最近になって論文でたびたび目にする学習率のWarmupについて、CIFAR-10で実験してみました。その結果、Warmupを使うとバッチサイズの増加にともなう精度の急落を、ある程度緩和できることがわかりました。大きいバッチサイズで訓練したり、訓練を高速化したい場合は、このWarmupが非常に有効となるでしょう。
きっかけ
Google I/O'19の講演を聞いていたら、学習率のウォームアップについて話していました。RetinaNetをTPUで訓練する話です。
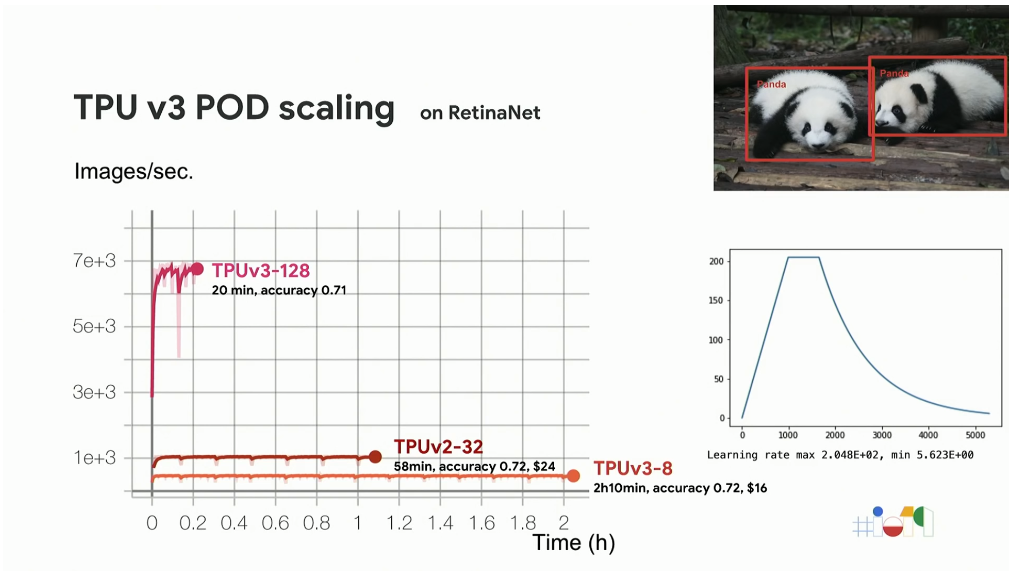
曰く、「このケースではResNet50の訓練済みモデルを初期値として使い、レイヤーを固定せず、全てのレイヤーを訓練させる。大きいバッチサイズを使っているので、訓練済み係数が壊れてしまう可能性がある。学習の最初は低い学習率を使い、徐々にあげていくという学習率のコントロールを行う」(ビデオ39分付近)とのことです。
学習率のWarmup
このアイディアはこの講演オリジナルではなく、論文ではWarmupと言われる手法です。
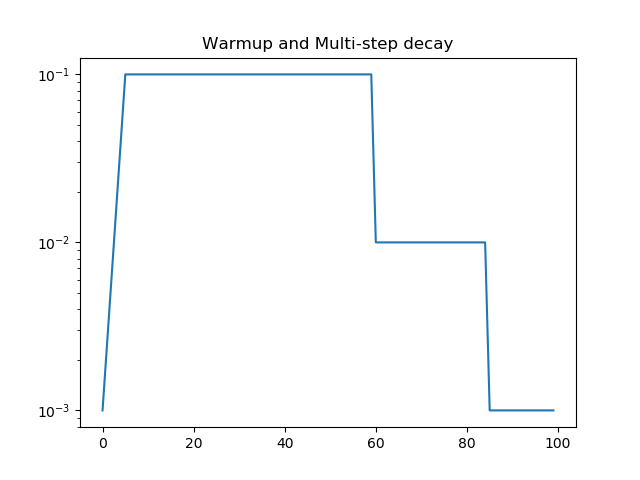
図はイメージなので、必ずしもこれが唯一の正解というわけではありません。後半の階段状のは、普通のMulti-step decayですが、前半の学習率が上がっているのがWarmupにあたります。Warmupはこの図ではlogスケールの直線ですが、線形でもlogスケールでもどっちでもいいと思います(多分)。
Fine-tuningでは係数を壊さないようにWarmupを使う、というのは直感的にはわかりやすい話です。また、fine-tuningでなくても、MomentumやAdamといった移動平均を使うオプティマイザーなら、移動平均を取るための勾配の蓄積が足りないと(ここらへんの議論は[1]参照)、学習の初期段階において値の信頼度が低い(よって変な値が出て精度を損ねる)ということも考えられます。
Warmup単独について分析した記事は探したところなかったので、今回は、この学習率のWarmupに焦点を当ててCIFAR-10で精度がどのように変わるのかを分析してみます。
ImageNetの高速化でも使われるWarmup
さて、いくつかImageNetの訓練の高速化の研究を読んでいると、その中で学習率のWarmupが使われているのがわかります。
一例としては、ソニーのImageNetを224秒で訓練したという論文です[2]。以下のような式の学習率スケジューリングが使われています。「if epoch<5」のところがWarmupですね。

また、今年2019年に出た、富士通のImageNetを74.7秒で訓練したという論文でもこのWarmupは使われています。富士通の論文は他にもいろいろ工夫があるので、Warmupはあくまでその中の1つという位置づけです。
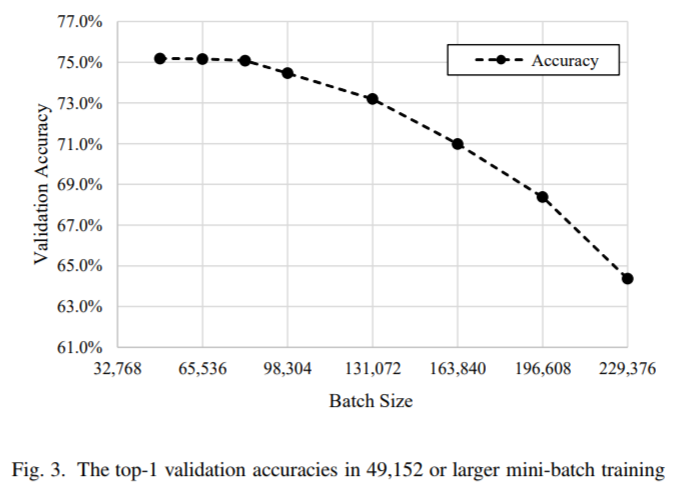
この図は富士通の論文からです。バッチサイズを大きくすることは訓練の高速化への大きな要因ですが、いくらハードウェア要件をクリアしても、バッチサイズを際限なく大きくすることはできないと一般に考えられています。ある大きさのバッチサイズから、急に精度が落ち始める(この図ではバッチサイズ10万以降)のが確認されています。
ここからがポイントなのですが、富士通の論文を読んだときに「精度が落ち始めるバッチサイズの値がずいぶん高いな」と思ったのです。少し昔の論文を出しましょう。Facebookが2017年に出した、ImageNetを1時間で訓練する論文[4]です。
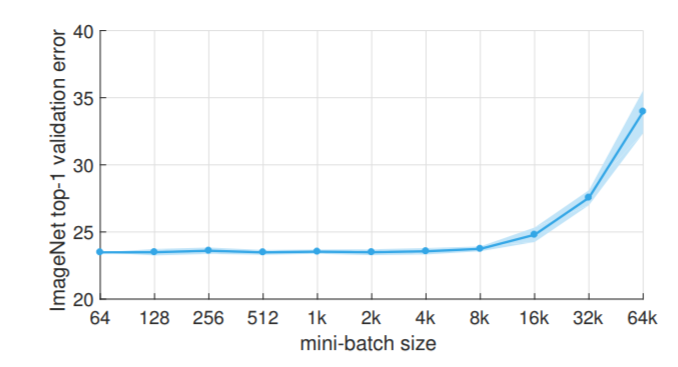
Facebookの論文だと、バッチサイズ1.6万ぐらいから落ち始めているのに、富士通の論文だとそれを10万ぐらいまで遅らせられるというわけです。つまり、精度が急に落ち始めるラインを遅らせる技術というのが存在するということになります。これを考えることが、精度を維持しつつ訓練を高速化する上で重要なのです。
