リファクタリングの鶏卵問題
ソースコードがクソなので綺麗にしたい。
リファクタリングしたい。
しかし、リファクタリングが出来ない。
リファクタリングが出来ないのは、テストが無いからだ。
よし。じゃあテストを書こう。あれ、テストが書けない?
そのようなテストが無く、書き換えられないことによる矛盾や憤りは皆さん何百回と感じてきたと思います。
しかし、この「テストが出来ない」ということを言語化するのは、非常に難しいと思います。それは、「テストが出来ない」には実は2つの視点があります。
- 本質的にテストが困難なモジュールで、誰がやってもテストが書けない。
- 本質的にモジュールはテスト可能だが、自分の実力が足りず、自分ではテストが書けない。
1.のようなテスト困難なモジュールは誰がやってもテストは書けないです。しかし、問題は、「テストを書きたい」と思ったとき、「自分がそれほどテストに詳しくない」という場合が多いと思います。その時、自分がテストがしたい対象が、「テスト困難なモジュール」なのか「ただ実力不足なのか」が見分けがつかない。という問題が発生します。
実は、昨今のソフトウェア開発において、本質的にテストが困難なモジュールは多い。本質的にテスト困難なモジュールが多くなってしまう。 と私は思います。しかし、一方でテスト困難だと思って、テストをあきらめる選択肢も選べないでしょう。このドキュメントでは、「本質的にテストが困難なモジュールを見極め、それをテスト可能な形に変形する方法」 を紹介したいと思います。
テスト出来ないを回避する
以下では、"典型的なテスト出来ない関数"を例示していきます。そして、それぞれにおいて、テスト可能にするために、どのように回避するかの処方箋を書きます。
直接IOを操作する関数
以下のようなUserの情報を標準出力に書き込む機能があったとします。これはテストできません。
def print_user(user):
print(f"[id:{user.id} name:{user.name}]")
この関数はユーザーのデータを受け取ると、[id:1 name:Taro]のような形で標準出力に書き込まれることを期待しています。しかし、標準出力にどのような文字列が書き込まれたのかを検証する術はありません。このようにファイルやIOが絡むものに関しては、テスト出来ないことが多々あります。そういった関数は以下の様に書き換えると良いです。
def print_user(user,file):
print(f"[id:{user.id} name:{user.name}]",file=file)
def test_print_user():
user = User(1,"Taro")
with io.StringIO() as s:
print_user(user,s)
assert s.getvalue() == "[id:1 name:Taro]\n"
これは関数に対する解釈を少し変える必要があります。もともとのprint_userは「Userのデータを受け取り、"[id:{user.id} name:{user.name}]"のフォーマットに文字列を成型する機能」、「標準出力に書き込む機能」の部分の2つに分けられます。このうち、「標準出力に書き込む機能」の解釈を変更し、「ストリームに書き込む機能」ととらえなおします。そうすると、出力先をStringIOに置き換えることが可能で、StringIOのgetvalueから書き込まれた文字列の情報を取得し、その値を比較することで関数が動作していることを確認することが出来ます。
このようにIOなどが絡む系では、その書き込み先(この場合ではストリーム)を固定せず、引数等で指定出来るようにすることで、出力を検証できるように変形します。
現在時刻に依存する関数
大量のデータを扱っていると、ファイルの命名などにYYmmDDHHMMSSのような現在時刻を扱う文字列が欲しくなることがあるでしょう。しかし、このような関数はテストできません。
def get_timestamp_str():
now = datetime.datetime.now()
return now.strftime("%Y%m%d%H%M%S")
これは、以下の様にdateを引数に渡すことで回避し、テストします。
def get_timestamp_str(date):
return date.strftime("%Y%m%d%H%M%S")
def test_get_timestamp_str():
date = datetime.datetime(2020,4,14,15,31,0)
assert get_timestamp_str(date) == "20200414153100"
現在時刻をプログラム上で取り扱うことは、よくあると思いますが、不用意に取得して処理を作りこんでしまうとテストできなくなります。これは現在時刻を自由自在に変更する方法がプログラマーにはないからです。ファイルの生成日時など、一般的に日時・時刻を扱う場合は、それほど気にしなくてよいのですが、現在時刻を扱う場合は、簡単にテスト不能な構成を作りこんでしまうので、割と繊細に気を付ける必要があります。そのため、現在時刻を元に処理をするようなケースであれば、引数でデータを渡して検証可能な設計にする必要があります。
乱数に依存する関数
乱数は本質的に予測不能です。したがって、以下のようなサイコロを振る関数はテスト不能です。
def roll_dice():
return random.choice([1,2,3,4,5,6])
このような関数はテスト可能なのか?というとやりようがないわけではないです。1つの方法に乱数のシード値を固定してしまう。という手があります。
import random
def roll_dice(generator):
return generator.choice([1,2,3,4,5,6])
def test_roll_dice():
