Linebotを作った背景
「画像認識AI使ってなんか作りたいなぁ。。。」「SpotifyAPI使って音楽提案アプリ作ってみたいなぁ。。。」
「せや!怒ってる顔してたらデスボゴリゴリの激しい音楽、悲しい顔してたらアコースティックな落ち着く音楽、笑顔やったらPOPな明るい音楽を提案してくれるアプリ作ろ!」
ということで今回の開発は始まりました。
完成デモ
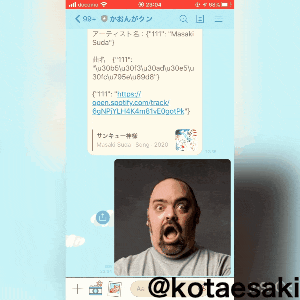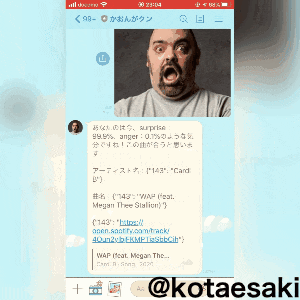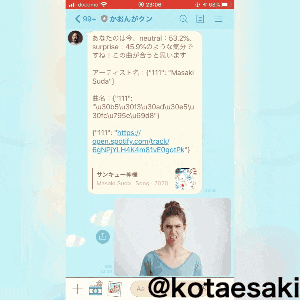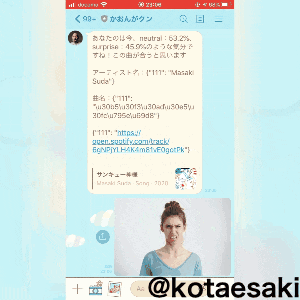

上記のQRから使えます。
テストでこの画像を使いすぎて、アイコンにしてしまいました。笑

ターゲット
・今の気分に合った音楽を提案して欲しい人 ・顔写真にBGMを付けたい人(?)開発環境
Python3.7.5 microsoftFaceAPI SpotifyAPI LineMessagingAPI Herokuつくりかた
流れ
- ユーザーが顔写真をLinebotに送信する(main.py)
- FaceAPIを通して顔写真の感情を分析する(face_api.py)
- 感情分析数値をSpotifyAPIに投げて、音楽データから感情に合った音楽をユーザーに返す(spotify_api.py)
1. ユーザーが顔写真をLinebotに送信する(main.py)
プログラム
app = Flask(__name__)
# herokuの環境変数に設定された、LINE DevelopersのアクセストークンとChannelSecretを
# 取得するコード
LINE_CHANNEL_ACCESS_TOKEN = os.environ["LINE_CHANNEL_ACCESS_TOKEN"]
LINE_CHANNEL_SECRET = os.environ["LINE_CHANNEL_SECRET"]
line_bot_api = LineBotApi(LINE_CHANNEL_ACCESS_TOKEN)
handler = WebhookHandler(LINE_CHANNEL_SECRET)
header = {
"Content-Type": "application/json",
"Authorization": "Bearer " + LINE_CHANNEL_ACCESS_TOKEN
}
# herokuへのデプロイが成功したかどうかを確認するためのコード
@app.route("/")
def hello_world():
return "hello world!"
# LINE DevelopersのWebhookにURLを指定してWebhookからURLにイベントが送られるようにする
@app.route("/callback", methods=['POST'])
def callback():
# リクエストヘッダーから署名検証のための値を取得
signature = request.headers['X-Line-Signature']
# リクエストボディを取得
body = request.get_data(as_text=True)
app.logger.info("Request body: " + body)
# 署名を検証し、問題なければhandleに定義されている関数を呼ぶ
try:
handler.handle(body, signature)
except InvalidSignatureError:
abort(400)
return 'OK'
# 以下でWebhookから送られてきたイベントをどのように処理するかを記述する
@handler.add(MessageEvent, message=TextMessage)
def handle_message(event):
print("文字だよ")
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text="顔写真を送ってみてね!"))
