この記事について
TeradataのBring-Your-Own-Model機能を紹介します。
これは、学習した機械学習モデルをTeradataデータベースに取り込み、データベース上のデータに適用し推論を実施する機能です。
この記事では、lightgbm, scikit-learn, tensorflow の3つのライブラリで学習したモデルを例に、この機能の実装を紹介します。

実行コードは、日本テラデータGitHubにて公開中しています(lightgbm, sklearn, tensorflow)。
このコードは無料のTeradata環境 ClearScape Analytics Experience にて実行可能です。
要点
- Teradataは予測モデルのための代表的なファイル形式とツールに対応
- Teradata上にモデルを導入し、データベース上のデータに対する推論に利用可能
- モデルをデータベース上にデプロイ、データの変換からモデルによる予測までをデータベース内で完結
Teradata Bring-Your-Own-Model 機能とは
外部環境で学習した機械学習モデルを取り込み、データベース上のデータに対して推論を行う機能です。
これにより、モデルをデータベース上にデプロイし、データ変換からモデルによる予測まで、一連のパイプラインを全てデータベース内で完結させることが可能になります。
執筆時点でサポートしているファイル形式、サードパーティツールはこちらです。
特に、オープンソース言語(scikit-learn, tensorflow など)で学習したモデルは PMMLやONNX形式に保存することが可能なため、この機能のサポート対象です。サードパーティの機械学習プラットフォームで学習したモデルも順次サポートを拡張しています。
事前準備
必要なライブラリをインストールします。
pip install pandas "sqlalchemy<2" ipython-sql teradataml scikit-learn matplotlib \
nyoka lightgbm "dask>2023.3.2" "distributed>2023.3.2" \
sklearn2pmml jdk4py tensorflow
sqlalchemy バージョン2との互換性に不具合が出ているので、改善まではバージョン1を指定します
lightgbm との不適合に対応するため、daskのバージョンを指定しています (関連するGitHub Issue)
Teradataへの接続
実際の環境に合わせて接続情報を指定します。
わからなければデータベース管理者に聞いてみましょう。
この例はお試し環境 ClearScape Experience での設定です。
from getpass import getpass
from urllib.parse import quote_plus
host = "host.docker.internal"
user = "demo_user"
database = "demo_user"
password = getpass("Password > ")
dbs_port = 1025
encryptdata = "true"
# sqlalchemy用の接続文字列
connstr = (
f"teradatasql://{user}:{quote_plus(password)}@{host}/?"
f"&database={database}"
f"&dbs_port={dbs_port}"
f"&encryptdata={encryptdata}"
)
from sqlalchemy import create_engine
from teradataml import create_context, DataFrame
engine = create_engine(connstr)
context = create_context(tdsqlengine=engine, temp_database_name=user)
住宅価格の予測 (LightGBM)
カリフォルニア住宅価格データを用いて、価格予測を行います。
データの準備
from sklearn.datasets import fetch_california_housing
data = fetch_california_housing(as_frame=True)
df = data["data"]
df.insert(0, "target", data["target"])
# teradata へデータをロード
from teradataml import copy_to_sql, DataFrame
copy_to_sql(df, "housing", if_exists="replace", index=True)
# ロード結果を確認
DataFrame("housing")
#target MedInc HouseAge AveRooms AveBedrms Population AveOccup Latitude Longitude index_label
#1.208 3.75 10.0 3.45 0.8 50.0 2.5 38.01 -121.29 16385
#1.55 2.9821 32.0 6.576923076923077 1.1153846153846154 138.0 2.6538461538461537 38.02 -121.27 16387
#1.125 1.15 52.0 4.88 1.04 62.0 2.48 38.05 -121.3 16
#....
