前回、メッセージングのミドルウェアとしてFlumeを使った記事を投稿しました。
No.4 新卒未経験エンジニアがFlumeを使ってTweetを取得してみた
同じメッセージングのミドルウェアとして今回はKafkaを使ってメッセージのやり取りをしてみました。
Kafkaって何?
Kafkaは、LinkedInが開発したメッセージングのミドルウェアです。
基本的な仕組みについては前回のFlumeについての記事で紹介したイメージと一緒で、大量のログデータを処理するためのものです。
ちなみにKafkaは秒間200万メッセージ処理を実現しているらしいです。
すごい。。。
Flumeとの違い

KafkaはProducer → Broker → Consumerの3つのコンポーネントで構成されています。
Producerでメッセージを送信し、Brokerにメッセージを一旦保存して最終的にConsumerでメッセージを受信します。
一般的なクライアントサーバモデルにおいて、クライアントがサーバにデータを取りに行くことを「Pull」、サーバがクライアントへデータを送り出すことを「Push」といいます。
KafkaはPull型を採用しています。
Pull型のモデルをPublish-Subscribeモデルとも言います。
Pull型であるメリットは
・Brokerがデータ転送量などを意識する必要がない
・Producerが自らスループット調整できる
・バッチ処理にも対応できる
というものがあります。
Kafkaの仕組み
上記の図ではBrokerが1つしかないのですが、実際にはZookeeperというOSS(オープンソースソフトウェア)が裏で動いていて、複数のKafkaが連携してクラスターとなっています。
仕組みをとても分かりやすく紹介されているブログを見つけましたので紹介します。
シシド・カフカさんが気になって調べていたら Apache Kafka 入門していたメモ
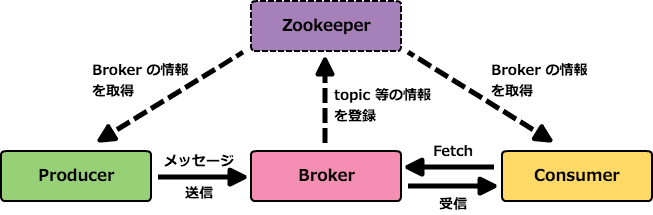
Producer、Broker、Consumer、Zookeeperに関して僕自身が持っているイメージを再び居酒屋を用いて説明します。
配役は以下です。
・Producer、Consumer:お客さん
・Broker:居酒屋
・Zookeeper:キャッチの人
流れとしては
居酒屋(Broker)は事前にキャッチの人(Zookeeper)に場所などの情報を伝えておきます。
↓
キャッチの人(Zookeeper)はお客さん(Producer)に居酒屋(Broker)の場所を教えます。
↓
お客さん(Producer)はその居酒屋(Broker)で注文(メッセージ送信)します。
という流れです。
各コンポーネントでどんなことをしているかをもっと詳しく知りたい方は上記のリンクを見て頂ければと思います。
図に書かれているtopicというのは、ProducerからBrokerにメッセージを送信する際に付ける名前(キュー名)です。
チャットのグループ名的なものです。
Brokerはメッセージをtopic名毎に保存します。
ちなみにZookeeperは、必須の構成ではなく、Zookeeper無しでもKafkaは利用出来ます。
キャッチの人がいなくても居酒屋を選べるのと同じですね!
事前準備
それでは実践に移っていくための事前準備をしていきます。
■ Zookeeperのインストール
まずはキャッチの人を連れてきましょう!笑
$ brew install zookeeper
■ Kafkaのインストール
続いて居酒屋さんもオープンさせましょう!
$ brew install kafka
いざ実践!
事前準備が整ったので実際にKafkaを動かしていきます。
まずはZookeeperを起動します。
■ Zookeeperの起動
$ sudo zkServer start
ZooKeeper JMX enabled by default
Using config: /usr/local/etc/zookeeper/zoo.cfg
Starting zookeeper ... STARTED
次にKafkaを起動します。
■ Kafkaの起動
$ sudo kafka-server-start /usr/local/etc/kafka/server.properties
[2017-10-11 10:31:54,985] INFO KafkaConfig values:
advertised.host.name = null
advertised.listeners = null
advertised.port = null
alter.config.policy.class.name = null
authorizer.class.name =
auto.create.topics.enable = true
auto.leader.rebalance.enable = true
background.threads = 10
broker.id = 0
broker.id.generation.enable = true
broker.rack = null
compression.type = producer
...
...
...
ZookeeperとKafkaが起動出来たらいよいよメッセージの送受信を行っていきます。
■メッセージの送受信
まずはtopicを作成しましょう。
上でも書きましたが、Kafkaはtopicという単位でメッセージをやり取りします。
ここでは「hello_kafka」というtopicを送信(produce) → 受信(consume)していきます。
【topicの作成】
$ kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic hello_kafka
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic "hello_kafka".
WARNINGの部分をGoogle翻訳にかけると
警告:メトリック名の制限により、ピリオド( "。")またはアンダースコア( '_')のトピックが衝突する可能性があります。問題を回避するには、どちらか一方を使用するのが最善ですが、両方を使用するのは最善です。
どうやら「.」(ピリオド)と「_」(アンダーバー)を両方使用した方がいいよ、ということっぽいです。
無視して続けます。
きちんとtopicを作成出来たかどうかを確認します。
$ kafka-topics --list --zookeeper localhost:2181
hello_kafka
topic名が表示されたら、無事topicが作成されています!
【Consumer起動】
topic作成がうまく行ったら次にメッセージの受信側であるConsumerを起動します。
先ほどKafkaを立ち上げたターミナルとは別に新しくターミナルを立ち上げます。
$ kafka-console-consumer --zookeeper localhost:2181 --topic hello_kafka --from-beginning
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
上記のコマンドを入力すると「Using...」以下のメッセージが表示されてメッセージの受信待ち状態になります。
【Producer起動】
Kafkaを立ち上げたターミナル、Consumerを起動したターミナルとは別にまた新しくターミナルを起動します。
$ kafka-console-producer --broker-list localhost:9092 --topic hello_kafka
>
上記のコマンドを打つとメッセージの入力待ちの状態になります。
ここで
>my first kafka message!
と入力すると、先ほどConsumerを起動したターミナルの方に
my first kafka message!
が表示されたらメッセージの送受信完了です!!
ちなみにConsumerとProducerで指定しているlocalhostのポート番号2181番と9092番はKafkaのデフォルトの出力用ポートと入力用ポートです。
まとめ
Producerで送信されたメッセージがKafkaにPushされ、ConsumerがメッセージをPullしてくる、という一通りの流れを試してみました。
使ってみた感想としてはFlumeの時と同じく、そんなに複雑な操作ではなく意外と分かりやすかったな、という感じです。
KafkaとFlumeを組み合わせて
Flume→Kafka→Flume
のように、FlumeのChannel的な役割をKafkaのBrokerに担わせるような使い方もあるようです。
Flume、Kafkaと一見とっつきにくそうなツールも、チュートリアルを試してみると意外とそうでもない、ということが分かりました!
皆さんもとっつきにくそうなツールも喰わず嫌いせずに試してみましょう!!!
次回は「新卒未経験エンジニアがDockerを使ってみた(仮)」をお送りします!
お楽しみに!!