# 送られてきたメッセージが画像の場合の処理
@handler.add(MessageEvent, message=ImageMessage)
def handle_message(event):
message_id = event.message.id
print(message_id)
#face_api.pyで画像分析
face1 = face_api.FaceApi1(getImageLine(message_id))
face2 = face_api.FaceApi2(getImageLine(message_id))
print(face1)
print(face2)
text1 = json.dumps(face1[1][0])
text2 = json.dumps(face1[1][1])
text3 = json.dumps(face1[1][2])
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text='あなたのは今、' +
str(face1[0][0]) + ':' + str(face1[0][1] * 100) + '%、' +
str(face2[0]) + ':' + str(face2[1] * 100) + "%のような気分ですね!この曲が合うと思います\n\n" +
'アーティスト名:' + text1 + "\n\n" + '曲名:' + text2 + "\n\n" + text3))
#TextSendMessage(text=spotify_api.SpotifyApi())
print("画像だよ")
def getImageLine(id):
#送られてきた画像のurl
line_url = 'https://api.line.me/v2/bot/message/' + id + '/content/'
# 画像の取得
result = requests.get(line_url, headers=header)
print(result)
# 画像の保存
im = Image.open(BytesIO(result.content))
filename = '/tmp/' + id + '.jpg'
print(filename)
im.save(filename)
return filename
# ポート番号の設定
if __name__ == "__main__":
port = int(os.getenv("PORT", 5000))
app.run(host="0.0.0.0", port=port)
2. FaceAPIを通して顔写真の感情を分析する(face_api.py)
次にmain.pyから送られてきた画像をFaceAPIで感情認識してもらいます。# 一番数値の高い感情を取得
def FaceApi1(file):
#画像のurl
image_url = file
faces = CF.face.detect(image_url, face_id=True, landmarks=False, attributes='emotion')
# 出力結果を見やすく整形
print(type(faces))
print (faces[0])
total = faces[0]
attr = total['faceAttributes']
emotion = attr['emotion']
anger = emotion['anger']
contempt = emotion['contempt']
disgust = emotion['disgust']
fear = emotion['fear']
happiness = emotion['happiness']
neutral = emotion['neutral']
sadness = emotion['sadness']
surprise = emotion['surprise']
#数値が高いもので並べ替え
emotion2 = max(emotion.items(), key=lambda x:x[1])
print(emotion2)
track_href = spotify_api.SpotifyApi(emotion2)
return emotion2, track_href
この画像を送ると、、、

'faceAttributes':
{'emotion':
{'anger': 0.001,
'contempt': 0.0,
'disgust': 0.0,
'fear': 0.0,
'happiness': 0.0,
'neutral': 0.0,
'sadness': 0.0,
'surprise': 0.999}}}
驚いた顔を取得することができました。
3. 感情分析数値をSpotifyAPIに投げて、音楽データから感情に合った音楽をユーザーに返す(spotify_api.py)
まず、spotifyにあるランキングCSVを取得します。songs = pd.read_csv("top100.csv", index_col=0, encoding="utf-8")
print(songs.head(10))
そして、個々の曲の詳しいデータも取得していきます。
i = 0
for url in songs["URL"] :
df = pd.DataFrame.from_dict(spotify.audio_features(url))
song_info = song_info.append(df)
song_info.iat[i, 0] = url
i += 1
取得してみると、spotifyAPIは曲ごとに半端ない情報をデータとして提供してくれているのがわかります。
'danceability': {143: 0.935}, 'energy': {143: 0.454}, 'key': {143: 1.0}, 'loudness': {143: -7.509}, 'mode': {143: 1.0}, 'speechiness': {143: 0.375}, 'acousticness': {143: 0.0194}, 'instrumentalness': {143: 0.0}, 'liveness': {143: 0.0824}, 'valence': {143: 0.357}, 'tempo': {143: 133.073}
ダンスのしやすい曲だったらdanceabilityが高かったり、激しい歌だったらloudnessが高くなったりするらしいです!
詳しくはここに載ってます。
Spotifyの楽曲に埋め込まれている情報がハンパない話
最後に、画像のデータを元に、happinessが高ければvelance(曲の明るさ)が高い曲、
Surpriseが高ければdanceability(ダンスしやすさ)が高い曲などを振り分けます。
if tpl[0] == 'happiness':
print('happiness')
ser_abs_diff = (song_info['valence']-tpl[1]).abs()
min_val = ser_abs_diff.min()
ts = song_info[ser_abs_diff == min_val]
href = ts['URL']
art = ts['artist']
name = ts['track']
d = ts.to_dict()
print(d)
d_url = d['URL']
print(d_url)
d_art = d['artist']
print(d_art)
d_name = d['track']
return d_art,d_name,d_url
elif tpl[0] == 'contempt':
print('a')
ser_abs_diff = (song_info['loudness']-tpl[1]).abs()
min_val = ser_abs_diff.min()
