「カードは 予測した」
概要
- 遊戯王のモンスターカードの価格を機械学習で予測した
- 誤差200円以内で予測できる確率が58%
- 市場情報 > カード情報 > デッキ情報 の順で重要
前書き
最近,にわかに自分の周りに遊戯王がブームになっています.そんななか,周りがカードショップに行って,高いカードを買っていて,「なんでカードの価格って,そんなに高いんだ?」「強いカードは高いのか?」という疑問が出てきました.「カード価格はどうやって決まるのか?」もし,カードの強さだけで評価できるなら,「カードの情報のみから,カード価格は予測できるのではないか.」と考え始めました.そうであれば,機械学習で予測することが出来るのではないか?そう
人工知能は遊戯王カードの価格を予測できるか?
事前準備
カード情報を集めるだけだと,簡単なのですが,最近使われているカード.となると難しい.と思います.そこで,「きりぶろ!」というサイトを参考にさせてもらっています.このサイトにある,最近のデッキレシピを主にカード情報を集めています.今回,参考にしたのは
- 【2017年4月環境】遊戯王大会優勝・入賞デッキレシピまとめ【新制限 新ルール】
- 【遊戯王デッキレシピ】大会優勝・入賞デッキレシピまとめ【2017年1〜3月】
- 【真竜(しんりゅう)】デッキレシピ:大会優勝・入賞デッキまとめ
- 【遊戯王 恐竜族】デッキレシピ:大会優勝・入賞デッキ5個まとめました!
- 【Kozmo(コズモ)】デッキレシピ:大会優勝・入賞デッキまとめ,
- 【純十二獣(じゅうにしし)】デッキレシピ:大会優勝・入賞デッキまとめ
- 【インフェルノイド】デッキレシピ:大会優勝・入賞デッキまとめ
この7つのURLからデッキレシピを取得してきました.スクレイピングするスクリプトはこんな感じ.
# coding:utf-8
from pyquery import PyQuery as pq
import pandas as pd
import time
import os.path
def extract_card(url):
price_df = pd.DataFrame(
extrat_card_price(url+"&Price=1"),
columns=[
"name",
"price",
"shop_num"
]
)
detail_df = pd.DataFrame(
extract_card_detail(url),
columns=[
"num",
"name",
"limit",
"kind",
"rarity", "variety", "race",
"attack",
"defense"
])
return pd.merge(detail_df,price_df,left_on="name",right_on="name")
def extract_card_detail(url):
for table_tag in pq(url).find("table").eq(2):
for tr_tag in pq(table_tag).find("tr"):
td_tag = pq(tr_tag).find("td")
if td_tag.eq(4).attr["colspan"] is None:
record = pq(td_tag)
name=record.eq(2).find("a").eq(0).text().strip()
if len(name) != 0:
if record.eq(7).text()=="?" or record.eq(8).text()=="?":
continue
num = int(record.eq(0).text())
limit = record.eq(1).text()
limit = "普" if len(limit)==0 else limit
kind = record.eq(3).text()
rarity = int(record.eq(4).text())
variety = record.eq(5).text()
race = record.eq(6).text()
attack = int(record.eq(7).text())
defense = int(record.eq(8).text())
yield num,name,limit,kind,rarity,variety,race,attack,defense
def extrat_card_price(url):
for table_tag in pq(url).find("table").eq(3):
for tr_tag in pq(table_tag).find("tr"):
td_tag = pq(tr_tag).find("td")
if td_tag.eq(7).text().isdigit():
record = pq(td_tag)
name = record.eq(2).text().strip()
price = int("".join(filter(unicode.isdigit,record.eq(6).text())))
shop_num = int(record.eq(7).text())
yield name,price,shop_num
def dumpData(fulldata_filename):
entry_points = [
"http://yugioh-resaler.com/2017/03/20/post-15584/",
"http://www.yugioh-resaler.com/2017/02/16/post-13395/",
"http://www.yugioh-resaler.com/2017/02/16/post-13502/",
