概要
クリーンアーキテクチャを勉強した際,
「これって実際に自分がプロダクトを作るときにはどう設計するの?」
という疑問が浮かびました.
本に載っている内容を追うことはできる.しかし,その本から外れたような概念を扱うようになると,途端に右往左往してしまうことがありました.
特にクラスの依存関係への言及は多いのですが,実際の処理フローまでは書かれていません.そのため,クラスはかけるのですが,一通りの処理が書けないとなりました..ある程度のフローが想像できないため,クラスや関数の機能の責任範囲が分からない.実装できない.といったことに私は陥りました.
そのため,私が,クリーンアーキテクチャを勉強したときに,こうかな?と感じた別の理解,解釈を書いてみようと思います.実際に一通りの処理を書く際の一助になればと思います.注意点としては,これがクリーンアーキテクチャのすべてではありません.省略している点も多々ありますので,ご容赦ください.
想定の読者
クリーンアーキテクチャを読んだが,実際に自分のプロダクトを設計する時に,うまく組めなかった方.
また,実装してみて,クラスの分割や,その意味付けに悩んだ方.
クリーンアーキテクチャに関して理解を深めたい方.
クリーンアーキテクチャに関する実装イメージがついていない方は,
リファクタリングして学ぶTypeScriptでクリーンアーキテクチャ
などを読んでいただければ,イメージがつくかもしれません.
クリーンアーキテクチャとは
「クリーンアーキテクチャ 達人に学ぶソフトウェアの構造と設計」のp200によると
- フレームワーク非依存:アーキテクチャは,機能満載のソフトウェアのライブラリに依存していない.これにより,システムをフレームワークの制約で縛るのではなく,フレームワークをツールとして使用できる.
- テスト可能:ビジネスルールは,UI,データベース,ウェブサーバー,その他の外部要素がなくてもテストできる.
- UI非依存:UIは,システムのほかの部分を変更することなく,簡単に変更できる.たとえば,ビジネスルールを変更することなく,ウェブUIはコンソールUIに置き換えることができる.
- データベース非依存:OracleやSQL ServerをMongo,BigTable,CouchDBなどに置き換えることができる.ビジネスルールはデータベースに束縛されていない.
- 外部エージェント非依存:ビジネスルールは外界のインターフェースについて何も知らない.
これらのアイデアを実現するのがクリーンアーキテクチャだそうです.
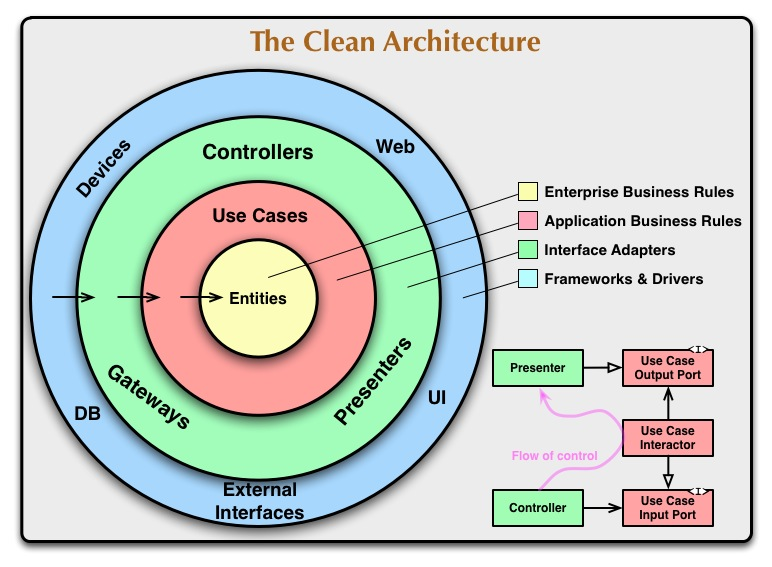
そして,それらを実現するために重要な「依存性のルール」というものがあります.
ソースコードの依存性は,内側(上位層レベルの方針)だけにむかっていなければいけない.
例えば,UseCasesにあたるクラスは,Entitiesにあるクラスに依存してもよいが,Controllersに含まれるクラスに依存してはならない.もし下位のモジュールが上位のモジュールに依存してしまう場合は,上位のモジュールにインターフェースを定義し,下位モジュールで,それを実装することで依存性の逆転を図ります(後述).このルールを守ることで,コードがクリーンに保たれるようです.
