1. 知識の蒸留とは
「ニューラルネットワークの知識の蒸留」とは、大きなニューラルネットワークモデルから、より小さくて効率的なモデルを作成する手法です。このプロセスでは、元の大規模なモデルの「知識」が、より小さいモデルに移されます。
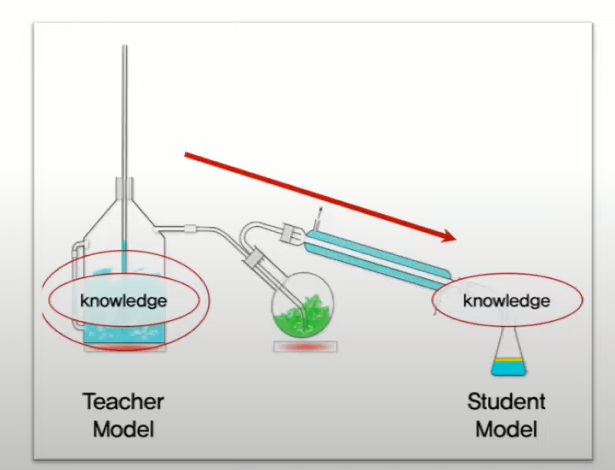
通常、大きなニューラルネットワークモデルは、数百万または数十億のパラメータを持っており、高度なタスクを実行するのに必要な複雑さを持っています。しかし、これらのモデルは計算リソースとメモリの面で高い要件を持ち、デプロイや使用には制約があります。
2. 教師モデルと生徒モデル
このような場合、蒸留技術は大きなモデルの「知識」を捉え、それをより小さいモデルに伝達することで、効率的なモデルを作成します。一般的には、教師モデル(大きなモデル)と生徒モデル(小さなモデル)が関与します。
3. 生徒モデルのトレーニング過程
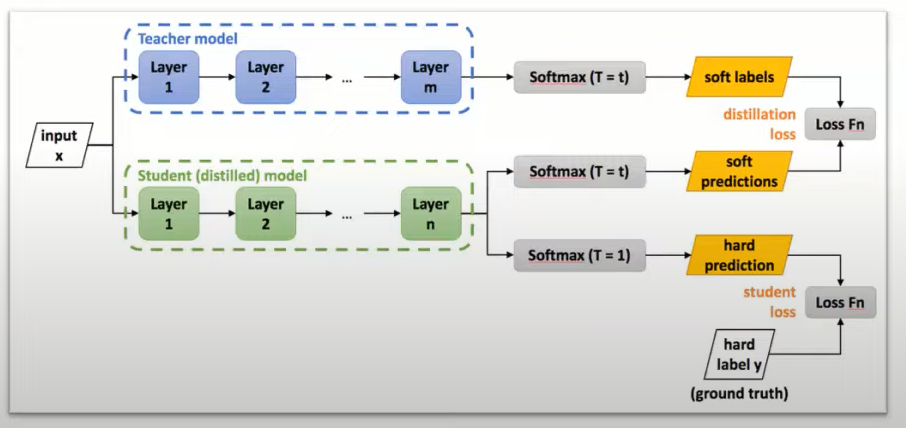
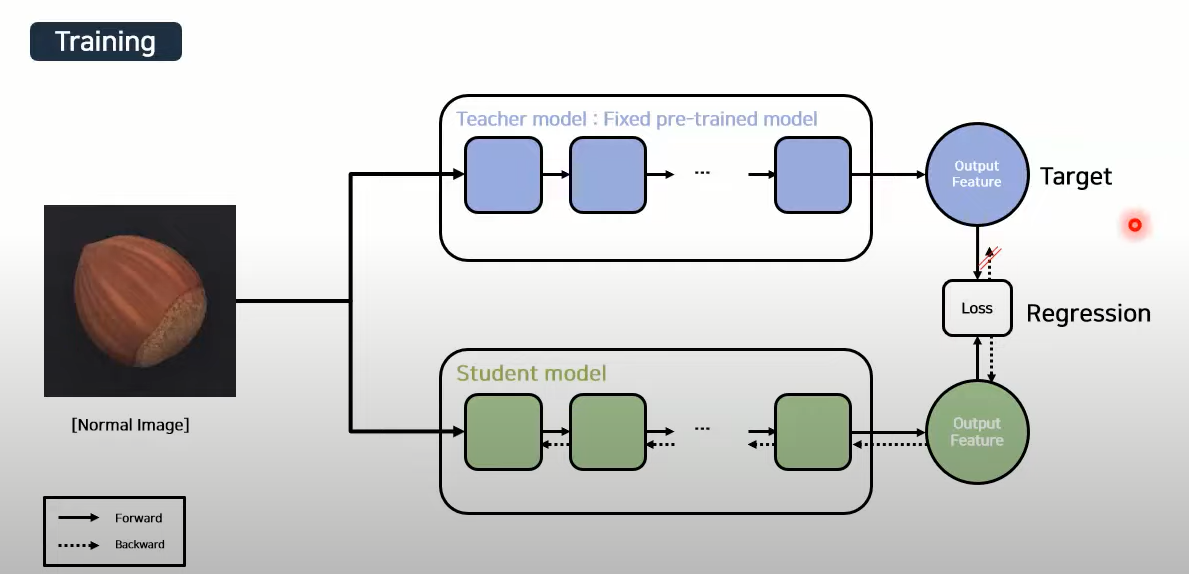
蒸留プロセスでは、教師モデルの出力や中間表現を使用して、生徒モデルをトレーニングします。教師モデルは、高い精度を持つために多くの学習データや計算リソースを使用してトレーニングされています。生徒モデルは、より少ないパラメータを持ち、よりコンパクトでリソース効率の高いモデルです。
#4 蒸留の目的とメリット
蒸留の目的は、生徒モデルが教師モデルと似た振る舞いをするようにすることです。生徒モデルは、教師モデルの予測や中間表現との間で類似性を最大化するようにトレーニングされます。このプロセスにより、生徒モデルは教師モデルと同等のタスクパフォーマンスを達成できることが期待されますが、より小さなモデルサイズや高速な推論が可能となります。
蒸留は、デプロイメントの制約がある環境でニューラルネットワークモデルを使用する場合に特に有用です。また、モデルの可解釈性や解釈可能性を向上させるためにも使用されることがあります。