Python初心者です。普段C#を使っている自分がPythonを勉強して驚いたことをまとめました。公式チュートリアルの勉強メモです。この公式チュートリアルはよくできていて、プログラミング経験者ならこれを読むのが一番わかりやすいと思います。
環境:Python3.6(64bit)、Anaconda 4.3.0(64bit)、Visual Studio 2017 Community
Visual Studio Installer経由でPython、Anacondaを同時にインストールできます。Anacondaのオプションを入れるとJupyter NotebookやNumpyもまとめてインストールしてくれるのでおすすめ。Jupyter Notebookの初回起動時にコンソールが一瞬表示されて起動しないことがありますが、パスが通っていないのが原因なので修正しましょう。
参考:Visual Studio 2017におけるPythonサポート (1/2)
http://www.atmarkit.co.jp/ait/articles/1708/18/news028.html
Jupyter Notebookを立ち上げると,一瞬だけコンソール画面が出てから落ちる
http://publicjournal.hatenablog.com/entry/2017/02/04/010544
1. 複数同時の代入
これは感動しました。2つの値を入れ替えるという操作をよくするのですが、仮の変数を用意しなくてもよくなります。例えばバブルソート。
def bubble(array):
for i in range(len(array)):
for j in range(i, len(array)):
if(array[i] > array[j]):
array[i], array[j] = array[j], array[i]
x = [1,7,2,9,-1]
bubble(x)
print(x)#[-1, 1, 2, 7, 9]
C#(他よくある言語)だと入れ替え部分でtmpのような変数を用意する必要があります。追記:C#でもC#7.0で導入されたValueTupleを使うと同じことができます。コメントで指摘してくださった方ありがとうございました。
var tmp = array[i];
array[i] = array[j];
array[j] = tmp;
//ValueTupleを導入
(array[i], array[j]) = (array[j], array[i]);
2.forが実質的にforeach
多重ループで次のようなバグをよくやります。こういうやらかしが出なくなるのがいいですよね。
for(var i=0; i<3; i++)
{
for(var j=0; j<3; i++)//無限ループ
{
Console.WriteLine($"i = {i}, j = {j}");
//i = 0, j = 0
//i = 1, j = 0
// : : (i=3になってもbreakせず無限に続く)
}
}
C#でもforではなくforeachを使えという声もあります。PHPでもforの中で変数名のプレフィックスの$を忘れたりfor文自体バグが出やすいんですよね。上のコードをforeachを使って書き直します(自分はこっちのほうが好きです)。
foreach(var i in Enumerable.Range(0, 3))
{
foreach(var j in Enumerable.Range(0,3))
{
Console.WriteLine($"i = {i}, j = {j}");
//i = 0, j = 0
//i = 0, j = 1
// : :
//i = 2, j = 2
}
}
Pythonのfor文とそっくりですよね。Pythonのfor文でリストを回すときにインデックスが欲しい場合はenumerate()を使ってKey,Value形式にできます。(for key, value in enumerate(list):)
3.リストをprintに入れるとダンプされる
string.Joinで結合するのだるくなくて感動。ただC#(VisualStudio)の場合はとても優秀なデバッガーがあるのでこれだけで比較するのなと思います。
var x = new int[] { 1, 2, 3, 4, 5 };
Console.WriteLine(x);//System.Int32[]
Console.WriteLine(string.Join(", ", x));//1, 2, 3, 4, 5
Pythonはとてもシンプルです。
x = [1, 2, 3, 4, 5]
print(x)#[1, 2, 3, 4, 5]
4.リストのスライス記法から見るミュータブル、イミュータブル
きっかけはPythonで列挙するシーケンスに対して、ループ内で変更を加えるという怪しい(?)操作ができることから。
data = list(range(3))#[0, 1, 2]
for i in data:
if i == 2:
data.append(3)
print(i)
print(data)
# 0
# 1
# 2
# 3
# [0, 1, 2, 3]
C#の場合ここはしっかりしていて、同じことをするとSystem.InvalidOperationExceptionの例外が発生します。
var data = Enumerable.Range(0, 3).ToList();
foreach(var i in data)
{
if (i == 2) data.Add(3);//System.InvalidOperationException
Console.WriteLine(i);
//0
//1
//2
//ハンドルされていない例外: System.InvalidOperationException: コレクションが変更さ
//れました。列挙操作は実行されない可能性があります。
// 場所 System.ThrowHelper.ThrowInvalidOperationException(ExceptionResource reso
//urce)
// 場所 System.Collections.Generic.List`1.Enumerator.MoveNextRare()
// 場所 System.Collections.Generic.List`1.Enumerator.MoveNext()
}
Pythonの例で元の値に準じてループをしたい(つまり0,1,2で終わらせたい)場合は、スライス記法[:]でコピーすることが推奨されています。Pythonの公式ドキュメントを見ると