また,クリーンアーキテクチャには以下のような図が掲載されています.これは「典型的なシナリオ」と本文では記載があり,記事では,この内容を参考にしていこうと思います.

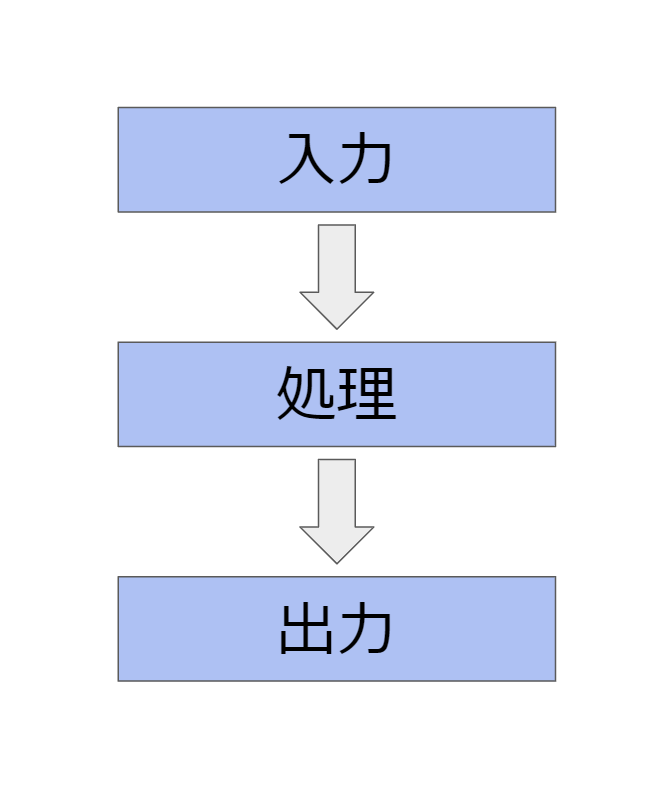
プログラムの基本形
プログラムの基本形とは何か?というと,
- 入力
- 処理
- 出力
の3つの手順を踏むことになります.
例えば,「消費税込みの値段を計算する.」という題材だと,
- ユーザーが商品の値段を入力(入力)
- 消費税込みの値段として,入力された値段を1.08倍する(処理)
- 消費税込みの値段を出力(出力)
といった形で分けることができます.
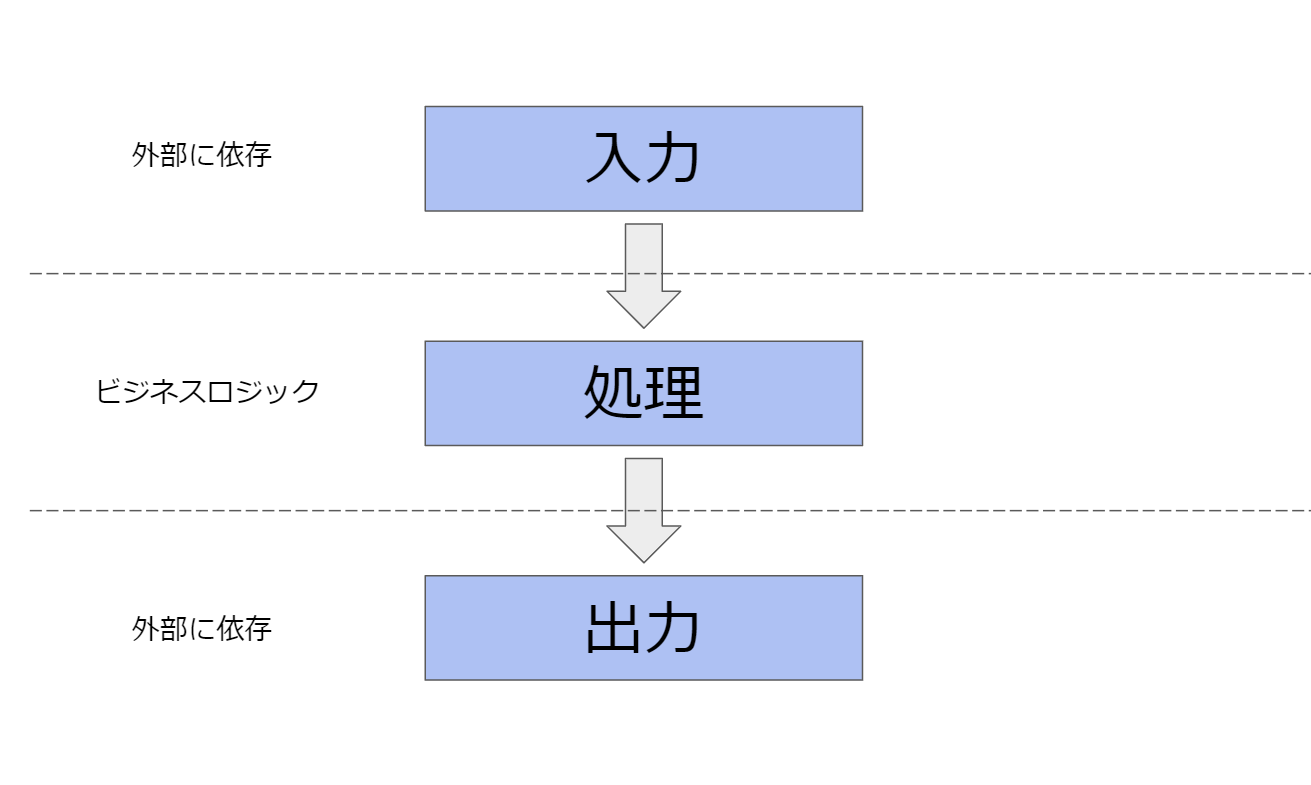
ビジネスロジックと外部への依存
「消費税込みの値段を計算する.」ということを考えたとき,それに付随する,「ユーザーからの入力」「ユーザーへの出力」というのは,本質的にはビジネスロジックとは関係ありません.例えば,値段の入力がコマンドラインかREST APIのPOSTのボディか.もしくは音声UIか.といったことは関係ありません.また,出力がパソコンのディスプレイか,スピーカーから流れる音声なのかも関係がありません.