ちなみに、Facebookの論文[4]はWarmupの走りとなったもので、Warmupについてかなり詳細に議論されています。上の図もWarmupを入れた上での精度だそうです。ただ、自分が知りたかったのは「Warmup単体でこのバッチサイズー精度のグラフがどれだけ右に寄るか」、つまりWarmupはどれだけ精度の急落を遅らせるのに効いているのかだったので、これをCIFAR-10で調べてみることにしました。
Warmupの実装
以下のように実装しました。CIFARでも最大で8192のバッチサイズで訓練するのでGoogle ColabのTPUを使います(GPUだと3~4枚ぐらい必要だと思います)。全体のコードは末尾に載せるのでそちらを参照してください。
def wrap_scheduler(initial_lr, use_warm_up):
def lr_scheduler(epoch):
if use_warm_up and epoch <= 5:
return 10**(-2.0+0.4*epoch)*initial_lr
x = initial_lr
if epoch >= 60: x /= 10.0
if epoch >= 85: x /= 10.0
return x
return lr_scheduler
Warmupを使う場合(use_warm_up=True)は、logスケールで直線的にバッチサイズを上げるようにしてみました。Multistep-decayが対数スケールなので、Warmupもそれに合わせるのが自然かなということで。
実験
- 10層のCNNを使ってCIFAR-10の分類
- バッチサイズ128=初期学習率0.1とし、初期学習率はバッチサイズに比例させる。例えば、バッチサイズ1024なら、初期学習率0.8。この学習率のスケーリングは[1][4]などで使われている。
- Starndard Data Augmentation(上下左右4ピクセルのクロップ、左右反転)を入れる
- 各ケース1回ずつ試行
結果
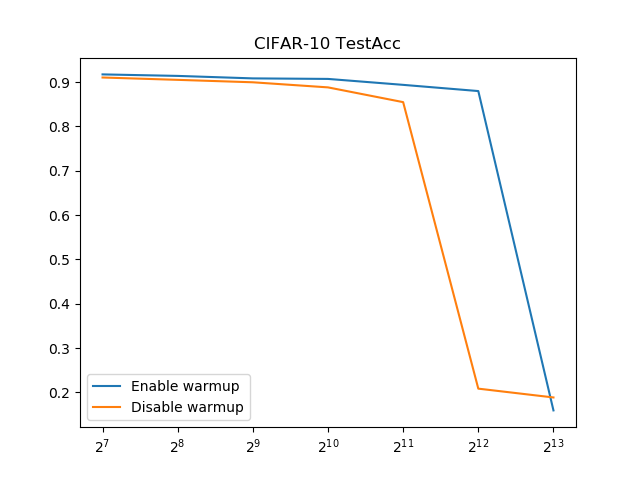
とてもわかりやすい結果になりました。Warmupは精度の急落を遅らせるのに純粋に効果がある。
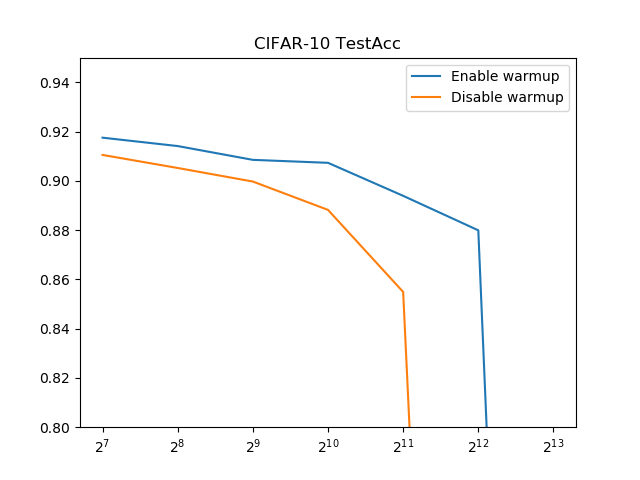
Warmupなしの場合、バッチサイズ1024(=2^10)で既にもう厳しいのに、Warmupありにするとバッチサイズ4096(=2^12)まで持ちこたえられました。
| Batch / Warmup | あり | なし |
|---|---|---|
| 128 | 0.9175 | 0.9105 |
| 256 | 0.9141 | 0.9052 |
| 512 | 0.9085 | 0.8997 |
| 1024 | 0.9073 | 0.8882 |
| 2048 | 0.8939 | 0.8549 |
| 4096 | 0.8799 | 0.2083 |
| 8192 | 0.1592 | 0.1884 |
同一バッチサイズでもWarmupのほうが若干(1%程度)精度が上がりました。純粋に精度向上にも寄与しそうです。
この理由はなぜかというと、素人なりに考えてみたのですが、FP16で訓練する際に学習の初期の段階で特に勾配爆発を起こして損失関数がNanになることがあるというのと似ていると思います。学習の一番最初は、全てのレイヤーがまっさらな状態なので、強い勾配が伝わりやすいです。つまり、FP16のような範囲の狭い変数だと簡単にオーバー/アンダーフローを起こしやすい、Nanが出るのはそのような強い勾配が伝わっているという裏付けでしょう。また、Momentumの蓄積がない状態で強い勾配が伝われば、必ずしも正確な勾配が伝わるとも限りません。ノイズが多く強い勾配を最初に伝えてしまうと、ニューラルネットワークが悪い局所解にとらわれてしまうのではないか、だから最初は学習率を低くして徐々に上げるという方法が有効、というのがそれっぽい理由ではないでしょうか。もしかしたら、FP16での訓練でもWarmup入れると有効かもしれません。
まとめ
「大きいバッチサイズでする際に、学習率のWarmupを入れると、バッチサイズの増加に伴う精度の急落を緩和できる。精度にも寄与しそう。」ということでした。ぜひ使ってみてください。
コード
詳細クリックでコードを表示
import tensorflow as tf
