2021年のディープラーニング論文を1人で読むAdvent Calendar9日目の記事です。今回はデータセットの論文です。海洋ゴミをソナー画像からセマンティックセグメンテーションで見つけることを将来的に実現するための研究です。これは水域をきれいにするために重要とのことです。
これはいわゆるAIの応用例ですが、特定の問題に特化したデータセットを知っておくのは意義あるなと思ってチョイスしました。ニッチ領域と思いきや、ICCV2021のWorkshopに採択されているので意外と侮れません。著者はインドのネータージー・スバース工科大学と、ドイツ人工知能研究センターの方です。
- タイトル:The Marine Debris Dataset for Forward-Looking Sonar Semantic Segmentation
- URL:https://openaccess.thecvf.com/content/ICCV2021W/OceanVision/html/Singh_The_Marine_Debris_Dataset_for_Forward-Looking_Sonar_Semantic_Segmentation_ICCVW_2021_paper.html
- 出典:Deepak Singh, Matias Valdenegro-Toro; Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, 2021, pp. 3741-3749
- データセットURL:https://github.com/mvaldenegro/marine-debris-fls-datasets/
あとはこれまでのAdvent Calenderで読むのが大変な1論文がそこそこあったので、ここで少し休憩しよう意味も込めて入れています。データセットを作るだけの論文なら、そこまで難しい概念出てきませんからね。
FLSの公開データセット?ないよそんなもの
海底の大部分は海底ゴミで汚染されています。陸上なら光学カメラが使えますが、水中は散乱や減衰が大きく光学カメラからの正確なセグメンテーションができません。そこで有力なのがソナーで、**前方監視ソナー(FLS)**は水の濁りや光学的な視認性に左右されず、15Hzの高いフレームレートで水中の高画質な画像の撮影ができるとのことです。
ソナー画像のセグメンテーションのための公開データセットは大きな進展がありませんでした。光学画像によるデータセットはいくつかありますが、RGBによる画像なので適切ではありません。ソナーのグレースケール画像によるデータセットの構築がこの論文の目的です。この論文ではデータセットを構築した後、U-NetやPSPを訓練していますが、グレースケールの画像なのでRGB画像からの転移学習をしていません。1から訓練しています。

