Copilot+ PCでローカルLLMできるのか?
最近、ノートパソコンを新調しました。買ったのはThinkPad X1 Carbon Gen 13 Aura Editionという製品です。
このパソコンのウリの一つとしてCopilot+ PCの製品である。と銘打たれています。いわゆるAIが使えるPC!!という感じです。
では、本当にCopilot+ PCで外部GPUなしにAIが使えるのか?いろいろ試してみよう。
という実験を行いました。忙しい人向けに結論を書いておきますと、
- Copilot+ PCで高速にローカルLLMを動かす方法はあるが、それはNPUではなくGPUなのが現状。
- Copilot+ PCでAI Codingしたいなら、ipex-llmのllama.cpp(非NPU版)を利用するのがよい。
Copilot+ PCとは
雑に要約すると、Microsoftが認定したAIに特化したPCです。
Copilot+ PCs は、リアルタイム翻訳や画像生成などの AI 集約型プロセスに特化した、40 TOPS (毎秒 40 兆回の演算処理) 以上の実行性能を持つコンピューター チップである超高速ニューラル プロセッシング ユニット (NPU) を搭載した、新しいクラスの Windows 11 AI PC です。
以下の要件を満たす必要があります。
- プロセッサ: 40 TOPS 以上の実行性能を持つ NPU を備えた、互換性のあるプロセッサまたは System on a Chip (SoC)。
- RAM:16 GB DDR5/LPDDR5
- ストレージ:256 GB SSD/UFS
参考: Copilot+ PCs の最小システム要件
参考: 「Copilot+ PC」っていったい何? 知っておきたい、その中身と機能とは
ThinkPad X1 Carbon Gen 13 Aura Edition
今回買ったThinkPad X1 Carbon Gen 13 Aura Editionですが、カスタムしてCPUをIntel Core Ultara 7 268Vにしました。先ほどの、Copilot+ PCには、「40 TOPS 以上の実行性能を持つ NPU を備えた」という要件がありました。これに対応するのがIntel AI Boostと呼ばれるNPUです。
このあたり非常に検索しにくくて困るのですが、Intel Core Ultra 7 268Vに搭載しているのは、第4世代のNPUです。このあたりのNPUをひっくるめてIntel AI Boostと呼んでいるみたいです。一方でIntelのCPUのサイトにはNPUの具体的な世代数(製品番号等)が書かれていないので、非常に分かりにくく、性能も調べにくかったりします。また、このCPUにはIntel Arc Graphics 140Vというグラフィックチップも搭載しています。このあたりを図解するとこういうイメージです。

今度は、CPU・GPU・NPUの性能をネットから検索してきてまとめてみます。
| 名称 | Intel Core Ultra 7 268 | Intel Arc Graphics 140V | NPU Gen4 | GeForce 5090(参考) | GeForce 2070(参考) |
|---|---|---|---|---|---|
| Int8(TOPS) | (全体)118.00 | 66.00 | 48.00 | ||
| FP16(TFLOPS) | 12.48 | 104.8 | 14.93 | ||
| FP32(TFLOPS) | 6.24 | 104.8 | 7.47 |
これは色々な但し書きが必要ですが、スペック表を信じるとすると、Intel Arv Graphic 140VのスペックはGeForce 2070相当です(もちろん実行手法によってはGeForce 2070のほうが速いと思います)。一方で、現行の5090と比較するとそのスペックは十分の一程度です。
一方でNPUのFP16やFP32の性能はどうか?というと、あまり情報がないです。理由としては、そもそも論として、Copilot+ PCが45TOPSを基準としているため、それ以外の情報がないです。一応、FP16やFP32の演算はできるようですが、あまり情報が出ていません。
このあたりの情報から
NPUのINT8性能が高い。そのため、IntelのNPUかつINT8で演算できるローカルLLMを探そう
という方針が経ちました。
参考: Intel Arc 140V
参考: インテル® Core™ Ultra 7 プロセッサー 268V
参考: 完全刷新されたIntelの新GPU「Xe2」と第4世代NPUの詳細
参考: NVIDIA GeForce RTX 5090
参考: NVIDIA GeForce RTX 2070
参考: AI性能を重視したIntel第14世代SoC「Core Ultra」に搭載されたNPUの性能とは?