ts = song_info[ser_abs_diff == min_val]
href = ts['URL']
art = ts['artist']
name = ts['track']
d = ts.to_dict()
print(d)
d_url = d['URL']
print(d_url)
d_art = d['artist']
print(d_art)
d_name = d['track']
return d_art,d_name,d_url
elif tpl[0] == 'disgust' or tpl[0] == 'fear':
print('a')
ser_abs_diff = (song_info['energy']-tpl[1]).abs()
min_val = ser_abs_diff.min()
ts = song_info[ser_abs_diff == min_val]
href = ts['URL']
art = ts['artist']
name = ts['track']
d = ts.to_dict()
print(d)
d_url = d['URL']
print(d_url)
d_art = d['artist']
print(d_art)
d_name = d['track']
return d_art,d_name,d_url
elif tpl[0] == 'anger':
print('anger')
ser_abs_diff = (song_info['loudness']-tpl[1]).abs()
min_val = ser_abs_diff.min()
ts = song_info[ser_abs_diff == min_val]
href = ts['URL']
art = ts['artist']
name = ts['track']
d = ts.to_dict()
print(d)
d_url = d['URL']
print(d_url)
d_art = d['artist']
print(d_art)
d_name = d['track']
return d_art,d_name,d_url
elif tpl[0] == 'neutral':
print('neutral')
ser_abs_diff = (song_info['valence']-tpl[1]).abs()
min_val = ser_abs_diff.min()
ts = song_info[ser_abs_diff == min_val]
href = ts['URL']
art = ts['artist']
name = ts['track']
d = ts.to_dict()
print(d)
d_url = d['URL']
print(d_url)
d_art = d['artist']
print(d_art)
d_name = d['track']
return d_art,d_name,d_url
elif tpl[0] == 'sadness':
print('sadness')
ser_abs_diff = (song_info['acousticness']-tpl[1]).abs()
min_val = ser_abs_diff.min()
ts = song_info[ser_abs_diff == min_val]
href = ts['URL']
art = ts['artist']
name = ts['track']
d = ts.to_dict()
print(d)
d_url = d['URL']
print(d_url)
d_art = d['artist']
print(d_art)
d_name = d['track']
return d_art,d_name,d_url
elif tpl[0] == 'surprise':
print('surprise')
ser_abs_diff = (song_info['danceability']-tpl[1]).abs()
min_val = ser_abs_diff.min()
ts = song_info[ser_abs_diff == min_val]
href = ts['URL']
art = ts['artist']
name = ts['track']
d = ts.to_dict()
print(d)
d_url = d['URL']
print(d_url)
d_art = d['artist']
print(d_art)
d_name = d['track']
return d_art,d_name,d_url
else:
print('a')
neutral(普通の顔)のときどんな音楽を流すか対応に悩んでいます。。。
意見あれば待ってます。。。
完成!
この画像を送ると、、、 この感情を取得して、
'faceAttributes': {
'emotion': {
'anger': 0.001,
'contempt': 0.0,
'disgust': 0.0,
'fear': 0.0,
'happiness': 0.0,
'neutral': 0.0,
'sadness': 0.0,
'surprise': 0.999}}
驚いた顔なので、ダンスしやすい音楽を引っ張ってくると
{'URL': {143: 'https://open.spotify.com/track/4Oun2ylbjFKMPTiaSbbCih'}, 'track': {143: 'WAP (feat. Megan Thee Stallion)'}, 'artist': {143: 'Cardi B'}, 'danceability': {143: 0.935}, 'energy': {143: 0.454}, 'key': {143: 1.0}, 'loudness': {143: -7.509}, 'mode': {143: 1.0}, 'speechiness': {143: 0.375}, 'acousticness': {143: 0.0194}, 'instrumentalness': {143: 0.0}, 'liveness': {143: 0.0824}, 'valence': {143: 0.357}, 'tempo': {143: 133.073}, 'type': {143: 'audio_features'}, 'id': {143: '4Oun2ylbjFKMPTiaSbbCih'}, 'uri': {143: 'spotify:track:4Oun2ylbjFKMPTiaSbbCih'}, 'track_href': {143: 'https://api.spotify.com/v1/tracks/4Oun2ylbjFKMPTiaSbbCih'}, 'analysis_url': {143: 'https://api.spotify.com/v1/audio-analysis/4Oun2ylbjFKMPTiaSbbCih'}, 'duration_ms': {143: 187541.0}, 'time_signature': {143: 4.0}, 'rank': {143: 144}}
アーティスト名:Cardi B
曲名:WAP (feat. Megan Thee Stallion)
https://open.spotify.com/track/4Oun2ylbjFKMPTiaSbbCih
上の音楽を聴いてみると確かに超ノリノリの音楽が取得できました!!
改善点
・文字化けしているところが少しある ・音楽情報を読み込むのが遅い。 ・データをもっと加工してから出力する最後に
よくよく考えてみると、表情に合わせた音楽ってなんだよって思うのですが、 顔写真にBGMがつくのもまた面白いと思い作成してみました。spotifyAPIにもfaceAPIにも本当にたくさんの情報が詰まっているので、
また何かしら作ってみたいと思います。