KerasとTPUの黒魔術です。Kerasで重み共有レイヤーを使い、入力が2つあるモデルを訓練することを考えます。かなり特殊な状況で、訓練は入力が2つで(2つのサンプルを使って)行いたいものの、実際に推論するときは入力が1つで計算したい場合があります。例えば、Siamese Networkのようなサンプル間の距離を考えながら、埋め込み計算をする場合です。
つまり、「入力が2つのモデルから入力が1つのモデルに係数を転移させる」ということが必要となります。この手の黒魔術はCPUやGPUだとうまくいってTPUだと失敗するケースが多いものの、TPUでも成功したのが美味しいポイントでした。
環境:Colab TPU、TensorFlow v1.12.0
こんなイメージ
MLPやCNNでの想定です。この2つではうまくいくことを確認しましたが、RNNでは確認していないので、もしかするとうまくいかないかもしれません。
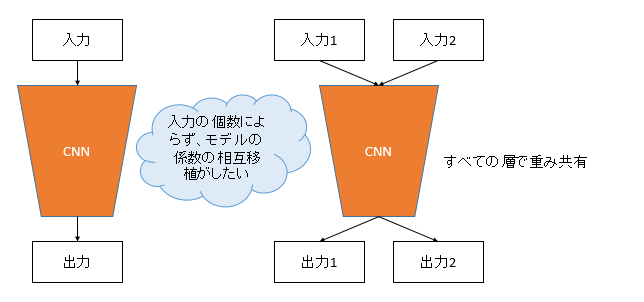
この図のように、「入力が1つのモデルから、入力が2つのモデルへ」またはその逆の「入力が2つのモデルから、入力が1つのモデルへ」係数の転移(移植)を相互で行いたいと思います。また入力が2つのモデルでは、全ての層の係数が入力に対して共有されているものとします。
「こんな移植できるの?」と思うかもしれませんができます。
そもそもどうやって全レイヤーの重みが共有されるようなネットワークを作る?
重み共有レイヤー
大きなポイントはネットワークの定義方法です。Kerasのドキュメントにもありますが、重み共有レイヤーのよくありがちな実装では、Functional APIを使い、
from keras.layers import Dense, Input
input1 = Input((784,))
input2 = Input((784,))
some_layer = Dense(128, activation="relu")
x1 = some_layer(input1)
x2 = some_layer(input2)
というように、「1回レイヤーの変数を定義して、その後にKerasのテンソルを計算する」というような計算をします。Functional APIを知らないとこれだけで気持ち悪いような感じはしますが、Sequential APIは入門としては良いものの、ほとんど運用上のメリットがないので、ちょっと突っ込んだことするならFunctional APIを使いましょう。
例えばFunctional APIで入力が1つのモデルでは、
x1 = Dense(128, activation="relu")(input1)
のような書き方をします。重み共有レイヤーでなければこれは間違いではありません。しかし、これでもう1個、
x2 = Dense(128, activation="relu")(input2)
というような書き方をすると、x1とx2の重みは共有されません。なぜなら、レイヤーのインスタンスが異なるためだからです。先程のようなレイヤーのインスタンスを1つにするようにしてあげなければいけません。
先程の書き方はネットワークが浅ければOKです。ただ、ネットワークが深くなってしまうと、2倍、3倍のコードを書かなければいけないのでスマートではありません。なので、CNNのような深いモデルに対してはもうちょっと工夫した書き方をする必要があります。
レイヤーを配列で管理してしまう
一つの案としては、レイヤーのインスタンスをリストとして管理してしまうことです。
from keras import layers
layer_list = []
layer_list.append(layers.Conv2D(32, 3, padding="same"))
layer_list.append(layers.BatchNormalization())
layer_list.append(layers.Activation("relu"))
layer_list.append(layers.AveragePooling2D(2))
layer_list.append(layers.Conv2D(64, 3, padding="same"))
layer_list.append(layers.BatchNormalization())
layer_list.append(layers.Activation("relu"))
layer_list.append(layers.GlobalAveragePooling2D())
もうちょっと深くなったらforループ等で書くのが楽でしょう。このリストに対して、
inputs = [Input((28,28,1)) for i in range(2)]
outputs = []
for input in inputs:
x = input
for l in layers:
x = l(x)
outputs.append(x)
とforループでレイヤー呼び出しをしてしまいます。モデルの定義は、
from keras.models import Model
model = Model(inputs, outputs)
とすればいいですからね(入力が1個の場合はリストが不要なのでif等で分岐させましょう)。レイヤーのインスタンスをリストに格納し、forループで呼び出すという飛び技を使うことで、重み共有レイヤーがあっても可読性を損なうことがなくなります。入力が1つのモデル、2つのモデルでも全く同じコードから生成することができるのもポイントが高いです。
ちなみに今回は深く掘り下げませんが、ResNetのような分岐構造がある場合はちょっと面倒になります。しかし、AddやConcatのところで区切り、メイン側とSkipConnection側で多重配列にすれば、動的なネットワーク生成はできると思います。VGGやMobileNetのような直線的なモデルの場合は今回の方法でOKです。
入力が1つのモデル→入力が2つのモデルへの係数移植
安直に2つのモデルを作るとうまくいかない
今までの話をまとめて、入力が2つでも1つでも同じように作れる関数を定義しました。
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras.models import Model
from tensorflow.contrib.tpu.python.tpu import keras_support
import tensorflow.keras.backend as K
import numpy as np
import os
def create_model(inputs):
# layers
layer_list = []
layer_list.append(layers.Dense(64, activation="relu"))
layer_list.append(layers.Dense(5, activation="relu"))
# outputs
outputs = []
for x in inputs:
for l in layer_list:
x = l(x)
outputs.append(x)