generator = random.Random(1)
for r in [2,5,1,3,1,4,4,4,6,4]:
assert r == roll_dice(generator)
pythonのrandomにはシード値を固定した乱数発生器を生成する方法があります。したがって、テスト側では乱数のシード値を固定して、引数に渡すことで、いつでも同じ結果が返すことができるようになるため、テスト可能になります。この時、検証すべき値(この場合では2,5,1,3,...)は、事前にprintなどで出力しておき、それをテストコードに移植しています。
しかし、それはテストになっているのか?という疑問があると思うので、以下のようなテストの方法もあるので、書いておきます。
import random
def test_roll_dice2():
generator = random.Random(1)
m = 1000
n = 6 * m
count = [0] * 6
for i in range(n):
count[roll_dice(generator)-1] += 1
for i in range(6):
assert abs(count[i] - m) < m*0.1
これは、6000回、サイコロを振って、それぞれの目の出現回数が900~1100であることを検証しています。偏りのないサイコロは二項分布Bin(6000,1/6)に従う乱数とみなすことができます。この条件で、目の出る回数が1100回となる場合の上側累積確率が3.28E-4でした。また、同様に目の出る回数が900回である場合の下側累積確率が2.41E-4でした(参考)。したがって、成功回数が900~1100に収まらない確率は、おおむね1e-3以下となります。したがって、目の出る回数が900~1100回に収まる確率は99.9%と計算できます。そのため、上記の判定に合格していれば「1~6の目がおおよそ均等に出ている」という見方が出来ます。
しかし、これでも完ぺきではなく、本当に数列が乱数であるという検定は難しく、1,2,3,4,5,6という数を順に繰り返し生成するだけの関数でも上記のテストはクリアしてしまうので、本当に統計的に正しい処理を行いたいのであれば、"生成された値が乱数である"というテストも必要です。この話は、統計的な検定の話で割と難しい数学の話になるので、ここでは取り扱いません。余談ですが、そもそもC言語の乱数は周期が短いなど性質が悪いので、本当は乱数を生成する関数の内部実装まで注意する必要があります。
(注釈:C言語の標準のrandは線形合同法であるため乱数の性能が悪い。という理解をしており、そのソースコードらしい部分は見つかりました。なぜ改善されないか。というと、どうやらISOによるC言語の仕様に沿っているため、仕様自体が線形合同法と定義されているため変えられない。と私は予想していますが、ISOの定義までは調べきれなかったので参考程度に考えておいてください。)
ここで1つ考えておくべきポイントは、「テストには観点がある」 ということです。test_roll_diceの方では、「少数の試行で、おそらくランダムに出現しているということ」をテストしています。一方、test_roll_dice2では、「大量の試行で、その出力の回数が900~1100で、出目が均等であること」をテストしています。したがって、それぞれのテストで見ている視点が微妙に違います。そのため、問題やソフトウェアの仕様によって、行うべきテストの視点をよく考える必要があります。
環境変数に依存する関数
例えば、以下のような環境変数から設定値を取り出し、HTTPリクエストをするような関数を作ったとします。
import os
import requests
def post_request(payload: dict):
protocol = os.environ.get('PROTOCOL', 'http')
host = os.environ.get('HOST', 'localhost')
return requests.post(f'{protocol}://{host}/post',json=payload).json()["json"]
実務上では、ステージング環境や、本番環境でリクエストするURLが違ったりするため、このような機能を作りこみたい場合があります。これは、実はテスト可能です。そのためには以下のようなテストコードで実行可能です。
import os
def test_post_request():
os.environ["PROTOCOL"] = "https"
os.environ["HOST"] = "httpbin.org"
payload = {"key1": "value1", "key2": "value2"}
assert post_request(payload)==payload
今まで出てきたテストは"出来ない"というケースしかありませんでしたが、これはそうではありません。では、良いコードのなのでしょうか?答えは、「いいえ」です。
FIRSTの原則というものがあります。これは良いテストコードの指標を端的に表したものとなっています。

Test Yourself - テストを書くと何がどう変わるか
https://www.slideshare.net/t_wada/jasst-2014-hokkaidotwadatdd
- Fast(迅速)
- Independent(独立)
- Repeatable(繰り返し可能)
- Self-Validating(自律的検証)
- Timely(適切なタイミングでの実行)
