PIFuとは
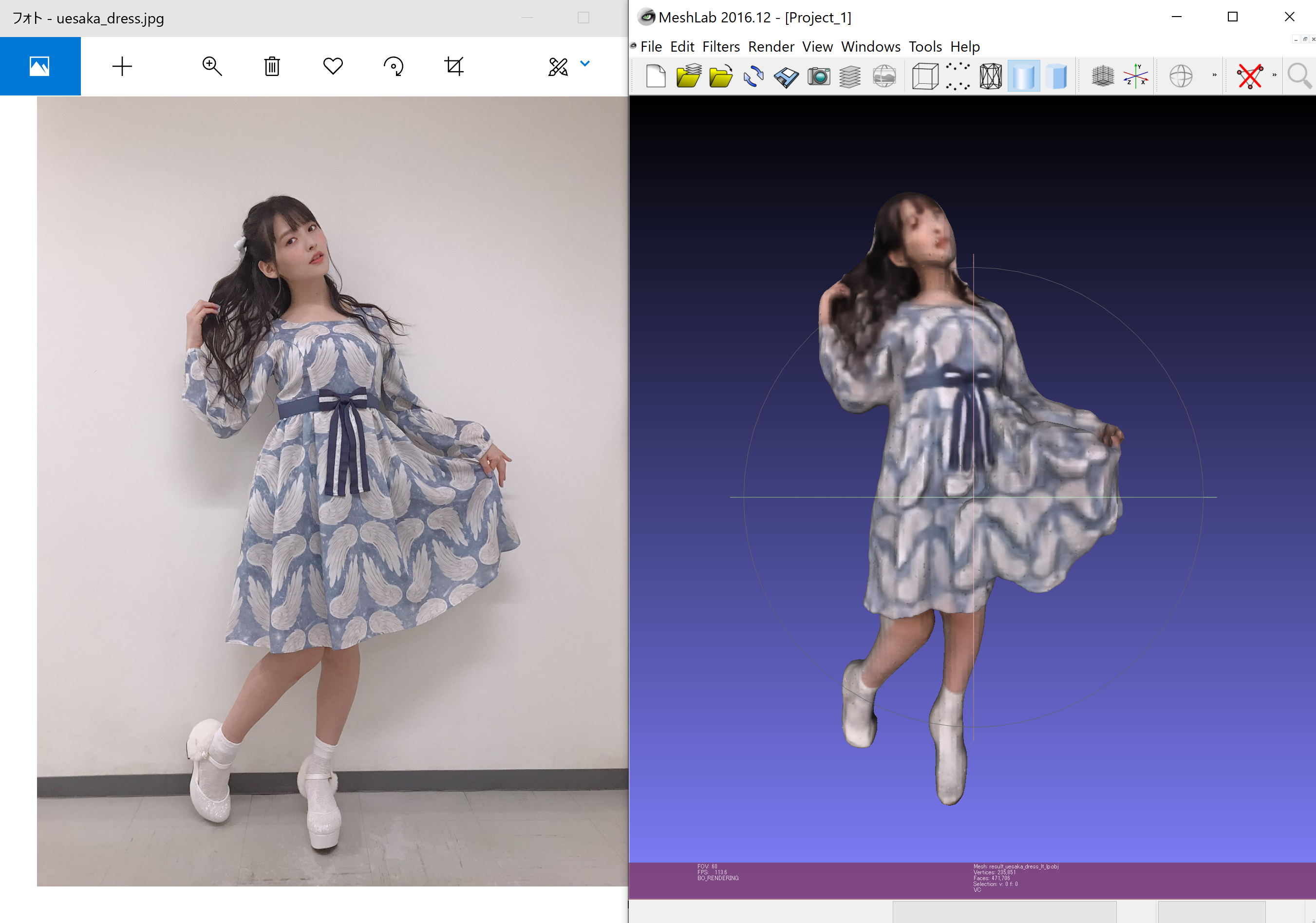
画像引用(左):上坂すみれ オフィシャルブログ 猫森集会
PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization
ざっくりと説明しますと、
1枚の画像から衣服付きの人物の3Dモデルを生成する機械学習のモデル
です。
We introduce Pixel-aligned Implicit Function (PIFu), a highly effective implicit representation that locally aligns pixels of 2D images with the global context of their corresponding 3D object. Using PIFu, we propose an end-to-end deep learning method for digitizing highly detailed clothed humans that can infer both 3D surface and texture from a single image, and optionally, multiple input images. Highly intricate shapes, such as hairstyles, clothing, as well as their variations and deformations can be digitized in a unified way.
