PyTorch+Google ColabでVariational Auto Encoderをやってみました。MNIST, Fashion-MNIST, CIFAR-10, STL10の画像を処理しました。また、Variationalではなく、ピュアなAuto EncoderをData Augmentationを使ってやってみましたが、これはあまりうまく行きませんでした。
データとネットワーク構成について
MNIST, Fashion-MNIST, CIFAR-10, STL10は以下の通りです。
MNIST

Fashion-MNIST

CIFAR-10

STL-10

STL-10は馴染みが薄いかもしれませんが、スタンフォード大学が公開している教師なし学習向けのCIFARに似たなデータセットです。ただし解像度が大きく、CIFARが32x32であるのに対して、STLは96x96です。
ネットワーク構成は以下の通りです。CNNによるVAEを作ります。1x1畳み込みから構成されるボトルネック層が1層、3x3畳み込みの層が3層、計4層のエンコーダーです。ダウンサンプリングはPoolingではなくConv2dのstrideを使っています。
| エンコーダー | チェンネル数 | カーネル | MNIST/Fashion | CIFAR-10 | STL-10 |
|---|---|---|---|---|---|
| ボトルネック | 32 | 1 | 28x28 | 32x32 | 96x96 |
| 1層目 | 64 | 3 | 28x28 | 32x32 | 96x96 |
| 2層目 | 128 | 3 | 14x14 | 8x8 | 24x24 |
| 3層目 | 256 | 3 | 7x7 | 4x4 | 6x6 |
ちなみにデコーダー側はこうなります。ConvTranspose2dでkernel_size=strideとしてアップサンプリングしました。ボトルネックの最後にはシグモイド活性化関数をつけています。
| デコーダー | チェンネル数 | カーネル | MNIST/Fashion | CIFAR-10 | STL-10 |
|---|---|---|---|---|---|
| 3層目 | 128 | stride | 7x7 | 4x4 | 6x6 |
| 2層目 | 64 | stride | 14x14 | 8x8 | 24x24 |
| 1層目 | 32 | stride | 28x28 | 32x32 | 96x96 |
| ボトルネック | 3 | 1 | 28x28 | 32x32 | 96x96 |
また中間層は以下のようになります。
| 中間層 | チャンネル数 |
|---|---|
| エンコーダー出力 | 128×データごとの解像度 |
| μ | 64 |
| σ | 64 |
| デコーダー入力 | 128×データごとの解像度 |
潜在変数は64個で表現しました。平均(μ)と対数分散(σ)は活性化関数なしの線形活性化関数です。コード全体はこちらになります。
コード:https://gist.github.com/koshian2/64e92842bec58749826637e3860f11fa
また本実装はPyTorchのVAEの例、CNNのVAEのPyTorchの例を参考にしました。各リポジトリは以下の通りです。
理論的な話
自分が説明するより詳しい説明がネットにいっぱいあるので、そちらを参照してください。直感的な説明ならKerasのブログがわかりやすいです。
Building Autoencoders in Keras
https://blog.keras.io/building-autoencoders-in-keras.html
日本語の資料ならこちらもおすすめです。
猫でも分かるVariational AutoEncoder
https://www.slideshare.net/ssusere55c63/variational-autoencoder-64515581
数式的な証明はこちらがわかりやすいです。自分は半分ぐらいしか理解できませんでしたが、ベイズの定理から始まり、潜在変数と入力データの同時確率を求めるというベイズ統計のアプローチをディープラーニングで用いるという手法です。VAEの場合は、潜在変数が標準正規分布に従うという仮定をおく(標準正規分布になるように最適化する)ことで、reparametrization trickを閉じた式で表現できるようになっています。難しいですが、非常に美しい理論展開です。
Variational Autoencoder: Intuition and Implementation
https://wiseodd.github.io/techblog/2016/12/10/variational-autoencoder/
結果
結果は以下の通りです。
各データセットにつき、1枚目の画像はテストデータをエンコーダーの入力に入れたときのデコーダー側の出力(reconstruction)、2枚目の画像は正規乱数をデコーダーの入力に通したランダムサンプリング(sampling)です。reconstruction, samplingともに最終エポックのものを表示しています。3枚目はオリジナルです(再掲)。
STL以外は200エポック、STLはデータ数が多いので処理時間の関係上100エポック訓練させました。
MNIST
reconstruction