"http://www.yugioh-resaler.com/2017/02/27/post-14493/",
"http://www.yugioh-resaler.com/2017/02/15/post-13443/",
"http://www.yugioh-resaler.com/2017/02/16/post-13514/",
"http://www.yugioh-resaler.com/2017/02/15/post-13399/"
]
stats = dict()
history = set()
all_df = None
for entry_point in entry_points:
print entry_point
dom = pq(entry_point)
count = 0
for a_tag in dom.find("a"):
link_url = a_tag.get("href")
#デッキURLのみ抽出
if "https://ocg.xpg.jp/deck/deck.fcgi" in link_url:
filename = "data_%s" % link_url.split("=")[-1]
if filename in history:
print "skip deck"
continue
else:
history.add(filename)
if os.path.exists(filename):
print "filename:" + filename + " read:" + link_url
df = pd.read_pickle(filename)
else:
print "filename:" + filename + " write:" + link_url
df = extract_card(link_url)
df.to_pickle(filename)
time.sleep(1)
print df
del df["num"]
for idx,row in df.iterrows():
name = row["name"]
if stats.has_key(name):
stats[name] += 1
else:
stats[name] = 1
if all_df is None:
all_df = df
else:
all_df = pd.concat([all_df,df]).drop_duplicates()
print len(all_df)
print entry_point
count += 1
hist_df = pd.DataFrame(
stats.items(),
columns=[
"name",
"hist"
]
)
return pd.merge(all_df,hist_df,left_on="name",right_on="name")
基本的には,pandasのデータ形式を引き回してます.あと,スクレイピングにはpyqueryというライブラリを使っています.今までは,BeautifulSoupを使うことが多かったのですが,pyqueryも使われているようなので使ってみました.「pyqueryはjqueryっぽくスクレイピングできる」というのがウリらしいですが,私はjqueryは使ったことがありません.しかし,pyquery自体十分使いやすいですね.あとはpickle化していて,サーバーに負荷をかけないようにしています.
また,今回,モンスターカードにのみ注目しています.理由は魔法・罠・モンスターカードを同時に取り扱うモデルが作りにくいので,そうしています.また,攻撃力? 守備力?のモンスターも除外しています.これも理由は同様で,モデルが作りにくいからです.
スクレイピングの結果,
- デッキ数 274
- カード数 506
のデータが集まりました.
「カード情報は 集めた」
集めたデータ
カード情報(Basic)
- レベル
- 攻撃力
- 守備力
- モンスターの種類
- 制限
- 属性
- 種族
ごく普通のカード情報.ただ,実際は少し調整を入れており,例えば,「属性」はOneHotVectorの形式にしており,闇属性ならis_Dark=1,
光属性ならis_Light=1という風な表現をしています.モンスターの種類についても同様で,エクシーズなら,is_Xyz=1,融合ならis_Fusion等で表現しています.また,効果については,表現が困難なため,考慮していません.
市場情報(Market)
- デッキ採用数
- 取り扱い店数
最初の思い付きの,「カード情報から価格を予測する」ということは無理だと思いました.その理由は,「カードの価格はカードの強さに依存するのではない.あくまで需要と供給のバランスでしか表現されない」と考えました.いわゆる経済学的な視点です.そのため,ここでは「需要=デッキ採用数」,「供給=取り扱い店数」,という仮説を立てました.したがって,「需要(デッキ採用数)が多いカードは高い.」,「供給(取り扱い店数)が多いカードは安い.」と考えました.
デッキ情報(Deck)
- 条件付き確率
これは,「あるパターンのデッキによく使われるカードは高いのではないか?」という仮説に基づき,採用した素性です.例えば,「青眼の究極竜(ブルーアイズアルティメットドラゴン)」を使おうと考えると,「青眼の白龍(ブルーアイズホワイトドラゴン)」が3体必要になります.このように,Aというカードを使うためにBというカードが必要になる.そのため,Aという強いカードの値段が高い場合,それに必要なBというカードの値段も高くなるだろう.という内容を表現するために,採用しました.ここで表現しているAが「青眼の究極竜」で,Bが「青眼の白龍」ということです.
