2021年のディープラーニング論文を1人で読むAdvent Calendar5日目の記事です。今回紹介するのはTransformerによるアニメーションの自動着色の研究です。まずはこちらの図をご覧ください。

1フレームの線画とカラー画像が参照データとして与えられます。次に複数のフレームの線画が与えられます。これらの複数線画に対して、最初の線画-カラー画像と同じように自動着色するアプリケーションを作りましたというのがこの論文の趣旨です。ICCV2021に採択されています。
- タイトル:The Animation Transformer: Visual Correspondence via Segment Matching
- URL:https://openaccess.thecvf.com/content/ICCV2021/html/Casey_The_Animation_Transformer_Visual_Correspondence_via_Segment_Matching_ICCV_2021_paper.html
- 出典:Evan Casey, Víctor Pérez, Zhuoru Li; Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 11323-11332
- プロジェクトページ:https://github.com/akasha-imaging/ICCV2021
- アプリ:https://cadmium.app/
詳細なコードは公開されていませんが、この研究を導入したアプリは公開されているので、詳細な実装に踏み込まずに雰囲気だけ見ていく感じで読んでいきます。アプリの公開ホームページのデモ動画を見るとこの研究のアウトラインが見てきます。
ディープラーニングやTransformerの応用例として見ると面白いでしょう。この研究はTransformerらしさを活かしたものなので、「なぜCNNではダメで、Transformerなのか」を踏まえながら見ていきたいと思います。
Animation Transformer(AnT)
モデルのアーキテクチャ

まずはバックボーンのネットワークで特徴を抽出します。画像をセグメント単位でクロップし、クロップ画像とBounding Boxの座標に分けます。クロップ画像はCNNで、Bounding Boxの座標はFCN(MLP)で特徴抽出します。これを参照画像とターゲットの画像の両方で行います。
次に参照画像とターゲット画像の各特徴をTransformerに入れ、Self Attention、Cross Attentionを使って相関行列を計算します。これにセグメント別の色を入れ、最終的な着色結果を出力するのがAnimation Transformer(AnT)です。
SuperGlueとの比較
論文でも引用されていますが、この研究はCVPR2020に採択されたSuperGlueに着想を受けています(日本語解説記事)。SuperGlueの論文からの引用です。

SuperGlueでは、2つの画像間の点のマッピングをGNN(Graph Neural Network)で行っています。この動画はSuperGlueのGitHubからのものですが、大量のキーポイントを一瞬でペア作れるのがすごいですね。

SuperGlueのアーキテクチャーは次のとおりです。
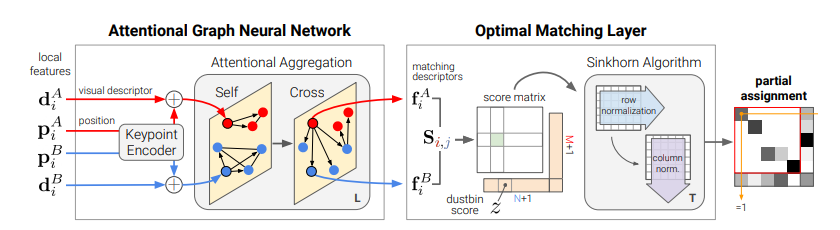
なんだかAnTと似ていますね。大きな違いはGNNかTransformerか、マッピングが点かセグメンテーションかの違いでしょうか。SuperGlueはコードが公開されているので、AnTを実装したいときは参考になるかもしれません。
バックボーン(CNNとFCN)
AnTに戻りましょう。クロップした画像の解像度は$(H_c\times W_c \times 2)$なので、線画とセグメンテーションマスクを同時に入れているのでしょうか(ここ自信ない)。CNNでは、これを1×1Convで$D$次元の高レベルの特徴量へマッピングします。この論文では$H_c=W_C=32, D=256$を採用しています。
FCNではBounding Boxの座標をFCNに食わせて、CNNの出力と同じ次元の特徴量を作ります。CNNと出力とFCNの出力を足し合わせて、バックボーンの出力とします。
Self attentionとCross attention
このモデルではSelf attentionとCross attentionという2つのアーキテクチャーを利用しています。Self attentionのCross attentionの違いはこの論文に限らず一般的な話なのですが、1枚の画像内でAttentionを取るのがSelf attention、2枚の画像間のAttentionを取るのがCross attentionです。下の図を見てみましょう。

