2021年のディープラーニング論文を1人で読むAdvent Calendar16日目の記事です。今回紹介するのはCVPR2021でBest Paper Honorable Mentionsを獲得した「Exploring Simple Siamese Representation Learning」という論文です。一言で言えば「Siamese Networkを勾配停止操作を使うことでめちゃめちゃ簡単にしました。従来の方法は不要でした。教師なしながらCIFAR-10で91.8%」というかなりヤバい内容です。
この論文arXivに出たのが2020年11月で、厳密に言えば2020年の論文なのですが、CVPR2021に出て賞を取っていることから、ここでは2021年の論文として扱います。かなり読んでいる方が多く、解説記事もいくつかある比較的有名な論文です。手法にあまりにびっくりしてしまったので書いていきたいと思います。著者の所属はFacebook AI Researchで、1人はResNetでおなじみの人工知能界の大御所「Kaiming He」です。
- タイトル:Exploring Simple Siamese Representation Learning
- URL:https://openaccess.thecvf.com/content/CVPR2021/html/Chen_Exploring_Simple_Siamese_Representation_Learning_CVPR_2021_paper.html
- 出典:Xinlei Chen, Kaiming He; Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 15750-15758
- コード:https://github.com/facebookresearch/simsiam
Siamese Networkってなんだっけ?
まずはSiamese Networkから復習していきましょう。Siamese NetworkとはもともとOne-shot Learningを目的としたものでした。図は「Siamese Neural Networks for One-shot Image Recognition」の論文からです
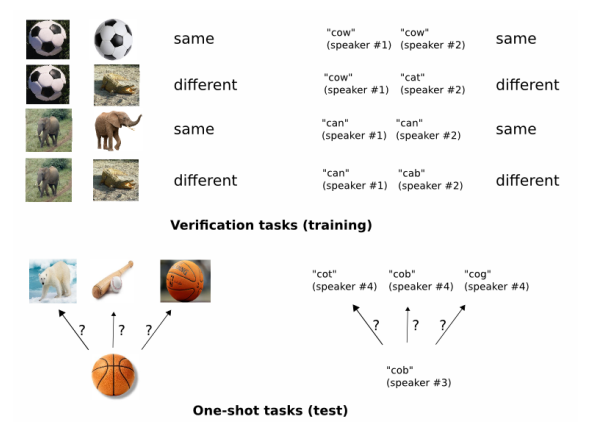
画像分類は、例えばCIFAR-10なら1クラスあたり訓練画像が5000枚あり、事前に大量の学習データが与えられたクラスに対してテスト画像を推論するというものでした。One-shot Learningは異なり、1個しか学習(参照)データがない場合、どう推論するのかという問題です。具体的には顔認証や指紋認証がいい例でしょう。
顔認証がわかりやすい例で、同一人物の画像を何千枚も撮ることができませんし、無数に対象人物が追加される中でデータセットを拡張しつつ、追加されるたびに画像分類モデルを学習しなおすのも現実的ではありません。このような問題で、ベースラインとして使われるのがSiamese Networkです。Siamese Networkが画像分類モデルと大きく異なる点は以下のとおりです。
- 画像分類:与えられた1枚の画像がどのクラスに属するのかを学習
- Siamese Network:与えられた2枚以上の画像が、それぞれ異なるクラスに属するのか同一のクラスに属するのかを学習
「猫、犬、馬」とクラスがあったときに画像分類なら各クラスを学習しますが、Siamese Networkなら「異なるクラスか、同一のクラスか」だけを学習し、具体的なクラスの中身までは学習しません。Siamese Networkのほうが画像分類よりも問題設定が簡単になっていると言えるでしょう(問題設定を簡単にした分One-shotでも通用するようになった)。