Pixel-aligned Implicit Function(PIFu)を導入します。これは、2D画像のピクセルを対応する3Dオブジェクトのグローバルコンテキストにローカルに整列させる非常に効果的な暗黙的な表現です。 PIFuを使用して、単一の画像、およびオプションで複数の入力画像から3D表面とテクスチャの両方を推測できる非常に詳細な衣服をデジタル化するためのエンドツーエンドの深層学習方法を提案します。ヘアスタイル、衣服などの非常に複雑な形状、およびそれらのバリエーションや変形は、統一された方法でデジタル化できます。
導入方法 & チュートリアル
導入方法はシンプルです。
$ git clone https://github.com/shunsukesaito/PIFu.git
$ cd PIFu
$ pip install -r requirements.txt
$ sh ./scripts/download_trained_model.sh
PIFuにはサンプルのデータセットが用意されているので、それを実行するだけで簡単に動かすことができます。
$ sh ./scripts/test.sh
そうすることで、results/pifu_demo/result_ryota.objというファイルが出力されます。

3Dモデルを見るときにはMeshLabがお勧めです。
理由は、PIFuで出力されたモデルはテクスチャが存在せず、VertexColorで色がついています。このVertexColorで色がついているモデルを見れるビューワーが少なく、手軽に見れるのでお勧めです。
指定した画像で3Dモデルの生成
PIFuで3Dモデルを生成するには2つの作業をする必要があります。
- 正方形の画像を準備
- マスク画像の準備
今回は、フリー素材ぱくたそ(www.pakutaso.com)から、袖に手を入れる浴衣眼鏡男子(全身)のフリー画像(写真)を使います。
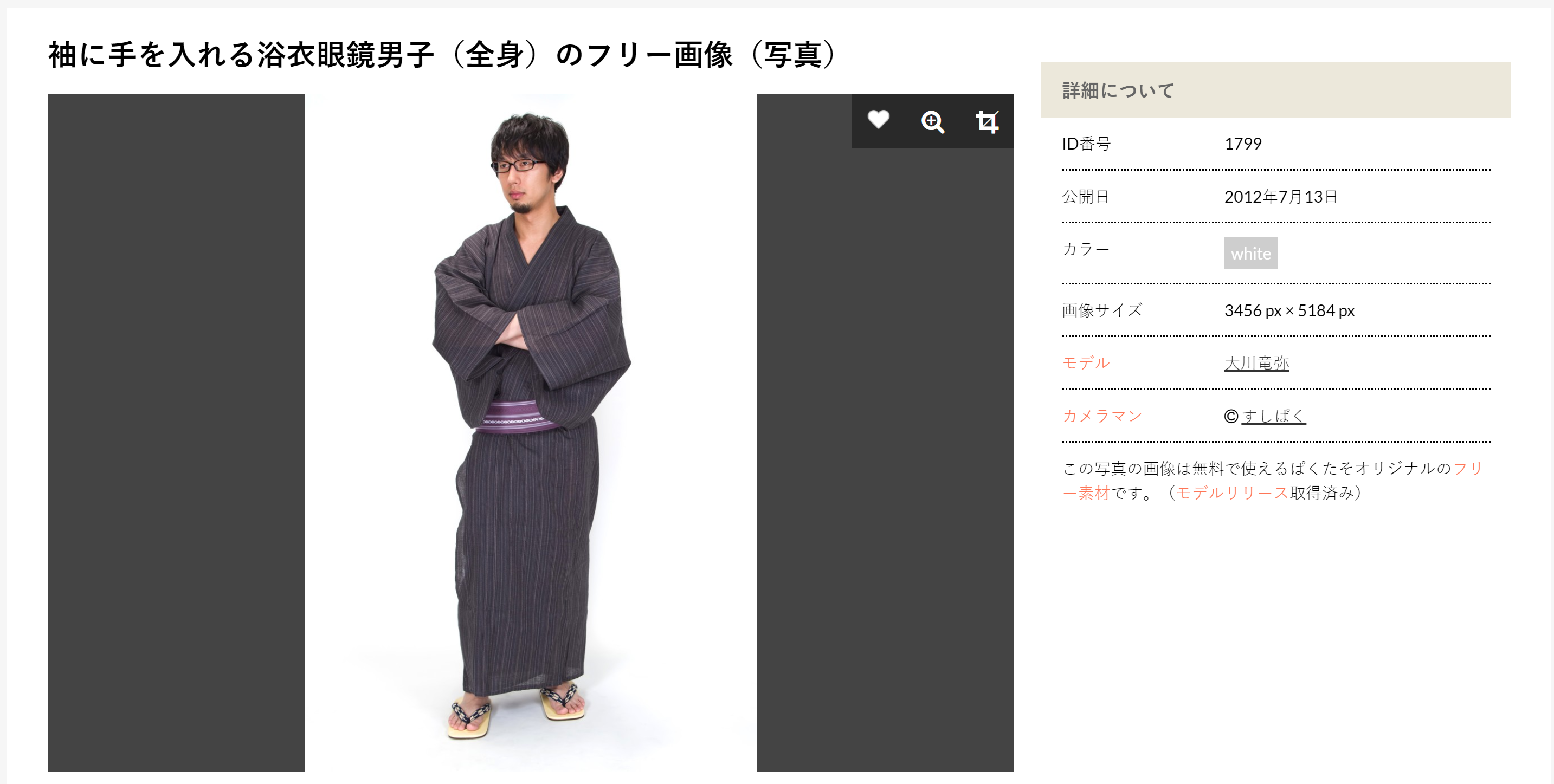
もとの画像が縦長なので、帯を付けて正方形の画像にします。これをkimono.pngとします。

その後、マスク画像を生成します。これをkimono_mask.pngとします。
ここで名前が重要です。必ずマスク画像には_maskを付けてください。

そして、kimono/フォルダを作成し、2つのファイルをコピーします。
mkdir kimono/
cp kimono.png kimono/
cp kimono_mask.png kimono/
以下の内容をscripts/eval.shとして作成します。