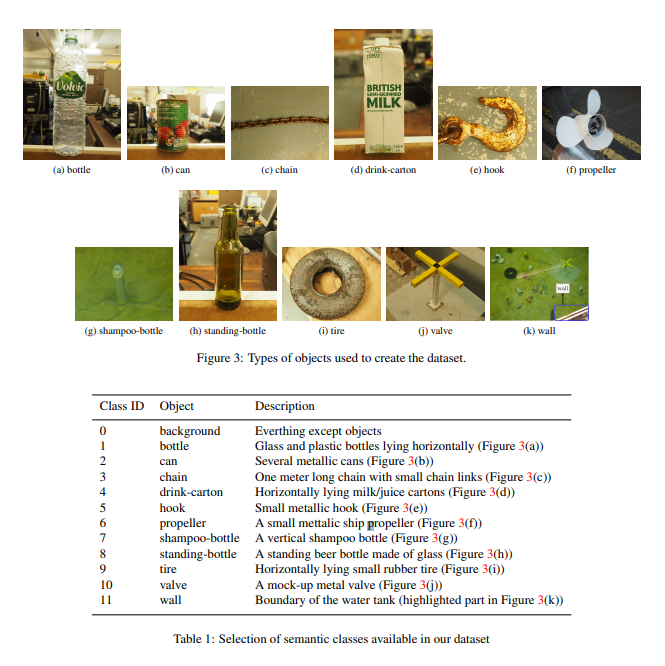
データの収集にあたっては「ARIS Explorer 3000」というセンサーが使われました。このデータセットは1868枚の画像からなり、11種類のゴミのクラスと、1種類の背景クラスからなります。
データの収集
データの収集には縦2m、横3m、深さ4mの人工的な水槽を使っています。実際の環境で海洋ゴミのデータ収集は難しかったとのことです。
ARIS Explorer 3000のソナーは最小飛距離は70cm、最大飛距離は5m(周波数による)。空間分解能は1ピクセルあたり近距離では2~3mm、遠距離では10cmです。ゴミとして使ったオブジェクトは、
- 家庭用のオブジェクト:空き缶、飲料用の紙パック、プラスチックのシャンプーボトルなど
- 海洋用のオブジェクト:チェーン、フック、ゴムタイヤ、プロペラ、バルブ
実際に水槽にゴミを入れた光景が次の通りです。海底ゴミは家庭用品が多いため、空き缶やペットボトルを中心になっています。

採集したデータは.arisファイルで極視野に投影し、png画像として保存しています。すべての画像の中から1つ以上の物体がはっきりと見えているものだけを選択し、画像間の相関を避けるため最低でも5フレーム以上開けるようにしています。AUV(ソナーのついている機械)は水槽内を1/4周するように0.1m/sで移動してします。水槽内の移動スペースが限られているため、すべての視点からのデータを取得できなかったそうです。また壁面の画像では水槽の境界が強調されて表示されているため、壁のクラスを別に作っています。クラス全体は以下のとおりです。
アノテーション
LabelMeを使ってセマンティックセグメンテーションのためのラベル付けがされました。アノテーションの際は以下の点が課題になったそうです。
- ソナーデータは色情報がなく、大きなノイズがあること
- すべての物体がはっきり見えるわけではなく、ほとんどの物体は影を作っていない。影の見え方は物体の大きさや撮影したときの視点によって異なる
アノテーターは物体のハイライトについてラベル付けをしますが、難しい物体については、検出に最も重要な特徴である影にラベル付けしています。
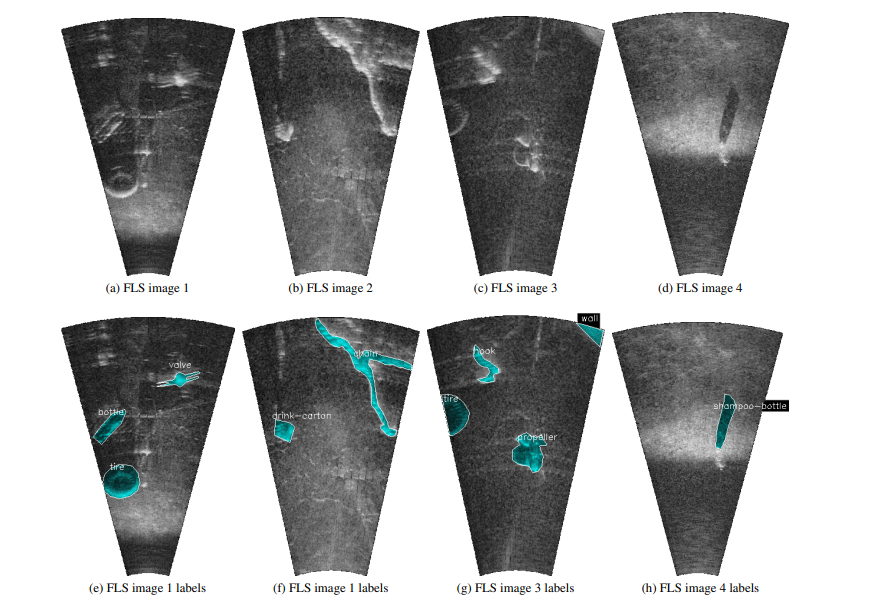
これが実際のソナー画像とラベルです。(e)の画像のようにタイヤはソナー画像からはっきり見えるとのことです。後は影の識別が多いですね。

背景のラベルはこの通り。それ以外の白く光っている部分が何らかの物体になります。
データセットの詳細