入力や出力の方式が変わっても,後々ビジネスロジックを使いまわすために,「入力」と「出力」など外部への依存の部分は,「処理」と切り離しておきたい.という要求があります.
ビジネスロジックへの橋渡し・ビジネスロジックからの橋渡し
ここで,「入力」や「出力」などの「外部の依存」から「処理」を守るためにはどのようにすればよいか?を考えます.
そうすると,「処理」にまつわる「入力データ」と「出力データ」を自分で定義するという方法があります.これが図の「UseCaseInputData」と「UseCaseOutputData」という部分です.このように自分で定義することで,「入力」や「出力」にかかわるフレームワークや環境が変わったとしても,吸収できるようになります.
この部分はp180の「恐怖のモノリス」が詳しいです.
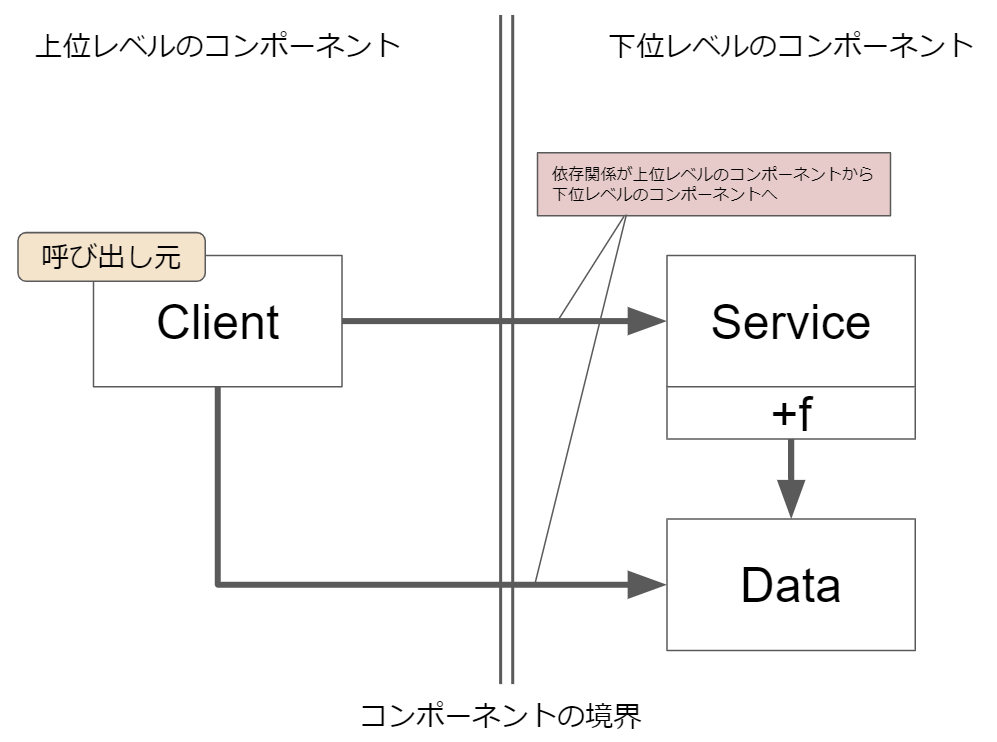
「恐怖のモノリス」では,ClientがServiceを呼び出すというケースを紹介しています.何も考えずに普通に実装してしまうと,下記のような依存関係になります.こうしてしまった場合,呼び出し元の上位レベルのモジュールであるClientが下位レベルのモジュールの実装に依存してしまいます.