このうち、Independentという指標があります。これは、「各テストケースが独立している方が良いテストである。」ということを表しています。どういうことかと言うと、あるテストケースを実行したときに、別のテストケースに影響を与えない方が良いテストである。 ということです。今回書いたテストケースではos.environ["PROTOCOL"] = "https"のようにグローバルな環境変数の書き換えを行っています。したがって、この環境変数の書き換えが他のテストケースに干渉していまい、テストを不安定化させる原因となり得るので、このようなテストケースは避けるべきです。では、どのように書き換えると以下のような書き方が出来ます。
def post_request(protocol: str, host: str, payload: dict):
return requests.post(f'{protocol}://{host}/post',json=payload).json()["json"]
def test_post_request():
protocol = "https"
host = "httpbin.org"
payload = {"key1": "value1", "key2": "value2"}
assert post_request(protocol, host, payload)==payload
protocolやhostの部分を引数にすることで、テストでリクエストする際のプロトコルやホスト名を制御可能にすることで、テスト可能にします。これには、もう1つ書き方があって、
class RequestConfig:
def __init__(self, protocol, host):
self.protocol = protocol
self.host = host
@staticmethod
def build_from_environment(self):
os.environ["PROTOCOL"] = self.protocol
os.environ["HOST"] = self.host
def post_request(request_config: RequestConfig, payload: dict):
return requests.post(f'{request_config.protocol}://{request_config.host}/post',json=payload).json()["json"]
def test_post_request():
request_config = RequestConfig(protocol="https", host="httpbin.org")
payload = {"key1": "value1", "key2": "value2"}
assert post_request(request_config, payload)==payload
このように、protolやhostを1つの設定値として扱うクラスを定義してしまって、それを引数として渡すのが個人的な好みです。この場合であれば、protocolとhostは必ず2つで1つの扱いなので、それを集約して扱う方が取り回しがしやすいと思います。またREST APIを組む場合のような、非常に多くの設定値をを必要とする時、それらを意味的なグループ化せずに取り扱ってしまうと、コードが煩雑になる場合があります。そのため、このようなConfigのクラスを作ることが私は多いです。
しかし、これではREST APIのリクエストごとにConfigが必要となってしまい、呼び出し元でRequestConfig.build_from_environment()のような呼び出しが多発し、非常に煩雑になってしまいます。したがって、私の場合は、そのような実装を行わず、REST APIの呼び出し部をクラスにしてしまい、DIコンテナと合わせて使います。
from injector import Injector, inject
class ApiClient:
@inject
def __init__(self, request_config: RequestConfig):
self.request_config = request_config
def post(self, payload: dict):
return requests.post(f'{self.request_config.protocol}://{self.request_config.host}/post',json=payload).json()["json"]
def test_post_request():
def configure(binder):
binder.bind(RequestConfig, to=RequestConfig(protocol="https", host="httpbin.org"))
injector = Injector(configure)
api_client = injector.get(ApiClient)
payload = {"key1": "value1", "key2": "value2"}
assert api_client.post(payload)==payload
ここではテストの形式で表記していますが、configure内で、RequestConfigを初期化し、それをDIコンテナに設定しておくことで、api_clientを取り出しやすい状態で管理し、それで実装を行う場合が多いです。実務的には、mainにあたる関数でDIコンテナを初期時にRequestConfig.build_from_environmentを呼び出し、インスタンスを登録することで、環境変数と連携し、動作させます。
テスト困難の体形化
新人プログラマに知っておいてもらいたい人類がオブジェクト指向を手に入れるまでの軌跡によい図があったので引用します。
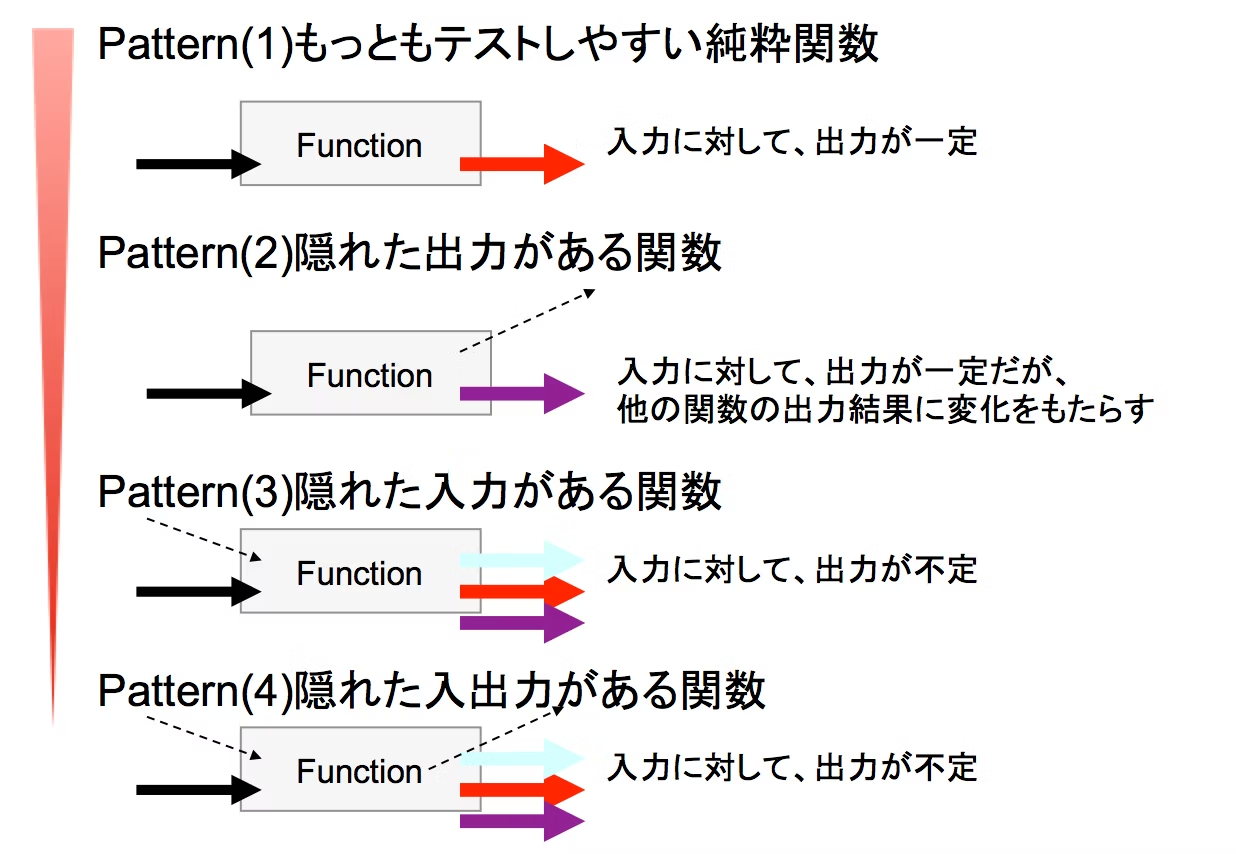
関数に対する入力・出力のタイプ・振る舞いに関して分類されており、パターン1が一番テストしやすく、パターン4が一番テストしにくい。です。
パターン1に関しては、簡単で、
def add(a,b):
return a+b