ループ内部でイテレートしているシーケンスを修正する必要があれば (例えば選択されたアイテムを複製するために)、最初にコピーを作ることをお勧めします。シーケンスに対するイテレーションは暗黙にコピーを作りません。スライス記法はこれを特に便利にします:
ただ、これシャローコピーなんですよね。チュートリアルの「データ構造」に詳しく書いてありました。
list.copy()
リストの浅い (shallow) コピーを返します。a[:] と等価です。
シャローコピー自体は悪いことではないんですが、どういう挙動になるかよく知った上で使わないといけません。イミュータブルなオブジェクトの場合は、変数の値がコピーされます。
import copy
def dump_vars():
for key, val in dic.items():
dump_var(key, val)
def dump_var(key, val):
print(key, "= ", val, "id =", id(val))
print("ids in", key, "=", [id(i) for i in val])
x = list((x, x+1)for x in range(3))
print("id(x) = ",id(x))
print()
# f:そのまま代入、g:シャローコピー、h:ディープコピー
dic = {"f" : x, "g" : x[:], "h" : copy.deepcopy(x)}
dump_vars()
print()
dic["f"][0] = (-1,-1)
dump_vars()
# id(x) = 41301320
# f = [(0, 1), (1, 2), (2, 3)] id = 41301320
# ids in f = [41291272, 41291400, 41327240]
# g = [(0, 1), (1, 2), (2, 3)] id = 44305992
# ids in g = [41291272, 41291400, 41327240]
# h = [(0, 1), (1, 2), (2, 3)] id = 44306184
# ids in h = [41291272, 41291400, 41327240]
# f = [(-1, -1), (1, 2), (2, 3)] id = 41301320
# ids in f = [41291720, 41291400, 41327240]
# g = [(0, 1), (1, 2), (2, 3)] id = 44305992
# ids in g = [41291272, 41291400, 41327240]
# h = [(0, 1), (1, 2), (2, 3)] id = 44306184
# ids in h = [41291272, 41291400, 41327240]
id(x)はユニークなオブジェクト識別子を返す関数で、実行ごとに結果は変わります。f,g,hの中身のIDは全て同じなのに(なぜディープコピーまで中身のIDが等しくなっているかというと、Pythonの代入は参照渡しだから:後述)、代入後f[0]のIDと値のみ変わっていますね。タプルはイミュータブルな型なので、スライス記法でもディープコピーと同様の結果が得られます。タプルをリスト(ミュータブルな型)にするとどうでしょうか。
import copy
def dump_vars():
for key, val in dic.items():
dump_var(key, val)
def dump_var(key, val):
print(key, "= ", val, "id =", id(val))
print("ids in", key, "=", [id(i) for i in val])
x = list([x, x+1] for x in range(3))#ここを()から[]にした
print("id(x) = ",id(x))
print()
# f:そのまま代入、g:シャローコピー、h:ディープコピー
dic = {"f" : x, "g" : x[:], "h" : copy.deepcopy(x)}
dump_vars()
print()
dic["f"][0][0] = -1#ミュータブルな型なのでリストの中身を直接代入できる
dump_vars()
# id(x) = 51131720
# f = [[0, 1], [1, 2], [2, 3]] id = 51131720
# ids in f = [51514888, 51515080, 51635208]
# g = [[0, 1], [1, 2], [2, 3]] id = 51635144
# ids in g = [51514888, 51515080, 51635208]
# h = [[0, 1], [1, 2], [2, 3]] id = 51635080
# ids in h = [51635016, 51634888, 51634824]
# f = [[-1, 1], [1, 2], [2, 3]] id = 51131720
# ids in f = [51514888, 51515080, 51635208]
# g = [[-1, 1], [1, 2], [2, 3]] id = 51635144
# ids in g = [51514888, 51515080, 51635208]
# h = [[0, 1], [1, 2], [2, 3]] id = 51635080
# ids in h = [51635016, 51634888, 51634824]
f(直接代入)とg(シャローコピー)リストの中身のIDのみ一致するようになり、代入後はf,gが連動する形で値が変わっています。gがシャローコピー、hがディープコピーえあることを確認しやすいのはこちらでしょう。ここでいうディープコピー、シャローコピーというのは、ミュータブルなオブジェクトに対して再帰的に値をコピーするかと考えてよさそうです。本当にディープコピーをしたいのであればcopy.deepcopy()を使うべきです。「あれ、そういえばこんな挙動見たことあるぞ」とピンと思い出します。そうです。C#のToArray()と同じです。
var data1 = new int[] { 0, 1, 2 };
var z1 = data1.ToArray();
data1[0] = -1;
Console.WriteLine(string.Join(", ", z1));//0, 1, 2