このような上位レベルのモジュールが下位レベルのモジュールへ依存してしまうと,下位モジュールの変更が上位モジュールへ波及し,保守性の悪い実装になります.
そのため,書籍では以下のような設計を勧めています.
上位レベルのコンポーネント側に,ServiceInterfaceというInterfaceを作ります.下位レベルのコンポーネントでは,そのServiceInterfaceを実装した,ServiceImplというクラスを作成します.そして,上の図では下位レベルのコンポーネントで定義されていたDataと呼ばれるクラスを上位モジュールの方で定義します.
これにより,上の図では,「上位コンポーネントから下位レベルのコンポーネントへ向かっていた依存関係」を,「下位レベルのコンポーネントから上位コンポーネントへ向かう依存関係」へ移すことで,下位レベルのコンポーネントのクラスの実装へ依存しない設計を行っています.
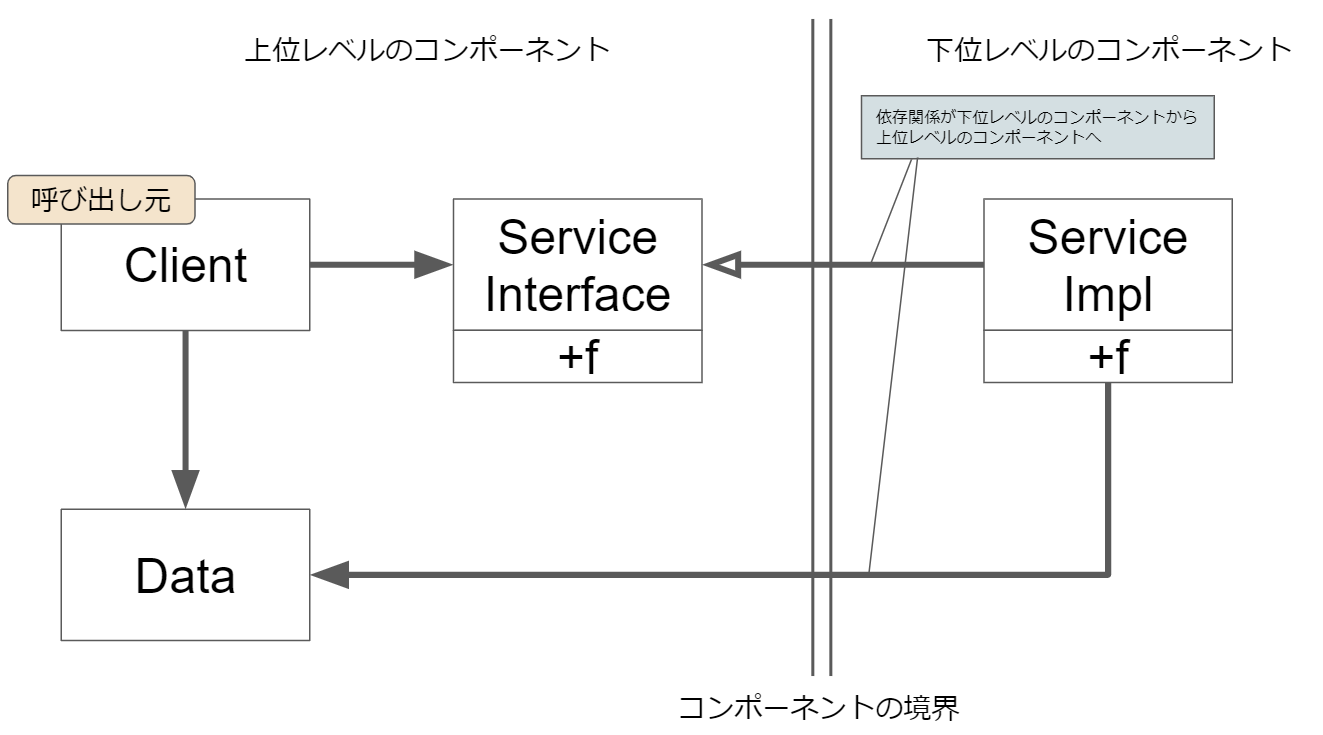
先ほど書いた,「『処理』にまつわる『入力データ』と『出力データ』を自分で定義する」という行為は,上図のDataの定義を上位レベルのモジュールに移行することと同義で,UseCaseInputDataやUseCaseOutputDataの定義をUseCase側へ寄せることで,実装への依存を少なくしています.(もちろん,それに伴ってControllerのInterfaceもUseCase側に実装する必要があります.)