if len(outputs) == 1:
return Model(inputs[0], outputs[0])
else:
# 出力層が複数あるとpredictでうまくいかないのでConcatする
x = layers.Concatenate()(outputs)
return Model(inputs, x)
ただし入力が2つあるケースで、出力も2つにするとpredictがうまくいかない(shapeが違うぞと言われる)ので、暫定的にConcatenateさせています。これだとエラーは出ません。
そして、入力が1つのモデルと入力が2つのモデルを別々に生成してみます。
if __name__ == "__main__":
K.clear_session()
X = np.arange(800).reshape(8,100)
# 別々にモデルを作ると別な出力になる
# 入力が1つのモデル
input = layers.Input((100,))
single_model = create_model([input])
single_model.compile(tf.train.GradientDescentOptimizer(0.1), "mse") # TPUのモデル変換のためなんでなんでもよい
single_model.summary()
# TPUモデルに変換
tpu_grpc_url = "grpc://"+os.environ["COLAB_TPU_ADDR"]
tpu_cluster_resolver = tf.contrib.cluster_resolver.TPUClusterResolver(tpu_grpc_url)
strategy = keras_support.TPUDistributionStrategy(tpu_cluster_resolver)
single_model = tf.contrib.tpu.keras_to_tpu_model(single_model, strategy=strategy)
# singleの推論
y_single = single_model.predict(X)
print(y_single)
# 入力が2つのモデル
input1 = layers.Input((100,))
input2 = layers.Input((100,))
double_model = create_model([input1, input2])
double_model.compile(tf.train.GradientDescentOptimizer(0.1), "mse") # TPUのモデル変換のためなんでなんでもよい
double_model.summary()
# TPUモデルに変換
double_model = tf.contrib.tpu.keras_to_tpu_model(double_model, strategy=strategy)
# doubleの推論
y_double = double_model.predict([X, X])
print(y_double)
これは当然別々の出力を返します(具体的な値は初期値の乱数挙動によって実行するたびに変わります)。レイヤーのインスタンスが違うので当たり前ですね。
# 入力が1つのモデル
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 100) 0
_________________________________________________________________
dense (Dense) (None, 64) 6464
_________________________________________________________________
dense_1 (Dense) (None, 5) 325
=================================================================
Total params: 6,789
Trainable params: 6,789
Non-trainable params: 0
_________________________________________________________________
# その推論
[[ 0. 0. 57.22351 0. 0. ]
[ 0. 0. 87.0583 0. 0. ]
[ 0. 0. 115.63985 0. 0. ]
[ 0. 0. 145.86166 0. 0. ]
[ 0. 0. 176.26633 0. 0. ]
[ 0. 0. 209.57587 0. 0. ]
[ 0. 0. 242.88531 0. 0. ]
[ 0. 0. 276.19476 0. 0. ]]
# 入力が2つのモデル
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_2 (InputLayer) (None, 100) 0
__________________________________________________________________________________________________
input_3 (InputLayer) (None, 100) 0
__________________________________________________________________________________________________
dense_2 (Dense) (None, 64) 6464 input_2[0][0]
input_3[0][0]
__________________________________________________________________________________________________
dense_3 (Dense) (None, 5) 325 dense_2[0][0]
dense_2[1][0]
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 10) 0 dense_3[0][0]
dense_3[1][0]
==================================================================================================
Total params: 6,789
Trainable params: 6,789
Non-trainable params: 0
__________________________________________________________________________________________________
# その推論(columnの0~4と5~9は入力の1つ目、2つ目に対応しているが、内部での重みが共有されているので、同一の値を返す)
[[ 0. 38.57988 0. 95.709076 37.404163 0.