# !/usr/bin/env bash
set -ex
# Training
GPU_ID=0
DISPLAY_ID=$((GPU_ID*10+10))
NAME='pifu_demo'
# Network configuration
BATCH_SIZE=1
MLP_DIM='257 1024 512 256 128 1'
MLP_DIM_COLOR='513 1024 512 256 128 3'
TEST_FOLDER_PATH=$1
shift
# Reconstruction resolution
# NOTE: one can change here to reconstruct mesh in a different resolution.
VOL_RES=$1
shift
CHECKPOINTS_NETG_PATH='./checkpoints/net_G'
CHECKPOINTS_NETC_PATH='./checkpoints/net_C'
# command
CUDA_VISIBLE_DEVICES=${GPU_ID} python ./apps/eval.py \
--name ${NAME} \
--batch_size ${BATCH_SIZE} \
--mlp_dim ${MLP_DIM} \
--mlp_dim_color ${MLP_DIM_COLOR} \
--num_stack 4 \
--num_hourglass 2 \
--resolution ${VOL_RES} \
--hg_down 'ave_pool' \
--norm 'group' \
--norm_color 'group' \
--test_folder_path ${TEST_FOLDER_PATH} \
--load_netG_checkpoint_path ${CHECKPOINTS_NETG_PATH} \
--load_netC_checkpoint_path ${CHECKPOINTS_NETC_PATH}
最後に、
$ sh scripts/eval_default.sh kimono/ 256
とすることで、results/pifu_demo/result_kimono.objが生成されます。

脱法PIFu
脱法PIFuというものがあります。こいつは私が作った高画質のテクスチャが作れるPIFuです。(私が適当に本家と区別するために命名しているだけです。)
ただ脱法というだけあって、若干アレなところがあります。まぁ諸事情があるので後述します。
左:元画像
中:PIFuデフォルト
