初めに
PHM2008のNASA Turbofan Engineのデータセットを利用して分析してみます。
https://data.nasa.gov/Aerospace/CMAPSS-Jet-Engine-Simulated-Data/ff5v-kuh6

データセットの準備
データセットの説明(英文)
The data are provided as a zip-compressed text file with 26 columns of numbers, separated by spaces. Each row is a snapshot of data taken during a single operational cycle, each column is a different variable.
The columns correspond to:
unit number
time, in cycles
operational setting 1
operational setting 2
operational setting 3
sensor measurement 1
sensor measurement 2 ...
sensor measurement 26
Data Set: FD001
Train trjectories: 100
Test trajectories: 100
Conditions: ONE (Sea Level)
Fault Modes: ONE (HPC Degradation)

探索的データ解析
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
df_train = pd.read_csv('/PHM-IEEE-2008/train_FD001.csv', header = None)
columns_train = ['unit_ID','cycles','setting_1','setting_2','setting_3','T2','T24','T30','T50','P2','P15','P30','Nf',
'Nc','epr','Ps30','phi','NRf','NRc','BPR','farB','htBleed','Nf_dmd','PCNfR_dmd','W31','W32' ]
df_train.columns = columns_train
df_train

plot
fig, axes = plt.subplots(6,5, figsize=(30,30))
ax = axes.ravel()
for i in range(len(df_train.columns)):
ax[i].scatter(df_train['cycles'], df_train.iloc[:,i], color='blue')
ax[i].set_title(df_train.columns[i])
ax[i].set_yticks(())
ax[i].grid()
fig.tight_layout()
plt.show()

データの前処理
移動平均(n=5)
ノイズ除去
#making new dataframe
df_train_sma = pd.DataFrame(columns=columns_train)
df_train.columns
columns_to_move_average = ['setting_1', 'setting_2', 'setting_3', 'T2', 'T24',
'T30', 'T50', 'P2', 'P15', 'P30', 'Nf', 'Nc', 'epr', 'Ps30', 'phi',
'NRf', 'NRc', 'BPR', 'farB', 'htBleed', 'Nf_dmd', 'PCNfR_dmd', 'W31',
'W32']
for name in columns_to_move_average :
df_train_sma[name] = df_train[name].rolling(5).mean()

unit_IDとcyclesのデータを戻す
df_train_sma['unit_ID'] = df_train['unit_ID']
df_train_sma['cycles'] = df_train['cycles']
df_train_sma
NAをdrop
# drop NA
df_train_sma.dropna(inplace=True)
df_train_sma
indexのreset
df_train_sma.reset_index(drop=True, inplace=True)
df_train_sma

再びplot
fig, axes = plt.subplots(6,5, figsize=(30,30))
ax = axes.ravel()
for i in range(len(df_train.columns)):
ax[i].scatter(df_train_sma['cycles'], df_train_sma.iloc[:,i], color='red')
ax[i].set_title(df_train.columns[i])
ax[i].set_yticks(())
ax[i].grid()
fig.tight_layout()
plt.show()

Feature選択

columns_to_drop_train = ['setting_1', 'setting_2', 'setting_3', 'T2','P2', 'P15', 'epr','farB', 'Nf_dmd', 'PCNfR_dmd', 'W31','W32']
df_train.columns
columns_to_drop_train = [ 'setting_1', 'setting_2', 'setting_3',
'T2','P2', 'P15', 'epr','farB', 'Nf_dmd', 'PCNfR_dmd',
'W31','W32']
df_train_feature = df_train_sma.drop(columns=columns_to_drop_train)
df_train_feature

Standarization
Scalingを行う。unit_ID、cyclesはscaling対象ではないことに気を付けましょう。
# Scaling
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df_pca = df_train_feature.drop(columns=['unit_ID', 'cycles'])

scaler.fit(df_pca)
df_scaled = pd.DataFrame(scaler.transform(df_pca), columns = df_pca.columns)
df_scaled

データ分析(PCA)
#PCA
from sklearn.decomposition import PCA
pca = PCA(n_components=4)
pca.fit(df_scaled)
pca_result = pca.transform(df_scaled)
print(f'original data: {df_scaled.shape}')
print(f'after PCA data: {pca_result.shape}')
print(f' Explaiend variance ratio : {pca.explained_variance_ratio_}')
PCA1 77%とPCA2 18% 合計で95% 悪くないですね。
original data: (20627, 12)
after PCA data: (20627, 4)
Explaiend variance ratio : [0.76605196 0.18037961 0.01050908 0.00907406]
データ分析結果の解析
pca結果をdataframe化する。その後の可視化、解析のため。
# pca result to dataframe
df_pca_result = pd.DataFrame(pca_result, columns=['PC1', 'PC2','PC3','PC4',])
df_pca_result
とにかく可視化
fig , ax = plt.subplots(1,1, figsize = (10,10))
ax.scatter(x=df_pca_result['PC1'], y=df_pca_result['PC2'])
ax.set_title('PCA')
ax.set_xlabel('PC1')
ax.set_ylabel('PC2')
ax.grid()
fig.tight_layout()
plt.show()

cyclesの情報を入れてみよう。
df_pca_result_plus_cycles = pd.concat([df_pca_result, df_train_feature[['unit_ID', 'cycles']] ], axis=1)
df_pca_result_plus_cycles

fig , ax = plt.subplots(1,1, figsize = (12,10))
mappable=ax.scatter(x=df_pca_result_plus_cycles['PC1'], y=df_pca_result_plus_cycles['PC2'],
c=df_pca_result_plus_cycles['cycles'])
ax.set_title('PCA')
ax.set_xlabel('PC1')
ax.set_ylabel('PC2')
ax.grid()
fig.tight_layout()
fig.colorbar(mappable)
plt.show()