38.57988 0. 95.709076 37.404163]
[ 0. 152.1218 0. 209.1978 140.52289 0.
152.1218 0. 209.1978 140.52289 ]
[ 0. 257.20923 0. 312.2815 238.54837 0.
257.20923 0. 312.2815 238.54837 ]
[ 0. 359.7143 0. 412.8396 332.09595 0.
359.7143 0. 412.8396 332.09595 ]
[ 0. 460.10046 0. 512.0321 419.4279 0.
460.10046 0. 512.0321 419.4279 ]
[ 0. 560.48676 0. 611.2248 506.75964 0.
560.48676 0. 611.2248 506.75964 ]
[ 0. 660.87305 0. 710.41736 594.09155 0.
660.87305 0. 710.41736 594.09155 ]
[ 0. 761.2593 0. 809.61 681.4234 0.
761.2593 0. 809.61 681.4234 ]]
今、「重み共有レイヤー」と「モデル同士のレイヤー(重み)の共有」を同時に論じているので話が見えにくくなっていますが、入力が2つのモデルでは内部での重みは共有されているものの、入力が2つのモデルと1つのモデルの同期は取れていません。この記事での目的は後者の同期を図るものです。
save_weights, load_weightsで係数を転移させる
実は、(少なくとも同一モデル内の全レイヤーで重みを共有していれば)入力の個数が異なっていても、save_weights()→load_weights()で係数を転移させることができます。これによって、レイヤーのインスタンスが別々でも同一の係数を再現させることが可能になります。
先程の例を少し変えます。
if __name__ == "__main__":
K.clear_session()
X = np.arange(800).reshape(8,100)
# save_weightsをはさむと入力の個数が違っても同期できる
# 入力が1つのモデル
input = layers.Input((100,))
single_model = create_model([input])
single_model.compile(tf.train.GradientDescentOptimizer(0.1), "mse") # TPUのモデル変換のためなんでなんでもよい
single_model.save_weights("weights.hdf5", save_format="h5")
# TPUモデルに変換
tpu_grpc_url = "grpc://"+os.environ["COLAB_TPU_ADDR"]
tpu_cluster_resolver = tf.contrib.cluster_resolver.TPUClusterResolver(tpu_grpc_url)
strategy = keras_support.TPUDistributionStrategy(tpu_cluster_resolver)
single_model = tf.contrib.tpu.keras_to_tpu_model(single_model, strategy=strategy)
# singleの推論
y_single = single_model.predict(X)
print(y_single)
# 入力が2つのモデルの係数をload_weightsで、入力が1つのモデルから転移
input1 = layers.Input((100,))
input2 = layers.Input((100,))
double_model = create_model([input1, input2])
double_model.load_weights("weights.hdf5")
double_model.compile(tf.train.GradientDescentOptimizer(0.1), "mse") # TPUのモデル変換のためなんでなんでもよい
# TPUモデルに変換
double_model = tf.contrib.tpu.keras_to_tpu_model(double_model, strategy=strategy)
# doubleの推論
y_double = double_model.predict([X, X])
print(y_double)
# 結果の確認
print("double_modelの重み共有 :", np.all(y_double[:,:5]==y_double[:,5:]))
print("double_modelとsingle_modelの重み共有 :", np.all(y_double[:,:5]==y_single))
本当にうまくいくでしょうか?