sampling

かなり上手くいっています。MNISTは簡単なデータセットなので。
ground truth
Fashion-MNIST
reconstruction

sampling

Fashion-MNISTはMNISTより若干難しいデータセットです。輪郭のボケは見えるものの、だいたい上手くいっているように見えます。
ground truth
CIFAR-10
reconstruction

sampling

カラー画像になるとかなり厳しい印象を受けます。ネットワークをもっと深くすれば生成性能は上がるかもしれませんが、reconstructionでも相当ボケていますし、samplingはもっとひどくて雰囲気はわかるもののピンぼけが厳しいですね。
ground truth
STL-10
STL-10のデータ構成はtrain, testだけでなく、unlabled(ラベル付されていない)データがあります。trainが5000件、testが8000件、unlabledが10万件用意されているので、unlabledで訓練させtestで再現画像を生成させました。
reconstruction

sampling

正直ひどいですね。samplingなんかGANの失敗画像みたいな感じになっています。解像度が大きくなるとVAE特有のピンぼけさが目立つようになります。
ground truth
学習経過
VAEのエラーはBinary Cross Entropy+KL Divergenceなので、この評価方法はひょっとしたら正しくないかもしれませんが、画像1枚あたりのエラーを画像の(ピクセル数×カラーチャンネル数)で割った値をプロットしてみます。カラーチャンネル数はモノクロなら1、カラーなら3です。
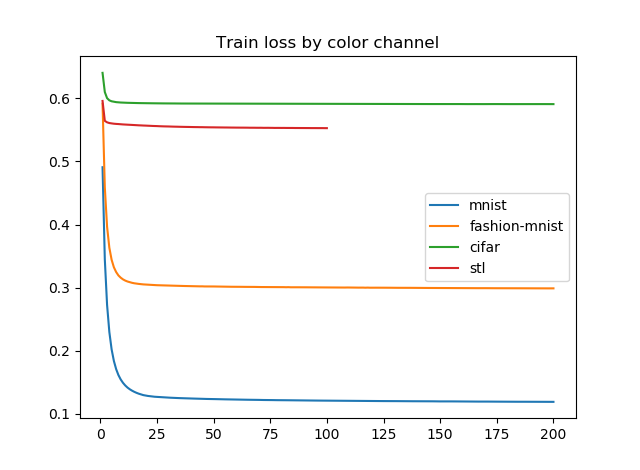
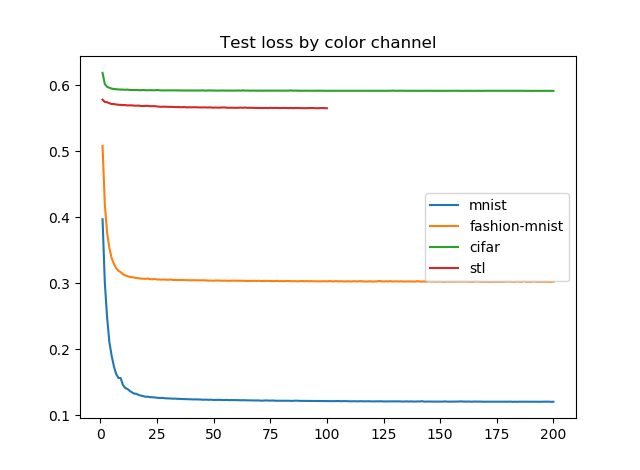
やはり生成された画像を見たとおり、カラー画像に対するエラー推移があまりよろしくないです。STLのテストなんてほとんど学習が進んでいません。
プレーンなAuto Encoder+Data Augmentationの模索
VAEがプレーンなAuto Encoderに比べて良い点は、潜在変数を標準正規分布と仮定することで、空間がスカスカにならないことです。ただその一方で、そのパラメトリックな仮定が悪さをしているのか、あるいはモデルの深さが足りないこととの相互作用なのか、解像度が高い画像に対してはぼやけるという欠点があります。
スカスカにならないのなら、例えばShake-Shakeのようなネットワークの中でData Augmentationを行ってプレーンなAuto Encoderに食わせたらどうだろう?と思ってやってみました。結果はダメでした。他にもShake-Shakeではなく、MixupのようなData Augmentationを行っても似たような失敗例になりました。
コードはこちらにあります。
https://gist.github.com/koshian2/2098e2261d673c818f6bdc51fa485e86
なお、Shake-Shakeの実装はこちらのリポジトリを使わせていただきました。
https://github.com/hysts/pytorch_shake_shake/blob/master/functions/shake_shake_function.py
ポイントだけかいつまんでいうと、
- エンコーダー・デコーダーともに1層あたり畳み込みを2つ作り、それをShake-Shakeで結合する
- 中間層はエンコーダー側はtanhで、デコーダー側はReLUで結ぶ。
- 中間層からの生成については、reconstructionはそのまま、samplingのみ2つに分割し、(1)ブートストラップサンプリング、(2)ランダムサンプリングの2つのパターンを作る
- ブートストラップサンプリングについては、直前の中間層の行列(ミニバッチサイズ×潜在変数の次元)をキャッシュし、潜在変数の次元ごとにnp.random.choiceで選んで、次元間で独立にサンプリングする(ミニバッチ単位でブートストラップすると、reconstructionと変わらないため)。つまり、このブートストラップは(ミニバッチサイズ)^(潜在変数の次元)の組み合わせがある。
- ランダムサンプリングについては、-1~1の一様乱数で潜在変数をサンプリングする。ただし、潜在空間が一様分布に従うという保証はない(VAEの場合は、正規分布に従うという仮定がある)。
ピュアなAEの結果
MNISTとCIFARでやってみました。結果を見てみましょう。reconstructionはとてもきれいです。
reconstruction


