2021年のディープラーニング論文を1人で読むAdvent Calendar19日目の記事です。今日読むのはMattingの論文で、人物の透過切り抜きの研究です。Zoomのバーチャル背景の適用がまさにその例です。
この論文かなりすごくて、HDや4Kというニューラルネットワークでは扱いづらい高解像度動画に対し、1枚のGPUでリアルタイム処理ができています。もちろん動画のMattingも想定し、デモ動画ではプラグインを作っています。CVPR2021に採択され、「Best Student Paper Honorable Mentions」を受賞しているすごい論文です。この論文、実装が若干難しい部分もありますが、コードが非常に読みやすいのでおすすめです。HDや4Kをリアルタイム処理するには、どのようなモデルを作っているでしょうか。著者はワシントン大学の方です。
- タイトル:Real-Time High-Resolution Background Matting
- URL:https://openaccess.thecvf.com/content/CVPR2021/html/Lin_Real-Time_High-Resolution_Background_Matting_CVPR_2021_paper.html
- 出典:Shanchuan Lin, Andrey Ryabtsev, Soumyadip Sengupta, Brian L. Curless, Steven M. Seitz, Ira Kemelmacher-Shlizerman; Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 8762-8771
- コード:https://github.com/PeterL1n/BackgroundMattingV2
- プロジェクトページ:https://grail.cs.washington.edu/projects/background-matting-v2/#/
まずはこちらの動画をご覧ください。デモ動画がわかりやすいのでこちらでアウトラインをつかめます。
4KのMattingをリアルタイムで行う
この研究がやろうとしているのは、Zoomのバーチャル背景などで使われる人間の前面切り抜き問題(Matting)です。バーチャル背景で下図のように少しだけ背景が残ってしまうことがありますよね。それを高精度で行い、かつ高い解像度でも実用的なFPSで動かすことに成功したのが本論文です。

髪の毛の部分を綺麗に切り抜けているのがわかりますね。精度はいいとして、速度はどんなものでしょうか。
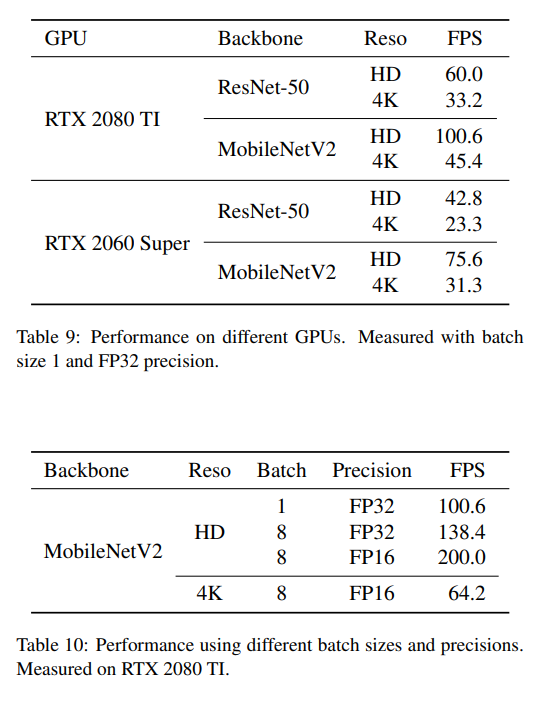
2080TiならResNet-50でHDが60.0FPS、4Kが33.2FPSだと……(やばい)
この速度はPyTorchの実装のみで、モデルコンバート等はしていないFP32での速度です。つまりもっと高速化する余地があります。Zoomでの利用想定すると動画をリアルタイムで切り抜きできるというのが要件として求められるのでしょうね。
Mattingはセグメンテーションの問題として捉えることができます。ところが、4Kをリアルタイムで動かせるセグメンテーションのモデルは自分は聞いたことありません(あったら教えて下さい)。これをどうやって技術的に可能にしたかが、本論文の面白いところです。
本論文にはColab Notebookが付属しています。静止画用、動画用
モデルのアウトライン
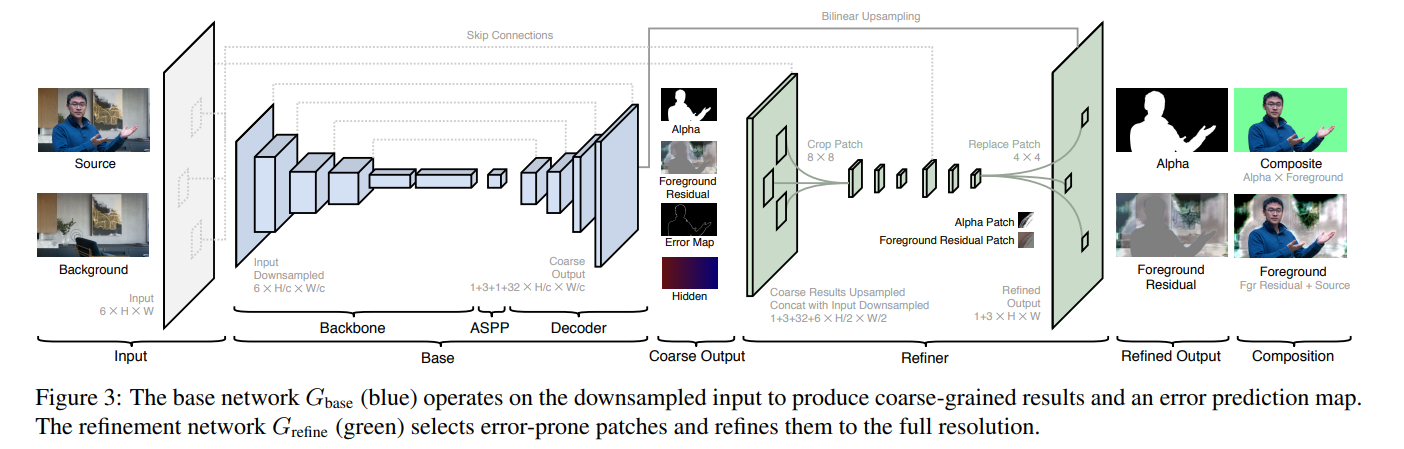
よくあるCoarse to fine構造のモデルですが、Fine側にかなり工夫があります。Coarse側は図では「Base」、Fine側は「Refiner」と表記されています。Baseで大雑把な切り抜きをしてRefinerで微調整するイメージです。
Refinerで高い解像度の画像をそのまま入出力にしてしまうと、ConvNetの性質上膨大な計算量が要求されてしまいます。HDや4KをGPU1枚ではとても30FPSは出せません。そこで、Base側でエラーマップを出力し、エラーの可能性が高い部分を重点的に切り抜きます。切り抜いたパッチをFine側で読み込み、微調整したのち戻します。エラーの可能性が高い部分のパッチのみ学習することで、HDや4Kでも現実的なFPSを出すことに成功しています。これが本論文の高速化のキモです。
Baseの入出力
細かなネットワーク構造は後ほど見ていくとして、入出力のみ見ていきましょう。Base側のネットワークの入力は2つの画像からなります。
- Source:人間が映っている画像です。Sourceの人間以外を切り抜いて出力したいのです。shapeは$(N, 3, H, W)$です。
- Background:背景の画像です。$(N, 3, H, W)$です。
これらをチャンネルの軸で組み合わせて、$(N, 6, H, W)$とします。バックボーンのネットワークでは計算量削減のために、スケール$c$でダウンサンプリングしてから入力するため、$(N, 6, H/c, W/c)$となります。出力は4個あり少しややこしいです。$c$はHDなら4、4Kなら8を使っています。