var data2 = new int[][] { new int[] { 0, 1, 2 }, new int[] { 10, 11, 12 } };
var z2 = data2.ToArray();
data2[0][0] = -1;
Console.WriteLine(string.Join(", ", z2.Select(x => "[" + string.Join(", ", x) + "]")));
//[-1, 1, 2], [10, 11, 12] ← 2次元の場合はディープコピーにならない
前のC#の例ではリストだったのに今回は配列になっていますが、どっちも参照型なので挙動は変わりません。ToArray()は配列にコピーするメソッドですが再帰的にディープコピーする機能はありません。なるほど、これですっきりしました。
最初「Pythonも値型や参照型の違いのような挙動をするんじゃ?」と思ったのですが、どうもこれは違いました。例えば次のように変数のアドレスを見てみます。C#の場合このようにブレークポイントを配置しても、変数x,yのアドレスは全てにおいて変わりません(値型だからそれはそう)。
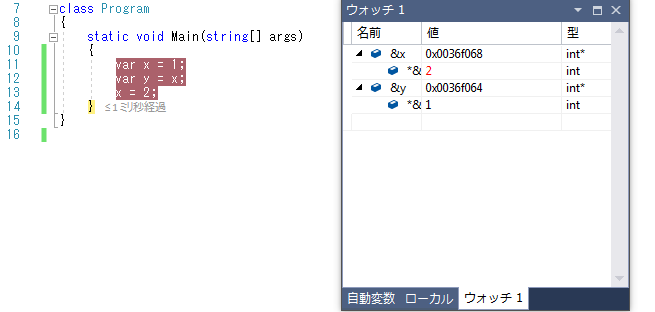
ただ、Pythonで同じことをやると結果が変わります。
x = 1
print("id(x) = ", id(x))
y = x
print("id(x) = ", id(x), "id(y) = ", id(y))
x = 2
print("id(x) = ", id(x), "id(y) = ", id(y))
# id(x) = 505324640
# id(x) = 505324640 id(y) = 505324640
# id(x) = 505324672 id(y) = 505324640
y = xと代入したところでxのIDがそのまま代入されてる!!? その後xに別の値を放り込むとIDは変わります。Pythonでは変数の代入は参照渡しで、オブジェクト指向言語にあるような参照型と値型の違いというようなのはイミュータブルかミュータブルかという点に集約されるようです。詳細は以下の記事で。
参考:Pythonの値渡しと参照渡し
http://amacbee.hatenablog.com/entry/2016/12/07/004510
しかし、ループ中の変数に追加されるのがまかり通って代入が参照渡しって、特にブラックボックス化しがちな内包表記の中でハマるとひどそうですね。気をつけないと。
5.for…else文
for文でbreakしなかった場合にelseが呼ばれます。一体何のためにあるだろうと考えて小一時間、有用そうな例を見つけられました。
for x in range(5):
print(x, end=" ")
if(x>5):
break
else:
print("finish")
# range(5) → 0 1 2 3 4 finish
# range(10) → 0 1 2 3 4 5 6
rangeが5まではbreakしていないのでfinishが呼ばれますが、それ以上はbreakしたためfinishが呼ばれません。これ、continueだけでは書けないんですよね(有限なら挙動は同じになるが、無限ループの場合は最後まで到達しない)。for…elseがない場合はループがbreakしたかどうかの変数を用意するか、この部分だけ関数化してif…returnします。前者はちょっとダサいので省略します。後者の関数化した場合はこうです。この書き方だと馴染みがあります。
def check(x):
for i in range(x):
print(i, end=" ")
if(i > 5):
return
print("finish")
check(5)#0 1 2 3 4 finish
check(10)#0 1 2 3 4 5 6
空のループに対してもelseが呼ばれます。なのでループ内でループ外変数を初期化するケースで、シーケンスが空でループが呼ばれなかった場合に書いておく…みたいなトリッキーな書き方のもできると思います。ループ外で一度初期化しておけばいいだけの話ですが。
for i in range(0):
print("i")
else:
print("do nothing")
# 出力はdo nothing
6.関数のデフォルト値が一度しか評価されない
これはちょっと頭をかしげました。関数のデフォルト値って再帰関数でよく使うんですよね。再帰の例でよく出て来る階乗関数を実装してみます。
def fact(x, tmp=1):
if(x==1):
return tmp
else:
return fact(x-1, tmp*x)
print(fact(1))#1
print(fact(2))#2
print(fact(3))#6
確かにうまく行っています。デフォルト引数をリストに変えて、カウントダウンをする関数を定義します。
def countdown(x, tmp=[]):
if(x==0):
return tmp
else:
return countdown(x-1, tmp + [x])
print(countdown(1))#[1]、appendはダメだった
print(countdown(2))#[2,1]
print(countdown(3))#[3,2,1]
else以下の第2引数をtmp.append(x)とするとエラー(AttributeError: 'NoneType' object has no attribute 'append')になります。tmp.append()だと参照はtmpのままだけど、tmp+[x]だと参照が新しいリストになるのかな?再帰ではなくもう少しわかりやすい例で。
追記:エラーになるのはappend()の返り値がNoneだからだそうです。コメントで指摘してくださった方ありがとうございました。
def switch(x, tmp=[0,0,0,0,0]):
tmp[x-1] = 1
return tmp
print(switch(1))#[1,0,0,0,0]
print(switch(2))#[1,1,0,0,0]
print(switch(3))#[1,1,1,0,0]
こんなトリッキーな実装されたら泣きそう。引数に対応したインデックスだけ1にする場合は、先程のスライス記法[:]を使ってみます。
def switch_new(x, tmp=[0,0,0,0,0]):
hoge = tmp[:]
hoge[x-1] = 1
return hoge
print(switch_new(1))#[1,0,0,0,0]
print(switch_new(2))#[0,1,0,0,0]