具体的にどのように計算しているかというと,簡単な例で説明します.
以下のようなデッキAとデッキBを対象に考えます.
デッキA:「青眼の白龍」「青眼の究極竜」「ドラゴンの秘宝」
デッキB:「青眼の白龍」「青眼の究極竜」「突進」
この中で,その中で,全てのカードのペアを考え,それらをカウントしていきます.
| 青眼の白龍 | 青眼の究極竜 | ドラゴンの秘宝 | 突進 | |
|---|---|---|---|---|
| 青眼の白龍 | 0 | 2 | 1 | 1 |
| 青眼の究極竜 | 2 | 0 | 1 | 1 |
| ドラゴンの秘宝 | 1 | 1 | 0 | 0 |
| 突進 | 1 | 1 | 0 | 0 |
例えば「青眼の白竜」「青眼の究極竜」のペアはデッキA,デッキB両方にあるので,"2"という値が入っています.一方で,「青眼の白竜」「突進」はデッキBにしか存在しないので,1になっています.この値を最終的に列に対して正規化します.
| 青眼の白龍 | 青眼の究極竜 | ドラゴンの秘宝 | 突進 | |
|---|---|---|---|---|
| 青眼の白龍 | 0.00 | 0.50 | 0.25 | 0.25 |
| 青眼の究極竜 | 0.50 | 0.00 | 0.25 | 0.25 |
| ドラゴンの秘宝 | 0.50 | 0.50 | 0.00 | 0.00 |
| 突進 | 0.50 | 0.50 | 0.00 | 0.00 |
この行列を値として使っています.いわゆる条件付き確率です.
検証手法
主に使ったライブラリは,Pandasとscikit-learn.内部的にはnumpyもちょこちょこと使っています.
あまり詳しく書きませんが,機械学習の手法はLasso回帰を採用しました.理由は,Linear,Ridge,Lassoで回帰分析をしたときに,LassoとRidgeの性能が良かったこと.また,Lassoは変数の説明の理解がしやすかったために採用しました.
また,デッキ情報についても,先述した行列をそのまま使っているわけではありません.SVDで50次元にまで削減しています.理由は説明変数が多すぎることと,実際にSVDで次元削減を行った場合,50次元でexplained_variance_ratio_の総和が90%を超えたので,その値としました.
モデル自体は3分割の交差検証を行っています.ハイパーパラメータは,scikit-learnのLassoのページに書いてある,alphaのパラメータを0.1~1.0まで0.1刻みで調整し,また,normalizeのパラメータをTrue,FalseかどうかをGridsearchCVで探索しています.その中で,R^2係数が一番良いモデルを選択しています.
その後,検証のため,R^2係数が一番良いモデルに対し,全訓練データをあてはめ,以降の検証を行っています.
検証結果
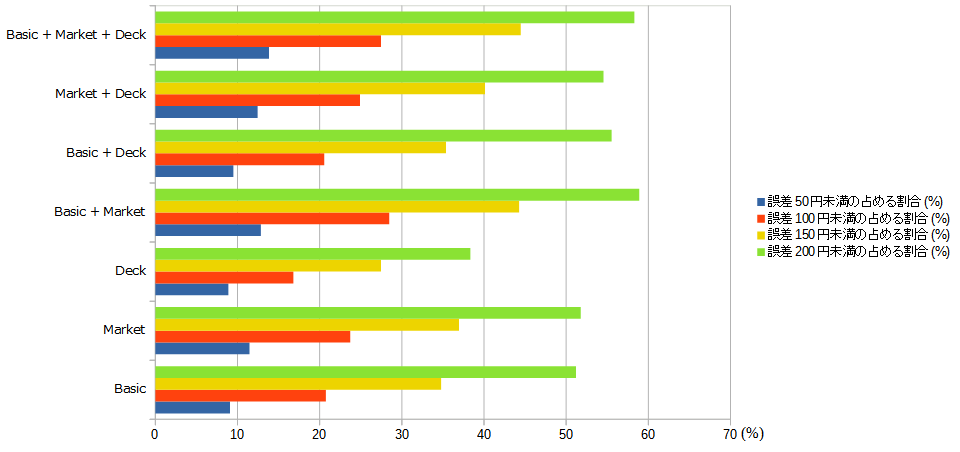
今回は3種類の検証を行いました.「1素性モデル」と,ここでは呼んでますが,「カード情報(Basic)」,「市場情報(Market)」,「デッキ情報(Deck)」の3種類から1つだけ選んで回帰しています.「2素性モデル」は,「カード情報(Basic)」+「市場情報(Market)」のように,3種類の素性から2つ取り出して,組み合わせたモデルです.最後に全部を使った「3素性モデル」で検証を行っています.