import tensorflow.keras as keras
import tensorflow.keras.layers as layers
import numpy as np
import os
import pickle
from tensorflow.contrib.tpu.python.tpu import keras_support
def create_block(input, ch, reps):
x = input
for i in range(reps):
x = layers.Conv2D(ch, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
return x
def create_model():
input = layers.Input((32,32,3))
x = create_block(input, 64, 3)
x = layers.AveragePooling2D(2)(x)
x = create_block(x, 128, 3)
x = layers.AveragePooling2D(2)(x)
x = create_block(x, 256, 3)
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dense(10, activation="softmax")(x)
return keras.models.Model(input, x)
def wrap_scheduler(initial_lr, use_warm_up):
def lr_scheduler(epoch):
if use_warm_up and epoch <= 5:
return 10**(-2.0+0.4*epoch)*initial_lr
x = initial_lr
if epoch >= 60: x /= 10.0
if epoch >= 85: x /= 10.0
return x
return lr_scheduler
def train(batch_size, use_warm_up):
tf.logging.set_verbosity(tf.logging.FATAL)
(X_train, y_train), (X_test, y_test) = keras.datasets.cifar10.load_data()
y_train = keras.utils.to_categorical(y_train)
y_test = keras.utils.to_categorical(y_test)
train_gen = keras.preprocessing.image.ImageDataGenerator(
rescale=1.0/255.0,
width_shift_range=4.0/32.0,
height_shift_range=4.0/32.0
).flow(X_train, y_train, batch_size=batch_size, shuffle=True)
val_gen = keras.preprocessing.image.ImageDataGenerator(
rescale=1.0/255.0
).flow(X_test, y_test, batch_size=1000, shuffle=False)
initial_lr = 0.1 * batch_size / 128
scheduler = keras.callbacks.LearningRateScheduler(wrap_scheduler(initial_lr, use_warm_up))
hist = keras.callbacks.History()
model = create_model()
model.compile(keras.optimizers.SGD(initial_lr, 0.9), "categorical_crossentropy", ["acc"])
tpu_grpc_url = "grpc://"+os.environ["COLAB_TPU_ADDR"]
tpu_cluster_resolver = tf.contrib.cluster_resolver.TPUClusterResolver(tpu_grpc_url)