Ollamaとllama.cppの関係
私がなぜローカルLLMを利用したいか。というとRooCodeでVibe Codingをしたいからです。普段はVisual Code LLM APIを利用していますが、別の選択肢を検討していました。
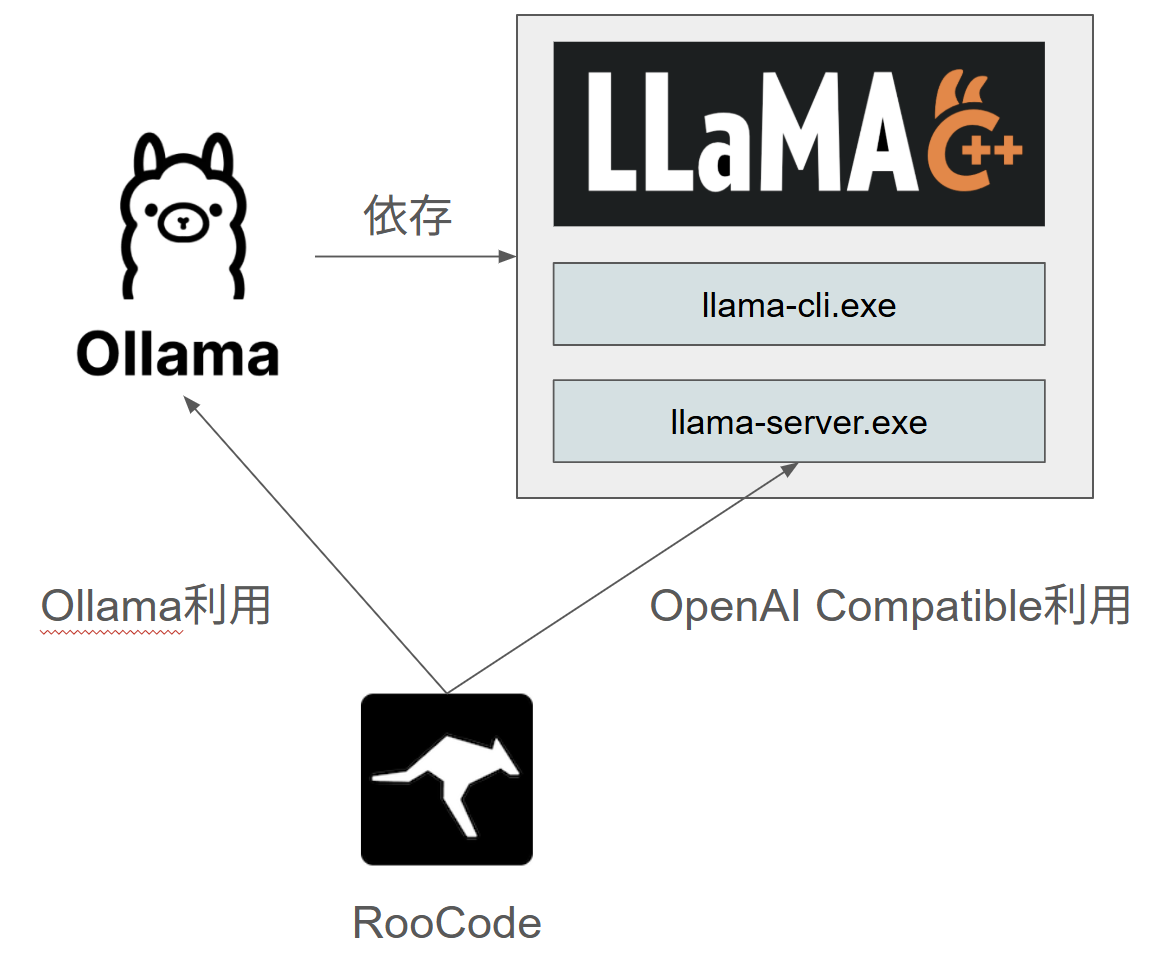
ローカルLLMでAI Codingしたい場合、有名なのはOllamaを利用する方法です。RooCodeでも選択項目があるのでわかりやすいと思います。もう1つの選択肢として、llama.cppというものもあります。これには、llama-serverというツールがあり、これを利用することでもAI Coding可能です。その時には、RooCode内では、OpenAI Compatibleを利用する必要があります。
どうやらOllamaは内部的にはllama.cppをラップしているだけらしいので実質ほぼ同じです。ですが、これは後々"違う"ということがわかります。
本家Ollamaと本家llama.cppのNPU方針
ここでは、一般的にollamaと呼ばれているソフトを本家ollamaと呼びます。そして、一般的にllama.cppと呼ばれているソフトを本家llama.cppと呼びます。結論から言うと本家ollamaと本家llama.cppはNPU対応はまだ行っていません(2025/04/15)。そのため、NPUでは動作しないというのが現状です。
では、今後、本家ollamaや本家llama.cppがNPU対応するのか?というと、
- 本家ollamaはNPU対応しなさそう
- 本家llama.cppは対応するかも
というのが私見です。
本家ollamaに関していうと、Intel NPUやIntel GPUに関するIssueがあります。
- [Feature] Support Intel GPUs #8414
- Support to Intel NPU by Intel NPU Acceleration Library #5747
- Runing ollama on Intel Ultra NPU or GPU #8281
- Add Vulkan support to ollama #5059
- Add support Intel GPU by OneApi /SYCL #10244
ソースコード内にはOLLAMA_INTEL_GPUという記述があったりするのですが、実際に自分のマシンで有効化して動かしてもGPUを利用しないようです。また、この辺のマニアック(?)なGPUに関しては、Ollamaは割と消極的な印象を受けて、過去にVulkanに対応したバージョンをプルリクエストとして出したが、マージされず今に至るようです。また、先ほどのIntel GPUの機能も、一時期は有効化していたが、今は無効化されているようです。
一方で、本家llama.cppはなぜNPU対応しそうか。というと、リリースを見るとわかります。

本家llama.cppはこのように非常に多くのGPUに対応したバージョンをリリースしています。そのため、その1つとしてNPUが入っても不思議ではないな。という感触があります。
一方で、本家ollamaのリリースは以下のようになっています。
このように非常に少ないです。本家ollamaは本家llama.cppに依存しており、本家llama.cppにはたくさんのGPUに対応しているが、なぜこんなことが起こるのか?というと、単純にビルドやマージが大変で、思想が違うから。という気がします。