-
copy_to_sqlを用いてローカル環境のデータフレームをteradataへロードしています -
index=Trueを指定することで、もともとの行番号を識別列として追加しています (データの順序は入れ替わってしまうので、後で突合するときに必要)
df = DataFrame("housing")
df_tr = df[df.index_label.mod(5) > 0]
df_te = df[df.index_label.mod(5) == 0]
copy_to_sql(df_tr, "housing_tr", if_exists="replace")
copy_to_sql(df_te, "housing_te", if_exists="replace")
-
index_labelを5で割った余りが0ならテストデータ、それ以外なら学習データとして用います - 他にもう少し込み入ったアルゴリズムでの分割も可能です (TrainTestSplit 関数)
- ここでも
copy_to_sql関数を使っていますか、ここではteradataml.DataFrameをテーブルとして保存するために使っています
モデルの学習
from lightgbm import LGBMRegressor
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import MinMaxScaler
model = Pipeline([
("scale", MinMaxScaler()),
("lgbm", LGBMRegressor(n_estimators=120, max_depth=7))
])
# データをローカルへ抽出
tmp = df_tr.to_pandas()
X_tr = tmp.drop(columns=["index_label", "target"])
X_tr.index = tmp.index_label
Y_tr = tmp.target
# 学習
model.fit(X_tr, Y_tr)
-
MinMaxScalerはあまり意味ないですが、複数ステップのモデルへの対応を確認できるよう入れています - 学習はローカル環境で行うので、データベースからデータを抽出しています(
to_pandasメソッド) - 実際はハイパーパラメータを最適化するところですが、今回は割愛します
from nyoka import lgb_to_pmml
feature_names = X_tr.columns
target_name = "target"
filename = "housing_lgbm.pmml"
lgb_to_pmml(model, feature_names, target_name, filename)
-
nyoka ライブラリの
lgb_to_pmml関数でモデルをファイルに書き出します
書き出したファイルは次のようなXMLファイルになっています
<?xml version="1.0" encoding="UTF-8"?>
<PMML xmlns="http://www.dmg.org/PMML-4_4" version="4.4">
<Header copyright="Copyright (c) 2018 Software AG" description="Default Description">
<Application name="Nyoka" version="4.3.0"/>
<Timestamp>2024-04-04 06:54:58.168165</Timestamp>
</Header>
<DataDictionary numberOfFields="9">
<DataField name="MedInc" optype="continuous" dataType="double"/>
<DataField name="HouseAge" optype="continuous" dataType="double"/>
<DataField name="AveRooms" optype="continuous" dataType="double"/>
<DataField name="AveBedrms" optype="continuous" dataType="double"/>
<DataField name="Population" optype="continuous" dataType="double"/>
...
モデルをデータベースにロード
from teradataml import save_byom
save_byom(model_id="housing_lgbm", model_file=filename, table_name="housing_models")
-
save_byom関数で、PMMLファイルをteradataにロードすることができます -
model_idはモデルの識別名です -
table_nameはモデルを保存するテーブル名です
ロードしたモデルは、下記のようにテーブルの1行として保持されます。
SELECT * FROM housing_models
/*
model_id model
housing_lgbm b'<?xml version="1.0" encoding="UTF-8"?>\n<PMM...
*/
データベース上のデータに対する推論
from teradataml import PMMLPredict, retrieve_byom
import teradataml
teradataml.configure.byom_install_location = "mldb"
# Bring-Your-Own-Model 関数の場所を指定
# 実際の環境により変化することがある
# 予測に使うテーブルとモデルオブジェクト
newdata = DataFrame("housing_te")
modeldata = retrieve_byom(model_id="housing_lgbm", table_name="housing_models")
# PMMLモデルによる予測の実行
out = PMMLPredict(
newdata=newdata,
modeldata=modeldata,
accumulate=["index_label"]
)
out.result
#index_label prediction json_report
#16395 1.1415913558411674 {"predicted_target":1.1415913558411674}
#16405 1.1689394206776245 {"predicted_target":1.1689394206776245}
#16410 1.1883080099743224 {"predicted_target":1.1883080099743224}
#16415 1.450895640017683 {"predicted_target":1.450895640017683}
#....