ただ、samplingが厳しいです。ブートストラップだと、かろうじて原型は残っていますが、何がんなんだかわからない。多分このブートストラップだと変数間の相関を無視しているからだと思います。
bootstrap sampling


そしてランダムサンプリングだとほぼノイズですね。
random sampling


あとかなり気になったのが、ピュアなAEにしたらVAEと比べてロスの値がガクッと(VAEが100ぐらいとしたら、AEが0.00…いくつ)落ちたことです。ピュアなAEではKLダイバージェンスを入れていません。ひょっとすると、VAEではロスのうち、エンコーダーの入力画像をデコーダーの出力画像を等しくするクロスエントロピーよりも、KLダイバージェンスのほうが圧倒的に支配力が強いのではないかなと思われます。不鮮明になってしまうのはひょっとしたらこれもあるかもしれません。
やはり、潜在変数の分布は仮定したほうが良いのでしょうか?その一方でDCGANをはじめGANファミリーが画像生成で素晴らしい成績を残しているので、エンコーダー・デコーダーモデルが悪いというわけではないはずです。VAEは、GANに見られるようなDiscriminator/Generatorの片方のロスが0になってモデルが崩壊するということがないので、学習が安定しているというメリットがあると思います。
なので、VAEでGAN並の高解像度な出力ができたら、個人的にはVAEを使ったほうが実用面でのメリットは今の所は大きいかなと感じています。GANの学習安定化について理論だったアプローチがあれば知りたいですし、Auto Encoderで高解像度な出力を得る方法があったらコメントで教えていただければ助かります。