右:脱法PIFu

私のPIFuのリポジトリの2_phase_generateというブランチです。
このブランチで、scripts/eval_two_phase.shで出力することができます。
使い方としては、
./scripts/eval_two_phase.sh IMAGE_DIR/ VOXEL_RESOLUTION VOXEL_LOAD_SIZE TEX_LOAD_SIZE
という感じです。IMAGE_DIR/は画像の入っているディレクトリです。VOXEL_RESOLUTIONは512,1024あたりがお勧めです。1024だと20GBぐらいメモリを持っていくので、その辺はマシンに合わせて。
VOXEL_LOAD_SIZEは512固定にしておくことをお勧めします。
TEX_LOAD_SIZEはテクスチャの解像度に合わせて、1024や2048にしてください。
これで高画質なテクスチャのモデルが出るハズです。
で、どのあたりが脱法なのか。という話です。まぁどうやら非正規挙動を利用しているっぽいです。
詳しくは私が出したプルリクに書いてありますが、本来はVOXEL_LOAD_SIZE, TEX_LOAD_SIZEは512以外は指定してはいけなかった。ということです。しかし、ここで私がTEX_LOAD_SIZEを1024に指定して出力してみたら、なんかきれいなモデルができちゃったというのが面倒なところです。
最初、私は「TEX_LOAD_SIZEに不正な値を入れたら死ぬんだろうなぁ」とか、「もし動いてもテクスチャがズタズタだろうなぁ」と思っていて適当に改造していたんですが、なんかそれっぽくキレイに出た。出てしまった。というので、プルリク作ったんですが、本来ダメだったそうです。
実際のところ、後ろのテクスチャは割とズタズタです。
左:PIFu
右:脱法PIFu
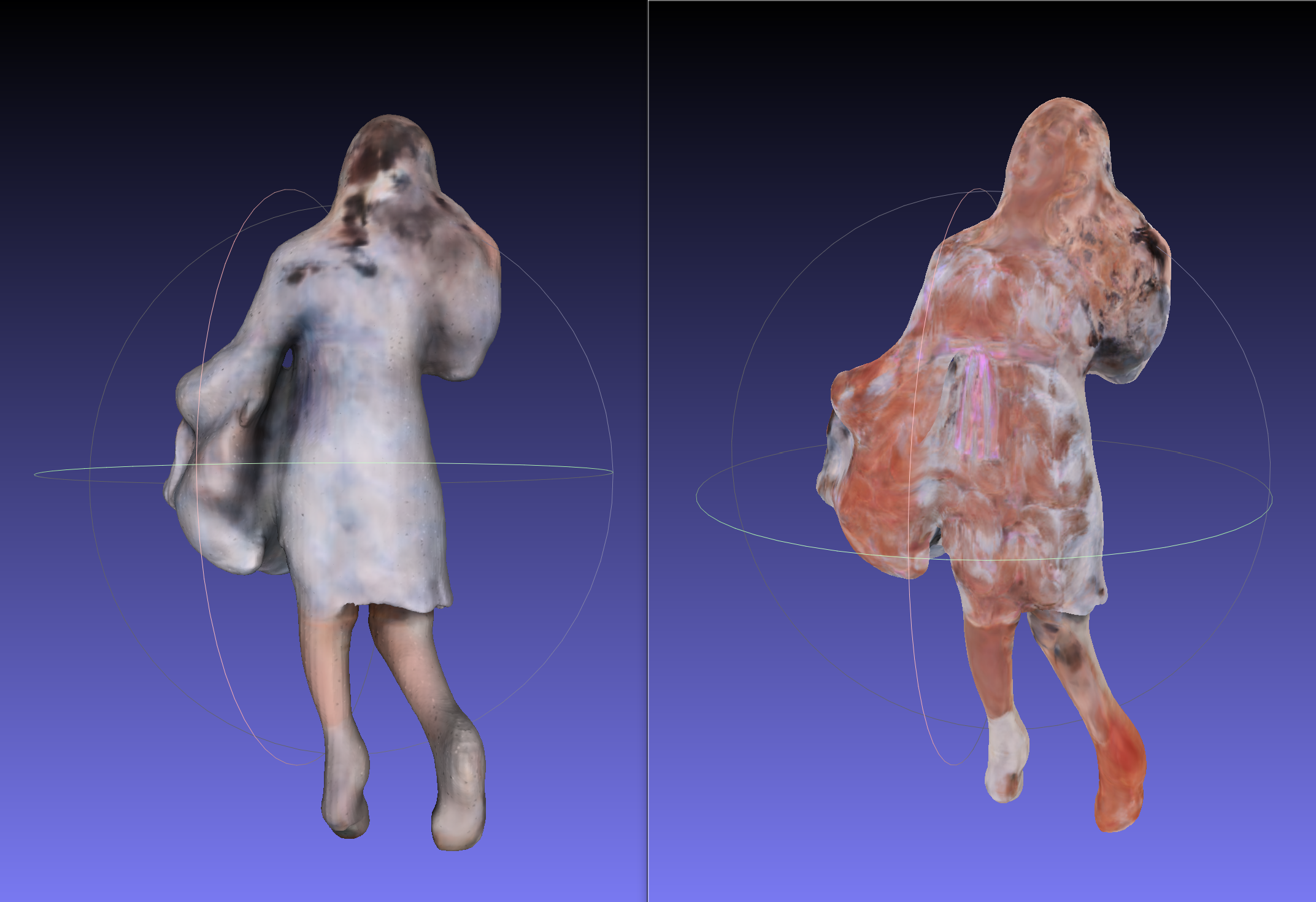
作者の方がおっしゃるように、もしハイクオリティなテクスチャが欲しいならシンプルに投影したら?と言われているので、まぁそうかもしれません。実は、PIFuにはテクスチャを投影する機能もあるにはあるんですが、コードを見た感じ、高解像度での出力は不可能なので、改造は必須だと思います。
感想
すみぺを紹介できたので僕は満足です。PIFuは、去年から存在は知っていて、コードはいつ公開されるかなーと思いましたが、意外に早く出てきて驚きました。また、割と動かしやすいものだったので、サクッと出来てよかったです。ただ、もうちょっとイイ感じにできないかなーと思案中です。ソニックブームソニックブームウエサカカワイイ。