-
PMMLPredict関数に対象のデータとモデルを与えることで、推論を実行できます - 関数の場所が環境により変わることがあるので、
teradataml.configure.byom_install_locationパラメータを適宜設定します(不明の場合はシステム管理者に確認) -
accumulateオプションには、予測結果とともに出力すべき列名を与えます。ここでは行のidを含めるようにして他のデータと突合できるようにしています
なお、teradataml.configure.byom_install_location に何を設定するかわからない場合、クエリで探すことも可能です。
SELECT
databaseName, tableName, tableKind
FROM
dbc.tablesV
WHERE
tableName LIKE '%PMML%'
/*
DataBaseName TableName TableKind
mldb PMMLPredict_contract C
mldb PMMLPredict L
*/
手書き数字画像の分類 (scikit-learn, tensorflow)
MNIST手書き数字データ を用いて、画像の分類を行います。
データ準備
from sklearn.datasets import load_digits
data = load_digits()
X = data["data"]
Y = data["target"]
print(X.shape, Y.shape)
#(1797, 64) (1797,)
- 特徴量は8x8のピクセル値が64列に分かれたものです
- 下記のようなラベル付きの画像データが取得できます
# データをTeradataへロード
import pandas as pd
from teradataml import copy_to_sql
df = pd.DataFrame(X)
df.columns = [f"col_{j}" for j in range(df.shape[1])]
df.insert(0, "target", Y)
copy_to_sql(df, "mnist", if_exists="replace", index=True)
# 結果を確認
DataFrame("mnist")
#target col_0 col_1 col_2 col_3 col_4 ... col_61 col_62 col_63 index_label
#2 0.0 0.0 0.0 4.0 15.0 ... 16.0 9.0 0.0 2
#4 0.0 0.0 0.0 1.0 11.0 ... 4.0 0.0 0.0 4
#5 0.0 0.0 12.0 10.0 0.0 ... 10.0 0.0 0.0 5
from teradataml import TrainTestSplit
x = DataFrame("mnist")
tmp = TrainTestSplit(data=x, id_column="index_label", seed=87, test_size=0.2).result
display(tmp)
# TD_IsTrainRow が追加され、これがその行が学習テストかを示すフラグになる
# 学習、テスト部分に分割
a = tmp[tmp.TD_IsTrainRow == 1].drop(columns="TD_IsTrainRow")
b = tmp[tmp.TD_IsTrainRow == 0].drop(columns="TD_IsTrainRow")
# それぞれをデータベースに保存
copy_to_sql(a, "mnist_tr", if_exists="replace", index=False)
copy_to_sql(b, "mnist_te", if_exists="replace", index=False)
# 結果を確認
df_tr = DataFrame("mnist_tr")
df_te = DataFrame("mnist_te")
-
teradatamlのTranTestSplitを用いてデータを分割 -
TranTestSplitは、もともとテーブルにTD_IsTrainRowというフラグを追加する点に注意(scikit-learnのtrain_test_splitとは仕様が異なる)
ロジスティック回帰モデルの学習 (scikit-learn)
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import MinMaxScaler
from sklearn.decomposition import PCA
from sklearn2pmml import PMMLPipeline
# データをローカル環境へ抽出
tmp = df_tr.to_pandas().set_index("index_label")
X_tr = tmp.drop(columns="target")
Y_tr = tmp.target
# 後にPMML形式でエクスポートするため、PMMLPipeline としてモデルを定義する
# PMMLPipeline は scikit-learn の Pipeline の拡張なので、
# fit や predict などのメソッドはそのまま使える
model = PMMLPipeline([
("scale", MinMaxScaler()), # 値の範囲を [0,1] にスケール
("pca", PCA(n_components=25)), # 主成分分析で特徴量抽出
("logit", LogisticRegression(solver="liblinear", max_iter=2000)) # 分類モデル
])
model.fit(X_tr, Y_tr)
- 後に
sklearn2pmmlライブラリでPMMLに出力できるよう、sklearn2pmml.PMMLPipelineを利用 - それ以外は通常の学習と同じ
from sklearn2pmml import sklearn2pmml
sklearn2pmml(model, "mnist_logistic.pmml")
from teradataml import save_byom
save_byom(model_id="mnist_logistic",
model_file="mnist_logistic.pmml",
table_name="mnist_models")
# BYOMモデルはDB上にテーブルの1レコードとして保持される
SELECT * FROM mnist_models WHERE model_id = 'mnist_logistic'
/*
model_id model
mnist_logistic b'<?xml version="1.0" encoding="UTF-8" standal...
*/
ロジスティック回帰による予測
import teradataml
from teradataml import PMMLPredict, retrieve_byom
# Bring-Your-Own-Model 関数の場所を指定
# 実際の環境により変化することがある
teradataml.configure.byom_install_location = "mldb"
# 予測に使うテーブルとモデルオブジェクト
newdata = DataFrame("mnist_te")
modeldata = retrieve_byom(model_id="mnist_logistic", table_name="mnist_models")
output_fields = [f"probability({i})"for i in range(10)]
# PMMLモデルによる予測の実行
out = PMMLPredict(
newdata=newdata,
modeldata=modeldata,
accumulate=["index_label"],
model_output_fields=output_fields,
overwrite_cached_models="false" # モデルのキャッシュを更新
)
out.result
#index_label prediction probability(0) ... probability(9)
#4 0.00648795254447769 ... 2.1762516814145803e-05
#11 4.3997059151278296e-05 ... 0.006041986332802298
#16 7.165264470789079e-05 ... 1.6844970793049803e-05
#....