のような純粋な関数で、入力に対して、出力が一定である関数です。 基本的には、このパターン1に関数の形を変形してくことがポイントとなります。
パターン2に当てはまるのが前節の「直接IOを操作する関数」です。print_user関数自体は返り値のない関数のため出力は一定です。しかし、標準出力へ暗黙的に影響を与えるような関数でした。したがって、パターン2と分類できます。この場合、関数は直接標準出力へ書き込んでおり、関数の影響が観測できなかったため、print_userの引数にfileを渡し、出力を観測できるように変形しました。
パターン3に当てはまるのが「現在時刻に依存する関数」「乱数に依存する関数」「環境変数に依存する関数」です。「現在時刻に依存する関数」では、元々、get_timestamp_strは引数にdateを取らず、内部的に直接、datetime.nowを呼び出していました。そのため、現在時刻という隠れた入力が存在しました。そういった隠れた入力を明示的にするため、引数にdateを引き出し、テストできるようにしました。「乱数に依存する関数」も同様で、random.choiceはpythonのインタープリターの「内部的な乱数の初期化」に依存していました。そのため、この「内部的な乱数の初期化」が隠れた入力となっていました。したがって、それを明示化し、動作を固定化するために、引数にgeneratorを渡し、テスト可能な状態に変形しました。「環境変数に依存する関数」も同じで、関数内で直接環境変数を取り出すことで、それが隠れた入力となっていました。そのため、設定値を扱うConfigクラスを定義し、関数呼び出し時(クラス初期化時)に随時渡してやることで、隠れた入力を無くす工夫をしていました。
以上のようなテストが可能になるモジュールの変形は、実践テスト駆動開発 テストに導かれてオブジェクト指向ソフトウェアを育てる P240 「第20章 テストの声を聴く」に詳しく書かれています。個人的にお勧めなのでぜひ読んでみてください。
では、パターン4はどのような例があるでしょうか?例えば、DBへユーザーの情報を登録するcreate_user関数の動作を考えてみます。
> create_user("kotauchisunsun")
{"id":1, "name":"kotauchisunsun"}
> create_user("kotauchisunsun")
raise Exception("user is duplicated.")
以上はREPLの出力結果のようなものですが、雰囲気はつかんでもらえると思います。
最初に、create_user("kotauchisunsun")と行ったとき、{"id":1, "name":"kotauchisunsun"}と応答が返ってきました。これでユーザー登録が完了できたと思われます。しかし、もう一度、create_suer("kotauchisunsun")と実行すると、raise Exception("user is duplicated.")と出てきました。これは、パターン4における、「入力が同じなのに出力が不定である」という性質が見受けられます。これは、「DBへユーザーの情報を登録する」というユースケースでした。一般的なサービスであれば、同じ名前のユーザーは登録できないような仕様であることが多いでしょう。したがって、一度目のcreate_userのタイミングでDBへデータが保存され、その保存内容が影響して、出力が変化していると考えられます。ここから、既にDB内にkotauchisunsunというユーザーが存在する=隠れた入力があることが分かります。ここから、このようなユースケースはパターン4であることが分かります。こういったケースはテストが難しいため、次の章で詳しく取り扱いたいと思います。
テスト出来ないと戦う
では、さらにテストが困難なコードとはどのようなものかを深堀していきます。
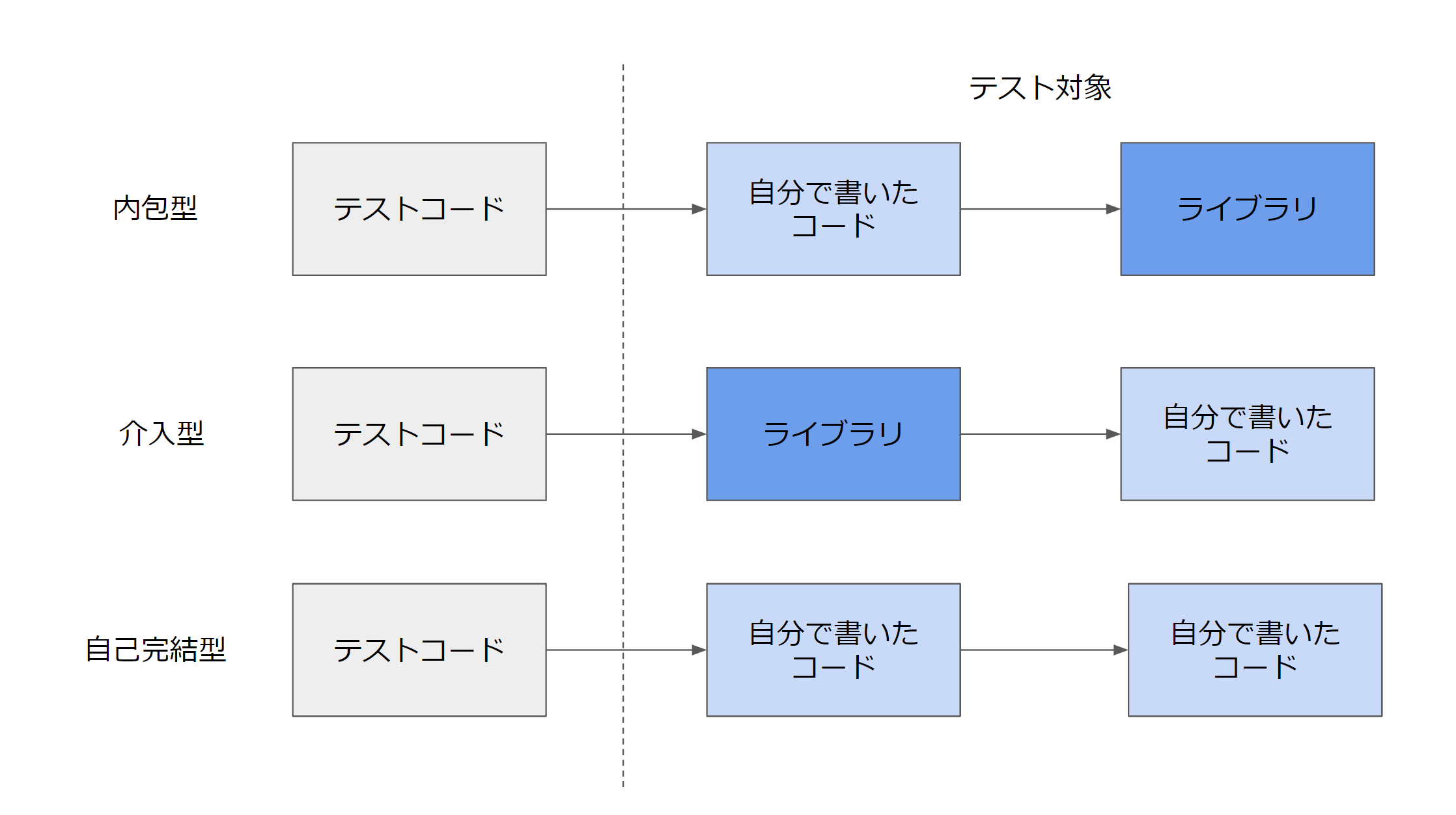
あるコードをテストしたいときに、テストコードが「自分で書いたコード」を直接呼び、その「自分で書いたコード」から「ライブラリ」を呼び出す形式を、ここでは「内包型」と呼びます。一方で、テストコードが「ライブラリ」を直接呼び、その「ライブラリ」が、「自分で書いたコード」を呼び出す形式を、「介入型」とここでは呼ぶことにします。以降で、その実例を見ていきます。
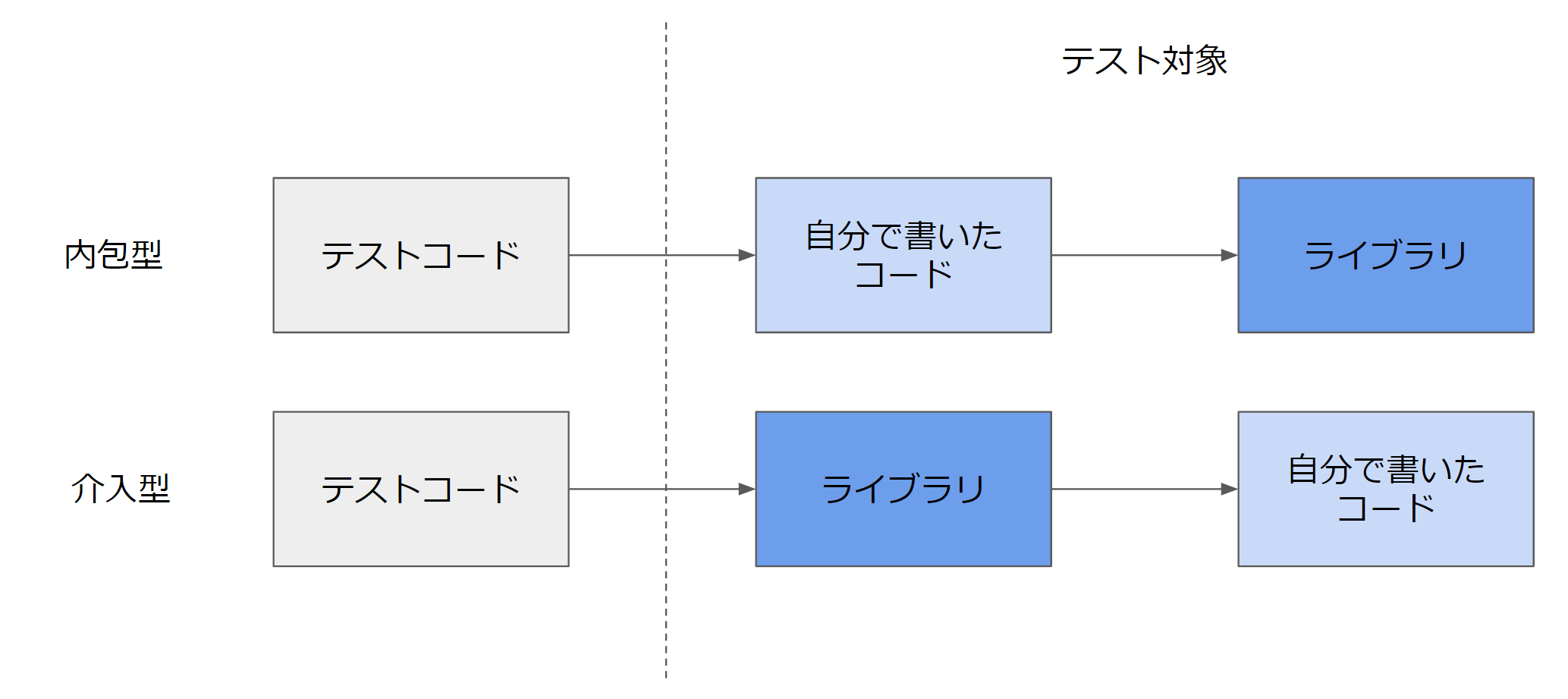
内包型のテストパターン
「内包型」と呼ばれるパターンで一番よく目にするのはリポジトリパターンです。いわゆるデータを保存するときは、ほぼこの形態になります。
from typing import Optional
from sqlmodel import Field, Session, SQLModel, create_engine,select
from dataclasses import dataclass, field
class UserModel(SQLModel, table=True):
user_id: Optional[int] = Field(primary_key=True)
user_name: str
@dataclass
class User():
user_id: int
user_name: str
class UserRepository:
def __init__(self, engine):
self.engine = engine
def find(self, user_id: int) -> User:
statement = select(UserModel).where(UserModel.user_id == user_id)
with Session(self.engine) as session:
user_model = session.exec(statement).first()