基本的にollamaはllama.cppを簡単に使えるようにしたもの。という感じです。そのため、簡単に使える。ためにユーザーが迷わないように、基本的に1つのexeを選べばよい。という思想があるように思います。一方で、本家llama.cppは玄人向けで、自分のPCが何であるか。を知ったうえで、それに合ったexeを自分でダウンロードしてくる。という思想に見えます。
また、llama.cppのcu11.7版を見るとファイル容量が303MBあります。もしollamaがすべてのGPUに対応した場合、単純に考えると、llama.cppが配布しているexeのファイルの容量を全部足し合わせたぐらいの容量になります。すでにollamaのwindows版が1GBを超えていることを考えると、おそらく2GB越えの容量になるのではないでしょうか。そんなことを書いていますが、ここはollamaも実は頑張っており、ollamaは標準でcudaやrocmに対応した状態でリリースしています。そのため、省コストで最大のリーチや最大の効果を手軽に実現するような思想で運営しているような思想も見えます。したがって、マイノリティーなIntel GPUの対応はollamaは注力しないのではないか。というのが私の意見です。
ipex-Ollamaとipex-llama
intelがipex-llmというリポジトリを公開しています。
これは、
IPEX-LLM は、Intel GPU (iGPU を搭載したローカル PC、Arc、Flex、Max などの個別 GPU など)、NPU、CPU用の LLM アクセラレーション ライブラリです。
だそうです。そう考えると、ここにあるバイナリはNPUを利用しそうです。このリリースにollamaとllama.cppが存在します。これを便宜上、ipex-ollamaとipex-llama.cppと呼びます。リリースを見てみると、動きそうなexeが3種類あります。

- llama-cpp-ipex-llm-2.2.0-win-npu.zip
- llama-cpp-ipex-llm-2.2.0-win.zip
- ollama-ipex-llm-2.2.0-win.zip
これらを実行してみました。
| バイナリ | 結果 |
|---|---|
| llama-cpp-ipex-llm-2.2.0-win-npu | NPUで動作するが、不正な応答が返ってくる。 |
| llama-cpp-ipex-llm-2.2.0-win | GPUで動作し、正常に応答する。 |
| ollama-ipex-llm-2.2.0-win | GPUで動作し、正常に応答する。 |
という結果になりました。llama-cpp-ipex-llm-2.2.0-win-npu(以下、ipex-llama-npu)は

タスクマネージャー上でもNPUが稼働していることが確認できました。しかし、LLMとして不正な応答しか返ってきませんでした。具体的には、
PS C:\Users\kotau\Downloads\llama-cpp-ipex-llm-2.2.0-win-npu> .\llama-cli-npu.exe -m ..\DeepSeek-R1-Distill-Qwen-7B-Q6_K.gguf -n 32 --prompt "What is AI?"
・ソusing 犹もク巵ク」犹・ <think>リオル・ッ Di盻・ 2犹もク巵ク」犹・ 1 2
みたいな感じです。Issueに挙げています。