print(switch_new(3))#[0,0,1,0,0]
デフォルト値は一度しか評価されないというをふまえつつ、代入する対象の参照に気をつけるのが大事ということなのかなと。
追記:switch_newはこう書く方が多いそうです。コメントで指摘してくださった方ありがとうございました。
def switch_new(x, tmp=None):
if tmp is None:
tmp = [0,0,0,0,0]
tmp[x-1] = 1
return tmp
7.キーワード引数
関数のオーバーロードやオプション用のクラス定義をしなくていいのがいいと思いました。例えばラーメン屋店主になったつもりで、お客さんのスープや麺の量、トッピングの注文を聞いて値段を計算する関数を作ってみます。
# ラーメン屋の関数
def ramen(soup, **option):
price_soup = {"醤油":650, "塩":700, "味噌":720}#スープの指定は必須
price = price_soup.get(soup, 0)
#オプション(トッピング)
if("noodle" in option):#麺の増量
optprice = {"大盛":50, "特盛":100}
price += optprice.get(option["noodle"], 0)
price += option.get("egg", 0) * 70 #味玉1個70円
price += option.get("meat", 0) * 50 #チャーシュー1枚増量50円
return price
print(ramen("塩"))#700
print(ramen("醤油", noodle="大盛"))#700
print(ramen("味噌", egg=1, meat=2))#890
print(ramen("醤油", noodle="特盛", meat=6))#1050
print(ramen("塩", egg=2))#840
print(ramen("味噌", egg=1, rice=1))
# 790 ライスはメニューにないので受け付けない
普通ここまでオプションが多くなると、トッピング用のクラスを定義してそのインスタンスを引数に指定するのですが、そこらへんの手間を省けるのが動的型付けの強みだなと(もちろんそれ故のデメリットもあると思います)。
8.リストの内包表記
すごくLINQを使いたくなります。関数表記すると例えばmapしてsortするとなると、sort(map(…))のように操作と逆順に関数をネストしないといけないので直感的じゃないんですよね。せめてメソッドチェーンを使えれば、操作順になるので多少マシと思ったものの、返り値がNoneなのでチェーンできないと。もちろんライブラリを使えばできるのでしょうが。一番腑に落ちたのがリストの内包表現(公式チュートリアルでも内包表現を推奨しています)。ただこれでもメソッドチェーンできないし、つなげようとすると逆順になるというアレ。
例えば、次のような簡単なRPGを想定します(数値は適当)。
# モンスターのマスターデータ
master_enemy = [{"id":1, "name":"スライム", "maxhp":10},
{"id":2, "name":"ドラキー", "maxhp":15},
{"id":3, "name":"スライムベス", "maxhp":20}]
# 戦闘のオブジェクトの作成
def encount(id_list):
battle = []
#global master_enemy#グローバル変数を使う宣言→いらない
for id in id_list:
enemy = [x for x in master_enemy if x["id"] == id].pop()#ここをもうちょっとうまく書きたい
enemy.update({"nowhp":enemy["maxhp"]})#マスターから取得したdictにnowhpの項目を追加
battle.append(enemy)
battle.sort(key = lambda x:x["id"])#idでソート
print("\n".join(["{0} があらわれた! HP:{1}/{2}".format(x["name"], x["nowhp"], x["maxhp"]) for x in battle]))
return battle
battle = encount([1,3,2,2])
# スライム があらわれた! HP:10/10
# ドラキー があらわれた! HP:15/15
# ドラキー があらわれた! HP:15/15
# スライムベス があらわれた! HP:20/20
書いてて結構もどかしかったです。いきなりRPGなんてと思うかもしれませんが、実践的にはこういう操作、言語を問わず非常に多いです。モンスターのマスターデータの構造はMySQLに代表されるRDBMSの形式そのものですし、Pythonをサーバーで動かしてWebアプリを作ろうと思ったら必ずこのようなケースにぶち当たります。デスクトップでもExcelのシートやcsvやJSONのデータを引っ張ってくると、ほぼ同様の問題に当たります。
同様のケースをC#で書いてみます。本当はこの手の問題はちゃんとクラスを定義すべきですが、Pythonではクラスを使わなかったのでC#では匿名型でやってみました。
//匿名型でマスターデータを定義
var masterEnemy = new[]
{
new {Id = 1, Name = "スライム", MaxHp = 10},
new {Id = 2, Name = "ドラキー", MaxHp = 15},
new {Id = 3, Name = "スライムベス", MaxHp = 20}
};
//匿名型を返せないのでdynamicで
Func<int[], dynamic> encount = (idlist) =>
{
//Battleのオブジェクト作成はこれだけ
var battle = idlist.Select(x => masterEnemy.Where(y => y.Id == x).FirstOrDefault())
.OrderBy(x => x.Id)
.Select(x => new { Id = x.Id, Name = x.Name, NowHp = x.MaxHp, MaxHp = x.MaxHp }).ToArray();
//Consoleに表示
foreach (var x in battle) Console.WriteLine($"{x.Name} があらわれた! HP:{x.NowHp}/{x.MaxHp}");