クラスの中身を推論したいときはどうするのか? ということですが、参照となるクラスラベル付きのデータをいくつか用意します。それらの参照データに対して、訓練したニューラルネットワークの特徴量を取得します。その後kNNや類似度計算でクラスを推定します。推論部分は現在でも大まかには変わっていません。
SimSiam
シンプルすぎるアーキテクチャ
本論文のSimSiamはこれまでのSiamese Networkとは大きく変わっていて、異なるクラスか同一のクラスかどうかも加味しません。特に距離学習では、安定的な学習のために、PositiveとNegativeのペアをどう発掘するかということがよく研究されていました。また、2つのパスは残っていますがData Augmentationによる違いだけで、もとは同一の画像です。そういった過去のプロセスを一切無視して通用すると主張しているのがSimSiamです。以下の図と擬似コードを見ましょう。
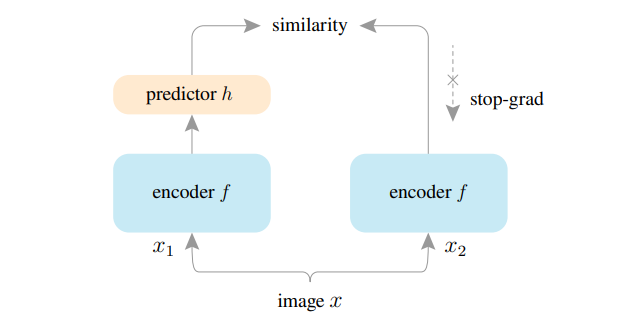

「あれ、これだけ…?」
そう、これだけです。
タイトルにもRepresentation Learning(表現学習)とありますので、従来の距離学習とはかなり異なるモデルであることがわかります。訓練中にはラベルを一切使わない教師なし学習です。ラベルを推論したいときは、特徴量をとってkNNをかけます。kNNの詳細に先行研究の論文にならっているとのことです。
実際精度出るの?
→出ます
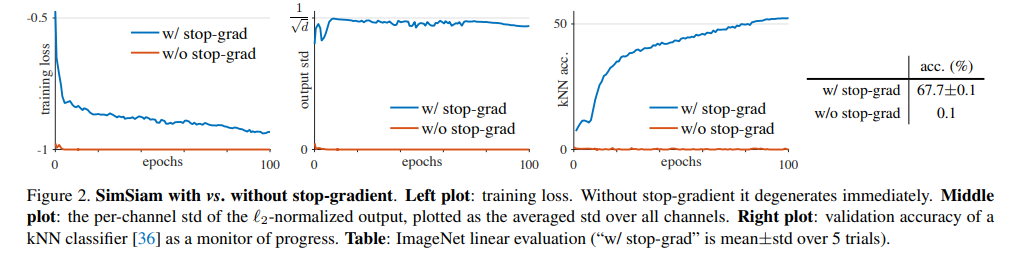
ImageNetの場合
CIFAR-10の場合
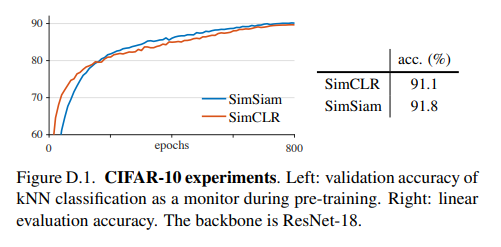
それぞれImageNet 1K、CIFAR-10で提案手法以外は特に変わったことはしていません。特に**CIFAR-10は教師ありか?**と疑うぐらいの精度ですね。ImageNetも教師ありのResNet50がTop1で80%弱だったので、教師なしにしては相当すごいレベルです。
ImageNetの場合の「w/o stop gradient」というのが、本論文で提唱している勾配を止めるオペレーションをしない(擬似コードの.detach()の行)ケースです。この場合は精度は0.1%(ほぼノイズ)レベルまで低下してしまうので、いかにこの勾配を止めるオペレーションがクリティカルかがわかります1。
SimSiamのお気持ち
ネガティブペアやモメンタムエンコーダを用いず、1つの画像の2つのビューの類似度を直接最大化する
というのがSimSiamの根底にある思想です。入力には1つの$x$という画像を使います。それをData Augmentationをそれぞれかけ、異なる画像$x_1, x_2$を得ます。2つのパスをニューラルネットワークに通すことで、特徴量$z_1, z_2$を取得します。Predictor層を通した値$p_1, p_2$とし、$p_1, z_2$、$p_2, z_1$のように交互にロス計算していくのがSimSiamのシステムです。ロスを計算するといっても元は1つの画像なので、Augmentationをかけた画像でも同一の画像とみなせるように訓練しているということがわかります。