一方で、llama-cpp-ipex-llm-2.2.0-win(以下、ipex-llama)はGPUしか利用していない。ということがわかりました。

これは、ollama-ipex-llm-2.2.0-win(以下、ipex-ollama)でも同じです。
では、ipex-llama-npuのバグが直ったら、うまくいくか?というとそうでもない。というところが難しいです。これはipex-llama-npuの配布物です。
PS C:\Users\kotau\Downloads\llama-cpp-ipex-llm-2.2.0-win-npu> ls
ディレクトリ: C:\Users\kotau\Downloads\llama-cpp-ipex-llm-2.2.0-win-npu
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 2025/04/14 23:57 cache
d----- 2025/04/15 4:02 NPU_models
-a---- 2025/04/09 2:55 716680 ggml.dll
-a---- 2025/04/09 2:55 567176 llama-cli-npu.exe
-a---- 2025/04/09 2:55 1609096 llama.dll
-a---- 2025/04/09 2:55 4826504 npu_llm.dll
-a---- 2025/04/09 2:55 13244768 openvino.dll
-a---- 2025/04/09 2:55 1834848 openvino_intel_npu_plugin.dll
-a---- 2025/04/09 2:55 438112 openvino_ir_frontend.dll
-a---- 2025/04/09 2:55 1893 README.txt
-a---- 2025/04/09 2:55 1896 README.zh-CN.txt
-a---- 2025/04/09 2:55 189792 tbb12.dll
-a---- 2025/04/09 2:55 101256 zlib1.dll
前の章でAI Codingをするには、llama-serverでOpenAI CompatibleなAPIを立てればよい。と書きました。一方で、ipex-llama-npuにはllama-serverの配布がありません。 また、現状のipex-llama-npuは動作するモデルが限られているため、かなりピーキーです。そのため、AI Codingにはまだまだ課題がある。という状態です。
ベンチマーク
ここまで調べたところで、
「結局、ipex-llamaがGPUしか使わないのであれば、本家llama.cppのGPU版使っといてもいいんじゃない?」
という疑問が浮かびました。なので、実験してみました。本家llama.cppはb5097、ipex-llamaはv2.2.0を利用しました。
今回は対照実験もかねて、
- ipex-llama
- 本家llama-sycl
- 本家llama-vulkan
- 本家llama-openblas
- 本家llama-avx2
で行っています。openblas,avx2はCPUのみを利用する代表として、sycl,vulkanはGPUを使う代表として選出しています。noavxなどCPU拡張命令を使用しないバージョンが本家llama.cppに存在しますが、あまりにも時間がかかりそうだったのでやめました。