1素性モデル
| 素性 | R^2 | 誤差50円未満の占める割合(%) | 誤差100円未満の占める割合(%) | 誤差150円未満の占める割合(%) | 誤差200円未満の占める割合(%) |
|---|---|---|---|---|---|
| Basic | 0.00782 | 9.09 | 20.75 | 34.78 | 51.19 |
| Market | 0.03645 | 11.46 | 23.72 | 36.96 | 51.78 |
| Deck | -0.03684 | 8.89 | 16.80 | 27.47 | 38.34 |
この結果を見て分かることは,3つあります.どのモデルもR^2は低いということです.あまり当てはまりは良くないようです.2つ目は,市場情報(Market)の情報のみで,価格を予測した場合,精度が良かった.ということです.R^2は0.03程度ですが,誤差50円未満で予測できるカードが11%あるというのは,他の素性を選んだ場合より,2%程度高いので,回帰になにかしらの影響がありそうです.3つ目は,デッキ情報(Deck)で回帰したモデルは,誤差が大きいモデルである.ということです.R^2値が一番低くなっています.また,誤差50円未満の占める割合は,Basicとほぼ同じですが,それ以外は,4%~10%以上違うので,かなり誤差が大きいと思われます.
この内容から,価格予測に重要なファクターは,順に 市場情報 > カード情報 > デッキ情報 となることが分かります.
2素性モデル
| 素性 | R^2 | 誤差50円未満の占める割合(%) | 誤差100円未満の占める割合(%) | 誤差150円未満の占める割合(%) | 誤差200円未満の占める割合(%) |
|---|---|---|---|---|---|
| Basic + Market | 0.08830 | 12.85 | 28.46 | 44.27 | 58.89 |
| Basic + Deck | -0.00915 | 9.49 | 20.55 | 35.38 | 55.53 |
| Market + Deck | 0.03582 | 12.45 | 24.90 | 40.12 | 54.55 |
このモデルからわかることは2つあります.カード情報(Basic)+市場情報(Market)のR^2は0.08程度あり,一番高い.また,1素性モデルのMarketのR^2が0.03だったことを考えると,大きく伸びています.また,2素性モデルの全ての検証項目において,上位の予測精度になっています.2つ目にわかることは,「デッキ情報」を含めたモデルは性能が良くない.ということです.「Market+Deck」と「Basic+Deck」を比べた場合,全ての評価項目において,「Basic+Market」 > 「Market+Deck」となっています.これは1素性のモデルと同じ評価で,予測において重要なのは,カード情報 > デッキ情報 ということがここからも読み取れます.しかし,面白いことが分かります.「誤差150円未満の割合」,「誤差200円未満の割合」はそれほど悪くない.ということです.1素性モデルの,BasicとDeckの「誤差150円未満の割合」のギャップは約7%ありました.しかし,2素性モデルの,
「Basic+Market」と「Market+Deck」の「誤差150円未満の割合」のギャップは約4%です.特に顕著なのが,「誤差200円未満の占める割合」のギャップは,1素性モデルだと13%あったのが,2素性モデルでは4%になっています.そのため,デッキ情報は,誤差を全体的に下げるのに貢献しているようにも思われます.