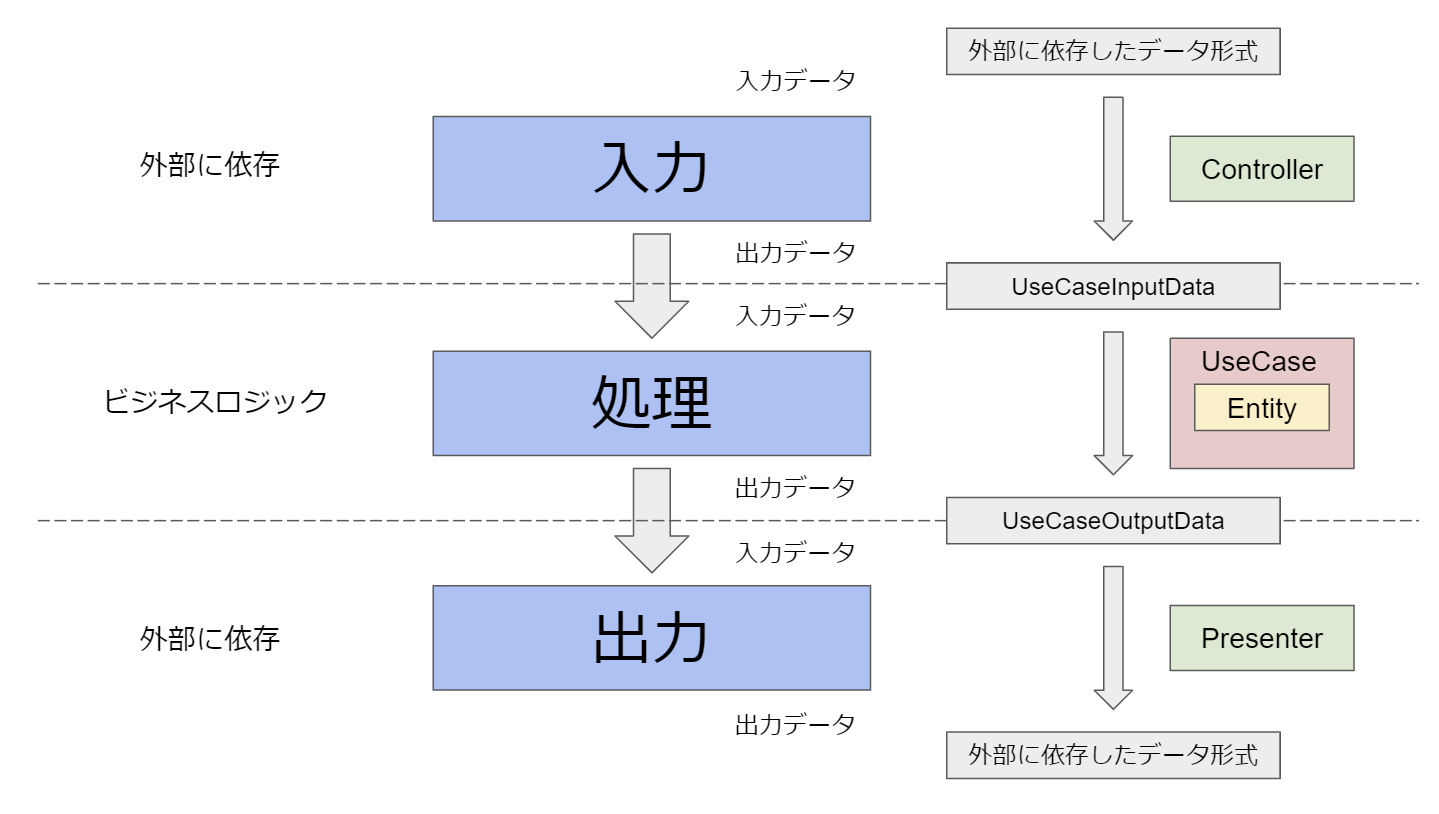
それらから,入力や出力に関してのフローの解釈を整理すると以下のようなまとめになります.