# 入力が1つのモデル
[[1.17118584e+02 1.67248783e+01 0.00000000e+00 3.48740425e+01
0.00000000e+00]
[3.40153900e+02 4.46984100e+00 0.00000000e+00 5.20611725e+01
0.00000000e+00]
[5.67267822e+02 5.66595459e+00 0.00000000e+00 6.38724823e+01
1.02516174e+00]
[7.89560669e+02 1.10407867e+01 0.00000000e+00 7.61143646e+01
3.85089111e+00]
[1.01189038e+03 1.56332855e+01 0.00000000e+00 8.88464508e+01
6.88870239e+00]
[1.23421997e+03 2.02258453e+01 0.00000000e+00 1.01578629e+02
9.92658997e+00]
[1.45522437e+03 2.51077271e+01 0.00000000e+00 1.14337677e+02
1.42870178e+01]
[1.67615308e+03 3.01563110e+01 0.00000000e+00 1.27196930e+02
1.91447449e+01]]
# 入力が2つのモデル
[[1.17118584e+02 1.67248783e+01 0.00000000e+00 3.48740425e+01
0.00000000e+00 1.17118584e+02 1.67248783e+01 0.00000000e+00
3.48740425e+01 0.00000000e+00]
[3.40153900e+02 4.46984100e+00 0.00000000e+00 5.20611725e+01
0.00000000e+00 3.40153900e+02 4.46984100e+00 0.00000000e+00
5.20611725e+01 0.00000000e+00]
[5.67267822e+02 5.66595459e+00 0.00000000e+00 6.38724823e+01
1.02516174e+00 5.67267822e+02 5.66595459e+00 0.00000000e+00
6.38724823e+01 1.02516174e+00]
[7.89560669e+02 1.10407867e+01 0.00000000e+00 7.61143646e+01
3.85089111e+00 7.89560669e+02 1.10407867e+01 0.00000000e+00
7.61143646e+01 3.85089111e+00]
[1.01189038e+03 1.56332855e+01 0.00000000e+00 8.88464508e+01
6.88870239e+00 1.01189038e+03 1.56332855e+01 0.00000000e+00
8.88464508e+01 6.88870239e+00]
[1.23421997e+03 2.02258453e+01 0.00000000e+00 1.01578629e+02
9.92658997e+00 1.23421997e+03 2.02258453e+01 0.00000000e+00
1.01578629e+02 9.92658997e+00]
[1.45522437e+03 2.51077271e+01 0.00000000e+00 1.14337677e+02
1.42870178e+01 1.45522437e+03 2.51077271e+01 0.00000000e+00
1.14337677e+02 1.42870178e+01]
[1.67615308e+03 3.01563110e+01 0.00000000e+00 1.27196930e+02
1.91447449e+01 1.67615308e+03 3.01563110e+01 0.00000000e+00
1.27196930e+02 1.91447449e+01]]
double_modelの重み共有 : True
double_modelとsingle_modelの重み共有 : True
うまくいきました。設計上、入力が2つのモデル内での重み共有とが行われているのと同時に、入力が1つのモデルと入力が2つのモデルの係数を同期させることに成功しました。入力の個数が違ってもweightsのファイルが適用できてしまうの面白いですね。
入力が2つのモデル→入力が1つのモデルへの係数移植
今度は逆の移植をしてみます。同じようにできます。
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras.models import Model
from tensorflow.contrib.tpu.python.tpu import keras_support
import tensorflow.keras.backend as K
import numpy as np
import os
def create_model(inputs):
# layers
layer_list = []
layer_list.append(layers.Dense(64, activation="relu"))
layer_list.append(layers.Dense(5, activation="relu"))
# outputs
outputs = []
for x in inputs:
for l in layer_list:
x = l(x)
outputs.append(x)
if len(outputs) == 1:
return Model(inputs[0], outputs[0])