サンプル間のペアを考えないことは大きなメリットがあって、計算量が大きく異なります。データセットのサンプル数を$N$とすれば、ペアを考えれば$O(N^2)$の計算量になります。しかし、この方法は1枚の画像で完結するため$O(N)$のままです。距離学習で問題になった安定的なペアの探索の問題も考える必要がなく、実装をシンプルにできるというメリットもあります。
なお、Data Augmentationは以下のものを使っています。すべてPyTorchの表記です。
-
RandomResizedCrop:スケールは[0.2, 1.0] RandomHorizontalFlip-
ColorJitterで「明度、コントラスト、再度、色相」をそれぞれ「0.4, 0.4, 0.4, 0.1」で適用。確率は0.8 -
RandomGrayScaleを確率0.2で適用 - ガウシアンぼかしのAugmentationを使用し、ガウスカーネルが[0.1, 2.0]の間
いずれも古典的な画像処理中心のAugmentationで、特段複雑なものは使用していません。
先行研究との位置づけ
サンプル間のペアを考えないことはこれが初出ではなく、SimCLRやSwAVなどの先行研究でも行われています。この論文のモデルはBYOLとも似ていますが、BYOLにあったモメンタムエンコーダーを消しているというのが大きなポイントです。
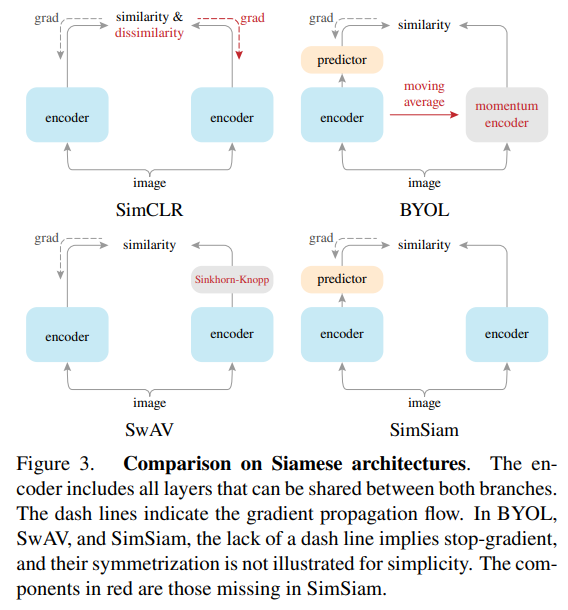
BYOLでは訓練の安定化のためにモメンタムエンコーダーを利用していましたが、それを勾配をストップするだけでいいよと言っているのが本論文SimSiamの主張です。
SimSiamのほうがシンプルという印象を受けます。先行研究の論文を見ていたら「ImageNetで教師ありにせまる精度を出した」という主張をたびたび見ましたが、あくまでそれは係数250M近い特大モデルでの話だったので、ResNet50をメインに検討しているこの論文は、計算リソース的には親切な印象を受けます。
損失関数はコサイン類似度だけ
コサイン類似度ベースのシンプルすぎる損失関数も本論文の特徴です。「2つのビュー間の類似度を最大化したいのだから、負のコサイン類似度を最小化すればいいよね?」というストレートな発想です。
$$\mathcal{D}(p_1, z_2)=-\frac{p_1}{|p_1|_2}\cdot\frac{z_2}{|z_2|_2}$$
各分数はL2-Noramlizeを表し(擬似コード中のコメント参照)、これはコサイン類似度にマイナスをつけたものにほかなりません。全体の損失関数は、
$$\mathcal{L}=\frac{1}{2}\mathcal{D}\bigl(p_1, \rm{sg}(z_2)\bigr)+\frac{1}{2}\mathcal{D}\bigl(p_2, \rm{sg}(z_1)\bigr)$$
ここで$\rm{sg}(\cdots)$は勾配ストップのオペレーターです。
クロスエントロピーに変えると精度が5%落ちる
もし損失関数をコサイン類似度からクロスエントロピーベースに変えた場合はどうでしょう。クロスエントロピーベースの損失関数とは、$\mathcal{D}(p_1, z_2)=-\rm{softmax}(z_2)\cdot\log\rm{softmax}(p_1)$です。
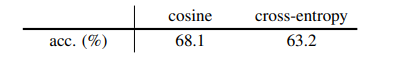
クロスエントロピーベースに変えると、ImageNetの精度が68.1%から63.2%に落ちてしまいました。やはりコサイン類似度の最大化が良いことになります。
ProjectionとPredictionのMLPの構造
この研究では、ProjectionとPredictionのMLPの構造が結構重要です。