- Alpha:切り抜きに使うアルファ値です。切り抜く人間の部分を1、背景を0とします。1チャンネルの値なので、shapeは$(N, 1, H/c, W/c)$です。
- Foreground Residual:これの直感的な解釈が難しいですが、入力画像の微調整項です。Foreground Residualを$F^R$としたときに、最終的には$F=\max(\min(F^R+I, 1), 0)$を計算します。ここで$I$は入力画像です。なぜ$F$を直接推定ではなく$F^R=F-I$を学習させるのかというと、学習が向上し、アップサンプリングを通じて低解像度の残差をそのまま高解像度に適用できるからと述べています1。このshapeは$(N, 3, H/c, W/c)$でカラー画像と同じ扱いです。
- Error Map:エラーの可能性の高い部分のマップです。エラーマップ$E$の真の値$E^*$を、$E^*=|\alpha-\alpha^*|$となるようにします(実際ロスでもこれをベースにした損失関数を組み立てます)。このエラーマップはRefine側でのパッチの抽出に役立ちます。$E^*$の定義からもわかるように、1チャンネルの値でshapeは$(N, 1, H/c, W/c)$です。
- Hidden Encoding:隠れ層の特徴量を$(N, 32, H/C, W/C)$とします。これの目的はRefine側で広域なコンテクスト情報を使いたいからです。実装上はRefine側でパッチの切り出し前に、「Alpha, Foreground Residual, Hidden Encoding」をチャンネルの軸で結合しています。中間層の出力を明示的に出すというよりかは、もともとBaseとRefineのネットワークは1本で表されて、「Alpha, Foreground, Error」が分岐の中間出力(Auxially Output2)とみなすこともできます。
論文中の図にはBase側の出力チャンネル数が「1+3+1+32」とありますが、これらの4つをすべて統合した値です。
Refineの入出力
次にRefine側の入出力を見てみましょう。Refine側の入力はBaseの出力に、SourceとBackgroundをダウンサンプリングしたものを追加します。
- Alpha:Base側から。アップサンプリングし$(N, 1, H/2, W/2)$。
- Foreground Residual:Base側から。アップサンプリングし$(N, 3, H/2, W/2)$。
- Hidden Encoding:Base側から。アップサンプリングし$(N, 32, H/2, W/2)$。
- Source:入力から。解像度を半分にダウンサンプリングし、$(N, 3, H/2, W/2)$
- Background:入力から。解像度を半分にダウンサンプリングし、$(N, 3, H/2, W/2)$
Error Mapはパッチの切り出しにのみ使うので除外して考えます。これらをチャンネルの軸で結合し、$(N, 42, H/2, W/2)$で考えます。
出力は2つの項です。
- Alpha:リファインされたアルファ値です。shapeは$(N, 1, H, W)$です。
- Foreground Residual:Base側と同様ですが、リファインされた残差マップです。shapeは$(N, 3, H, W)$です。
Base同様、Foreground Residual$F^R$に対し、$F=\max(\min(F^R+I, 1), 0)$をすることでForegroundの画像を求めます。
最終的な切り抜き結果$I'$は、新しい背景(Zoomの仮想背景など)を$B'$としたとき、
$$I'=\alpha F+(1-\alpha)B'$$
で計算できます。
Baseネットワークの詳細
バックボーンはResNet-50/MovileNet V2を使っています。この後に、DeepLabV3のASPP(Atrous Spatial Pyramid Pooling)モジュールを入れています。
デコーダー側は以下の構成です。
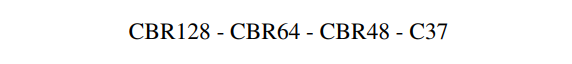
- "CBRk"は「3×3畳み込みSame padding、biasなし」→「Batch Norm」→「ReLU」を意味します
- "Ck"は「3×3畳み込みSame padding、biasあり」を意味します
デコーダーの全ての畳み込みレイヤーの前には2倍のBilinearアップサンプリングを入れ、Skip Connectionを結合します。デコーダーの出力のチャンネル数37は**「Alpha(=1), Foreground Residual(=3), ErrorMap(=1), Hidden Encoding(=32)」の合計**を意味します。Hidden Encoding以外は出力前に0~1の範囲に打ち切りします。Hidden Encodingは出力前にReLUを適用します。
Refinerのネットワークの詳細