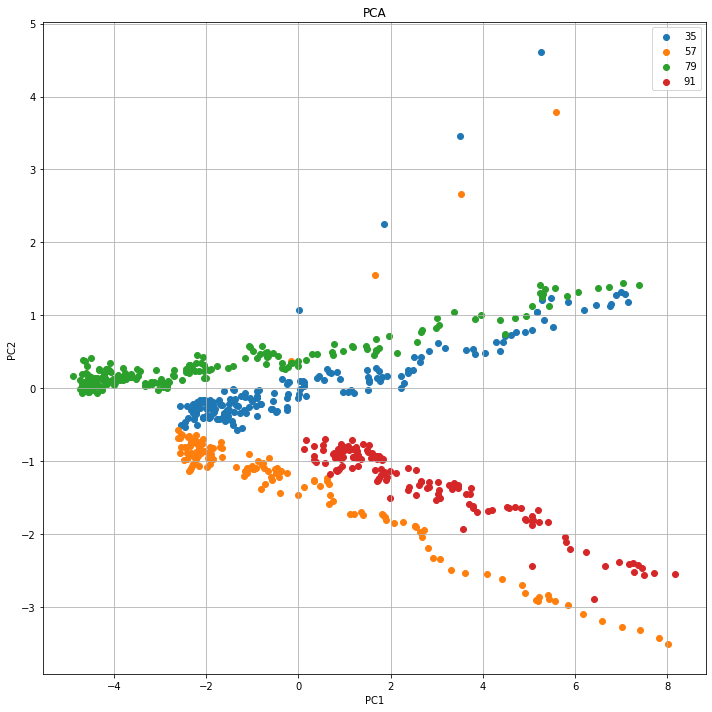
まだよく分からないので、四つのエンジンだけ取り出してみる。
# Unit Number 35, 57, 79, 91
unit_list = [35, 57, 79, 91]
#unit_list = [1, 2, 3, 100]
fig , ax = plt.subplots(1,1, figsize = (10,10))
for number in unit_list:
ax.scatter(x=df_pca_result_plus_cycles[df_pca_result_plus_cycles['unit_ID']==number]['PC1'],
y=df_pca_result_plus_cycles[df_pca_result_plus_cycles['unit_ID']==number]['PC2'],
)
ax.set_title('PCA')
ax.set_xlabel('PC1')
ax.set_ylabel('PC2')
ax.grid()
ax.legend(unit_list)
fig.tight_layout()
plt.show()
1つのエンジンだけにして、cyclesで色をつけてみる。
fig , ax = plt.subplots(1,1, figsize = (12,10))
number = 5
mappable=ax.scatter(x=df_pca_result_plus_cycles[df_pca_result_plus_cycles['unit_ID']==number]['PC1'],
y=df_pca_result_plus_cycles[df_pca_result_plus_cycles['unit_ID']==number]['PC2'],
c=df_pca_result_plus_cycles[df_pca_result_plus_cycles['unit_ID']==number]['cycles'])
ax.set_title('PCA')
ax.set_xlabel('PC1')
ax.set_ylabel('PC2')
ax.grid()
ax.legend([number,])
fig.tight_layout()
fig.colorbar(mappable, ax=None)
plt.show()
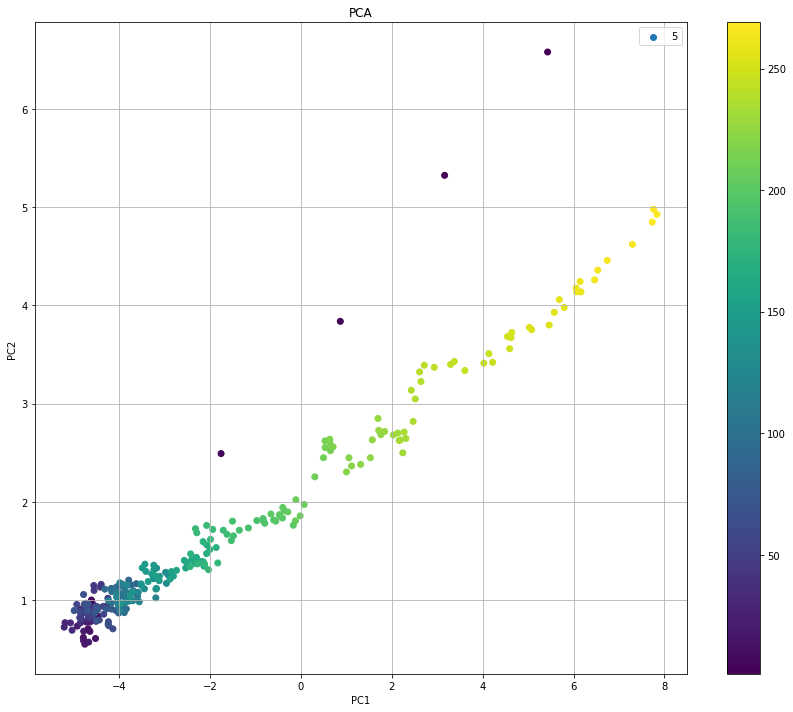
PCAでエンジンの劣化状態が分かりますね。
参考文献
-
https://www.kaggle.com/code/mochmunirulichsan/predictive-maintenance-scheduling-fd001
-
https://pub.towardsai.net/predicting-the-remaining-useful-life-of-turbofan-engine-f38a17391cac
-
Remaining useful life prognosis of turbofan engines based on deep feature extraction and fusion
-
Course2 Statement: NASA Turbofan PCA](https://www.kaggle.com/code/brjapon/course2-statement-nasa-turbofan-pca)