- BYOMによる推論結果はJSON形式で与えられるが、フィールド名を指定するに取り出してくれる (
model_output_fields) -
overwrite_cached_modelsは予測モデルのキャッシュを更新するフラグ。モデルを更新しても予測結果が変わらない場合、キャッシュが残っている可能性があるのでこれを "true" に設定
畳み込みニューラルネット (CNN) の学習 (tensorflow)
# データをローカル環境へ抽出
tmp = df_tr.to_pandas().set_index("index_label")
X_tr = tmp.drop(columns="target").values
Y_tr = tmp.target
tmp = df_te.to_pandas().set_index("index_label")
X_te = tmp.drop(columns="target").values
Y_te = tmp.target.values
# 深層学習用途では事前に入力データを[0, 1] の範囲にスケールしておく
X_tr = X_tr / 16.0
X_te = X_te / 16.0
# 入力データは 8x8x1 のピクセルデータに変換
X_tr = X_tr.reshape((-1, 8, 8, 1))
X_te = X_te.reshape((-1, 8, 8, 1))
# 出力データは、10次元のone-hot表現にする
from sklearn.preprocessing import LabelBinarizer
lb = LabelBinarizer().fit(Y_tr)
Y_tr = lb.transform(Y_tr)
Y_te = lb.transform(Y_te)
print(X_tr.shape, Y_tr.shape, X_te.shape, Y_te.shape)
#(1437, 8, 8, 1) (1437, 10) (360, 8, 8, 1) (360, 10)
- tensorflowのCNNは (高さ, 幅, チャネル) の多次元配列を受け取るのでそれに合わせて変換
- 入力を 0~1 の範囲になるよう 最大値 (16) で割る
- 目的変数は、10次元のone-hot表現に。各列が 0, ..., 9 であることを表す
from tensorflow.keras.layers import Dense, Conv2D, MaxPool2D, Flatten, Input
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
def create_cnn_model():
x = Input(shape=(8, 8, 1), name="mnist_image")
y = Conv2D(64, kernel_size=3, activation="relu")(x)
y = MaxPool2D(padding="same")(y)
y = Conv2D(32, kernel_size=3, activation="relu")(y)
y = MaxPool2D(padding="same")(y)
y = Flatten()(y)
y = Dense(10, activation="softmax", name="out_probability")(y)
model = Model(inputs=x, outputs=y)
return model
model = create_cnn_model()
model.compile(optimizer=Adam(1e-2), loss="categorical_crossentropy", metrics=["accuracy"])
history = model.fit(X_tr, Y_tr, validation_split=0.3, batch_size=256, epochs=25)
下記のような学習プロセスになりました。もっとチューニングできそうですが、本旨とずれるのでここで止めます。
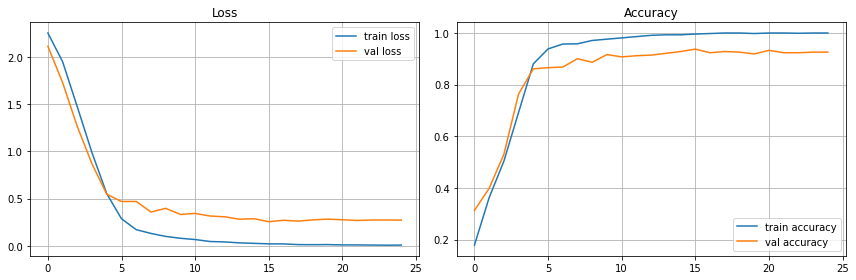
import tensorflow as tf
# まずはモデルをTensorflow形式のファイルに保存
tf.saved_model.save(model, "mnist_cnn_tensorflow.tf")
# model.save("mnist_cnn_tensorflow.tf") # for older version of tensorflow
# TF形式から ONNX形式に変換
# tf2onnxライブラリが必要
!python -m tf2onnx.convert --saved-model mnist_cnn_tensorflow.tf/ --output mnist_cnn.onnx --opset 10 --verbose
- ONNXファイルを出力するため、まず、tensorflowのモデルをTF形式に保存
- 次に、
tf2onnx.convertコマンドを用いて (tf2onnxについてくる)、ONNX形式に変換
from teradataml import save_byom
save_byom(model_id="mnist_cnn",
model_file="mnist_cnn.onnx",
table_name="mnist_models")
SELECT * FROM mnist_models
/*
model_id model
mnist_cnn b'\x08\x05\x12\x07tf2onnx\x1a\r1.15.1 37820d:\...
mnist_logistic b'<?xml version="1.0" encoding="UTF-8" standal...