この論文実装でかなりポイントとなるのがパッチの切り出しです。パッチの切り出しは公式コードでは物体検出のRoI Align(torchvision.ops.roi_align)を使っています。RoI Alignがなぜパッチの切り出しに使えるかは後ほど見ていきたいと思います。
先程の見たとおり、Refinerの入力は$(N, 42, H/2, W/2)$の特徴量です。ここからエラーマップを使い、1枚あたりエラーの可能性が高い$K$枚のパッチを切り出します。パッチ1枚あたりの解像度は8です。したがって、パッチ切り出し後の解像度は、
$$(N, 42, H/2, W/2)\xrightarrow{patch}(NK, 42, 8, 8)$$
となります。Refinerは2つのステージにわかれ、
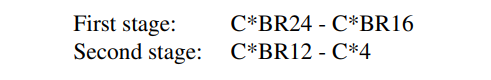
- 「C*BRk」:「3×3畳み込みValid padding、biasなし」→「Batch Norm」→「ReLU」を意味します
- 「C*k」:「3×3畳み込みValida padding、biasなし」
を意味します。Valid paddingはpaddingなしのため、3×3Conv1回ごとに縦横の解像度が2落ちます。つまり、First stageの後は、
$$(NK, 42, 8, 8)\xrightarrow{first}(NK, 16, 4, 4)$$
となります。この後にNearest Neighborで2倍のアップサンプリングをし、SourceとBackgroundについて対応するパッチを8×8で切り出し結合します。この結果6チャンネル増えるので22チャンネルとなります。
$$(NK, 16, 4, 4)\xrightarrow{upsample}(NK, 16, 8, 8)\xrightarrow{concat}(NK, 22, 8, 8)$$
この後Second stageを適用し、4チャンネルの4×4サイズのパッチを得ます。1チャンネル目はAlpha、残りの3チャンネルはForeground Residualです。Bilinear法でアップサンプリングすれば、パッチ切り出し前の8×8解像度に戻ります。これを元のAlphaとForeground Residualに戻せば良いというわけです。
$$(NK, 22, 8, 8)\xrightarrow{second}(NK, 4, 4, 4)\xrightarrow{upsample}(NK, 4, 8, 8)\xrightarrow{merge}(N, 4, H, W)$$
パッチの切り出し(RoI Align)
このモデルで問題となるのが「どうやって微分可能な形でパッチを切り出し、再度代入するか」ということです。実装上の一例はRoI Alignを使うのですが、なぜRoI Alignを使うとパッチを切り出せるのか、簡単なサンプルと公式コードをあわせて見ていきたいと思います。
RoI Alignによるサンプル
ここからTorchVisionのRoI Alignの実装をサンプルでアバウトに確認していきます。なぜRoI Alignでパッチの切り出しができるのでしょうか? ここご存知の方は飛ばしてもOKです。
画像の読み込み
import torchvision
import torch
import matplotlib.pyplot as plt
import sklearn.datasets
import numpy as np
china, flower = sklearn.datasets.load_sample_images()['images']
imgs = np.stack([china, flower], axis=0).transpose([0, 3, 1, 2])
imgs = torch.FloatTensor(imgs / 255.0)
print(imgs.shape) # torch.Size([2, 3, 427, 640])
# 並べて表示
grid_imgs = torchvision.utils.make_grid(imgs, nrow=2)
plt.imshow(grid_imgs.permute(1, 2, 0))
plt.show()
例としてsklearn.datasetsにある画像サンプルを2枚組み合わせて仮想的なバッチとしてみます。このような画像です。

RoI Alignによるパッチの切り出し
本論文のコードでも使っているtorchvision.ops.roi_alignは以下の定義です。
def roi_align(
input: Tensor,
boxes: Union[Tensor, List[Tensor]],
output_size: BroadcastingList2[int],
spatial_scale: float = 1.0,
sampling_ratio: int = -1,
aligned: bool = False,
) -> Tensor:
ここではinput, boxes, output_sizeの3つの引数が必須です。inputはそのまま画像の4階テンソルを与えるだけ、output_sizeは$(H, W)$の形で出力解像度をすれば良いです。boxesのフォーマットをどうすればいいのか個人的に悩みました。ここを検証してみます。boxesのフォーマットは$(K, 5)$とし、$K$は切り出すパッチの個数です。例えば、Bounding Boxは左上、右下の座標順で、
- 1枚目の(0, 0), (256, 256)
- 2枚目の(128, 128), (384, 384)
- 1枚目の(256, 256), (512, 288)
- 2枚目の(160, 160), (192, 416)
のようにバラバラの解像度で切り出します(RoI Alignはこのようなことが可能です)。最終的に256×256の解像度に統一して出力します。このコードは、
# 画像の読み込み
china, flower = sklearn.datasets.load_sample_images()['images']
imgs = np.stack([china, flower], axis=0).transpose([0, 3, 1, 2])
imgs = torch.FloatTensor(imgs / 255.0)
# RoI Align
# (index, x0, y0, x1, y1) : [K×5]
boxes = torch.Tensor([
[0, 0, 0, 256, 256],
[1, 128, 128, 384, 384],
[0, 256, 256, 512, 288],
[1, 160, 160, 192, 416]
])
patches = torchvision.ops.roi_align(imgs, boxes, (256, 256))
# プロット用
grid_imgs = torchvision.utils.make_grid(patches, nrow=2)
plt.imshow(grid_imgs.permute(1, 2, 0))
plt.show()
とします。ここでboxesの各パッチのフォーマットは、[index, x0, y0, x1, y1]です。左上・右下のBounding Boxの座標の他、最初に画像のバッチ内でのインデックスを指定する必要があります(このフォーマットが何を表しているのかハマった)。
パッチの切り出しでは、1枚目と2枚目が256×256、3枚目は256×32、4枚目は32×256とバラバラです。最終的には各パッチをリサイズしてoutput_sizeの256×256に統一します。
出力解像度が256×256に統一されているのがわかります。1,2枚目はただ切り出しただけです。3枚目は切り出しが256×32と横長なので、縦方向に引き伸ばされています。4枚目は切り出しが32×256と縦長なので、横方向に引き伸ばされているのがわかります。
RoI Alignについて突っ込んでみると、0.5ピクセルずらすや、バイリニア補間などあるのですが、ここでは「RoI Alignでパッチの切り出しができる」というアウトラインを理解のが目的なので割愛します。
Error Mapとのつなぎ合わせ
今のRoI AlignはBounding Boxをアドホックに与えた例でした。実際はError Mapのエラーの可能性が高いところをサンプルするという方法を取ります。エラーの可能性が高いところのインデックスを微分可能な形で取得する必要があります。これは公式実装ではtopkを使っていました。
topkとはある軸に対して降順のsort, argsortをかけるものだと思ってください。実際に簡単な例で試してみます。xをError Mapだと思ってください。
def topk():
x = torch.zeros((4, 10))
x[1,3] = 1.0
x[2,7] = 0.5
x[2,9] = 0.9
x[2,1] = 0.1
x[3,2] = 0.4
values, indices = torch.topk(x, 3, dim=-1)
print(values)
print(indices)
tensor([[0.0000, 0.0000, 0.0000],
[1.0000, 0.0000, 0.0000],
[0.9000, 0.5000, 0.1000],
[0.4000, 0.0000, 0.0000]])
tensor([[0, 1, 2],
[3, 0, 1],
[9, 7, 1],
[2, 0, 1]])
xの値にしたがって、dim=-1軸のごとの降順ソートの結果が出てきます。
コードでの実装もこのように$(N, d)$のような行列にreshapeしてからパッチを切り出すようにしています。
パッチの代入について
切り出しはRoI Alignでできましたが、Refineで修正したパッチを代入するときはどうするでしょうか。これは単にreshapeで変形して代入という形をとっています(コードではscatter_nd)と書いています。
"""
Inputs:
x: image (B, C, H, W)
y: patches (P, C, h, w)
idx: selection indices Tuple[(P,), (P,), (P,)] where the 3 values are (B, H, W) index.