else:
# 出力層が複数あるとpredictでうまくいかないのでConcatする
x = layers.Concatenate()(outputs)
return Model(inputs, x)
if __name__ == "__main__":
K.clear_session()
X = np.arange(800).reshape(8,100)
# save_weightsをはさむと入力の個数が違っても同期できる
# 入力が2つのモデル
input1 = layers.Input((100,))
input2 = layers.Input((100,))
double_model = create_model([input1, input2])
double_model.compile(tf.train.GradientDescentOptimizer(0.1), "mse") # TPUのモデル変換のためなんでなんでもよい
double_model.save_weights("weights.hdf5", save_format="h5")
# TPUモデルに変換
tpu_grpc_url = "grpc://"+os.environ["COLAB_TPU_ADDR"]
tpu_cluster_resolver = tf.contrib.cluster_resolver.TPUClusterResolver(tpu_grpc_url)
strategy = keras_support.TPUDistributionStrategy(tpu_cluster_resolver)
double_model = tf.contrib.tpu.keras_to_tpu_model(double_model, strategy=strategy)
# doubleの推論
y_double = double_model.predict([X, X])
print(y_double)
# 入力が1つのモデルの係数をload_weightsで、入力が2つのモデルから転移
input = layers.Input((100,))
single_model = create_model([input])
single_model.load_weights("weights.hdf5")
single_model.compile(tf.train.GradientDescentOptimizer(0.1), "mse") # TPUのモデル変換のためなんでなんでもよい
# TPUモデルに変換
single_model = tf.contrib.tpu.keras_to_tpu_model(single_model, strategy=strategy)
# singleの推論
y_single = single_model.predict(X)
print(y_single)
# 結果の確認
print("double_modelの重み共有 :", np.all(y_double[:,:5]==y_double[:,5:]))
print("double_modelとsingle_modelの重み共有 :", np.all(y_double[:,:5]==y_single))
結果は以下の通りです。
# 入力が2つのモデルの推論
[[ 113.60694 0. 0. 0. 0. 113.60694
0. 0. 0. 0. ]
[ 316.3941 0. 0. 0. 0. 316.3941
0. 0. 0. 0. ]
[ 524.7592 0. 0. 0. 0. 524.7592
0. 0. 0. 0. ]
[ 733.12445 0. 0. 0. 0. 733.12445
0. 0. 0. 0. ]
[ 942.0818 0. 0. 0. 0. 942.0818
0. 0. 0. 0. ]
[1151.6317 0. 0. 0. 0. 1151.6317
0. 0. 0. 0. ]
[1361.1812 0. 0. 0. 0. 1361.1812
0. 0. 0. 0. ]
[1570.731 0. 0. 0. 0. 1570.731
0. 0. 0. 0. ]]
# 入力が1つのモデルの推論
[[ 113.60694 0. 0. 0. 0. ]
[ 316.3941 0. 0. 0. 0. ]
[ 524.7592 0. 0. 0. 0. ]
[ 733.12445 0. 0. 0. 0. ]
[ 942.0818 0. 0. 0. 0. ]
[1151.6317 0. 0. 0. 0. ]
[1361.1812 0. 0. 0. 0. ]
[1570.731 0. 0. 0. 0. ]]
double_modelの重み共有 : True
double_modelとsingle_modelの重み共有 : True
load_weights(), save_weights()はシリアライザー感覚で使えるというわけです。
まとめ
- モデル内での重み共有については、Functional APIを使い重み共有レイヤーを使う。この際、例えばレイヤーのインスタンスをリスト等で格納しておいて、動的にネットワークを生成するとスマートに定義できる。
- モデル同士の重みの共有については、(少なくともCNNやMLPのようなモデルで、全レイヤーが重み共有されている状態では)入力の数が変わってもload_weights(), save_weights()で重みの同期を取ることができる
- 係数の保存が、ファイルを通したシリアライザーのような挙動をするので、(少なくとも条件を限定すれば)係数の相互転移ができる
- 別の言い方をすれば、ImageNetで訓練した入力が1つのモデルに対して、学習積み係数をそのままスライドさせて入力を2つや3つにできる。冒頭の例に出した、Siamese Networkを分類モデルから転移学習させることも理論的にはできる
ということでした。以上、KerasとTPUを使った闇の魔術の紹介でした。