3素性モデル
| 素性 | R^2 | 誤差50円未満の占める割合(%) | 誤差100円未満の占める割合(%) | 誤差150円未満の占める割合(%) | 誤差200円未満の占める割合(%) |
|---|---|---|---|---|---|
| Basic + Market + Deck | 0.07645 | 13.83 | 27.47 | 44.47 | 58.30 |
最後に3素性モデルです.注目すべきは,「誤差50円未満の占める割合(%)」です.これは,「Basic+Market」のモデルに比べ,1%程度向上しています.全体のカードの枚数が500枚程度なので,約5枚程度が改善したようです.ここから,デッキ情報が予測の高精度化に寄与する場合がある.ということです.
係数の調査
次に,Lasso回帰したときの係数について調べてみました.値は,3要素モデルのものを利用しています.svdで始まる係数は,前述したデッキ情報をSVDで次元削減した値です.
カードの要素ですが,エクシーズであるかどうかは,かなり価格に影響するようです.また,当たり前ですが「バニラカードは安い」という認識も正しいようです.一方でペンデュラムが,むしろ係数が負に出てるのは少し疑問があります.
また「需要(デッキ採用数)が多いカードは高い.」「供給(取り扱い店数)が多いカードは安い.」
という最初の仮説はおおむね正しいようです.デッキ採用数の係数の値が正,取り扱い店数が負になっています.また,種族としては,ドラゴン族と海竜族が高価格になりやすいようです.あと意外性が高いのが,属性に関する係数が0ではない.ということです.解析はしていないのですが,高価格で使いやすいモンスターは属性が偏っているのではないか?と思われます.
デッキ系数に関しては詳しくは見ていませんが,50要素含めて,回帰したとしても,実際には8要素しか使わないんだなぁ.と感じました.
ここで一言断っておくと,一部いない属性や,種族があると思います.その理由は,もともとスクレイピングで取得したカードに偏りがあるためで,それらのデータから,属性や種族のリストを抽出しているからです.
| 要素 | 係数の値 |
|---|---|
| レベル | 0.000 |
| 攻撃力 | 0.000 |
| 守備力 | 0.006 |
| バニラ | -37.348 |
| 効果 | 0.000 |
| 融合 | 0.000 |
| チューナー | 0.000 |
| シンクロ | 0.000 |
| エクシーズ | 139.618 |
| ペンデュラム | -2.289 |
| 特殊召喚 | 0.000 |
| リバース | 0.000 |
| ユニオン | 0.000 |
| デュアル | 0.000 |
| 儀式 | 0.000 |
| 禁止 | 0.000 |
| 制限 | 0.000 |
| 制限なし | 0.000 |
| 植物族 | 0.000 |
| 鳥獣族 | 0.000 |
| 炎族 | 0.000 |
| 機械族 | 0.000 |
| 戦士族 | 0.000 |
| 悪魔族 | 0.000 |
| 恐竜族 | 0.000 |
| サイキック族 | 0.000 |
| 水族 | 0.000 |
| 獣戦士族 | -2.044 |
| 天使族 | 3.232 |
| 魔法使い族 | 0.000 |
| 岩石族 | 0.000 |
| アンデット族 | 0.000 |
| 爬虫類族 | 0.000 |
| ドラゴン族 | 139.839 |
| 魚族 | 0.000 |
| 獣族 | 0.000 |
| 海竜族 | 190.029 |
| 幻竜族 | 0.000 |
| 雷族 | 0.000 |
| 昆虫族 | -32.625 |
| 闇属性 | 0.000 |
| 光属性 | 62.002 |
| 風属性 | 12.426 |
| 炎属性 | 0.000 |
| 地属性 | -8.750 |
| 水属性 | 0.000 |
| 取り扱い店数 | -4.901 |
| デッキ採用数 | 2.901 |
| svd_0 | 0.000 |
| svd_1 | 0.000 |
| svd_2 | 0.000 |
| svd_3 | 136.713 |
| svd_4 | 0.000 |
| svd_5 | 0.000 |
| svd_6 | 0.000 |