- 入力(Controller)の役割は外部に依存したデータ形式を**ドメイン固有のデータ形式(UseCaseInputData)**へ変換すること
- 処理(UseCase/Entity)の役割は**ドメイン固有のデータ形式(UseCaseInputData)をドメイン固有のデータ形式(UseCaseOutputData)**へ変換(処理)すること
- 出力(Presenter)の役割はドメイン固有のデータ形式(UseCaseOutputData)を外部に依存したデータ形式へ変換すること
と捉え直すことが出来ます.
UseCaseInputDataやUseCaseOutputDataをUseCase側で定義することにより,外部の環境へ依存する部分を分離し,処理の部分を"クリーン"に保つことが肝だと思います.
境界を超えるデータ
ここで,UseCaseInputDataとUseCaseOutputDataはクリーンアーキテクチャの書籍では「境界線を越えるデータ」として書かれているものです.
境界線を越えるデータは,単純なデータ構造で構成されている.好みに応じて,構造体やデータ転送オブジェクトを使うこともできる.単なる関数呼び出しの引数にすることもできる.ハッシュマップに詰め込んだり,オブジェクトにしたりすることもできる.境界線を越えて渡すのは,独立した単純なデータ構造であることが重要だ.
UseCaseInputDataはInterfaceAdapter層からApplication Business Rule層を超える.UseCaseOutputDataはApplication Business Rule層からInterfaceAdapter層を超える,「境界線を超えるデータ」です.
この「境界を超えるデータ」はライブラリやプラットフォームに依存したデータ(ライブラリのSQLのRaw等)を持つべきではない.とされています.言語標準な型や,自分で定義したクラスを使うことで,ライブラリの依存性をビジネスロジックに持ち込むことが少なくなります.