return User(user_id=user_model.user_id, user_name=user_model.user_name)
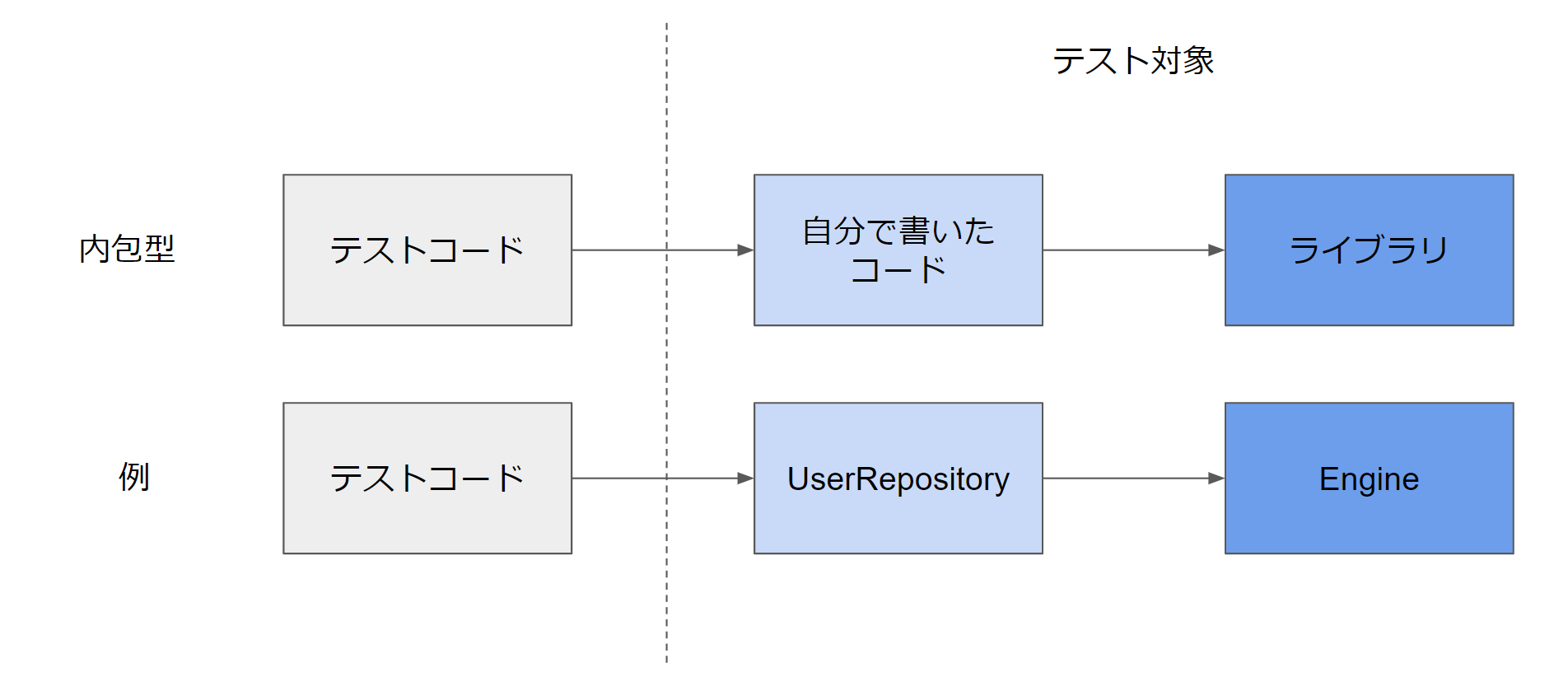
上のコードはsqlmodelというORMを使って簡易的なリポジトリパターンを組んでみた例となっています。先ほどの説明と対応を取ると、「自分で書いたコード」が「UserRepository」にあたり、「ライブラリ」にあたるのが「Engine」となります。
テストコードを書くと、以下の様になります。
from sqlmodel import SQLModel, create_engine, Session
from sql import UserModel, UserRepository
def test_find():
engine = create_engine("sqlite:///")
SQLModel.metadata.create_all(engine)
with Session(engine) as session:
user_id = 1
user_name = "kotauchisunsun"
user_1 = UserModel(user_id=user_id, user_name=user_name)
session.add(user_1)
session.commit()
repository = UserRepository(engine)
user = repository.find(user_id=user_id)
assert user.user_id == user_id
assert user.user_name == user_name
大前提として、単体テストはできません。結合テストをしなくてはなりません。
このようなストレージが必要となるテストは、データのクリアが難しい面があります。そのため、ライブラリをモックをしたくなります。モックをすべきではありません。 このことは先ほども紹介した実践テスト駆動開発 テストに導かれてオブジェクト指向ソフトウェアを育てる P74 「第8章 サードパーティーコードの上に構築する」に詳しく書かれています。ここには、 「モックするのは自分の持っている型だけ」「自分で変更できない型をモックしてはならない」 という記述があります。かいつまんで説明すると、プログラムをする際、多くの人はライブラリを使いますが、その内部実装について知らずにプログラムを実装しています。これは、ある意味では自然なことで、内部実装に詳しくなくても、そのライブラリの機能の恩恵を受けられる。という面では、喜ばしいことです。しかし、それをモックしてテストするとなると、利用者側は、よく知らないライブラリの挙動を類推しながら、不完全なモックを作らざるを得ません。この状態になると、結局、実際にライブラリを使って動かしたことにはならず、テストが実際のライブラリの挙動を反映していないため、効果の薄いテストになってしまいます。そのため、書籍内では、アダプタ層を出来る限り薄く作り、インテグレーションテストすべきである。という言及があります。そのため、このような内包型のケースにおいては、多くの場合、インテグレーションテストをすべきです。
また、クラスの実装にもポイントがあり、テストが介入できるように組む必要があります。ほぼ同じように見えますが以下のコードはテストできません。
class UserRepository2:
def __init__(self):
engine = create_engine("sqlite:///database.db")
self.session = Session(engine)
def find(self, user_id: int) -> User:
statement = select(UserModel).where(UserModel.user_id == user_id)
user_model = self.session.exec(statement).first()
return User(user_id=user_model.user_id, user_name=user_model.user_name)
UserRepository2のコンストラクタの引数にengineが無いことがポイントです。UserRepositoryの場合、引数にsessionがあるために、任意のDBに向き先を変えることが出来ました。しかし、UserRepository2では、engine = create_engine("sqlite:///database.db")と内部的に接続処理をしてしまっています。これがどういう問題を引き起こすかというと、この実装だと複数回のテストが実行できません。UserModelはuser_idをprimary_keyとして持っているため、同じuser_idのユーザーを作ることが出来ません。そのため、UserRepository2を用いて、先ほどのテストと同じ内容のテストを複数回実行すると、user_id=1のユーザーが2度作成されてしまい必ず失敗するテストとなってしまいます。これは、先ほど紹介した「FIRSTの原則」における「Repeatable」、繰り返し実行可能である。という原則に違反しています。一方、UserRepositoryでは、テストの度にengine = create_engine("sqlite:///")でin-memoryのDBを生成しているため、テストが終了するたびにデータが揮発するため問題となりません。したがって、テストやプログラムを実装する際には、このようなテストのライフサイクルにも注意する必要があります。
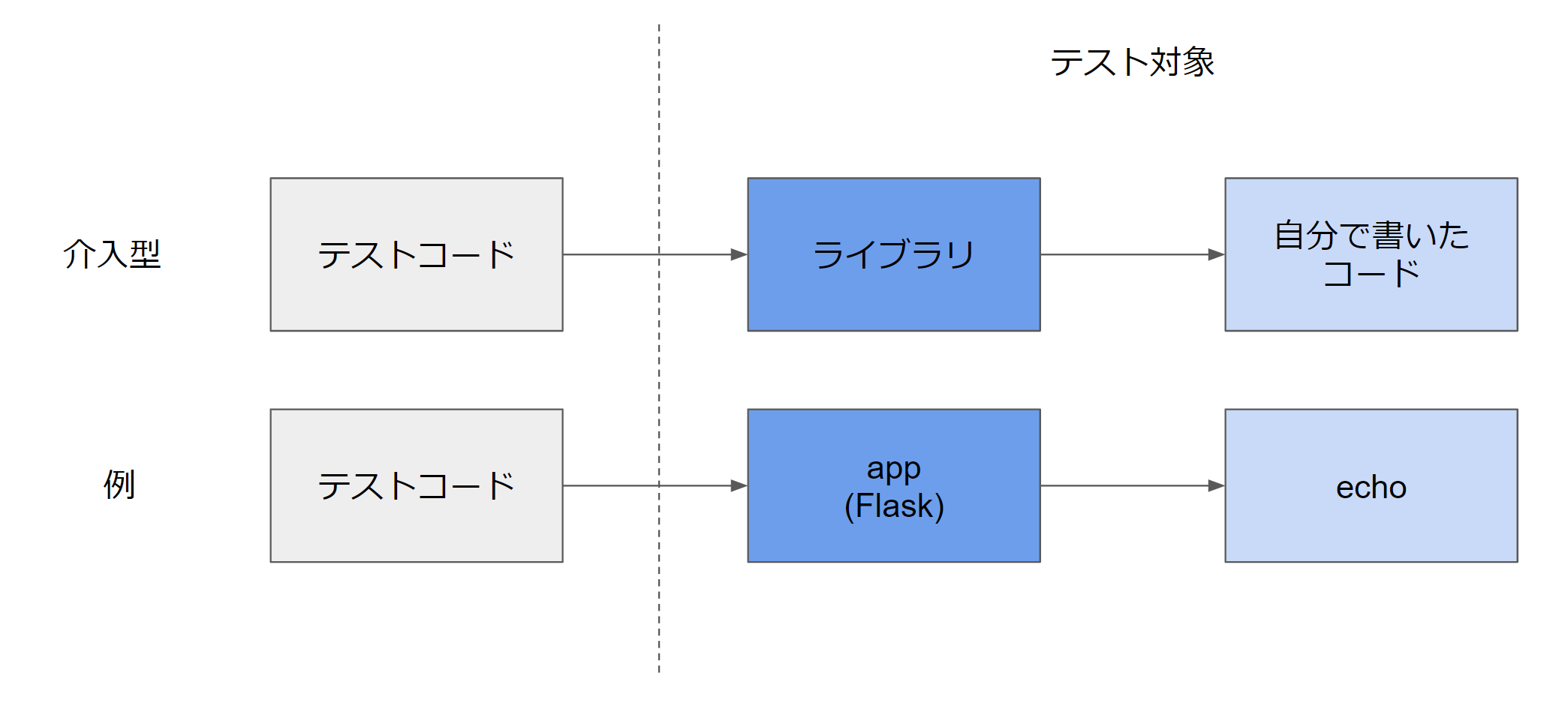
介入型のテストパターン
次に「介入型」の例です。このタイプで典型的な例はREST APIなどのハンドラーを渡すタイプです。以下では、簡単なflaskのechoサーバーを実装してみます。