| svd_7 | 0.000 |
| svd_8 | 0.000 |
| svd_9 | 0.000 |
| svd_10 | 81.461 |
| svd_11 | 306.910 |
| svd_12 | 0.000 |
| svd_13 | 286.363 |
| svd_14 | 0.000 |
| svd_15 | 0.000 |
| svd_16 | 0.000 |
| svd_17 | 406.618 |
| svd_18 | 0.000 |
| svd_19 | 0.000 |
| svd_20 | 0.000 |
| svd_21 | 0.000 |
| svd_22 | 0.000 |
| svd_23 | 0.000 |
| svd_24 | 971.848 |
| svd_25 | 0.000 |
| svd_26 | 565.228 |
| svd_27 | 0.000 |
| svd_28 | 0.000 |
| svd_29 | 0.000 |
| svd_30 | 0.000 |
| svd_31 | 0.000 |
| svd_32 | 0.000 |
| svd_33 | 0.000 |
| svd_34 | 0.000 |
| svd_35 | 0.000 |
| svd_36 | 0.000 |
| svd_37 | 0.000 |
| svd_38 | 0.000 |
| svd_39 | 0.000 |
| svd_40 | 0.000 |
| svd_41 | 0.000 |
| svd_42 | 0.000 |
| svd_43 | 0.000 |
| svd_44 | 0.000 |
| svd_45 | 0.000 |
| svd_46 | 0.000 |
| svd_47 | 385.641 |
| svd_48 | 0.000 |
| svd_49 | 0.000 |
デッキ情報は効果があったのか?
今までの話の中で,デッキ情報が効果的だったのか?という疑問があったと思います.当初の予定であれば,「あるパターンのデッキによく使われるカードは高いのではないか?」という仮説から,この情報を入れていました.その中で面白いデータが取れたので紹介します.
ガエルデッキ
* 「ガエル」と名の付くカードを主軸にして戦うデッキ。
主に下級ガエルによるコントロールデッキ、《デスガエル》を大量展開してのビートダウンデッキ、ランク2エクシーズ召喚特化デッキの3通りの戦術に別れる。*
引用
いわゆるガエルと呼ばれるモンスターを主軸に戦うデッキですが,これはデッキ情報の効果が出た例だと思います.
カード情報と市場情報のみで予測した結果より,デッキ情報を加えたほうが誤差が少なくなっていることが分かります.しかも面白い事実があり,正負両方のデータが出ていることです.例えば,鬼ガエルは136円の予想だったのが,デッキ情報を加えることで171円になっています.そのため,デッキ情報を加えることで,予想の価格が上昇し,本来の価格に近付いています.一方で餅カエルを見てみると,デッキ情報を加えることで,価格が下がり,本来の価格に近付いています.
このようにデッキ情報により予測価格が上下しており,デッキ情報が有効に効いていると思われます.
| カード名 | 価格 | Basic+Market | Basic+Market+Deck |
|---|---|---|---|
| 鬼ガエル | 197 | 136.98 | 171.25 |
| 粋カエル | 444 | 202.34 | 229.41 |
| 魔知ガエル | 319 | 228.81 | 253.91 |
| 餅カエル | 162 | 253.00 | 230.94 |
ムーンライトデッキ
シャイニング・ビクトリーズで登場した、ムーンライトを中心とした【正規融合】。
展開やサーチに優れたムーンライトで融合召喚の準備を整え、非常に攻撃的な効果を持つムーンライト融合モンスターを融合召喚してビートダウンを行う。
ムーンライトと呼ばれるモンスターの価格を比較していますが,これはあまりよくない結果です.ある意味予想通りなのですが,基本的に上振れしています.特に月光黒羊の上り幅が50円近くあり,元の35円からほど遠いデータになっています.おそらくムーンライトのテーマに引っ張られて,価格が上振れしているのではないか?と予測しています.