ベンチマーク方法はデフォルト設定です。モデルはcyberagentのDeepSeekの日本語版14Bを使いました。
./llama-bench.exe -m ../cyberagent-DeepSeek-R1-Distill-Qwen-14B-Japanese-Q4_K_M.gguf
デフォルトでは、ppとtgというベンチマークを行います。ppはPromptProcessingということでプロンプトのバッチ処理を行い、tgはTextGenerationということでトークンのシーケンスを生成する試験となっています。評価はt/sという単位で1秒当たりの平均トークン数と標準偏差が出力されます。今回、1秒当たりの平均トークン数のみを出力しています。


結果は、おおむねipex-llamaが速いです。特にppでは群を抜いて速く、2位の3倍差です。次いでsycl、vulkanとなっています。CPUのみのopenblasやavx2はそれほど早くない。というのは直観と一致しています。
tgのテストも、ipex-llamaが速いですが、vulkanと同じくらいです。しかし、今回の結果で興味深いのはそれほどGPUが速くない。ということです。例えば、ppの時、ipex-llamaは、avx2の25倍速く、その差は圧倒的でした。しかし、今回のtgの時は、高々2倍程度です。そのため、バッチ処理でこそ大差は出ますが、逐次処理においては、それほど大きな差は出ない。という結果になっています。したがって、
Copilot+ PCでローカルLLMするならipex-llmのollama、llama.cppを使うのがよい
と言えそうです。ollamaはベンチマークする方法がないのですが、llama.cppが速いのでたぶん速いだろう。という予測で書いてます。また、今回は生成速度にしか注目しておらず、生成のクオリティは確認していません。
では、なぜipex-llamaのほうが本家lamaのGPU版より速いのでしょうか?ここに関してはあまり情報がないのでわからない。というのが正直なところです。まず第1にipex-llamaやipex-ollamaのコードが公開されてなさそうです。そのため、本家llama.cppにどんなチューニングをしたのかあまりよくわかりませんでした。第2にipex-llmのリポジトリ内にはほとんどC/C++がないです。たいていは、oneAPIなど、ハードウェアに依存した部分のコードがあると思いましたが、そうではないようです。一応、Intelが作っているintel-npu-acceleration-library
を利用しているため、NPU部分はこれで速くなると考えられますが、GPUが速くなる理由付けにはなりません。したがって、ipex-llm版がなぜ速いか?はよくわかりませんでした。
AI プロバイダーとの速度比較
ローカルLLMの速度がわかったので、AIプロバイダーの出力速度と比較していきます。
今回、以下のダッシュボードを参考にしています。

ダッシュボード上のスペックではDeepSeek R1は22[t/s]です。そのため、tgを参考値として考えるとローカルのipex-llamaは3倍強程度遅い。ということになります。自分の周りではGemini 2.5 Proあたりが話題になっているように思いますが、これは204[t/s]と非常に速く、29倍程度速いです。また、Claude 3.7 Sonnetは77[t/s]となっており、12倍近く速いです。
こう考えると、いかに現状だと、ローカルLLMするのが厳しいかがわかるとおもいます
NPUによりローカルLLMは速くなるのか?