Output:
image: (B, C, H, W), where patches at idx locations are replaced with y.
"""
# Use scatter_nd. Best performance for PyTorch and TorchScript. Replacing patch by patch.
x = x.view(xB, xC, xH // yH, yH, xW // yW, yW).permute(0, 2, 4, 1, 3, 5)
x[idx[0], idx[1], idx[2]] = y
x = x.permute(0, 3, 1, 4, 2, 5).view(xB, xC, xH, xW)
return x
これは実際のコードからの抜粋です。4階テンソルの画像を6階テンソルを経由して、インデックスの軸を作り、代入するという形をとっていますね。このような6階テンソルを経由するのは、Swin TransformerのPatch Partition/Mergingのようにたびたび出てくることがあります。最初は難しいのでよくわからなかったらスルーしてください。
空間的なスケールの同一性をどう保証するか
「代入するってことは、パッチの切り出し前と置き換え後で空間的なスケールが同じである必要があるよね」ということに気づきます。ここにRefine側のネットワークの工夫があります。Refine側のネットワーク図をもう一度見てみましょう(書き足しました)。
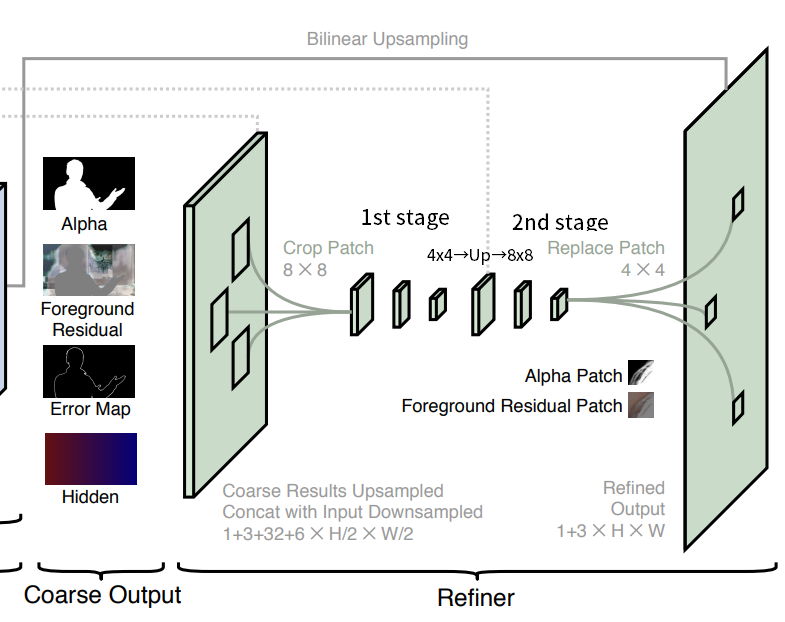
Refine側の入力は8x8で2ステージに分かれます。Refine側ではPaddingは使わないため、2つの3×3Convを通ったあとの1st stageの出力は4×4になります。それを2倍のアップサンプリングをし、元画像とのパッチを組み合わせて2nd stageの入力になります。2nd stageでもPaddingなしのConv層が2つあるため、出力が4×4になります。それをアップサンプリングし、8×8となります。つまり、パッチの切り出し前と置き換え時には解像度が同じということになります。
ただこれだけでは「いや待って。パッチの切り出し時に10×15→8×8と解像度をいじっている可能性あるよね」という疑問も残ります。パッチの切り出し側でもリサイズをしていないことを保証しないといけません。そこで公式実装のroi_alignを使っている部分を見てみましょう。