| カード名 | 価格 | Basic+Market | Basic+Market+Deck |
|---|---|---|---|
| 月光虎 | 29 | 149.88 | 179.03 |
| 月光黒羊 | 35 | 87.14 | 134.17 |
| 月光舞豹姫 | 165 | 90.09 | 114.96 |
| 月光舞獅子姫 | 95 | 92.06 | 116.14 |
| 月光彩雛 | 271 | 123.68 | 148.71 |
| 月光蒼猫 | 39 | 132.29 | 156.05 |
| 月光狼 | 28 | 158.15 | 185.12 |
超頻出カード群
デッキの8割から9割以上に採用されているカード群です.これを見てもらえばわかるようにデッキ情報を加えることで価格が下がっています.理由は簡単で,特定のデッキに依存しないので,特徴がなくなってしまい,デッキ情報による価格の値上がりがない.そのため,価格が下がったのだと思います.係数の比較でみてもらうと分かるように,デッキ情報は,基本的に価格が上がるほうに寄与します.そのため,その効果がないと,デッキ情報がない場合より,価格が下がると思われます.
| カード名 | デッキ採用数 | 価格 | Basic+Market | Basic+Market+Deck |
|---|---|---|---|---|
| 増殖するG | 283 | 791 | 954.94 | 948.52 |
| 灰流うらら | 265 | 1845 | 1039.92 | 984.87 |
| 幽鬼うさぎ | 238 | 1546 | 1032.86 | 966.43 |
価格予測できないカードに関する考察
価格の高いカード
今回は価格が高いカードが予測できませんでした.
下に価格に関する各種統計量を出しました.見るべきは2つで,平均と50%です.平均が312円に対し,50%が151円となっています.実は小数の高価格カードに引っ張られて全体の平均が上がっています.このように,高価格帯のカードは圧倒的に少なく,価格自体が予測しにくい結果になっています.
| 項目 | 値 |
|---|---|
| 平均 | 312.31 |
| 分散 | 413.44 |
| 最小 | 23.00 |
| 25% | 48.25 |
| 50% | 151.50 |
| 75% | 400.75 |
| max | 3547.00 |
価格にばらつきのあるカード
実は「青眼の白龍」のカードの価格を予測することが出来ません.
| カード名 | 価格 | 3素性モデルの予測値 |
|---|---|---|
| 青眼の白龍 | 142 | 587.06 |
確かに,予測値と価格のかい離があります.気になって少し「青眼の白龍」の価格について調査しました.
| レアリティ | 価格 |
|---|---|
| Normal | 155 |
| Super | 238 |
| Ultra | 325 |
| Secret | 2136 |
| Parallel | 226 |
| Ultimate | 13835 |
| Holographic | 4846 |
| N-Parallel | 145 |
| Millennium | 1032 |
| KC | 862 |
| KC-Ultra | 1397 |
| Holo-Parallel | 2754 |
表に書いた通り,遊戯王カードには色々なレアリティが存在し,そのレアリティの差によって値段が上下します.すごく極端な例ですが,NormalとUltimateだと100倍近い価格差があります.そのため,「青眼の白龍」の価格っていくら?と言われると,実はレアリティを考慮に入れないといけないので,実際のところ1つの値段では言いにくいという事実があります.ここでは平均値を使ってしまったために,このあたりの価格の揺れの影響を受けているように思われます.
したがって,最初のデータ準備の段階で,「Normal」に限る.とかの条件を付与したほうが良かったのではないかな.と思っています.しかし,そうするとレアリティの高いカードしかない,エクシーズやシンクロがデータに入ってこないので,それはそれで悩ましいことになっていました.
