してください。
#1
for a in ["3","2","1","Go!"]:
print(a)
#2
a=list(range(0,101,2))
print(a)
2日目の感想
2日目にしていきなり躓くとは思っていませんでしたが疑問がクリアになる瞬間は気持ち良いですね!
ちょくちょく馴染みのない単語(オブジェクト、モジュールなど)が出てきて都度調べながら読んでいますが
AI Academyさんのテキストにない情報を追加して自分なりにわかりやすいテキストを作っていくイメージで進めていきます。
明日もがんばれ自分