strategy = keras_support.TPUDistributionStrategy(tpu_cluster_resolver)
model = tf.contrib.tpu.keras_to_tpu_model(model, strategy=strategy)
model.fit_generator(train_gen, steps_per_epoch=X_train.shape[0]//batch_size,
validation_data=val_gen, validation_steps=X_test.shape[0]//1000,
callbacks=[scheduler, hist], epochs=100, verbose=0, max_queue_size=3)
return hist.history
def train_all(use_warm_up):
result = {}
for batch_size in [128,256,512,1024,2048,4096,8192]:
print(batch_size, "Starts")
result[batch_size] = train(batch_size, use_warm_up)
with open(f"warmup_{use_warm_up}.pkl", "wb") as fp:
pickle.dump(result, fp)
if __name__ == "__main__":
train_all(True)
参考文献
[1]: S. L. Smith, P.-J. Kindermans, C. Ying, Q. V. Le. Don't Decay the Learning Rate, Increase the Batch Size. ICLR. 2018.
https://arxiv.org/abs/1711.00489
[2]: H. Mikami, H. Suganuma, P. U-chupala, Y. Tanaka, Y. Kageyama. ImageNet/ResNet-50 Training in 224 Seconds. arXiv:1811.05233. 2018
https://nnabla.org/paper/imagenet_in_224sec.pdf
[3]: M. Yamazaki, A. Kasagi, A. Tabuchi, T. Honda, M. Miwa, N. Fukumoto, T. Tabaru, A. Ike, K. Nakashima. Yet Another Accelerated SGD: ResNet-50 Training on ImageNet in 74.7 seconds. arXiv:1903.12650. 2019
https://arxiv.org/abs/1903.12650
[4]: P. Goyal, P. Dollár, R. Girshick, P. Noordhuis, L. Wesolowski, A. Kyrola, A. Tulloch, Y. Jia, K. He. Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour. arXiv:1706.02677. 2017
https://arxiv.org/abs/1706.02677
続き
WarmupとData Augmentationのバッチサイズ別の精度低下について
https://blog.shikoan.com/warmup-data-augmentation-compare/
お知らせ
技術書典6で頒布したモザイク本の通販を下記URLで行っています。会場にこられなかったけど欲しいという方は、ぜひご利用ください。
『DeepCreamPyで学ぶモザイク除去』通販
https://note.mu/koshian2/n/naa60d5c9ebba
ディープラーニングや機械学習における画像処理の基本や応用を学びながら、モザイク除去技術DeepCreamPyを使いこなし、自分で実装するまでを目指す解説書です(TPUの実装中心に書いています)。