組み合わせるテーマの多いカード群
今,まだ調査段階ですが,「組み合わせるテーマの多いカード群」に関しては,予測精度が出ない.結果になっています.以下は真竜に関する調査結果です.
| カード名 | 価格 | Basic+Market | Basic+Market+Deck |
|---|---|---|---|
| 真竜機兵ダースメタトロン | 76 | 152.08 | 141.94 |
| 真竜騎将ドライアスIII世 | 26 | 117.07 | 120.43 |
| 真竜剣皇マスターP | 711 | 506.38 | 469.86 |
| 真竜剣士マスターP | 67 | 263.12 | 286.72 |
| 真竜拳士ダイナマイトK | 29 | 323.41 | 324.99 |
| 真竜皇V.F.D. | 214 | 328.58 | 330.36 |
| 真竜皇アグニマズドV | 329 | 235.98 | 242.48 |
| 真竜皇バハルストスF | 588 | 187.68 | 170.31 |
| 真竜皇リトスアジムD | 1234 | 329.10 | 326.80 |
| 真竜戦士イグニスH | 28 | 250.82 | 247.79 |
| 真竜導士マジェスティM | 30 | 287.44 | 265.60 |
| 真竜凰マリアムネ | 290 | 218.55 | 202.92 |
デッキ情報を加えてもそれほど価格が良い方向に動きません.これは今の遊戯王の状況で,ガエルを生かしたデッキ構成を考えると,使えるパターンが旧来より少なく,有効なカードが固定化し,価格予測が行いやすいデータセットになっているためだと思います.しかし,真竜に関しては,
- 恐竜真竜
- 命削り真竜
- 真竜メタルKozmo
- 真竜Kozmo
- 真竜WW(真竜召喚獣WW)
- 真竜召喚獣
と,少し調べただけでも多くのデッキ構成パターンがあります.おそらく,それが原因でデッキ情報がうまく機能せず,うまく予測できないものだと思います.同様の結果が,「Kozmo」「召喚獣」「インフェルノイド」などでも見られます.これらのテーマは,おそらく新しく出てきた形なので,まだ試行錯誤段階で,定番カードが決まっていないのも,原因の1つだと考えられます.これは「超頻出カード群の価格予測ができない」という理由とも整合性が取れます.
まとめ
- カード情報・市場情報・デッキ情報を組み合わせて機械学習によるカード価格予測を行った
- 誤差200円以内で予測できる確率が58%
- カード価格はレアリティの関係で1つの平均値で表すのは難しい
- デッキ情報を加えると,うまく予測できるテーマ(ガエル)とできないテーマ(真竜)がある
- 定番カードの安定していないテーマは予測しづらい
- 200円以上の高価格帯のカードはデータが少なくて予測しづらい
感想
思ったより辛かった.「カード情報」で予測できないのは織り込みづみだったが,「市場情報」を加えても,そこそこの精度しか出なかったのは,なかなか辛い.あとブランクが空きすぎて,遊戯王知識の少なさが予測の困難さに拍車をかけていた.
「カード情報」と「市場情報」を組み合わせて回帰した後,大した予測ができていないので,「うーん.カードの名前に"青眼の~"とかが入ってるかどうか.とかをフラグに入れるかなぁー.でも,すごくアーティファクトなチューニングだなー」とか,「モンスター効果の自然言語解析する?ちょっとGWのタスクにしては重すぎない?」とか思いながら解析していました.そんな中,予測できなかったカード群の一覧を見ていると,「伝説の赤石」「真紅眼の黒炎竜」「真紅眼の凶星竜-メテオ・ドラゴン」という並びを見て,「カード組み合わせ系も考慮に入れないとなぁ」とか考えたときに,「そうか"分布仮説"か」と思い出しました.自然言語処理的な話でword2vec周りにそんな話があったので,カードの共起確率を入れてみるのは実際結構面白いんじゃないかなーと思ったので,デッキ情報として,情報を組み込みました.結果としては,あまり機能はしなかったんですが,解析的には,なかなか面白いな.と思いました.
機械学習で面白いことをやりたいと思うんですが,「もう少し精度がでればなー」と歯がゆい思いをしますね.難しい.
あとは,遊戯王の記事を書くんなら,やっぱり
【ゆっくり実況】人は拾ったカードだけで決闘できるか?【遊戯王】をオマージュしたかった.それが出来て今回は満足.というわけで,
「人工知能は遊戯王カードの価格を予測できる」
「でも,難しいからやるなら本腰いれろよ!」