return battle;
};
var battleObj = encount(new int[] { 1, 3, 2, 2 });
//スライム があらわれた! HP:10/10
//ドラキー があらわれた! HP:15/15
//ドラキー があらわれた! HP:15/15
//スライムベス があらわれた! HP:20/20
なくて初めてわかるLINQのありがたみ。
追記:Pythonの場合に、encount関数をこうするともうちょっと綺麗にかけるよとコメントで教えていただきました。ありがとうございました。
def encount(id_list):
battle = [[enemy.update({"nowhp":enemy["maxhp"]}), enemy][-1]
for id in id_list
for enemy in [x for x in master_enemy if x["id"] == id][:1]] #存在しないときもOK
battle.sort(key = lambda x:x["id"])#idでソート
print("\n".join(["{0} があらわれた! HP:{1}/{2}".format(x["name"], x["nowhp"], x["maxhp"]) for x in battle]))
return battle
9.Zip関数が使いやすい
LINQ万能のように書いてしまいましたが、実はPythonのzip関数はとても直感的でわかりやすいです。次の例で考えてみましょう。これもよくありがちな例です。
pref = ["静岡県", "愛知県", "三重県", "岐阜県"]
capital = ["静岡市", "名古屋市", "津市", "岐阜市", "奈良市"]
designated = [["静岡市", "浜松市"], ["名古屋市"], []]
for p, c, d in zip(pref, capital, designated):
dstr = "なし"
if(len(d) > 0):
dstr = ", ".join(d)
print("{0} の県庁所在地は {1} 政令指定都市は {2}".format(p, c, dstr))
# 静岡県 の県庁所在地は 静岡市 政令指定都市は 静岡市, 浜松市
# 愛知県 の県庁所在地は 名古屋市 政令指定都市は 名古屋市
# 三重県 の県庁所在地は 津市 政令指定都市は なし
長さが異なるリストに対して最短のリストに合わせてループをするというケースです。リストの要素数が暫定的に同じであっても、IndexOutOfRangeを出さないために、リストの長さが等しくなるように保証してあげる必要というのがよくあります。Pythonのzip関数はとても明瞭です。並べるリストの数がいくらになろうともタプルに変換されるので問題ないです。
全く同じことをC#でやろうとするとこうなります。
var pref = new string[] { "静岡県", "愛知県", "三重県", "岐阜県" };
var capital = new string[] {"静岡市", "名古屋市", "津市", "岐阜市", "奈良市"};
var designated = new string[][] {
new string[] { "静岡市", "浜松市" },
new string[]{ "名古屋市" },
new string[]{ }
};
var query = pref.Zip(capital, (p, c) => new { Name = p, Capital = c })
.Zip(designated, (x, d) => new {
Name = x.Name, Capital = x.Capital,
Designated = d.Length > 0 ? string.Join(", ", d) : "なし" });
foreach (var pdata in query)
{
Console.WriteLine($"{pdata.Name} の県庁所在地は {pdata.Capital} 政令指定都市は {pdata.Designated}");
}
LINQのZipメソッドがごちゃごちゃしすぎて意味不明ですよね。なので以下のほうがまだわかりやすいでしょう。
foreach (var i in Enumerable.Range(0, new[] { pref.Length, capital.Length, designated.Length}.Min()))
{
var dstr = designated[i].Length > 0 ? string.Join(", ", designated[i]) : "なし";
Console.WriteLine($"{pref[i]} の県庁所在地は {capital[i]} 政令指定都市は {dstr}");
}
こうしてみるとPythonのzip関数はとても優秀です。
10.厳密なpublic/privateがない
これ見た時相当落ち込みました。確かに名前マンニングを使って先頭に__(アンダーバーを2個)引けば擬似的なプライベート変数は作れます。ただし強引にアクセスできてしまいます。なので、こんなことをされる可能性はあります。(しずかちゃんのインスタンスって何なの?という疑問はあったので、クラスメソッドにしました)
class Shizuka:
@classmethod
def school(cls, dokodemo):
print(dokodemo.user + "はどこでもドアを使った!しずかちゃんは通学中だった!")
@classmethod
def violin(cls, dokodemo):
print(dokodemo.user + "はどこでもドアを使った!しずかちゃんバイオリンの稽古中だった!")
# 公開したくないメソッド(擬似的なプライベート)
@classmethod
def __bath(cls, dokodemo):
print(dokodemo.user + "はどこでもドアを使った!しずかちゃんは入浴中だった!いやーん")
class DokodemoDoor:
def __init__(self, user):
self.user = user
# どこでもドアの使用者はのび太
nobita = DokodemoDoor("のび太")
# これは何の問題もない
Shizuka.violin(nobita)#のび太はどこでもドアを使った!しずかちゃんバイオリンの稽古中だった!
Shizuka.school(nobita)#のび太はどこでもドアを使った!しずかちゃんは通学中だった!