点は各セグメントの中心点です。Self attentionでは参照フレームのみのAttentionをとり、Cross attentionでは参照フレームとターゲットフレーム間のAttentionを取ります。これを交互に連続させていくことで、異なる点でのセグメンテーションのマッピングを学習していきます。これは位置不変性の保証されているCNNだけだと難しいので、Transformerならでは構造だと考えられます。
最終的な出力は、$A, B$という2つの画像があったときに、$\mathbb{z}_A^L:(M\times D)$、$\mathcal{z}_B^L:(N\times D)$という次元になります。ここで$M, N$は参照、ターゲットのセグメンテーションの数です。
類似度の行列を計算
A, Bの特徴量が計算できたら類似度行列を求めます。

ここで$\mathbb{f}_i, \mathbb{f}_j$は$\mathbb{z}_A^L, \mathbb{z}_B^L$の最初の軸でのスライスで、$\mathbb{f}_i, \mathbb{f}_j$は$D$次元のベクトルになります。$\mathbb{f}_i, \mathbb{f}_j$の内積を指数をかけたものを計算し、それを$M$方向の和を取って正規化したものが$\mathcal{S}_{ij}$です。やっていることは行単位でのSoftmax関数です。この$\mathcal{S}_{ij}$がセグメント単位の類似度行列になります。
最終的なターゲット画像の配色は、
\hat{c}_j = \sum_{i=1}^M \mathcal{S}_{ij}c_i
で求められます。
Forward match lossとCycle consistency loss
損失関数はForward match lossとCycle consistency lossからなります。

Forward match lossとはターゲットの配色がGround Truthにどれだけ近づいているかをクロスエントロピーで計算します。もしこれがセグメンテーションと色の関係が一意なら、Forward match lossだけで良かったのですが、現実的には複数のセグメンテーションで同じ色を使っています。このまま最適化すると誤った関係を学習することになります。

具体的にはこのような例です。右のキャラの緑色の服は複数のセグメントに分かれます。左のキャラの髪色も同様です。この問題を解決するためにCycle consistency lossを導入します。このロスはCycleGANを連想しますが発想は似ています。
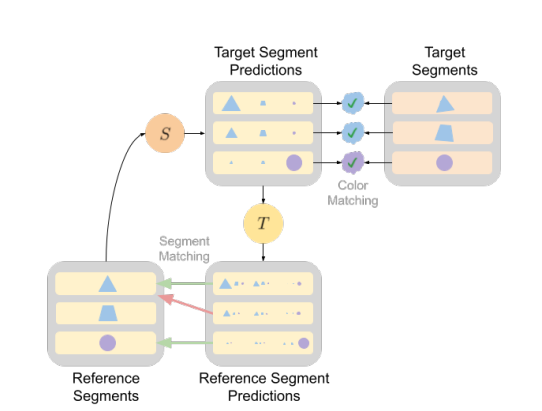
先程計算した類似度$S$が参照→ターゲットへの類似度です。これと逆(ターゲット→参照)の類似度$T$を計算し、リファレンスのセグメンテーションIDと同期を取るように促すのです。CycleGANだと逆変換用のモデルを新たに作るのですが、AnTではCycle consistency lossの計算は単純で、