Projection
バックボーンのGlobal Average Poolingの直後に入れるレイヤーです(公式実装では、バックボーンの分類部分のfcを置き換える形にしています)。ベースラインでは、3層からなるMLPで、隠れ層の次元は2048です2。各FC層にはBatch NormとReLUあり、最後の層だけReLUがありません。
Prediction
出力層にはBatchNormが不要
2層からなるMLPで、入力と出力の次元は2048です。中間層の次元は512とするボトルネック構造となっています。出力層にはBatchNormやReLUがありません。これらのBatchNormの配置が非常に重要で、精度が非常に大きく変わります。

どの層にもBatchNormを入れないと34.6%と精度が低いですが、全部の層にBatchNormを入れてしまうと損失が振動し不安定になってしまいます。Predictionの出力層だけBatchNormを入れないのが最も精度がよくなりました。出力層にBatchNormを入れないのは分類モデルでも同様です。
Predictionがないと精度がほぼ0%まで落ちる

また、PredictionのMLPを外したり、Predictionを訓練しないようにすると精度がノイズレベルまで下がってしまい、このPredictionのレイヤーが必要不可欠であることがわかります。「lr decayed」はもともと学習率をコサインでDecayさせていましたが、それがないほうがむしろ精度がわずかに上がるとのことでした。
ボトルネック構造が重要で、出力次元は大きく
Appendixでは、このボトルネック構造を使用しない場合を検討していましたが、もしPredictionにおいてすべての層をイコールにする(ボトルネック構造を作らない)と、学習が不安定になったり、失敗することが報告されています。ボトルネックはオートエンコーダーのような振る舞いをするため、Predictionでボトルネック構造を作ることを著者は推奨しています。
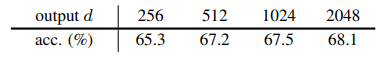
また、ボトルネックを作り(ボトルネックのチャンネル数は出力チャンネル数の1/4)、Predictionの出力次元を変動させたところ、多いほうが精度が上がることが報告されています。これは256のような少ない次元だと飽和してしまうからとのことです。
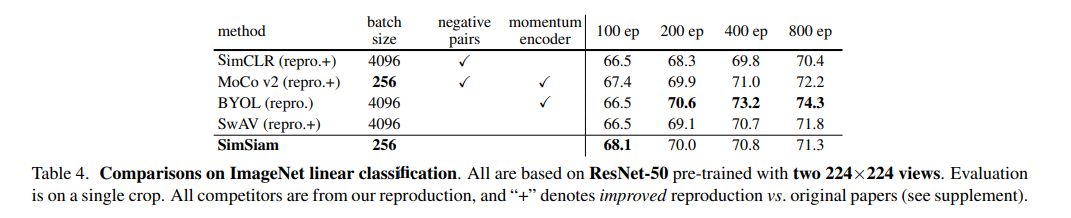
大きいバッチサイズは必要ない。ただのSGDでいい
SimCLRやSwAVといった先行研究では4096のような巨大なバッチサイズが必要でした。しかし、本論文SimSiamでは256や128のような現実的なバッチサイズでも十分訓練できています。また学習の崩壊を防ぐために特別なオプティマイザーも必要なく(例:LARS)、ただのSGDでいいとのことです。

事実他のモデルと比較すると、バッチサイズが256で良いのはMoCo v2だけですが、負のサンプルのペアとモメンタムエンコーダーが必要です。800エポックなど長時間訓練したときの性能は、SimSiamはBYOLと比べると頭打ちになってしまいますが、「バッチサイズ4096でないとダメ vs バッチサイズ256でいい」は3%の精度差を覆せるほどの差ではないかと個人的には思います。SimSiamは100エポックでは最も精度が良かったので、とにかく訓練リソースの面で優しいというのが大きな特徴ではないかと思われます。
Siamese Networkで事前学習して転移学習すると教師ありより性能が良い?