from flask import Flask, request
app = Flask(__name__)
@app.route('/',methods=["POST"])
def echo():
return request.get_data()
先ほどと同じように図示すると以下の様になります。flaskのappに対して、echoをハンドラーとして登録した形になります。
これは普通にはテスト出来ないタイプです。 なぜテスト出来ないか。というと、2つの問題点があります。このサーバーはPOSTで送られたデータを、そのまま返すだけのサーバーです。機能を実現するためには、サーバー側ではPOSTされたデータにアクセスする必要があります。そのデータが入っているのが、request.get_data()です。しかし、このrequest.get_data()に直接データをいれる手段がないので不可能です。これが1つ目の問題点です。2つ目は、前章で行ったような、「データに介入できるように、関数の引数にしてしまう」という手段を思いつきます。しかし、これもできません。そもそもflaskでは、POSTのデータにアクセスする手段として、request.get_data()の形式しか対応していないため、echoの引数に何か指定したとしても、flaskが自動認識してPOSTで送られたデータを引数に入れるようなことはしません。
こういったテストをはどのようにすべきか?というと、 ライブラリのテストのドキュメントをちゃんと読む ということが必要です。
from flask_sample import app
def test_flask_sample():
app.config.update({
"TESTING": True,
})
client = app.test_client()
response = client.post("/",data=b"Hello")
assert response.data == b"Hello"
究極的な話をすると、E2Eテストするしかない。 となります。人気のライブラリには大抵の場合、テストに言及している項目があります(Flaskの場合はこのページ)。したがって、これらの内容を熟読し、それぞれのライブラリにあったテストの書き方をきちんと学ぶことが大切です。
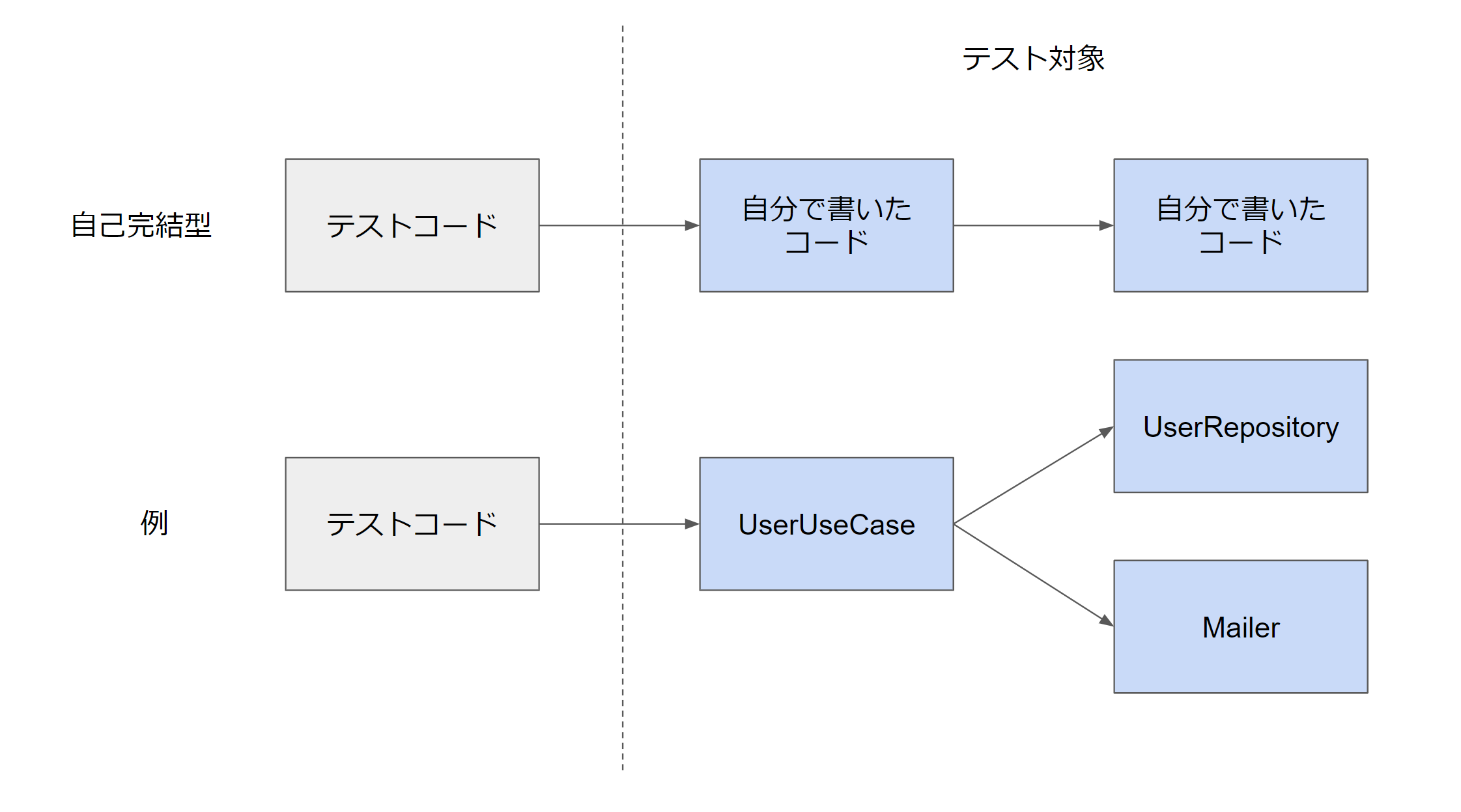
自己完結型
前章では、「内包型」と「介入型」という2つのテストの困難なパターンについて記述しました。しかし、よく考えてみると、「内包型」は、「自分の書いたコード」から「ライブラリ」の呼び出し、「介入型」は「ライブラリ」から「自分の書いたコード」の呼び出しでした。では、「自分の書いたコード」から「自分の書いたコード」を呼び出している場合はどうするべきか?という疑問があります。これを、ここでは自己完結型と呼びましょう。
例えば、以下のようなコードを考えてみます。UserUsecaseというクラスがあり、その中のユーザー作成処理で、DBへデータを保存し、その後、welcomeメールを送るというケースです。
class UserUsecase:
def __init__(self, user_repository: UserRepository, mailer: Mailer):
self.user_repository = user_repository
self.mailer = mailer
def create_user(self, name: str, email: str) -> User:
user = self.user_repository.create_user(name, email)
self.mailer.send_welcome_mail(user)
return user
これも同様に考えていくと、以下の様になります。
この場合は、どうするかというとモックを使います。
from usecase import UserUsecase, User
from unittest.mock import Mock,MagicMock
def test_usecase():
user_id = 1
user_name = "kotauchisunsun"
email = "kotauchisunsun@email.com"
user = User(user_id=user_id,user_name=user_name,email=email)
repository = MagicMock()
repository.create_user.return_value = user
mailer = MagicMock()
mailer.send_welcome_mail.return_value = None
usecase = UserUsecase(repository,mailer)
usecase.create_user(user_name,email)
repository.create_user.assert_called_once_with(user_name,email)
mailer.send_welcome_mail.assert_called_once_with(user)
先ほど、ライブラリの型はモックしてはいけない。という話をしましたが、今度は、自分で書いたコードであるため、その部分はモックしてOKです。モックの使い方ですが、基本的に、モックしたクラスが"どのような引数"で"どんな関数"が"何回呼び出されたか"を検証する必要があります。
実務的な多段クラス構成
この記事では、「内包型」「介入型」「自己完結型」の3つのパターンについて解説しました。しかし、これは実務上問題があるのではないか。と考えられるかもしれません。実務では、もっとクラスの構造が多段になっており、もっと複雑なケースがあります。その場合は、どうすればよいでしょうか?
