概要
この文章は,任意の文章を任意の著者風に変換するアルゴリズムに関する記録である.
近年,画像処理に関して,Prismaという非常に興味深いアプリが公開された.これは,任意の画像を,ゴッホ風やキュビズム風に変換するサービスだ.最新の機械学習が,実際にサービスに使われた非常に面白い例であった.
この文章は,Prismaが行っている「任意の画像を○○風に変換する」という作業を,「任意の文章を○○風に変換する」ということを目指して開発を行った.
例を挙げると,
「あなたは愚か者です.」
という文章を,式波アスカ風にすると
「あんたバカァ?」
となるかも知れないし,星野ルリ風に変化すると,
「馬鹿ばっか.」
になるかもしれない.他の例で挙げると,
「私は猫です.」
という文章を夏目漱石風に変換すると,
「吾輩は猫である.」
という変換になるかもしれない.
本文章は,それらを実現するためにアプローチを試みたが,実はそんなにうまくいかなかった.
というわけで,失敗の記録ですが,それでも良い方は以下をどうぞ.
先行研究
概要でも示したが,画像分野では,Prismaというアプリが非常に有名である.これはCNNを用いたDeepLearningの拡張であると予測されている.そのほかには,声質変換というものがある.これは名探偵コナンに出てくる蝶ネクタイ型変声機を想像しやすいが,いわゆる別人の声に声を変化させることができる機械である.このようなアプローチはメルケプストラムという声の特徴量を抽出・分離を行い,他人の特徴量を再度合成することにより達成している.
一方で,自然言語処理に目を向ける.日本語処理においてそのような研究があるかというと,あまりないように思われる.ネット上の例にある有名な例であれば,もんじろう( http://monjiro.net/ )が挙げられる.これは,任意の文章を○○風に変換できるサイトである.例えば,「あなたは愚か者です.」を武士語風に変換すると,「お手前は愚か者でござる.」という文章に変換される.また,別のサイトとして,ClalisTone ( https://liplis.mine.nu/lipliswiki/webroot/?ClalisTone4.1 )というものがある.これは,APIが公開されており,その仕様書を読むと以下のよう記述がある.
① name 設定名(任意)
② type 設定タイプ(0:通常変換、1:語尾変換)
③ befor 変換対象文字列
④ after 変換語文字列
ここから,分かることとして,この種のアルゴリズムは2つに分けられる.1つは「任意個所の変換」,2つめは「末尾変換」である.武士語を例にとると,「あなたは」という文字列は前者の変換にあたり,「お手前は」という変換になり,最後の「です」という部分が「ござる」という変換になるのが,後者の変換に当たることが分かる.しかし,これらのアプローチは問題もある.あまりにも単純な置換のため,式波アスカ風の「あんたバカァ?」のような変換はできない.また,末尾の変換を行える文体というものは,口語に限定される.例えば,いわゆる猫語のような,末尾を「にゃ」とする変換を行うことを考えると,「電車がやってきました」という文章は「電車がやってきましたにゃ」という文体になってしまい,文語を扱う小説のようなものには応用できない手法であることが分かる.ここで,本文章では,文語でも利用可能な作風変換について,考えてみることにする.
| 対象 | 例 |
|---|---|
| 口語 | もんじろう, ClalisTone |
| 文語 | 本手法 |
アルゴリズムの基礎概念
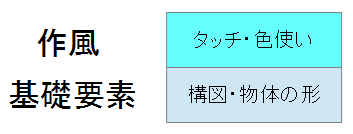
ここで,Prismaのような画風変換の手法について述べる.ざっくりとだが,絵の"基礎要素"と"作風"の部分に分けられる.簡単にしか説明しないが,"基礎要素"とここで示している部分の,"形"や"構図"に関する部分から画像を生成し,"作風"に合うように最適化している.このように2つの要素に分かれることが重要である.