面白いのが教師なしのSimSiamや先行研究の手法でImageNetを訓練し、物体検出のタスクで転移学習すると、ImageNetを教師あり学習で訓練して転移学習したケースよりも高性能になるということです。
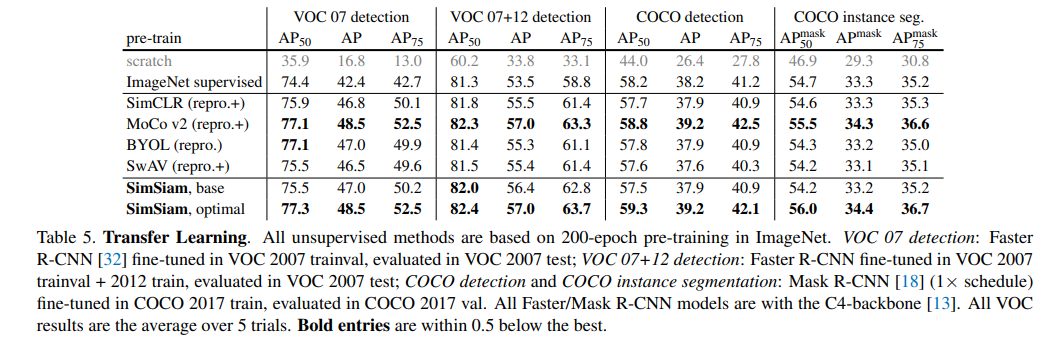
「ImageNet Supervised」が教師あり学習で訓練した係数を使って転移学習したケースです。SimCLR以降は先行研究の表現学習の手法、SimSiamは提案手法です。いずれのケースでも教師あり学習と同程度かそれを若干上回る性能を出しています。これらに共通するにはすべて「Siamese Network」なので、Siamese Networkが成功の要因になっているのではないかと述べています。
まとめと感想
この論文ではとにかくシンプルなSiamese Networkベースの表現学習SimSiamを提唱しています。後半ではSimSiamがEMアルゴリズムの近似ではないかという仮説について検証していましたが、自分が不勉強なものでEMアルゴリズムがよくわからなかったので、今回はその部分について割愛しました。気になる方は論文読んでみてください。
論文の結論としては「Stop Gradient is All You Need.」なわけなんですが、そう書かずにEMアルゴリズムの検証へと向かうのが大御所の大御所たる所以なのかなと思いました。
個人的な感想としては、最初は表現学習ではなく距離学習のコンテクストで、「Siamese Networkの簡易化ができるのでは」と期待して読みました。結果的にはImageNetやCIFAR-10で教師あり学習に匹敵するレベルの精度が出せているので、論文としては表現学習ですが、従来の距離学習のコンテクストで使ってもおそらくいけるのではないかと思います。とにかく訓練方法がシンプルなので、お手軽に実装しやすいですし、顔認証など距離学習の応用として試してみるのも面白そうです。
告知
このアドベントカレンダーが本になりました!
https://koshian2.booth.pm/items/3595424
Amazonでも扱いあります詳しくは👉 https://shikoan.com