# Use roi_align. Best compatibility for ONNX.
idx = idx[0].type_as(x), idx[1].type_as(x), idx[2].type_as(x)
b = idx[0]
x1 = idx[2] * size - 0.5
y1 = idx[1] * size - 0.5
x2 = idx[2] * size + size + 2 * padding - 0.5
y2 = idx[1] * size + size + 2 * padding - 0.5
boxes = torch.stack([b, x1, y1, x2, y2], dim=1)
return torchvision.ops.roi_align(x, boxes, size + 2 * padding, sampling_ratio=1)
この論文の例では、size=4, padding=2としています。x2-x1, y2-y1がパッチの幅と高さになるため、この値が8なら空間的なスケールの同一性が保証されることになります。
パッチの幅と高さは、size + 2 * paddingになります。これは「4+2×2=8」となるため、クロップするパッチの大きさは常に8×8であることがわかります。よって、パッチのクロップと、Refineの出力・代入の部分で空間的なスケールの同一性がとれ、アラインメントがとれるように保証されている、ということが言えます。
なぜRefine側でPaddingを使っていないかという点ですが、これは論文に書いてなかったので自分の想像ですが、Paddingによる0埋め(画像では黒の挿入)が敵対的な役割を果たしてしまうからと思います。特に8×8のように小さな特徴マップでは問題になりやすいのだと思います。Paddingなしのネットワークは最近はあまり見ないのでちょっと「ん?」と首をかしげてしまいますが、理由はきちんとあると思います。
損失関数やハイパラ設定
だいぶ脱線してしまいましたが、本論文の手法に戻りましょう。損失関数はBase側のネットワークと、Refine側のネットワークで両方適用します。
訓練スキーム
Coarse to fineのモデルらしく、最初にBase側を訓練し収束後、次にBase+Refineで同時に訓練という方法をとっています。Base側とRefine側でそれぞれロスを持つことになります。なお、訓練リソースは相当良心的で、
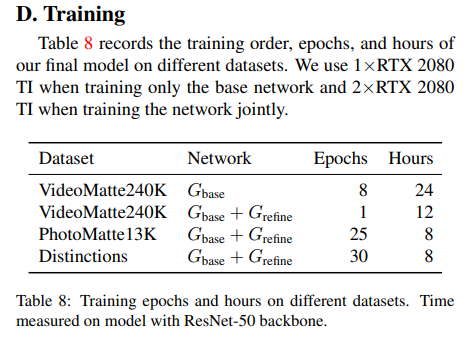
Base側の訓練時は2080Tiが1枚、同時訓練時は2080Tiを2枚にしています。VideoMatte240Kという(見るからに大規模そうな)データセットに対しても、Base側が1日、Refine側が半日でした。同時訓練時にもGradient Accumulation等を使えばGPU1枚でも頑張れそうです。バッチサイズはBaseのみが8、同時の場合は4としています。
各損失関数
Base側にもRefine側にも共通する損失関数の項を導入します。「Alpha, Foreground Residual, Error Map」の3つに対して損失関数を作ります。
\mathcal{L}_\alpha=\|\alpha-\alpha^*\|_1+\|\nabla\alpha-\nabla\alpha^*\|_1
これはAlpha(アルファ値)に対する損失関数です。$a^*$は真の値です。$\nabla$は微分を示しますが実際に微分を計算する必要はなく、Sobelフィルターを適用した後の値を求めます。これが実質的な微分の役割を果たします。
\mathcal{L}_F=\|(\alpha^* >0)*(F-F^*)\|_1 \\ F=\max(\min(F^R+I, 1), 0)
Foreground Residualはmin-maxをとって$F$に変換したあと、切り抜き対象のエリアのみL1で評価します。
\mathcal{L}_E=\|E-E^*\|_2 \\ E^*=|\alpha-\alpha^*|
次のError MapはBase側のみ使います。$E$はネットワークの出力からダイレクトに求められます。真の値$E^*$は出力の$\alpha$と真の値$\alpha^*$の差の絶対値を取ったものになっています。「差の差」を考慮し、直感的には2階微分の近似計算のようなことをやっているが、計算量が増えないようにうまく工夫している損失関数やモデル構造だなという印象を持ちました。
| Base | Refine | |
|---|---|---|
| $\mathcal{L}_\alpha$ | ○ | ○ |
| $\mathcal{L}_F$ | ○ | ○ |
| $\mathcal{L}_E$ | ○ | ☓ |
BaseとRefine側の損失関数は表の通り。係数のハイパラはなくただ足すだけです。ハイパラかわりにネットワークのモジュール単位で学習率を変えています。
モジュール単位で学習率を変える?
損失関数で係数のハイパラをおかない代わりに、モジュール単位で学習率を変えています。
| Base訓練時 | 同時訓練時 | |
|---|---|---|
| Base:バックボーン | 1e-4 | 5e-5 |