他にも声質変換の例を挙げると,
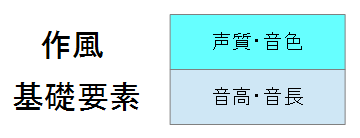
という風になる.音の高さや音の長さは同じだが,その声質が変わることによって,声の変換を行っている.もっと直感的に分かりやすいのが,MIDIかもしれない.MIDIは基本的に音高や音長を調整し,あとで,音色を変えることが容易にできる.同じ譜面でも,トランペットで音を鳴らしたり,ピアノで音を鳴らしたりすることが出来る.
ここで,本文章で扱っている,作風変換は以下のような分割ができると考えられる.
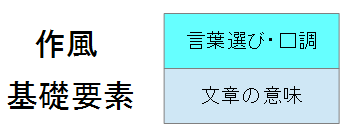
"基礎要素"に"文章の意味"というものがあり,それに対し,"作風"として,"言葉選び・口調"がある.と考えられる.先ほどの例でいうと,「あなたは愚か者です.」という文章と,「あんたバカァ?」の文章の表す意味は同じで,言葉選び・口調のみが異なる.ということが分かります.
アルゴリズム
一般的な声質変換は以下のようなフローになります.(図の都合で内容を簡略化してます)
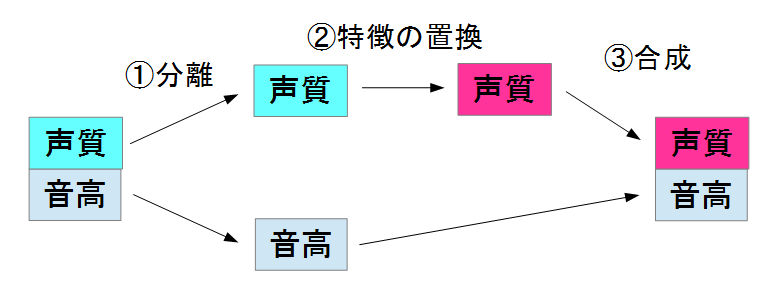
このように1.で声質と音高を分離し,2.で別の人の声質に置換し,それを3.で再合成する.という手法になります.画像の作風変換も似たようなアプローチをしていますが,この手法を文章の作風変換に応用するのは困難です.その理由として,文章における,"意味"と"言葉選び"というものを分離する手法が研究されておらず,同様のアプローチは非常に難しいと考えられます.この限定的なアプローチが先ほど示した"末尾による口調変換"で,末尾の言葉であれば,それほど意味に影響を与えないであろう.という仮定の下,語尾に「にゃ」という文字をつける手法になると考えられます.
ここでは,別の切り口で文章の作風変更を行います.
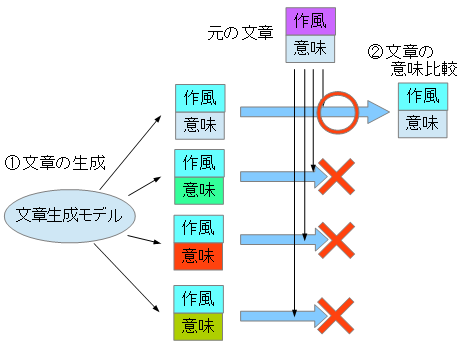
- 文章生成モデルから,文章を生成
- 変換したい文章(元の文章)と1.で生成した文章の意味を比較
- 2.意味が一番近い文章のみを出力
という仕組みです.
○○風の文章の自動生成というものは,一時期非常に流行した隠れマルコフモデルによる自動生成があります.これを利用し,1.で文章を生成します.意味比較にはDoc2Vecという方法を使います.word2vecという手法が以前に流行しましたが,これの拡張版で,ニューラルネットワークにより文章と文章の意味比較を行うことが出来る手法です.これを2.で利用します.
データ準備
コーパス自体は,青空文庫を用いました.以下のサイトで作者別のデータをダウンロードできます.
青空文庫 作家別一括ダウンロード
http://keison.sakura.ne.jp/
そして,以下の50名の文章をMecabで分かち書きを生成し,Doc2Vecの学習に用いました.
