初めに
こんにちは。
株式会社HRBrainでバックエンドエンジニアインターンをしている、蔭山といいます。
株式会社HRBrainではアドベントカレンダーに参加しています。
本記事は4日目になります。
業務でDBデータを取り扱う機会もあり、改めてDBとSQLに関して学び直しました。
今回は、その中からすぐにプログラマとして業務に活かせて、とくに気をつけたほうが良いと感じたSQLでのNULLの取り扱いについて書きたいと思います。
何番煎じか分かりませんが、順を追って説明します。
SQLにおけるNULLとは何か
行のある列の値がない場合、その列はNULLである、またはNULLを含むといいます。NOT NULL整合性制約またはPRIMARY KEY整合性制約によって制限されていない列の場合は、どのデータ型の列でもNULLを含むことができます。実際のデータ値が不定または値に意味がない場合に、NULLを使用してください。
参考:SQL言語リファレンス
レコードに値が含まれていない状態をNULLであると言います。
通常NOT NULL制約等をしない限り、どこにでもNULLは存在します。
NULLがあってもデータベースとしてはおかしくないのですが、比較条件といった真理値を扱う際には気をつけないといけません。
その理由を説明する前に、先にSQLでの真理値型について説明します。
通常、どの言語にも真理値型がありますが、SQLの真理値型の特徴として3値論理であることが挙げられます。
3値論理とはtrue, falseに加えて、unknownで表されるものです。
真理値表でのunknownの取り扱い
trueとfalseの2つであれば以下のようになります。

unknownが含まれると以下のようになります。
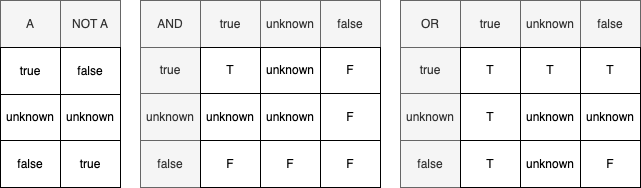
このように、unknownはtrueかfalseかどちらか分からない状態であると言えます。
3値論理の倫理条件については以下のサイトが詳しく解説してくださっています。
比較条件でのNULLとunknownの関係
また、比較条件でのNULLとunknownの関係も見ておきましょう。何気なく使っているIS NULLと=の違いも大切です。
| 比較条件 | Aの値 | 結果 | 比較条件 | Aの値 | 結果 |
|---|---|---|---|---|---|
| A IS NULL | 10 | F | A = NULL | 10 | unknown |
| A IS NOT NULL | 10 | T | A <> NULL | 10 | unknown |
| A IS NULL | NULL | T | A = NULL | NULL | unknown |
| A IS NOT NULL | NULL | F | A <> NULL | NULL | unknown |
| A = 10 | NULL | unknown | A <> 10 | NULL | unknown |
参考:SQL言語リファレンス
しっかりとIS NULL等を適切に使用しないと、すぐunknownになってしまうことがわかります。
思わぬ挙動になってしまうSQL
ここまでで、SQLの3値論理とunknownの振る舞いを見てきました。
ここからは具体例を交えながら、実際にNULLが含まれることでどのような挙動になるのかを説明します。
使用した環境は以下になります。
- PostgreSQL 14
PostgreSQLでは、unknownの代わりにNULLが使用されます。以降はそれに従い、unknownをNULLと置き換えます。
集合関数 NOT IN と NOT EXIST
ある集合の中に含まれているかどうかを判断したい場合はINを使うと思います。たとえば、以下のようなお店ごとに商品と売れた日付を管理するテーブルがあるとします。
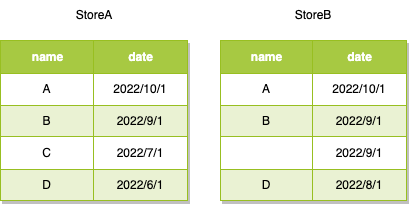
B店で9月以降に売れた商品のA店での売れた日付を表示させるSQLはこちらです。
SELECT name, date FROM StoreA WHERE name IN (SELECT name FROM StoreB WHERE date >= '2022/9/1');
-- A 2022/10/1
-- B 2022/9/1
出力はA 2022/10/1, B 2022/9/1になります。
NULLが含まれていようとも、正しく出力できています。ここで1つ注意なのですが、NULL IN {NULL}は正しく動作しないです。NULL IS NULLを使用しましょう。