先程の$\mathcal{S}$とは前後を入れ替えた($\mathcal{S}$は$\mathbb{f}_i^T \mathbb{f}_j$)相関行列$\mathcal{T}_{ij}$を計算します。
$r_i$を乱数で初期化したセグメントIDとし、$\mathcal{S}$とかけて$\hat{r}_j$とします。これと$\mathcal{T}$との積を取ったものが$\hat{r}_i$となります。$\hat{r}_i$と$r_i$のロスを計算したのがCycle consistency lossです。
実装詳細
データセットについて
訓練のためのデータセットをどう作ったのか興味ありますが、合成データセットと手描きアニメーションのデータセットの両方を自作しています。
- 合成データセット:自由に利用できる3Dモデルを使って、Cinema4Dで合成。1500×1500ピクセルで、各キャラ1000フレーム、11キャラで合計11000フレーム作成。
- 手描きアニメのデータセット:実際のアニメから3578フレームを収集。現実問題として、手描きアニメではセグメントIDはないため、カラー化された画像のセグメントを使って求めている。
計算時間
AnTのForeward pass1回はV100で76msで13FPSでした。フルHDに近い高解像度なデータでかなりの速度を出せています。先行研究のDEVCだと6FPSでした。Cross attentionの計算量は$O(MN)$、Self attentionの計算量は$O(M^2+N^2)$です。
メモリの消費量がガクッと落ちているのが特徴で、DEVCだとバッチサイズが3までしか訓練できなかったのが、AnTだと64まであげられます。これはDEVCの計算量が$O((HW)^2)$と画像解像度の各2乗に比例し、莫大であったからです。
評価

実際に比較すると、ずっと良かった先行研究よりも良かったことが報告されています。合成データでは結構健闘していますが、手描きのデータではまだまだ厳しいのが現状です。

実際のカラーリングは上の通り。合成データではかなり健闘していますが、リアル(手描き)のほうはまだ厳しいですね。顔ひげの着色がおかしいですし、腕の黄色が丸々消えています。

AnTで導入したすべての項目が有意に働いていたのがわかります。一番効いているのがCycle consistencyですね。これを外すと、対応関係のないセグメントを同じ色で塗りつぶしてごまかすとのことです。
リアルデータの着色のために合成データを使ったらどうか
リアル(手描きアニメ)データでの性能を上げるのが大変なので、「リアル向けでも合成データを訓練データとして使ったらどうか?」という疑問がわきます。
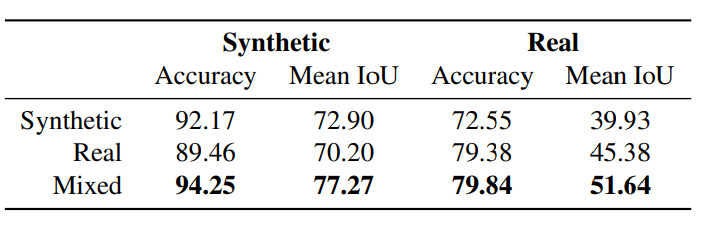
実際に試してみると、リアルと合成データを混ぜたほうが、合成・リアルの両方で最も性能が良かったことがわかります。混ぜたケースでリアルの性能が上がるのは理解できますが、合成のほうがむしろ大きく上がっているのが驚きです。論文では「合成データはリアルデータと比べて、多様性やチャレンジング度合いが乏しいから」と仮説づけています。
まとめと感想
この論文では、アニメーションの自動着色という、かなり実用性ありそうな問題についてチャレンジしています。1500×1500という高解像度でも現実的な計算量で収まっているのがすごいです。リアルなデータでの性能上げはまだまだ難しいですが、例えば、1日目に紹介したEdge Flowのように、インタラクティブに着色をある程度指定していくように問題を簡単にすると、もっと性能が上がるような気がします。
この論文は技術的に結構面白くて、Transformer特有のSelf attention、Cross attentionをうまく活用しています。具体的には参照画像とターゲット画像のマッチングにCross attentionを使う、計算量を落とすためにTransformerで使われるようなパッチを切り出し、Multi head風にするなどです。Transformerの時代であることは声高に言われますが「実際CNNで良くない?」って疑問が湧くことも多々あります。しかしAnTは、位置が大きく変わるセグメント間の類似度の学習のため、Transformerのほうが明らかに良いです。別の先行研究として触れたSuperGlueはGNNなので、「Transformerはまだ許せるけど、GNNはちょっと」みたいな人でも、使いやすいモデルとなっています。
AnTはTransformerらしさを活かした問題やモデル構造として、結構面白いのではないかと思います。4日目に紹介したStyleGANの合成はCNNの良さを活かしているので、ここらへんの使い分けが意識されると、より心地の良い世界になるのではないかと思います。
※AppendixにPaint Chainerの話が載っていてちょっとニヤリとします。
告知
このアドベントカレンダーが本になりました!
https://koshian2.booth.pm/items/3595424
Amazonでも扱いあります詳しくは👉 https://shikoan.com