アンデルセン,カフカ,グリム,ゴーゴリ,ジャン・クリストフ,ダンテ,チェーホフ,ドイル,ボードレール,ポー,マクラウド,モーパッサン,リルケ,ロラン,ヴィクトル・ユゴー,安吾の新日本地理,安吾人生案内,伊丹万作,伊藤左千夫,伊藤野枝,井上円了,井上紅梅,永井荷風,横光利一,岡本かの子,岡本綺堂,沖野岩三郎,下村千秋,夏目漱石,我が人生観,海野十三,芥川龍之介,梶井基次郎,葛西善蔵,蒲原有明,岸田国士,菊池寛,吉行エイスケ,吉川英治,久生十蘭,宮原晃一郎,宮城道雄,宮沢賢治,宮本百合子,近松秋江,桑原隲蔵,原田義人,原民喜,古川緑波,戸坂潤
一部人名でないものも入っていますが,たぶんその文章はエラーで処理できてないです.
事前実験
以下のようなスクリプトを用意しました.
# coding: utf-8
import sys
from gensim.models.doc2vec import Doc2Vec,DocvecsArray
from scipy.spatial.distance import cosine
from scipy.linalg import norm
import MeCab
class Estimator:
def __init__(self,model):
self.model = model
self.mecab = MeCab.Tagger("-Owakati")
def estimate(self,txt1,txt2):
txt1 = self.mecab.parse(txt1)
txt2 = self.mecab.parse(txt2)
a1 = txt1.decode("utf-8").split()
b1 = txt2.decode("utf-8").split()
#return self.model.docvecs.similarity_unseen_docs(self.model,a1,b1,alpha=0.0,min_alpha=0.0)
return self.model.docvecs.similarity_unseen_docs(self.model,a1,b1)
if __name__=="__main__":
model_filename = sys.argv[1]
txt1 = sys.argv[2]
txt2 = sys.argv[3]
model = Doc2Vec.load(model_filename)
estimator = Estimator(model)
print estimator.estimate(txt1,txt2)
このスクリプトを利用し,
$ python estimate.py [Doc2Vecのモデル名] "[文章1]" "[文章2]"
という形で,文章1と文章2の類似度を測ることが出来ます.(Doc2vecの学習部分のコードは省いています)これを用いて実験してみた結果,
kotauchisunsun-VirtualBox$ python estimate.py nda6.model "私は猫です。" "吾輩は猫である。"
0.667711547669
kotauchisunsun-VirtualBox$ python estimate.py nda6.model "私は猫です。" "私は猫です。"
0.805627031659
( ^ω^)・・・?
何度かやってみて,気づいたことですが,gensimのsimilarityは-1~1で正規化されており,1に近づくほど文章の意味が近いようです.ただ解せない点も多く,同じ文章を入れてもなぜか類似度が1.0にならないという挙動をしており,よくわかりませんでした.おそらく,similarity_unseen_docの仕様のような気はしています.あと評価値が安定せず,同じ文章に対し評価を3回行うと,だんだん値が小さくなっていく,という挙動をしていました...
作風変換実験
事前準備の時点でもう嫌な予感しかしていませんが,実際に自動生成をしてみましょう.入力は「私は猫です.」を入れています.
0.409022161426 "この事件の大部分は先刻奥さんは何です"
0.480818568261 "がいかにもつまらなくなった。"
0.559027353215 "彼は眼を失った。"
0.659924672818 "それは私は——其の人物とそこのです"
0.746559396136 "彼は夫です。"
0.781097738802 "こればかりであった。"
0.786329416341 "一人のです。"
0.802889606127 "今日の逼った。"
0.818648043016 "僕のです。"
当たり前ですが,ランダムに生成しているので,"吾輩"という単語を引き当てるだけでも実際は結構労力を使います.しかし,それ以上に"彼は夫です。"という文章が"吾輩は猫である."という文章より類似度は高いのはどうなんだ・・・?という疑問のほうが強いです.
ここで,問題を分割するために,コントロール実験をします.最初に必ず"吾輩"という言葉を選択するように,HMMのコードを改変し,自動生成してみました.こちらは比較的うまくいったので長めに流しています.今回,HMMで完全にランダムに生成しているわけでなく,10,000回生成し,平均的に点数の高かった語句を確定していき,その次の単語を試行する.という生成手法を取っています.モンテカルロ木探索に近いことをやっています.