| Base:ASPP | 5e-4 | 5e-5 |
| Base:デコーダー | 5e-4 | 1e-4 |
| Refine全体 | - | 3e-4 |
こういうやり方出してきた論文は初めてなので、コードでどうしているか見てみました。PyTorchなら簡単に実装できるそうです。
optimizer = Adam([
{'params': model.backbone.parameters(), 'lr': 1e-4},
{'params': model.aspp.parameters(), 'lr': 5e-4},
{'params': model.decoder.parameters(), 'lr': 5e-4}
])
影を人工的に作るAugmentation
一般的な画像のAugmentationの他に、影を人工的に作るということが重要になってきます。論文では「Shadow Augmentation」と呼んでいます。

上段がShadow Augmentationがない例、下段がある例です。現実世界では影が問題になってくるので、それをどう対応するかがキーのようです。
データセットをどうするか
そもそもHDや4Kに対応できるデータセットがなく、ある程度データセットを構築してから実験しています。この苦労話も書かれています。
公開データセット:Adobe Image MattingとDistinctions646
本論文では公開データセットとして「Adobe Image Matting」と「Distinctions646」の2つを紹介しています。
- Adobe Image Matting:269の訓練データ、11のテストデータ。全て人間がいる訓練画像。平均1000×1000の解像度。
- Distinctions646:この中の人間だけのサブセットを使い、362の訓練データ、11のテストデータ。。平均1700×2000の解像度。
これらの2つは手作業でMattingのラベルが作られており、高品質なラベルですが。合計631枚の訓練画像だけでは人間の多彩なポーズと、精密なディテールを捉えるには足りなかったことが報告されています。結局別に2つのデータセットを作っています。
VideoMatte-240K
グリーンバックの高解像度の動画を484本集めることから始めています。これらはロイヤリティーフリーの素材、購入したものが含まれています。うち384本は4Kで、100本がHDです。
これらの動画に対し、Adobe After Effectsを使用し、前景とアルファ値を切り出します。合計240,709フレームを取得しています。484本の動画のうち、479本を訓練、5本をValidationとしています。
動画からデータセットを構築したことにより、前後のフレームの情報がとれるため、今後の研究で動きを取り入れたモデルを開発できるようになったとのことです。
PhotoMatte13K/85
スタジオ品質の照明とカメラでグリーンスクリーンの前で撮影された13665枚の画像をベースに、クロマキーアルゴリズムで抽出したマット画像と、手動によるチューニングやエラーの修正をしました。13165:500の割合で訓練とValidationで分割しています。平均2000×2500程度の高解像度ですが、プライバシーとライセンスの関係からこのデータセットは公開できないとのことです。そのかわりに同品質の画像を85枚収集し、マットのラベルをつけてPhotoMatte85として公開しています。

具体例としてはこんな感じです。
定量評価
先行研究のFBAには若干劣るかもしれないが、4Kへの拡張や速度で圧倒的に優位
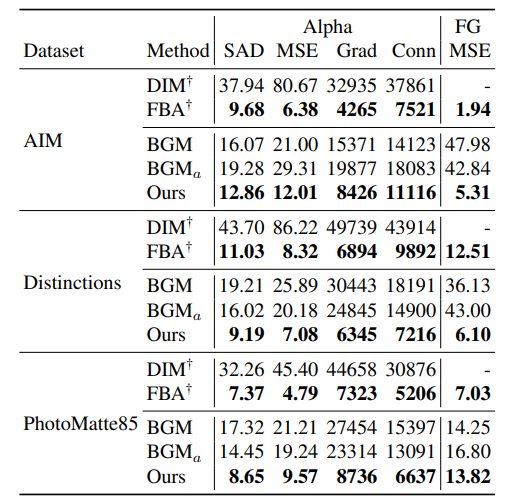
先行研究との定量評価です。FBAがこれまでのSoTAですが、メモリの制約でHD以上の拡張ができません。またFBAはHDで3FPS前後とリアルタイムからは程遠いです。ところがこの研究は4Kまで1枚のGPUでリアルタイム推論できます。
個人的にはこの定量評価あまり良くないと思います。なぜかというと、先行研究は低解像度での推論しか対応しておらず、この手法は低解像度も高解像度も両方いけるモデルなので低い方にあわせて評価してしまうからです。自分個人の意見では、単純な定量評価ではモデル本来の性能を比較評価することができず、この表は参考程度と思ったほうがいいでしょう。MSEはアルファ値と前景、SADはアルファ値の絶対値の差の和、Gradはアルファ値の空間的な勾配値、Connはアルファ値の接続性(謎指標)を表します。
むしろ大事になってくるのが定性的な評価で、透過切り抜きの精度は髪の毛の部分で差が出やすいです。

FBAもOursも髪の毛がかなりいい感じになっています。ただ、FBAは手動でトリムマップを生成できない(FBA auto)のケースでは若干悪くなっています。FBAの論文を読んだことがないので「手動でトリムマップを生成できない」というケースがどういうものなのか不明ですが、もしかしたらトリムマップが与えられているかどうかなど問題設定そのものが違うのかもしれません。
定量評価として意味があると思われるのは、速度の比較です。
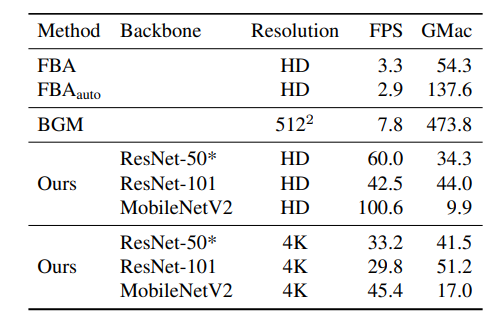
