最近話題のLLMってやつを触ってみたい
最近めちゃくちゃ大規模言語モデルって人気ですよね。でも触ってみようとするとColabとかKaggleだとかの無料のやつだとRAMが足りないとかVRAMが足りないとかでとっても苦労します。でもどうにかして触りたい・・・
対策
対策としてはシンプルにサブスクとか自分でマシン買うとか「課金する」というのが考えられます。でも課金するほどのモチベはないなあって人多いと思います、自分もそうです。
そこで無料枠で頑張って動かす方法を考えます。
手法
結論から言うとモデルを量子化して読み込めばいけ(る場合があり)ます。以下コードです。
rinna-instruction-3.6b-8bit.ipynb
# 必要なライブラリのインストール
!pip install accelerate
!pip install -i https://test.pypi.org/simple/ bitsandbytes
!pip install transformers[sentencepiece]
import gc
import torch
from accelerate import init_empty_weights, infer_auto_device_map, load_checkpoint_and_dispatch
from transformers import AutoConfig, AutoModelForCausalLM, AutoTokenizer, logging
torch.cuda.empty_cache()
#モデルの定義
model_name = "rinna/japanese-gpt-neox-3.6b-instruction-sft"
#重みなしで読み込む(modelを定義するため)
with init_empty_weights():
model = AutoModelForCausalLM.from_pretrained(model_name)
gc.collect()
#メモリの制限をかける(Out of memoryの対策)
device_map = infer_auto_device_map(
model, max_memory={0: "11GiB", "cpu": "7GiB"},
no_split_module_classes=["GPTNeoXLayer"]
,dtype=torch.int8
)
#load_in_8bitをTrueにして量子化する
model = AutoModelForCausalLM.from_pretrained(model_name,
device_map = device_map, load_in_8bit=True,
low_cpu_mem_usage=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = [
{
"speaker": "ユーザー",
"text": "りんなは人間ですか?それともAIですか?。"
}
]
prompt = [
f"{uttr['speaker']}: {uttr['text']}"
for uttr in prompt
]
prompt = "<NL>".join(prompt)
prompt = (
prompt
+ "<NL>"
+ "システム: "
)
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
do_sample=True,
max_new_tokens=128,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1):])
output = output.replace("<NL>", "\n")
print(output)
これで動きます。りんなちゃんは人間なのか?AIなのか?
出力
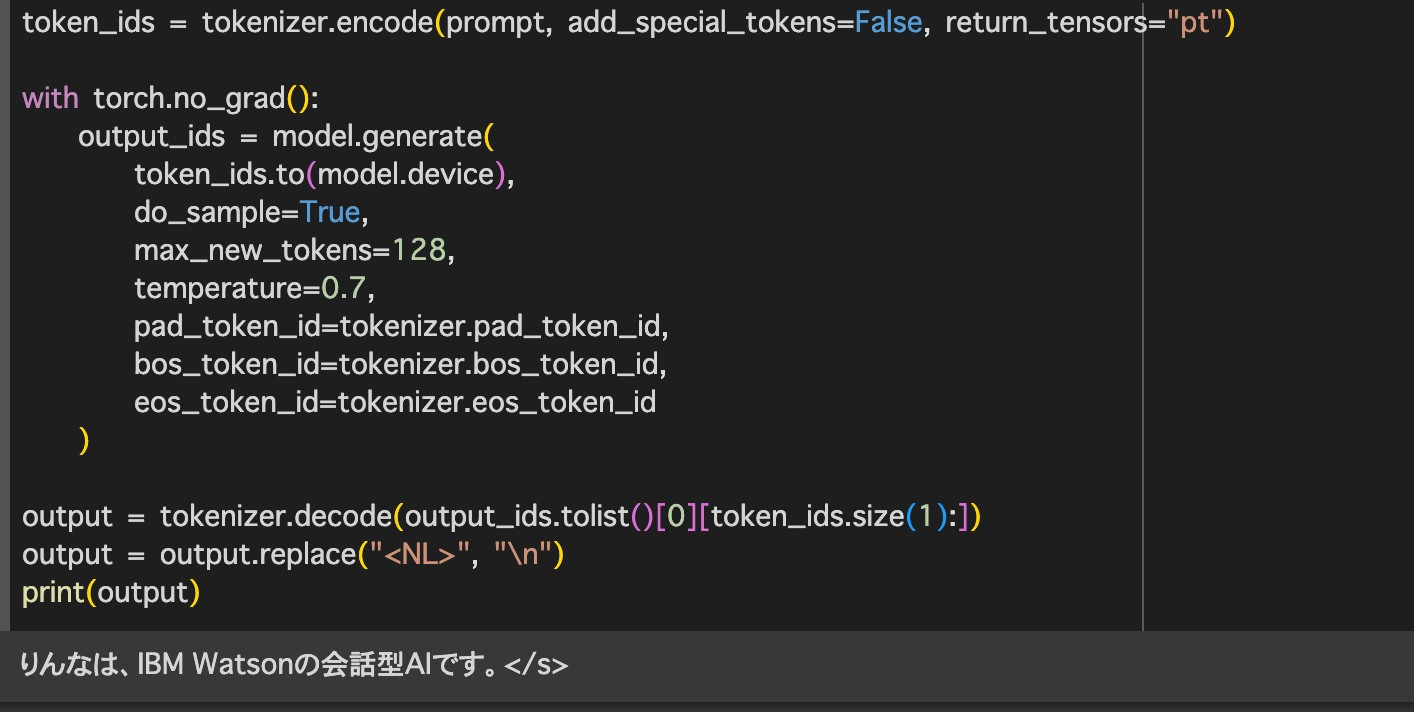
。。。IBM製のAIだった![]()
まとめ
- 大規模言語モデルはでっかいメモリがいる
- でっかいメモリを使おうとすると金がかかる
- 金をかけたくない-> 量子化すればワンチャン読み込めるかも?
最後にColabのリンクを共有します!prompt部分いじったら色々遊べます。
他のモデルでも3.6b程度までなら省メモリで動かせると思われます!