シーケンス図で見るクリーンアーキテクチャ
この記事の最初に掲載した,クリーンアーキテクチャに関する有名な図がありますが,それだけだと実際に処理を組む際に,処理フローが混乱し組み辛いことがあります.そのため,一度シーケンス図に起こしました.(C#による実例であれば実装クリーンアーキテクチャが詳しい)
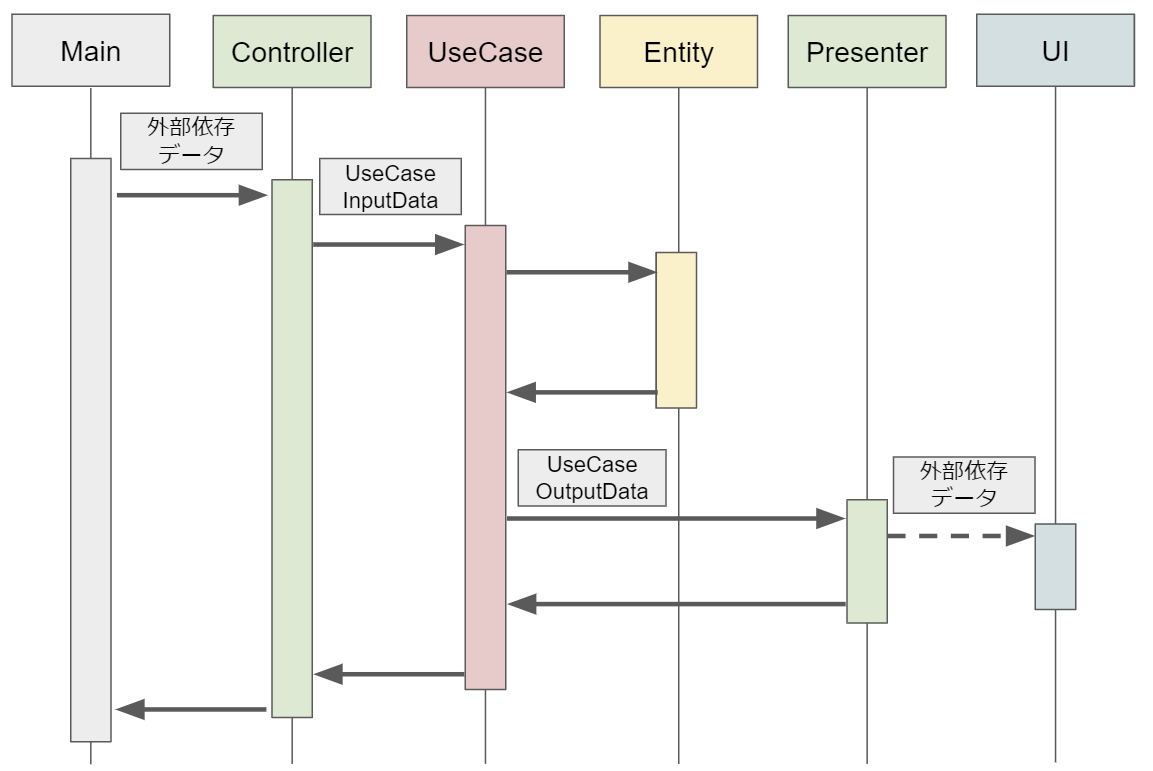
- Mainから「外部依存データ」(外部に依存したデータ形式)とともにControllerが呼び出されます.
- Controllerは「外部依存データ」から必要な情報を抽出し,UseCaseInputData(ドメイン固有のデータ形式)に詰め直して,UseCaseを呼び出します.
- UseCaseはUseCaseInputDataからデータを抽出し,ビジネスロジックであるEntityを通して,処理を行います.その後,処理結果を,UseCaseOutputData(ドメイン固有のデータ形式)に詰めて,Presenterを呼び出します.
- PresenterはUseCaseOutputDataの内容を読み取って,UIへ表示する用の「外部依存データ」(外部に依存したデータ形式)に詰め直して,UIへの表示を行います.
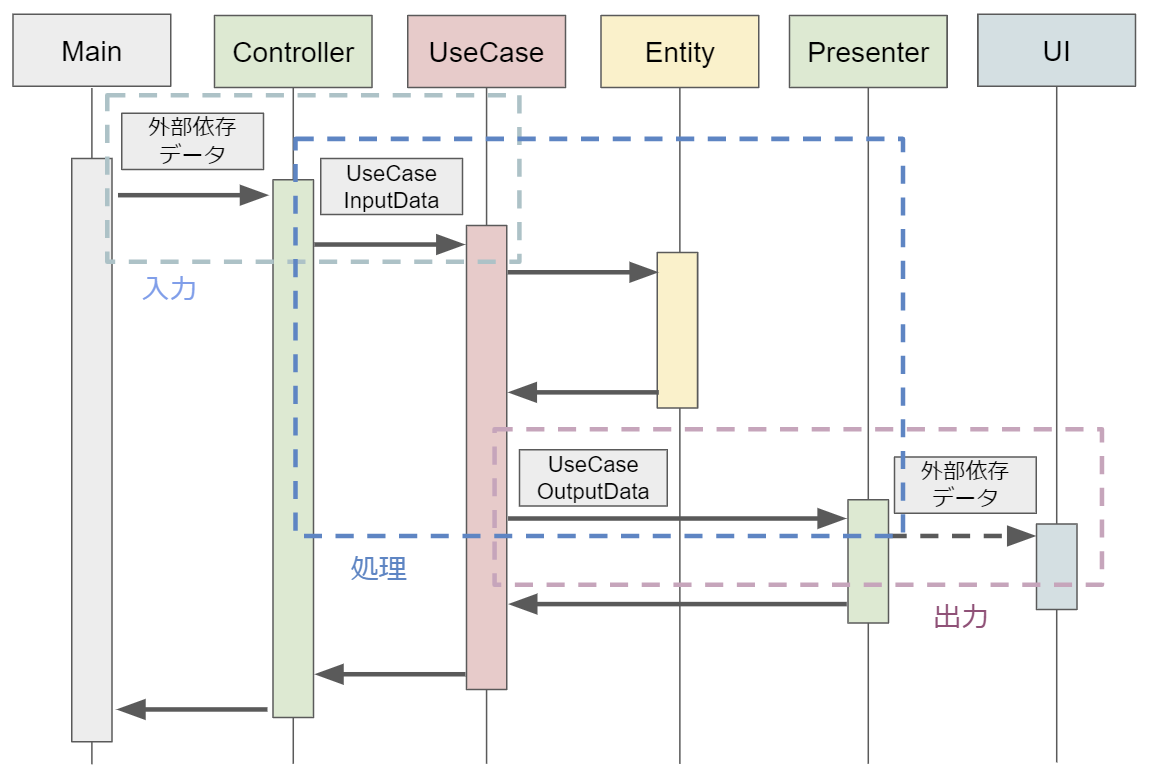
これを見ても
- Controllerが「外部依存データ」から「UseCaseInputData」への変換
- UseCaseが「UseCaseInputData」から「UseCaseOutputData」への変換(処理)
- Presenterが「UseCaseOutputData」から「外部依存データ」への変換
と,前節の内容と一致していることが分かります.