ぶっちぎりで速いですし、HD→4Kに拡張してもリアルタイムが不可能なレベルまでFPSが落ちてはいません。この理由は単純明快で、Refineのネットワークをパッチベースにして計算量を抑え込んでいるからです。この計測は2080Tiでおこない、PyTorchのモデルのままONNX等に変換せず、FP32での推論です。このへんを頑張ればもう少しスペックの悪いGPUでもリアルタイム追いつくと思います。
高解像度に対応できる良質なデータセットが重要
Ablation Studiesとしてデータセットを変えたときの性能の変化が報告されていました(これを報告してくる論文はあまりみたことないです)。
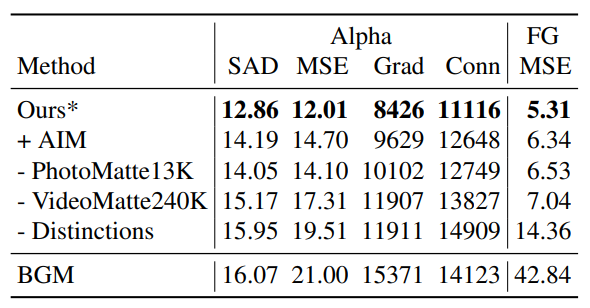
Oursから、1000×1000の解像度のデータであるAIM(Adobe Image Matting)を追加しただけで性能が悪化します。一方で、HD以上の高解像度なデータであるDistinctions646やPhotoMatte13KやVideoMatte240Kは抜くと性能が悪化します。全部を抜くと先行研究のBGM並に性能が悪化します。
つまり、モデル構造はもちろんだが、「高解像度の問題を解きたければ高解像度のデータがいかに重要か」という当たり前ながら大事なことを示していると言えます。個人的にはVideoMatte240Kが一番効いているように思えますが、ここのゲインが大きいので多分そうだと思います。データの調達もVideoMatte240Kのやり方が一番楽そうです。
パッチベースのRefineは解像度のスケールがしやすい
解像度を変えたときの出力結果です。480×270→HD→4Kと解像度をスケールさせても、髪の毛の付近が変にぼやけたりしないですよね。これがRefineのパッチの解像度が一定である恩恵ではないかと考えられます。
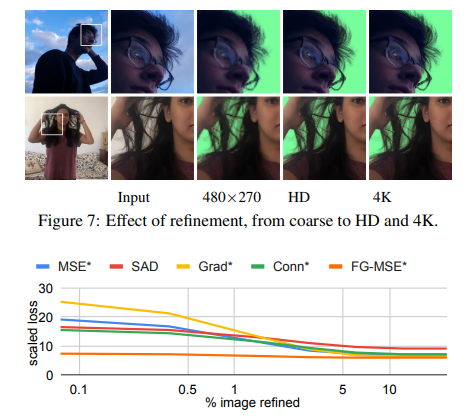
また、Refineのパッチでの修正割合と各種定量指標の関係です。5~10%やれば性能改善は頭打ちになっているのがわかります。画像全体をRefineに通す必要はなく、パッチベースのように必要な場所だけ通せばいいよということを実験ベースで正当化できていると言えるでしょう。もちろんこれは推論のスピードアップに相当寄与します。
失敗例
このモデルの失敗例には次のようなものがあります。

上は影があるケース。おそらく服の色と影の部分が見分けできないのでしょうね。Shadow Augmentationを導入しているのはこういう背景があるからです。
ただ、同様の影の問題はクロマキー合成でもあり、グリーンバックで撮影する際に影ができないよう、スクリーン全体に照明を当てるなど照明管理する必要があるとのことです。照明管理を素人が適当にやったケースだと、単なるクロマキー合成よりも本論文の手法が良かったことが報告されています。私見ですが、クロマキー合成の場合は、人間がキー色の服を持っているとそこだけ抜けちゃいますからね。「グリーンバックの照明管理が適当でもこの方法を使えばいいよね」というように応用例も検討されています。
下は失敗例その2で、背景のテクスチャが複雑なケース。これはどんな手法使っても難しいのではないかと思います。個人的にはよくこれだけ難しい設定で、これだけ切り出せたなというイメージが強いです。
まとめと感想
本論文では、Zoomのバーチャル背景による問題提起に始まり、一般的な画像・動画処理として需要の高い「人物の切り抜き(Matting)」をニューラルネットワークベースで解決しています。本手法の大きなポイントとして、GPU1枚でもHDや4Kにスケールできるようにし、なおかつ鮮明さを失わないという強い結果を出せている点です。それを支えるモデルのアーキテクチャは「Refine側をパッチベースにする」という比較的単純な発想(実装は若干ややこしいですが)で、「なるほどこうやるのか」と唸らされました。これはCVPRで賞をとって当然の論文だと思います。
Coarse to fineのモデル構造はImage to image translationの論文だとよく見るので、Mattingでこれだけ結果を残した手法なので、今後派生ジャンルへと応用されていってもおかしくはないと思います。HDや4Kでリアルタイムなセマンティックセグメンテーションができそうなので、これはかなりインパクト強そうです。
個人的に、キャラに3Dモデルを作ったときにMatting問題が必要になり、クロマキー合成の失敗例にかなり悩まされた経験があります。単なるバーチャル背景への応用例だけでなく、もっと応用範囲が広そうな研究だなと思いました。動画によるプレゼンがうまく、また公式コードが非常に読みやすい(こことても重要)なのがとても良かったです。気になった方はコード読んでみてください。
実はこの論文更新されてた
Twitterで捕捉いただいたのですが、同一著者が2021年8月に論文出していて「1080Tiで4K 70FPS+ and HD 100FPS+」まで向上するのに成功しています。頭おかしい(褒め言葉)
告知
このアドベントカレンダーが本になりました!
https://koshian2.booth.pm/items/3595424
Amazonでも扱いあります詳しくは👉 https://shikoan.com