*/
畳み込みニューラルネットによる予測
配列と列名の対応関係
ニューラルネットモデルの場合、入力が多次元配列であるのに対して、データベース上のデータはフラットなテーブルです。
そのため、どの列が配列のどの要素に対応するのかを予め指定する必要があります。
そこで、まずONNXモデルの要求する列名を把握します。
from teradataml import ONNXPredict
test_table = DataFrame("mnist_te") # 列名の確認をするだけなので、このデータは何でも良い
modeldata = retrieve_byom(model_id="mnist_cnn", table_name="mnist_models")
# ONNXモデルによる予測の実行
# show_model_input_fields_map=True にすると、Tensorとマップされる列名が表示される
out = ONNXPredict(
newdata=test_table,
modeldata=modeldata,
accumulate=["index_label"],
overwrite_cached_models="false",
show_model_input_fields_map=True
)
out.result
#ModelInputFieldsMap index_label json_report
#ModelInputFieldsMap('inputs=inputs_0_0_0,inputs_0_1_0,...,inputs_7_6_0,inputs_7_7_0') None None
-
show_model_input_fields_map=Trueを指定すると、想定される列名を返す - この場合、
inputs_{x}_{y}_0という命名規則になっていることがわかるので、これに合わせたテーブルを作成する
モデルの想定に合わせて列名を変更
# 上の結果、列名は inputs_{x}_{y}_{z} という命名規則に従うことがわかりました。
# そこで、この命名規則に従い列名を変更したテーブルを作成します。
import itertools
# 新しい列名から古い列名へのマッピングを作成
# teradataml.DataFrame には rename メソッドがないので、assign メソッドを使って新しい変数を定義
new_names = {"index_label": df_te.index_label, "target": df_te.target}
for k, (i, j) in enumerate(itertools.product(range(8), range(8))):
old_name = f"col_{k}"
new_name = f"inputs_{i}_{j}_0"
new_names[new_name] = df_te[old_name].div(16.0) # 忘れずに標準化する
df_te_new = df_te.assign(drop_columns=True, **new_names)
# 結果をデータベースに保存
copy_to_sql(df_te_new, "mnist_cnn_te", index=False, if_exists="replace")
# 結果を確認
DataFrame("mnist_cnn_te")
#target index_label inputs_0_0_0 inputs_0_1_0 ... inputs_7_6_0 inputs_7_7_0
#4 4 0.0 0.0 ... 0.0 0.0
#1 11 0.0 0.0 ... 0.0625 0.0
#6 16 0.0 0.0 ... 0.6875 0.0
-
teradatamlにはrename関数がないため、DataFrame.assignを用いて新しい変数を定義しています - ちょっと複雑なコードになっていますが、
assignはキーワード引数で新しい列を定義する仕様のため、新しい変数を定義する辞書を作成し、それを引数として渡しています - 結果として出力にあるようなテーブルが作成できれば他の手段でも可です
予測の実行
# 予測に使うテーブルとモデルオブジェクト
test_table = DataFrame("mnist_cnn_te")
modeldata = retrieve_byom(model_id="mnist_cnn", table_name="mnist_models")
# ONNXモデルによる予測の実行
out = ONNXPredict(
newdata=test_table,
modeldata=modeldata,
accumulate=["index_label"],
overwrite_cached_models="true",
show_model_input_fields_map=False
)
out.result
#index_label json_report
#4 {"output_0":[[6.587917E-10,2.2638268E-7,2.1552669E-13,5.8802438E-12,0.9998872,7.150676E-11,1.1224764E-4,4.6404818E-8,1.9489777E-7,1.672344E-12]]}
#11 {"output_0":[[2.2172659E-17,0.99996924,3.5191153E-10,4.4350195E-8,3.829391E-7,1.3302614E-11,6.647113E-10,2.4319868E-10,2.6723517E-5,3.6848623E-6]]}
#16 {"output_0":[[7.907412E-11,0.0053701894,1.9297017E-8,1.7565486E-5,2.504E-4,1.5501746E-6,0.9725108,4.0353387E-7,0.021849036,2.475626E-9]]}
- 予測結果は 多次元配列を要素に持つJSONで得られています
- 予測結果のフォーマットはONNXの変換アルゴリズムにより変わることがあります
結び
以上、Bring-Your-Own-Model機能を用いて、学習済みモデルをteradataへロードし、推論に用いる方法をご紹介しました。
予測モデルがデータベース上で動くと、パイプラインの構成やデータの流れが一気にシンプルになり、高速、かつ管理しやすくなると思います。作ったモデルをAPI化して開発・維持する、というデータサイエンティストの悩みも軽減されそうです。
疑問点・懸念点などありましたらぜひコメントください。GitHubの方にIssueを立てていただいても結構です。