1868枚の画像のうち、1000枚を訓練とし、251枚をValidation、617枚をテストにしています2。3つの分布間に偏りが生まれないよう、クラス間のピクセル数とオブジェクト数が分割間で一致するようになるまで、何回かランダムな分割を繰り返しています。
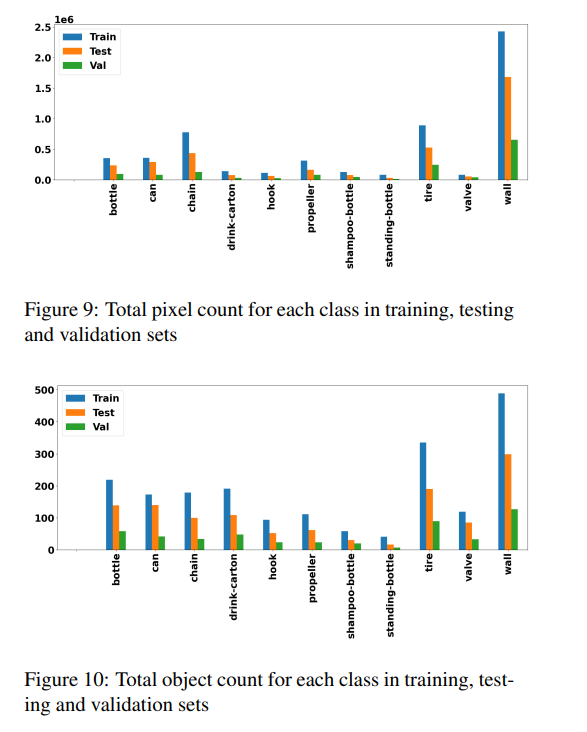
背景以外の各クラスのピクセル数、オブジェクト数はこの通り。不均衡データです。壁とタイヤあたりに推論が寄ってしまわないか、ピクセル数の少ないシャンプーボトル(shampoo-bottle)やガラス瓶(standing-bottle)がちゃんと検出できるか、個人的にかなり不安になります。壁は物理的に映る頻度も多いですし、強い音響反応を起こすため、ソナー画像的にも登場しやすくなっています。
セマンティックセグメンテーションの結果
実装の詳細は、セマンティックセグメンテーションの問題として目新しいものではないので端折りながら書きます。異なるバックボーンとセグメンテーションのモデルを試しています。テスト精度を比較したグラフがこちら。
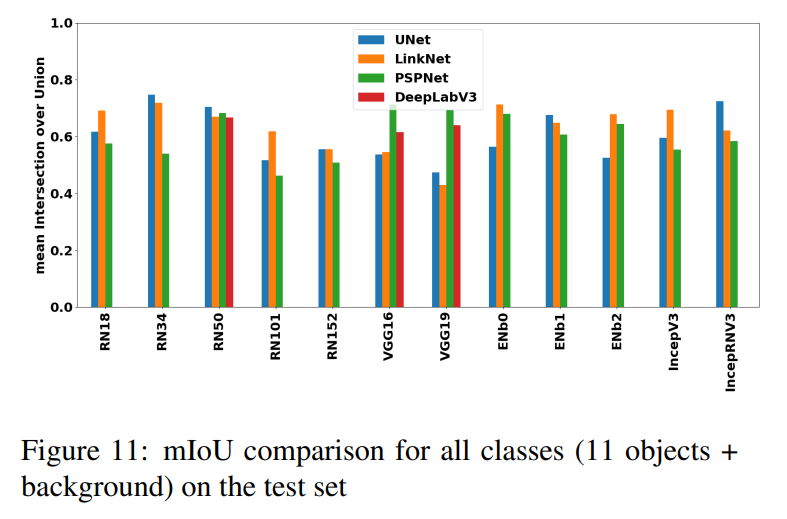
評価指標はmIoUです。テストデータで一番うまく行っているのがResNet34+U-Netでした。Inception ResNet V2+U-Netも良いです。この中では最も古典的なU-Netが一番うまく行った、というのはなかなか興味深いです。もともとU-Netは医用画像(電子顕微鏡)のセグメンテーションを目的として作られたので、同じモノクロ入力のソナーの画像とは相性いいのかもしれません。
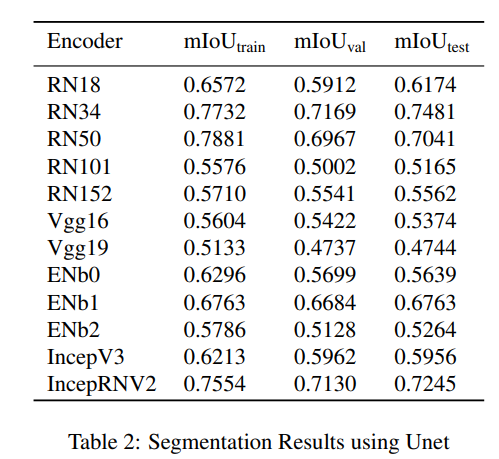
これはテストデータでの比較なので、Valで比較するのがより正しいかもしれません。ただテストでのmIoUが高いモデルはValでも高く、RN34+U-Net、IncepRNV2+U-NetはValでもmIoUが7割超えていました。U-Net以外にValが7割超えたのは、**ResNet34+LinkNet(0.7039)、VGG16+PSPNet(0.7018)**でした。RN34+U-NetのValが0.7169なので、ValでもやはりU-Netが最も高いmIoUを出しています。
この結果を見ると「一見mIoUが高くても、壁などマジョリティなクラスに対してうまくいっているだけで、少数のクラスに対してはうまくいっていないのでは?」との疑問もわきます。クラス単位のIoUを見てみると、
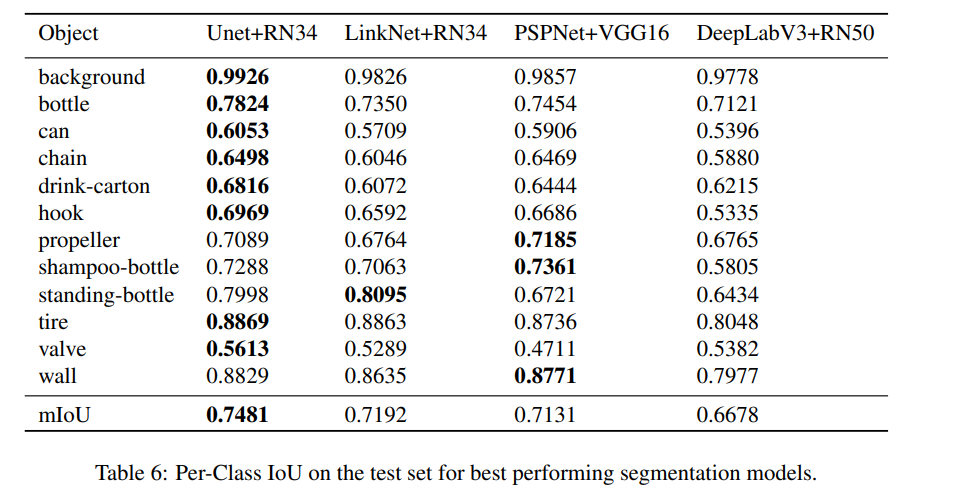