では、9月以降に売れた商品を含まない場合はどうなるでしょうか?NOT INを使ってみます。
SELECT name, date FROM StoreA WHERE name NOT IN (SELECT name FROM StoreB WHERE date >= '2022/9/1');
-- 何も表示されない
予想ならD 2022/6/1となるはずでしたが、何も表示されません。
これは比較条件がNULLになってしまっているのが原因です。順を追って見てみましょう。
- サブクエリが実行されて
{A, B, NULL}が出力される。 -
NOT INをそれぞれの要素の比較条件のANDに変換する。 -
(name <> NULL) = NULLでありAND真理値表から比較条件はNULLとなる。
SELECT name, date FROM StoreA WHERE name NOT IN {A, B, NULL};
SELECT name, date FROM StoreA WHERE name <> A AND name <> B AND name <> NULL;
SELECT name, date FROM StoreA WHERE TorF AND TorF AND NULL;
INもNOT INもNULLを含むので、この様になってしまいます。
回避策
NOT EXISTS関数を使用することで、NULLを除外して実行できます。
SELECT name, date FROM StoreA WHERE name NOT EXISTS (SELECT name FROM StoreB WHERE date >= '2022/9/1');
-- D 2022/6/1
覚えておくこと
-
NOT INにはNULLが渡らないようにする。NOT EXISTSかNOT NULL制約を使用する。 - WHERE句にNULLが入ると出力がなくなる。
-
NULL IN {NULL}はNULL。NULL IS NULLを使用する。
実践例
NULLが含まれているテーブルに対して、実用的にSQLを書く例を紹介します。
HavingによるNULL排除
店舗で日用品の売れた日付を管理するテーブルがあり、売り切れとなった品目を探したいとします。
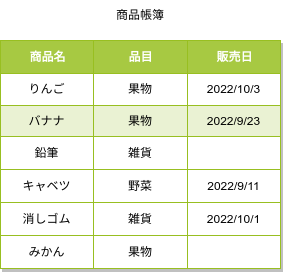
ここで覚えておいてほしいのは、COUNT(*)はNULLを数えて、COUNT("any")はNULLを排除するということです。
また、MAXといった集約関数の結果と値を比較したい場合、WHEREでは上手く行きません。
SELECT '町名' FROM '天気' WHERE '気温' = MAX('気温');
-- 上手く行かない
集約した結果に対して、何か絞り込みをかけたい場合は、サブクエリ(副問い合わせ)を利用するか、HAVING, GROUP BYを利用する必要があります。
(参考:PostgreSQL 9.21. 集約関数, PostgreSQL 2.7 集約関数)
結果
この違いを利用して、GROUP BY, HAVINGと組み合わせることでNULL排除が可能になります。
SELECT '品目' FROM '商品帳簿' GROUP BY '品目' HAVING COUNT(*) = COUNT ('発売日');
GROUP BYで品目ごとにグループ化し、COUNTの結果が異なるかどうかをHAVINGで判定しています。
覚えておくこと
- 集約関数の結果を条件指定したい場合、
WHEREではエラーになる。サブクエリかHAVING,GROUP BYを使用する。 -
COUNT(*)はNULLを数えて、COUNT("any")はNULLを排除する。 - 集約関数はサブクエリとCASE文で置き換えることもできる。
あとがき
本当は他にもCASE文や外部結合、副問い合わせの話、DB設計の話も勉強になって面白かったのですが、今回はNULLに関するものに留めました。
データベース専門ではないプログラマがデータベースと触れ合う一番の機会は、データを扱うクエリを考える際だろうと今回のテーマを選んだ所存です。
NULLの意識は常に持っておかないと、知らぬ間にまったく異なる挙動が生まれる可能性もあるんだな、と戒めつつ業務に励んでいきます。
最後に株式会社HRBrainでは新しいメンバーを募集中です。
僕自身、新卒で入社予定なのですが、社内の雰囲気もよく、エンジニアとしても尊敬できる先輩がたくさんいます。
興味がありましたら、ぜひご応募下さい!