# こんなをことする人がいるかもしれない(非推奨)
warui_nobita = Shizuka()
warui_nobita._Shizuka__bath(nobita)#のび太はどこでもドアを使った!しずかちゃんは入浴中だった!いやーん
エンジニアののび太くんは「しずかちゃんのお風呂がのぞけない?それならインスタンス作って、._Shizuka__bath(nobita)すればいいじゃん」なんて言ってくるかもしれません。この書き方は公式ドキュメントにもある通り、非推奨です。
JavaScriptはじめprivateの概念が全く無い言語はありますが、Pythonの場合下手にprivate-likeなことができるのが悲しみを産んでいるのかなと。
こののび太くんの言い分は一理あって、派生クラスで親クラスの変数を取得するときちょっと楽できます。ただ、知らないとハマります。この場合はカプセル化と天秤にかけるとどっちがいいともいえないと思います。
class MainClass:
class SubClass:
def __init__(self):
self.__sub_text = "Sub Class"
def __init__(self):
self.__main_text = "Main Class"
self.__inner = MainClass.SubClass()
def test(self):
print(self.__main_text)
print(self.__inner._SubClass__sub_text)
class DerivedClass(MainClass):
def __init__(self):
super().__init__()#スーパークラスのコンストラクタを呼び忘れないように
self.__derived_text = "Derived Text"
def test(self):
print(self.__derived_text)
print(dir(self))
print(self._MainClass__main_text)#ここはself、スーパークラスの変数なので_MainClassで
main = MainClass()
main.test()
# Main Class
# Sub Class
derived = DerivedClass()
derived.test()
# Derived Text
# ['SubClass', '_DerivedClass__derived_text', '_MainClass__inner', '_MainClass__ma
# in_text', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__'
# , '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__',
# '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__r
# educe__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '
# __subclasshook__', '__weakref__', 'test']
# Main Class
とても重要なことですが、**コンストラクタをオーバーロードする場合、継承先でスーパークラスのコンストラクタを呼び出すのを忘れないようにしましょう。**自分はこれで数時間ハマりました。継承先でオーバーロードする場合は、これをやらないと_MainClass__main_textがないと言われます。変数名でもメソッドでもプロパティでもエラーです。dir()をのぞくと、スーパークラスのインスタンスメソッドはあるからコールはできているのに、インスタンス変数が呼び出せていないという謎の現象。継承先でコンストラクタを作らない場合は特にエラーが出ませんでした。さらに、継承先からスーパークラスのインスタンス変数なりメソッドなりを呼び出す場合は、super()ではなくselfです。ここもハマりました。
スーパークラスのインスタンス変数を呼ぶのに非推奨の書き方をやめて、プロパティやメソッドに変えてみます。幸い、Pythonにはキーワード引数という便利なものがあるので、変数の数が多くなってきた場合、セットのメソッドを一括にまとめることができます。ゲッターの場合は返り値を辞書式にすればいいと思います。
class MainClass:
class SubClass:
def __init__(self):
self.sub_text = "Sub Class"
#プロパティの場合
@property
def sub_text(self):
return self.__sub_text
@sub_text.setter
def sub_text(self, value):
self.__sub_text = value
def __init__(self):
self.set_values(main_text = "Main Class", inner = MainClass.SubClass())
def test(self):
print(self.__main_text)
print(self.__inner.sub_text)
#メソッドの場合
def get_values(self):
return {
"inner" : self.__inner,
"main_text" : self.__main_text
}
def set_values(self, **args):
self.__main_text = args.get("main_text")
self.__inner = args.get("inner")
class DerivedClass(MainClass):
def __init__(self):
super().__init__()
self.__derived_text = "Derived Text"
def test(self):
print(self.__derived_text)
print(dir(self))
print(self.get_values()["main_text"])
main = MainClass()
main.test()
# Main Class
# Sub Class
derived = DerivedClass()
derived.test()
# Derived Text
# ['SubClass', '_DerivedClass__derived_text', '_MainClass__inner', '_MainClass__ma
# in_text', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__'
# , '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__',
# '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__r
# educe__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '
# __subclasshook__', '__weakref__', 'get_values', 'set_values', 'test']
# Main Class
dir()見てると完全には隠蔽はできてなさそうですね。そういう仕様だと割り切るしかありません。
11.ジェネレーター
yieldという文字を見ると楽しくなってきますね。例えばxまでの素数を生成する関数を定義しましょう。
def prime_list(x):
for i in range(2, x):
for j in range(2, int(i**0.5)+1):
if(i % j == 0):
break
else:
yield i;
100までの双子素数を列挙します。双子素数とは2つの差が2である素数の組み合わせです。
twins = [(x, y) for y in prime_list(100) for x in prime_list(y) if y - x == 2]
print(twins)