0.0880615096769 吾輩の羽根をしていない、秋先
0.7469903088 吾輩が打ち壊された。
0.759754754423 吾輩はある。
0.780031448973 吾輩のでなくっちゃんです。
0.79565634711 吾輩のです。
0.834694349115 吾輩猫ですかと云った。
0.838936420823 吾輩猫のですか、。
0.855492222823 吾輩猫ですか。
0.85682326727 吾輩猫ですね。
0.86722014861 吾輩猫ですとはなかろうと云うと自分
0.878538129172 吾輩猫です出来ないです。
あーおしい.「吾輩猫ですか.」って聞いてるもん.そのあとに「吾輩猫ですね.」ってちゃんと言ってるじゃん.そのあと,「吾輩猫ですとはなかろうと云うと自分」とかセルフ突っ込みしたと思ったら,「吾輩猫です出来ないです。」ってやっぱお前猫やないかい.と
このように,どうやら自動生成周りにバグはないようです.そのため,「吾輩は猫である」という文章に近い文章は一応生成できるようです.しかし,文章の意味比較がいまいちな部分もあり,そのせいで上手く変換が出来ていない可能性もあります.一方で,これはサーバーの台数を増やせば試行回数が増え,正確な答えが出るのではないか?とも考えられますが,先述の例でいえば,「吾輩は猫ですね.」で,本来は試行はほぼ終わっており,それ以上は選択肢はほぼないにもかかわらず,「吾輩猫ですとはなかろうと云うと自分」という答えを導き出しているところをみると,やはり文章の意味比較の精度を上げるほうが賢明な気がします.
まとめ
文章の作風変換のアルゴリズムを考案し,実装を行った.しかし,高精度の変換とまではいかず,一部,語句を手動でコントロールすることで,当初予定していた解の近似解を求めることはできた.
応用例
チャットボットに対し,個性を付け加えるのによい手法かもしれない.
【エヴァンゲリオン】アスカっぽいセリフをDeepLearningで自動生成してみるhttp://qiita.com/S346/items/24e875e3c5ac58f55810
という記事があり,DeepLearningで式波アスカっぽい文章を生成する実験を行っている.ここで,利用しているデータに
愛するべきもの -アニメのセリフ紹介-
http://lovegundam.dtiblog.com/blog-category-7.html
というすべてのエヴァンゲリオンのキャラのセリフをまとめたサイトがあるらしい.本手法の精度向上ができると,今まではSiriのような受け答えしかできなかったパーソナルアシスタントに対し,キャラの台本のデータから個性を後付けで付与できるとすると,面白いかもしれない.
感想
もう少し精度をあげることはできるような気がしたが時間切れ.Doc2Vecのチューニングには非常に悩まされたし,実際ほとんど使われていない.というのも困った点だった.そのため,gensimのDoc2Vecの使い方もなんとなくしかわからず,1つ1つコードを動かして検証するためすごく時間がかかった.
思いついた元ネタはコレ.【6月19日は桜桃忌】プログラミングで蘇る太宰治 ( http://pdmagazine.jp/people/dazai-program/ ).これを見てなんかもうちょっと面白いことができないかなぁと思った次第.
本当は個人的には採用実績のあったBM25の意味比較を取り入れようと思ったが,やはり流行には載っておくべきか.とも思い直して,gensimからのDoc2Vecを行ってみた.
あとはどうやらMecabの性能も悪いらしい.というのは,青空文庫の文章は著作期限切れの50年前の文章のため,少し言い回しが古臭いところがある.何個が目で確認してみた結果,区切りがおかしいところが散見されたので,現代語をベースにしているMecabでは厳しい.そこも機械学習の精度に影響しているように思われる.
最近は,GANやらの敵対学習も流行っているが,やはり学習用の対応データは欲しい.このあたりがなくて,機械学習は手が出しにくいところもある.個人的にやってみて,なんとなくできてるような気がする.程度のものを作ってしまうので,あまり精度が上がらないのが現状.
私はこんな風になってしまいましたが,第2第3の自然言語処理マニアが頑張ってくれるでしょう.