U-Net+RN34が多くのクラスで高いIoUを出しています。「データとしては少数のシャンプーボトルやガラス瓶はうまく行かないのでは?」との疑問もありましたが、0.7を超えていてそこまで足を引っ張った結果ではありませんでした。むしろ最もうまく行かなかったのがバルブで、これだけ0.5台と大きく足を引っ張っています。この理由については特に言及がありませんでしたが、バルブはサンプル数は比較的多くピクセル数は少ないので、小さいオブジェクトが中心なのかもしれません。これが検出難易度を上げているのだと思われます。

実際の推論結果の可視化がこちら。上段はResNet50がバックボーンなのでResNet34よりかは悪いです。下段の中で比較的性能が良いのが(d)のPSPNet+VGG16です。確かにチェーンやタイヤ、ボトルの先っぽ部分がリアルに出ているように見えます。
U-Net+RN34やPSPNet+VGG16という**「ずいぶん懐かしい時代のディープラーニングだな」感あるネットワークでも、最高の性能を出せている**というのは元気がもらえますね。
まとめと感想
この論文では海洋ゴミをソナー(FLS)で検出するためのデータセットの構築の話が中心でした。実際にセマンティックセグメンテーションを行った結果はおまけみたいなもので、この論文のメインはデータの収集やアノテーションの話にあると思います。ソナー画像の物体識別は影が重要な要素になっていること、壁やタイヤのように映りやすいものもあれば、映りにくい物体もあること、はっきりしない画像の場合はそもそもアノテーションをつけられないこと。もし将来的に実運用可能なレベルのモデルが出たときに、このあたりが問題になるのではないかと思います。
つまり、ソナーで見つけやすいゴミは回収されるが、ソナーで見つけづらいゴミはなかなか回収されない。言い方としては正しいのかはわからないですが、実世界とのPrecision-Recallの問題が出るのではないか、とうっすら考えています。ラベル付けされたデータ内ではPrecision-Recallは問題ないが、ソナー画像からも判別がつきづらい物体ゆえに、実世界ではRecallが高くない……という世界線が垣間見えてきます。これは妄想レベルなので、実際に起こるかはわかりません。
どうやってラベル付けしたか、ソナーの特性はどうというドメインレベルの知識は、「我々の○○Netで☓☓%のSOTAを達成しました」という論文ではなかなか掘り下げられないです。その点では、データセットの構築の論文を読むのはなかなかおもしろいなと思いました。内容的にも難しくなく癒やされる論文です。
告知
このアドベントカレンダーが本になりました!
https://koshian2.booth.pm/items/3595424
Amazonでも扱いあります詳しくは👉 https://shikoan.com