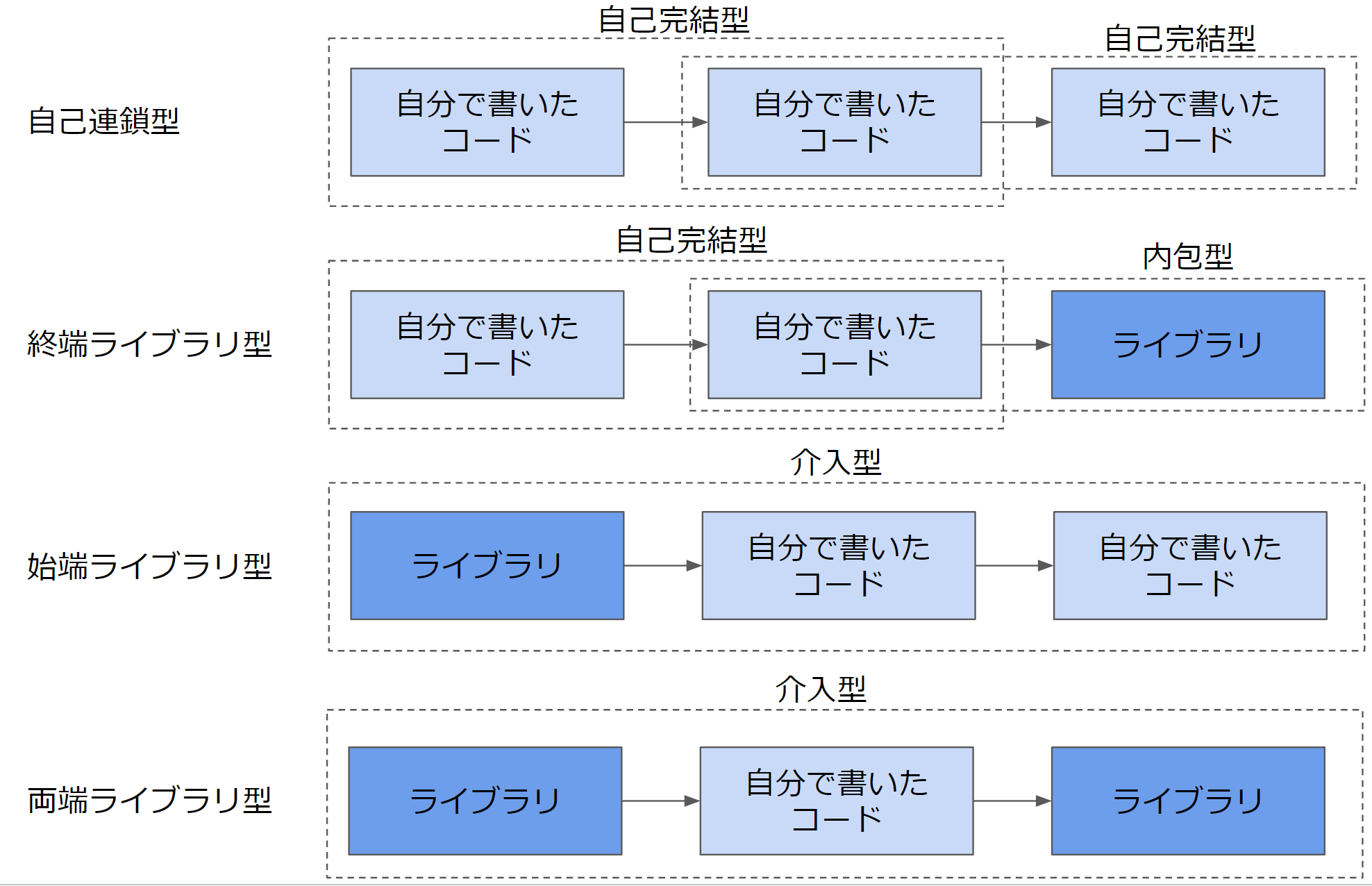
では、多段のケースについて解説します。「自分で書いたコード」が複数連結する呼び出しパターンである「自己連鎖型」は特に問題がありません。これは、部分的には、「自己完結型」となるので、それぞれの呼び出し先をモックすることにより、テストすることが可能です。次に「終端ライブラリ型」です。「自分で書いたコード」の呼び出しが連鎖した後、最終的に「ライブラリ」を呼び出すパターンです。これは、最後の「自分で書いたコード」と「ライブラリ」の部分を「内包型」としてテストを行い、それ以外の部分は「自己完結型」としてモックしてテストすればよいので比較的簡単な部類です。
難しいのは「始端ライブラリ型」と「両端ライブラリ型」です。このポイントは、最初に「ライブラリ」が来ていることです。先ほどの「介入型」の例に挙げたように、Flaskから呼び出される「自分で書いたコード」は、Flask特有の記述の仕方をする必要がありました。そのため、Flaskに登録したハンドラーのコードは単体で呼び出すことが出来ません。そのため、後続が、「自分で書いたコード」「自分で書いたコード」と連鎖していても、「自己完結型」のテストはできません。これはほぼE2Eテストと呼ばれる領域になり、システム全体を一体として動かす必要があるテストになり、全体としてテストの網羅性が低くなります。
「両端ライブラリ型」は、始端と終端両方にライブラリがあるケースで、一番頻出です。 というのも、REST APIを例に挙げると、例えば、API層をFlask、DB層をsqlmodelと採用すると、おのずと自分のコードがライブラリに挟まれてしまいます。こういった構成が取られてしまうと、おのずと全体を一体とした「介入型」のE2Eのテストしかできなくなってしまい、網羅性の低いテストしか出来ない状態になってしまいます。この場合はどうすればよいのでしょうか?
