はじめに
FreeNASでいきなり「Critical」が出て、しかもなんやらわからんもんが「DEGRADED」した!
しかも、ボリュームの名前に対して「DEGRADED」!
ていうか、DEGRADEDって。。。何?
という時のための記事を残します。
構成
仮想OS:FreeNAS 11.2 (FreeBSD11ベース)
ハイパーバイザ:vSphere 6.7
ストレージ:某社製JBOD
HBA接続: Dell 12Gbps SAS HBA external
ハードウェア:DELL R640
状況
ことの始まりは次のように表示がされてしまったこと。(見やすいのでlegacyモードで表示。)
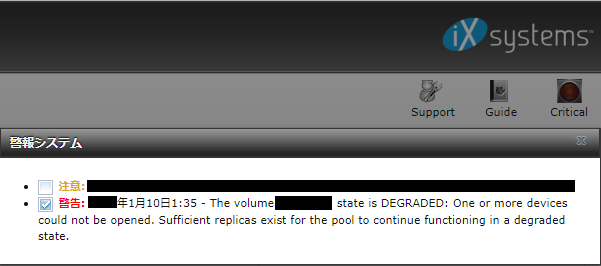
さて、何がどうなったのか、実はここからではわかることが限られます。
調査をしていきます。
状況調査
GUI画面でとりあえず抜けてるディスクを探す。
- ストレージ>ボリューム>ボリュームを表示 を選択していく。
- ストレージが表示されます。
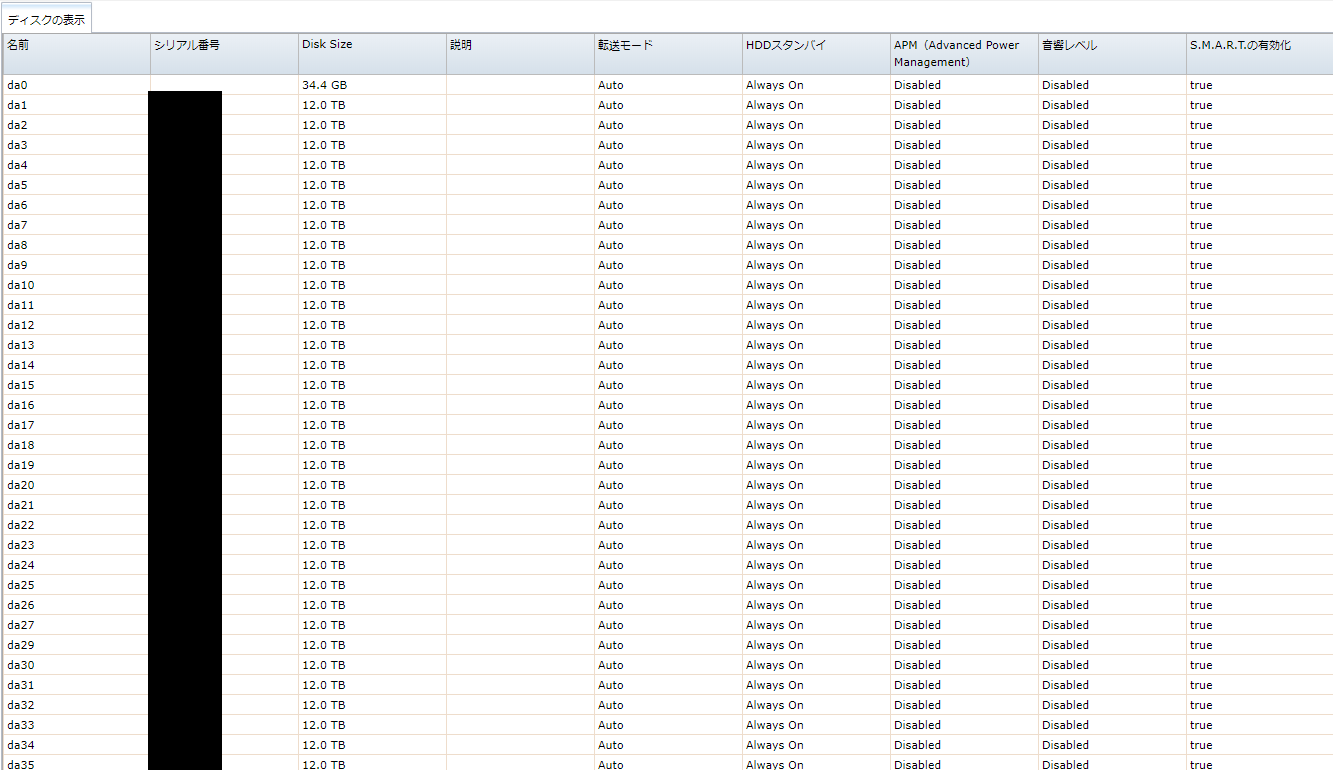
- ここから、実際についているHDDと一つ一つシリアルを照合しました。(とはいえ導入時にシリアルをメモってて助かりましたが)
→ほかにいい方法あれば教えてください!