# [(3, 5), (5, 7), (11, 13), (17, 19), (29, 31), (41, 43), (59, 61), (71, 73)]
for~elseも使えてとてもPythonらしいプログラムになりました。これは美しい。
12.デフォルトで使えるSQLite3
PHPと同じようにデフォルトでSQLite3が使えます。
import sqlite3
class Denco:
def __init__(self, **kwargs):
self.__id = kwargs.get("id", 0)
self.__name = kwargs.get("name")
self.__type = kwargs.get("type")
self.__maxap = kwargs.get("maxap", 0)
self.__maxhp = kwargs.get("maxhp", 0)
def to_tuple(self):
return (self.__id, self.__name, self.__type, self.__maxap, self.__maxhp)
dataobj = [
Denco(id = 1, name = "黄陽セリア", type = "サポーター", maxap = 260, maxhp = 348),
Denco(id = 2, name = "為栗メロ", type = "アタッカー", maxap = 310, maxhp = 300),
Denco(id = 3, name = "新阪ルナ", type = "ディフェンダー", maxap = 220, maxhp = 360)
]
con = sqlite3.connect(":memory:")#メモリに作る場合
con.execute("""CREATE TABLE denco(
id PRIMARY KEY, name, type, maxap, maxhp
)""")
con.executemany("INSERT INTO denco VALUES (?,?,?,?,?)", [x.to_tuple() for x in dataobj])
for row in con.execute("SELECT name, maxap, maxhp FROM denco WHERE id % 2 == 1 ORDER BY maxhp DESC"):
print(row)
# ('新阪ルナ', 220, 360)
# ('黄陽セリア', 260, 348)
ダブルクオーテーション3つ(""")で複数行のStringが定義できるのありがたや~。executemanyでプリペアドステートメントを一気に突っ込めるのと、SELECTをイテレーターで一気に回せるのがとても心強いです。パフォーマンスを検証していませんが、クエリ的なことをすると結構もどかしいので、面倒な処理はSQLiteにまかせてしまうというのもありかもしれない。
13.充実のrandomモジュール
randomモジュールはとても充実しているのでいろいろ遊べます。11連ガチャをするプログラムを作ってみましょう。
import random
def gacha():
rarity = ["SR", "R", "N"]
#排出率はSR=5%、R=30%、N=65%
result = random.choices(rarity, [5, 30, 65], k=11)
#射幸心を煽るフレーズ
message = "SR降臨!" if len([r for r in result if r == "SR"]) > 0 else None
if(message != None):
print(message)
print(result)
gacha_count = 0
while(True):
print("qを押すと終了、それ以外の任意のキーで11連ガチャを引きます(1回5000円)")
if(input() == "q"):
break
else:
gacha_count+=1
gacha()
print()
print("あなたはこのガチャで {0} 円使いました".format(gacha_count * 5000))
実行結果は次のようになります。
qを押すと終了、それ以外の任意のキーで11連ガチャを引きます(1回5000円)
a
['R', 'N', 'N', 'N', 'R', 'R', 'R', 'N', 'N', 'N', 'N']
qを押すと終了、それ以外の任意のキーで11連ガチャを引きます(1回5000円)
a
['N', 'R', 'N', 'R', 'N', 'N', 'N', 'N', 'N', 'N', 'N']
qを押すと終了、それ以外の任意のキーで11連ガチャを引きます(1回5000円)
a
['R', 'R', 'N', 'R', 'N', 'R', 'R', 'N', 'N', 'R', 'R']
qを押すと終了、それ以外の任意のキーで11連ガチャを引きます(1回5000円)
a
SR降臨!
['SR', 'R', 'N', 'R', 'N', 'R', 'N', 'R', 'N', 'N', 'N']
qを押すと終了、それ以外の任意のキーで11連ガチャを引きます(1回5000円)
a
['N', 'N', 'N', 'R', 'R', 'N', 'N', 'R', 'N', 'N', 'N']
qを押すと終了、それ以外の任意のキーで11連ガチャを引きます(1回5000円)
a
['R', 'N', 'N', 'N', 'N', 'N', 'N', 'N', 'R', 'N', 'N']
qを押すと終了、それ以外の任意のキーで11連ガチャを引きます(1回5000円)
q
あなたはこのガチャで 30000 円使いました
ガチャ爆死お疲れ様でした。実際こうして作ってみると生々しいですね。排出率を変えて遊べます。
当然モンテカルロ・シミュレーションもできます。円周率の近似値を求めるプログラムです。
import random
# 一様乱数を100万個
rand = [(random.uniform(0, 1), random.uniform(0, 1)) for x in range(1000000)]
# 単位円の内側なら1、外側なら0
in_circle = lambda x, y : (1 if x**2 + y**2 <= 1 else 0)
# 負の相関法で収束を速くする
in_circle_negative = lambda x, y : (1 if (1-x)**2 + (1-y)**2 <= 1 else 0)
# 合計(途中計算をリストではなくジェネレーターにすると速いらしい)
sum_rand = sum(((in_circle(*x) + in_circle_negative(*x))/2 for x in rand))
# 4倍して乱数すると円周率の近似値
pi_approx = sum_rand * 4.0 / len(rand)
print(pi_approx)
# 結果:3.14149(乱数なのでその時々で違う)
仕組みは簡単です。まず、x=0~1、y=0~1の範囲内に、半径1の1/4円(扇形)を思い浮かべます。この中にランダムに点を落としていって円の内側か外側かを判定します。円の面積の公式はπr^2ですから、1/4の円の面積はπ/4。一方で、辺の長さが1の正方形の面積は1ですから、円の内側に入った点の個数の4倍が円周率の近似値となります。詳しくはこちらを参照
結果は実行ごとに異なりますが、とりあえず小数第2位ぐらいまでは正確そうですね。
一様乱数の他にも正規乱数やベータ分布に従う乱数までも用意されている至れり尽くせりの仕様なので本当いろいろ遊べます。ここまで組み込みモジュールで用意されていて無料の言語、他にRぐらいしか知らないです。
14.Numpy事始め
実はこの円周率の近似計算、Numpyを使ってもできます。Visual Studio Installerを使ってAnaconda4.3.0をインストールしておきます。プロジェクトのPythono環境を右クリック→Python環境を追加/削除でAnacondaをPython環境に追加します。追加したら、Python環境下のAnacondaを右クリック→環境のアクティブ化を忘れずにしておきます。これしないとNumpyが読み込まれません。