クリーンアーキテクチャの適用限界
ソフトウェアの品質に関する国際基準であるISO/IEC9126には以下のような品質特性が挙げられています.
| 品質特性 | 詳細 |
|---|---|
| 機能性 | ソフトウェアが使用される目的に合っていること |
| 信頼性 | ソフトウェアが安心して使える度合い |
| 使用性 | ソフトウェアの使いやすさ |
| 効率性 | ソフトウェアの性能 |
| 保守性 | ソフトウェアが仕様変更に強く,テストが容易なこと |
| 移植性 | ソフトウェアが現在動いている環境から,別の環境への移行が容易なこと |
クリーンアーキテクチャは,この中で言う「移植性」と「保守性」にフォーカスしたアプローチだと言えます.「入力」や「出力」の部分をうまく抽象化することにより,ソフトウェアの「移植性」を非常に高めたアプローチだといえます.そして,それに付随して,外部への依存がきれいに処理部分と分離できることにより,テスタビリティが高まっています.そのため,テストを書きやすいアーキテクチャになっています.そのため,結果論的に「保守性」が上がっているアーキテクチャになっています.もちろん,クリーンアーキテクチャだからと言って,「保守性」が上がるわけではなく,テストを書かなければ,「保守性」は上がりません.そのテストを書くコストを下げられるのがクリーンアーキテクチャになります.
逆に言ってしまえば,そのほかの品質特性の改善は少ないように思います.
例えば,「機能性」に関していえば,ほぼほぼUseCaseとEntityの部分にまとめられており,複雑な業務ロジックに関しての言及は少ないです.その部分に関しては,どちらかというとドメイン駆動開発のようなアプローチの適用を行うほうが良いと思います.一方で,これはソフトウェア設計論のアプローチなので,組織や開発形態として「機能性」の改善を図るのであればアジャイル開発の手法になると思います.
当たり前ですが,「銀の弾丸」は存在せず,Issueにあった解決手法を選ぶべきです.
まとめ
今回は,クリーンアーキテクトの実装の意味付け,別視点からの解釈,特有のモジュール構成やクラスの実装をする理由についてまとめました.実際,私がクリーンアーキテクチャで組んだプログラムはそんなに数はないですが,組んでみるとテストが非常にしやすいアプローチであると感じます.その一方で,前の記事にも書きましたが,コード量がかなり増えるアーキテクトでもあります.その意味では,結構しんどい開発手法だったりします.
そして,結局のところソフトウェアアーキテクチャというものも開発する組織に依存するものだとも思います.開発メンバー内でアーキテクチャに関する共通認識がずれていると,その恩恵は受けられません.そして,このようなアーキテクチャ論は,やはり一定の練度が必要ですし,アーキテクチャに関する知識もそれなりに要求されます.複数人開発だと,技量や知識理解の粒が揃うことのほうが稀ですし,それらの共通認識を持つところからスタートするので,しんどいな.と思います.結局のところソフトウェア開発は究極的なところで属人化するなぁと感じます.したがって,導入するときには,慎重な一歩が必要だと思います.