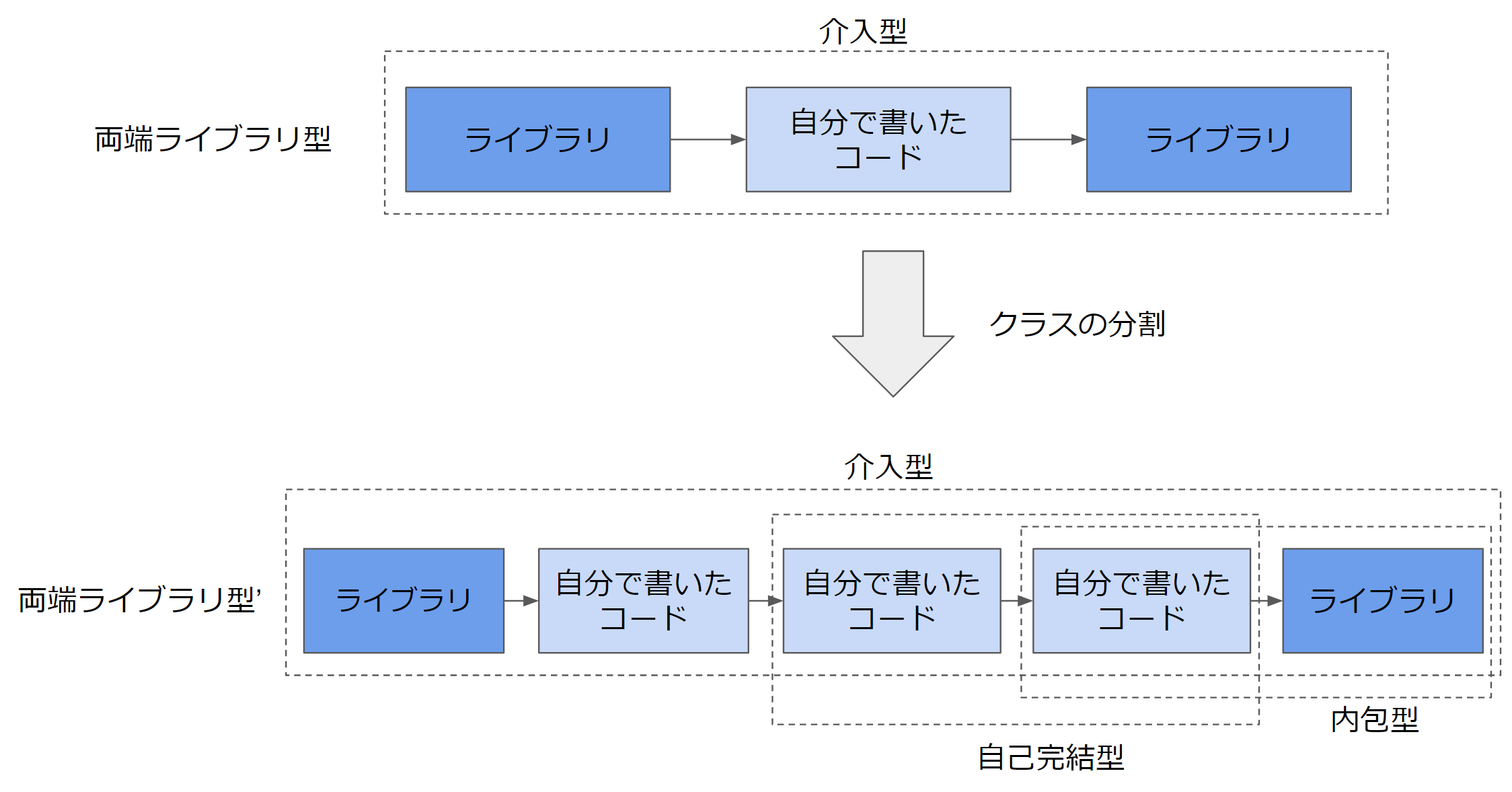
「両端ライブラリ型」を例にとりますが、 基本的には、クラスの分割を行います。 「ライブラリ」から「自分で書いたコード」の呼び出し部分は、ライブラリに依存する部分が多いため自由にテストできません。そのため、いわゆるハンドラーに書く部分は出来るだけ薄くします。そして、ビジネスロジックの部分(自己完結型)や、アプリケーションロジック(内包型)の部分に分割します。そうすることで、内部的にテストできる領域を広げ、テストの網羅性を上げることができます。
したがって、ここで言いたかったことは、テストの網羅性が低い。テストが十分に出来ない。と感じたときには、クラスを分割し、テストできる界面を作る必要がある。 ということです。
結局、テスト駆動すべし。
今回、テストが上手くいかないパターンについて記述しました。そして、それぞれのパターンにおいて、どのように変形したらよいかを記述しました。見たら分かると思いますが、 そもそもモジュールの設計レベルでテストについて考えておかないとテスト可能になりません。あとでテストを書く。という戦術は基本的に通用しないと考えておく方が良いです。 そうした場合、どうするか?と考えると、やはりテストファーストで書く、テスト駆動開発をすべき。という結論に至ります。テストを最初に書くと、必ず、モジュールのテスト可能性について考えざるを得ません。そうすることで、おのずとテスト可能なモジュール設計が出来るようになってきます。
最近、私が気にしているのは、「使用しているライブラリのドキュメントに"テスト"の項目があるか。」です。Qiitaもそうですが、「〇〇のチュートリアルをやってみる」という記事は多くあります。しかし、「〇〇のテストの書き方」という記事は驚くほど少ないです。そういったときに、重要となるのは、やはりライブラリの公式ドキュメントで、そういったドキュメントのテストの項目を穴のあくほど読むことが大切になってきます。しかし、実際問題として、公式のドキュメントに「自分のやりたいテスト」の方法が書いていることは少なかったりもします。そういった場合、ライブラリのリポジトリを見ると良いです。よく利用されているライブラリや、評価の高いライブラリは安定性が高いものが多いです。そうしたときに、大抵はテストが書いてあります。そうしたときに、ライブラリの作者が書いたテストのソースコードが手に入るので、そういった部分からライブラリのテスト方法を学ぶ。ということも重要になってきます。
繰り返し言いますが、全てのモジュールがテスト可能であるとは限りません。むしろテスト不能なモジュール・クラス構成の方が多いです。テスト可能性は最初から考慮しなければテスト可能になりません。
まとめ
「昨今のソフトウェア開発において、本質的にテストが困難なモジュールは多い。」ということを序盤に書きました。例にも挙げましたが、「API層をFlask、DB層をsqlmodel」のような選択を行い、実質的にはその間のコードを少し書くだけ。という割と楽な世の中になったと思います。しかし、その"楽さ"を享受しすぎて、テストをおざなりにしながら機能開発を行っていくと、途中でソフトウェアが制御不能になり、バグが直せない。という事態に陥ります。そこでようやく、「テストしたい」と思うようになったりします。しかし、そのタイミングでは手遅れで、「モジュールがテスト可能になっていない」ため、「テストが書けない」「改善が困難」、そして、その頃にはサービスがお金が稼げるようになってて「機能を削除するな」「既存の機能の動きを変えるな」「システムを止めるな」「これ以上バグを出すな」と言われる。しかし、そのような指示を出す人間は、そもそもそのようなひどいコードを出した張本人であるにも関わらず、反省せず技術負債を無視しながら売り上げのために新機能の実装だけ押し付けてくるうえに、一切もうコードは書かない割に「俺なら書ける」みたいなことを言ってくる奴だったりする。しかし、後任になった人は、そもそも「モジュールがテスト不能である」ということを言語化できず、交渉の材料に出来ない。「テスト不能である」ことを言語化出来ないし、方針や戦術も立てれない。何をやっても時間がかかるしうまくいかない。もし言語化できたとしても、ある程度、年数も立ち、売り上げを立てているような前任者は社内の信頼が厚く、そのように信頼の厚い人は、コミュニケーション技術に長けていたりする。社会において「論理的に正しい」というのは、実は無意味で、その議論を聞いている聴衆が「どちらの意見が正しいと"感じる"か」によって、「正しさ」が決まることがある。これを「正しさ」と呼ぶのは語弊があるかもしれないが。そのため、論理的に正しくても、聴衆の信頼の厚い実績もある相手と議論すると、そもそもビハインドが大きく、相手のコミュニケーション能力の高さ、話術により「自分の言っていることが聴衆に論理的に間違っている」と認識され、自分が悪者になる・・・みたいな高ストレスな状況下で作業する羽目になります。そして、システムとチームと人間関係の問題が発生し、高ストレス下でキレた新入社員が糞コードは直すな。みたいな展開になったりするわけです。
「既存コードにテストを書きたい」と思った時点で、既に負けてることが多い。
それは、
すべてのコードにテストが書けるわけではない。
昨今のソフトウェアはテストが書きにくく、また、書きにくいまま成長してしまう傾向がある。
ただテストライブラリの使い方を知っただけではテストが書けない。
コードをテストしたいのであれば、コードをテスト可能な形に書き換えなければならない。
ということが、エンジニアリング面では非常に難しさを作っているように思います。そのため、この記事を読んで、自分の携わっているソフトウェアが出来るだけ安全にテスト可能な範囲が広げられたらと思います。