Numpyの配列では配列どうしの計算ができるので、関数表記を減らすことができます。
import numpy
import time
start = time.time()
# 一様乱数を100万個
rand = numpy.random.rand(1000000, 2)
# 単位円の内側なら1、外側なら0
in_circle = numpy.sum(numpy.sum(rand * rand, axis = 1) <= 1.0) #行方向の和が1以下のものを合計
# 負の相関法で収束を速くする
in_circle_negative = numpy.sum(numpy.sum((1 - rand) * (1 - rand), axis = 1) <= 1.0)
# 4倍して乱数すると円周率の近似値
pi_approx = (in_circle + in_circle_negative) * 4.0 / len(rand) / 2.0
print(pi_approx)
elapsed = time.time() - start
print("elapsed =", elapsed)
Numpyを使った場合の書き方はPythonそのものよりもだいぶRに近い気がしました。Rもfor文やめてベクトル計算やapplyを使うと高速化できるので、Pythonもfor文やめると高速化できるかもしれない。Numpyを使わない場合(13)と比較して、経過時間は次のようになりました(それぞれ3回実行)。
Numpyを使わない場合
2.359299659729004
2.3497982025146484
2.3798024654388428Numpyを使った場合
0.12251543998718262
0.1140141487121582
0.1230156421661377
単位は秒です。Numpyを使うとざっと20倍ぐらいになります。これむちゃくちゃ速いです。ちなみに同じことをC#で書くと次のようになります。
using System;
using System.Linq;
using System.Diagnostics;
class Program
{
static void Main(string[] args)
{
var n = 1000000;
var random = new Random(Environment.TickCount);
var sw = new Stopwatch();
sw.Start();
var rand = Enumerable.Range(1, n)
.Select(x => new Tuple<double, double>(random.NextDouble(), random.NextDouble()));
var piApprox = rand.Select(x =>
(x.Item1 * x.Item1 + x.Item2 * x.Item2 <= 1 ? 1.0 : 0) +
((1 - x.Item1) * (1 - x.Item1) + (1 - x.Item2) * (1 - x.Item2) <= 1 ? 1.0 : 0))
.Sum() * 4.0 / n / 2.0;
sw.Stop();
Console.WriteLine(piApprox);
Console.WriteLine("Elapsed = {0}", sw.Elapsed);
}
}
実行速度は、次のようになりました。
00:00:00.1150376
00:00:00.1043071
00:00:00.1089778
NumpyよりC#のほうが若干速いような気がするけどまぁいいや。別にC#が最速だなんてこれっぽっちも思っていませんが、Numpy使わない場合のPythonって結構遅いんですね。
追記:大変おバカなことをしてしまったようで、Numpyの場合は**2(2乗)表記を使うべきでした。コメントで指摘してくださった方ありがとうございました。これだと余計な1-randの計算が省かれる分C#より若干速くなります。
# 単位円の内側なら1、外側なら0
in_circle = numpy.sum(numpy.sum(rand ** 2, axis = 1) <= 1.0) #行方向の和が1以下のものを合計
# 負の相関法で収束を速くする
in_circle_negative = numpy.sum(numpy.sum((1 - rand) ** 2, axis = 1) <= 1.0)
実行結果(Numpy 単位秒)
0.09600543975830078 0.09800529479980469 0.09600520133972168 0.09500575065612793 0.09380316734313965
平均:0.095764971秒
実行結果(C#)
00:00:00.0985163 00:00:00.1003610 00:00:00.0929759 00:00:00.0983167 00:00:00.0969475
平均:0.09742348秒
15.PycURL+BeautifulSoup4でスクレイピング
AnacondaのライブラリにはデフォルトでPycURLとBeautifulSoup4が入っていて、これだけでスクレイピングができます。
気象庁の積雪深から青森県の2/6現在の積雪を取得してみます。もうちょっと綺麗に書けるかもしれない。ちなみに、気象庁のデータはcsvで公開されているので、わざわざスクレイピングする意味ないです。
import pycurl
from io import BytesIO
from bs4 import BeautifulSoup
buffer = BytesIO()
# 気象庁の積雪深データ
curl = pycurl.Curl()
curl.setopt(pycurl.URL, "http://www.data.jma.go.jp/obd/stats/data/mdrr/snc_rct/alltable/snc00.html")
curl.setopt(pycurl.WRITEFUNCTION, buffer.write)
curl.perform()
# BeautifulSoup4でスクレイピング
buffer_val = buffer.getvalue()
soup = BeautifulSoup(buffer_val, "lxml")#html.parserでは失敗したのでlxmlで
def row_parser(row):
tds = row.select("td")
if(len(tds) > 10):#1行10セル以上ない行をはじく
for td in tds:
yield td.string
rows = (x for x in soup.select_one("table.data2_s").select("tr.mtx"))
cells = (list(row_parser(x)) for x in rows)
data = [r for r in cells if len(r) > 0]#空の行を弾く
# 青森県の現在の積雪深のみ絞り込み、積雪深で降順ソート
aomori = [[r[0], r[1].replace("*", ""), int(r[2])] for r in data if r[0] == "青森県"]
for a in sorted(aomori, key=lambda x:x[2], reverse=True):
print("{0}\t{1}\t{2}cm".format(*a))
結果は以下の通り。PycURLはcurlそのものなので、curl_multiを使って並行リクエストもできます。
青森県 酸ケ湯 322cm
青森県 今別 87cm
青森県 青森 62cm
青森県 碇ケ関 59cm
青森県 弘前 50cm
青森県 五所川原 49cm
青森県 むつ 42cm
青森県 脇野沢 42cm
青森県 鰺ケ沢 29cm
青森県 野辺地 28cm
青森県 大間 26cm
青森県 十和田 20cm
青森県 深浦 16cm
青森県 八戸 10cm
青森県 三戸 10cm
ちょっとしたWEBサービスぐらいなら作れそうですね。
長いエントリーになってしまいましたが、Python学習の参考になれば幸いです。C#でLINQに慣れている方なら内包表記も馴染みやすいと思いますよ。