ここから da27のシリアルが抜け落ちているのがわかりました。
※再起動すると、どうやらディスク名が再度整列される模様。写真はあるが、シリアルは元da28のものがずれているという。。
zpoolを確認しよう
shellでファイルシステムを確認することに。内部はRAID0+5構成で組んでいる。
※ある一定本数をRAID5で固めて、その固まりをRAID0でまとめる構成。なお、正確にはRAID-Zという形式ではあるがそのあたり割愛。
- SSHかブラウザからシェルを開く。(おすすめは、WinならTeraTerm、Macならコンソールでsshしてみること。見やすいから)
- 次を入力する
root@freenas[~]# zpool status - 次のデータでまず、探す。
pool: Volume hoge
state: DEGRADED
status: One or more devices could not be opened. Sufficient replicas exist for
the pool to continue functioning in a degraded state.
action: Attach the missing device and online it using 'zpool online'.
see: http://illumos.org/msg/ZFS-8000-2Q
scan: scrub repaired 0 in 0 days 17:32:01 with 0 errors on Fri Jan 11 04:07:07 2019
config: NAME STATE READ WRITE CKSUM
Volumehoge DEGRADED 0 0 0
raidz1-0 ONLINE 0 0 0
gptid/e1050d85-005d-11e9-8d5c-000c29f7b9b1 ONLINE 0 0 0
~省略~
raidz1-2 DEGRADED 0 0 0
gptid/56f4d78f-005e-11e9-8d5c-000c29f7b9b1 ONLINE 0 0 0
~省略~
gptid/5f5771cb-005e-11e9-8d5c-000c29f7b9b1 ONLINE 0 0 0
9303936301647382553 UNAVAIL 0 0 0 was /dev/gptid/61a44c50-005e-11e9-8d5c-000c29f7b9b1
gptid/63173cce-005e-11e9-8d5c-000c29f7b9b1 ONLINE 0 0 0
~省略~
raidz1-3 ONLINE 0 0 0
gptid/81f7dd62-005e-11e9-8d5c-000c29f7b9b1 ONLINE 0 0 0
~省略~
errors: No known data errors
ここからraidz1-2が「DEGRADED」してて、9303936301647382553ってのが「UNAVAIL」していることがわかる。
で。DEGRADEDってなによ!ってなるわけで。
ONLINE
デバイスまたは仮想デバイスは正常に動作しています。一時的なエラーがいくつか発生している可能性はありますが、それらを除けば正常に動作しています。
DEGRADED
仮想デバイスで障害が発生しましたが、デバイスはまだ動作しています。この状態は、ミラーデバイスまたは RAID-Z デバイスを構成するデバイスのうち、1 つ以上のデバイスが失われたときによく発生します。プールの耐障害性が損なわれる可能性があります。別のデバイスで続けて障害が発生した場合には、回復できない状態になることがあります。
FAULTED
デバイスまたは仮想デバイスへのアクセスが完全にできない状態です。この状態は通常、このデバイスで大きな障害が発生していて、デバイスとの間でデータの送受信ができないことを示しています。最上位レベルの仮想デバイスがこの状態の場合には、そのプールへのアクセスはまったくできません。
OFFLINE
管理者がデバイスを明示的にオフラインにしています。
UNAVAIL
デバイスまたは仮想デバイスを開くことができません。場合によっては、デバイスが UNAVAIL であるプールが DEGRADED モードで表示されることがあります。最上位レベルの仮想デバイスが UNAVAIL の場合は、そのプールのデバイスには一切アクセスできません。
REMOVED
システムの稼働中にデバイスが物理的に取り外されました。デバイスの取り外しの検出はハードウェアに依存しており、一部のプラットフォームではサポートされていない場合があります。
とのこと。
ように、RAID組んでたから、とりあえず一本死んでるけど、ほかで補ってるからなんとかデータは死んでないよ!っていうことですね。
まぁやばいことには間違いないわけで。
ここからどのHDD死んでるの?上のGUIで確認したHDDと同じなの?となるわけです。
message のログを探る
/var/log配下にあるmessageにこの手のログはほとんど溜まります。ここから故障前後の状況を含めて捜索しましょう。
正直grepでちょんちょん検索するより、logを落としてエクセルなどでがっつりみてしまったほうが早いです。
前後からHDDのシリアルと上の情報がすり合わさるので、そこで確認ができると思います。
※補足 ちょっとgrepで過去ログ見たい時にすでに.bz2で固まってることが多いです。その時は bzgrep '探す内容' ファイル名 で探せます!
対処
当該のHDDを外して再度付け直して復旧させます。
HDDの購入
・HDDは容量と回転数、ブランドぐらいは合わせておきましょう。自宅用であればそれで十分です。あとは予算と相談です。
・会社とかでがっつりJBOD等で利用している場合はHDDベンダーと相談してほかのHDDと同じHDD(ファームウェア含めて)をそろえましょう。(ちゃんとした会社と付き合うとこの辺りはしっかりサポートしてくれます。一人であったり、適当な会社だと、手の付けようがないのです)
HDDの入れ替え
- 本体の電源を落とします。
- コンセントも念のために抜きます。
- HDDを抜いて新しいHDDをセットします。
- 本体再起動します。
※ホットスワップ対応であれば、特に抜き差ししても問題ないです。
基本的に、FreeNASでは、autoreplaceが入っているので、勝手に再構築が始まります。(なんと簡単。)
→状況はzpool statusを見て確認しましょう!
最後に
FreeNASを本格的に利用するとなると、ZFSの仕組みなどやUNIXの仕組みを知らないとまだ難しいことが多いです。
ZFSのメモリの運用しかりチューニングしないとかなり速度が出づらいこともあるので、、しっかり勉強をしていくことをお勧めしたいです!自分も勉強中)
勉強方法は、元をたどれはZFSの仕組み自体はOracleが作ったものなので、提携しているFujitsuのサイトで勉強ができます。(Solarisなので全部が参考になるわけでもないですが。
一緒に勉強してくれる方、募集中です。。
補足
今回 ログの探し方の部分から下を書いてないのは、単純に別の問題を発見したのでそれを対処していたため参考になるものが載せられなかったためです。そっちの記事も書こうと思います。