実は結構難しいんじゃないか。と思いつつあります。
llama.cppを実行しいてると以下のようなログが出ました。
llama_model_loader: - type f32: 241 tensors
llama_model_loader: - type q4_K: 289 tensors
llama_model_loader: - type q6_K: 49 tensors
あまりllama.cppのログの見方を勉強したわけではないですが、ここから高速化した時の皮算用をしてみようとおもいます
f32はFP32、q4_K,q6_kをint8で処理していると仮定します。
仮に、1つ1つのtensorの計算にt秒かかるとします。そうすると現在、処理にかかっている時間Tは以下のようにあらわせます。
\begin{eqnarray}
T = 241t + 289t + 49t \\
T = 579t
\end{eqnarray}
これがNPUにより、fp32がもともとの6.24TFLOPSからINT8の118TOPSへ上昇し、INT8の演算は66TOPSから118TOPSに上昇すると仮定します。すると処理時間T_1は
\begin{eqnarray}
T_1 = 241t \times { 6.24 \over 118} + 289t \times {66 \over 118} + 49t \times {66 \over 118} \\
T_1 \fallingdotseq 201.8t
\end{eqnarray}
T/T1=2.86となり、大体3倍弱速くなるんじゃないかな。と目算が付きます。(だいぶ荒っぽい議論をしていますが、目算をつけるためです。)
ベンチマークからローカルでは6.26[t/s]だったので、高速化すると17.96[t/s]と予測できます。しかし、先ほどのAIプロバイダーの議論で、DeepSeek R1が22[t/s]であったことを考えるとまだまだ処理速度が遅いかな。という感じです。
まとめ
- intelのGPUでローカルLLMをしたいのであれば、ipex-llmのllama.cppやollamaを使うほうが良い
- ipex-llmのllama.cppはGPUを利用し、CPUをする場合に比べ最大25倍速い
- NPU版はまだ不安定なので、GPU版を使ったほうが良さそう
感想
長かった。よくわからないことが多すぎた。そもそもNPUってなんだ?ぐらいのレベルの話だったし、実際にNPUが何かはよくわからない。
ipex版もまともに動かない。NPUを使っている形跡は見られるが、正常な応答が得られないのを確認したとき、
「これって・・・まともにNPU使ってるソフトないんじゃ・・・?」
と思ったら、まぁまぁ当たりでした。「「Copilot+ PC」っていったい何? 知っておきたい、その中身と機能とは」という記事を参考にCopilot特有の機能を動かしてみました。
- リコール
- 未検証
- コクリエイター
- Microsoft 365 PersonalもしくはCopilot Proが必要で動作できず
- ライブキャプション
- 動作するがGPUやNPUを利用していない
- Windows Studio エフェクト
- NPUの動作が確認できた!!
- イメージクリエイター/リスタイル
- フォトアプリで利用できると書いてあるが表示されない。Insider版だけで正式版に存在しない?
とあり、まともにNPUが動作することを確認できたのは「Windows Studio エフェクト」のみでした。
ほかには、IntelにはAI Playgroundというものもあります。こちらはどうだ?と思って実行してみました。結果、Intel Arc Graphic向けで、結局NPUを使いませんでした。
というわけで、かなり現状だと難ありのIntel NPU事情でした。大変だった。なぜCopilot+ PCを買ったのか?というのが疑問に思うかもしれませんが、そもそも自分自身がLenovoが好きなので、その最上位グレードであるX1 Carbonを買ったらCopilot+ PCだった。というのが実情です。そのため、AIがローカルで動かなくてもまぁいいや。というのが心境です。
最近は、Github Copilotの無料版の締め付けも厳しくなるという話なので、新たなAIの実行方法を模索しなければならないかな。みたいな気持ちで少しやっていましたが、まぁ大変。もう少しぬるぬるーっと動いてくれればいいんですが、それにはまだごついGPUが必要そうです。あと改めて思いましたが、AI Codingはかなり出力の速度が大事だな。と思いました。cyberagentのDeepSeekモデルを使いましたが、基本的にthinkしてしまい、ほとんど文字が出力されません。そのため、thinkにほとんどのトークン出力速度が吸われ、全然コードや文字が出力されません。また、コード自体、そこそこ長い文字列です。そのために、編集するための出力も長大化しやすいので、そもそもの生成速度が遅いと使い物にならないなーというのが本音です。そのため、出力速度を上げるような努力をしないとな。という気持ちです。一方で、それを頑張るぐらいなら無料枠でやっててもいいか・・・みたいな気持ちもないわけではないです・・・