2021年のディープラーニング論文を1人で読むAdvent Calendar2日目の記事です。今回紹介するのは、時事ネタ論文です。画像のTransformer、今年熱いですよね。このTransformerを使って今年猛威を奮ったCOVID-19を検出しようという論文を紹介します。台湾の成功大学による研究です。
この論文はICCV 2021 Workshop: MIA-COV19Dで行われたコンペの解法を記したものです。このチームは最終的にMacro F1で3位でフィニッシュしています。
時事ネタだから引っ張ってきたのもあるのですが、
- 統計的検定に基づいたp値が出せる説明可能なディープラーニングのモデル
- 複数画像の特徴量を取ってきてTransformerで分析する一連の流れ
いずれも汎用性高く、今後流行りそうな有用な手法だからです。見ていきましょう。
- タイトル:Adaptive Distribution Learning With Statistical Hypothesis Testing for COVID-19 CT Scan Classification
- URL:https://openaccess.thecvf.com/content/ICCV2021W/MIA-COV19D/html/Chen_Adaptive_Distribution_Learning_With_Statistical_Hypothesis_Testing_for_COVID-19_CT_ICCVW_2021_paper.html
- 出典:Guan-Lin Chen, Chih-Chung Hsu, Mei-Hsuan Wu; Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, 2021, pp. 471-479
- コード:https://github.com/jesse1029/Deep-Wilcoxon-signed-rank-test-for-Covid-19-classfication
https://github.com/jesse1029/CCAT-CT-Detection
着想
- CTスキャンからCOVID-19の診断のための、統計的検定に基づいた説明可能なモデルを作りたい
- CTスキャンの1枚のスライス画像から判定するには、大規模なデータセットがないと精度が出ない。セマンティックセグメンテーションはアノテーションコストがかかる。小規模なデータセットでは、連続したスキャンから判定する3次元のモデルが必要(動画分類のようなアプローチが必要)。
- 2DConv+LSTM, RNNはLSTMやRNNが並列化できない。3DConvは計算量が多すぎるし、畳み込みの定義上、固定長のスライスからしか判定できない。よってTransformerを使いたい。
2つの手法:ADLとCCAT
この論文では2つの手法が登場しています。
- Adaptive Distribution Learning(ADL)[a]
- CT scan-Aware Transformer(CCAT)[b]
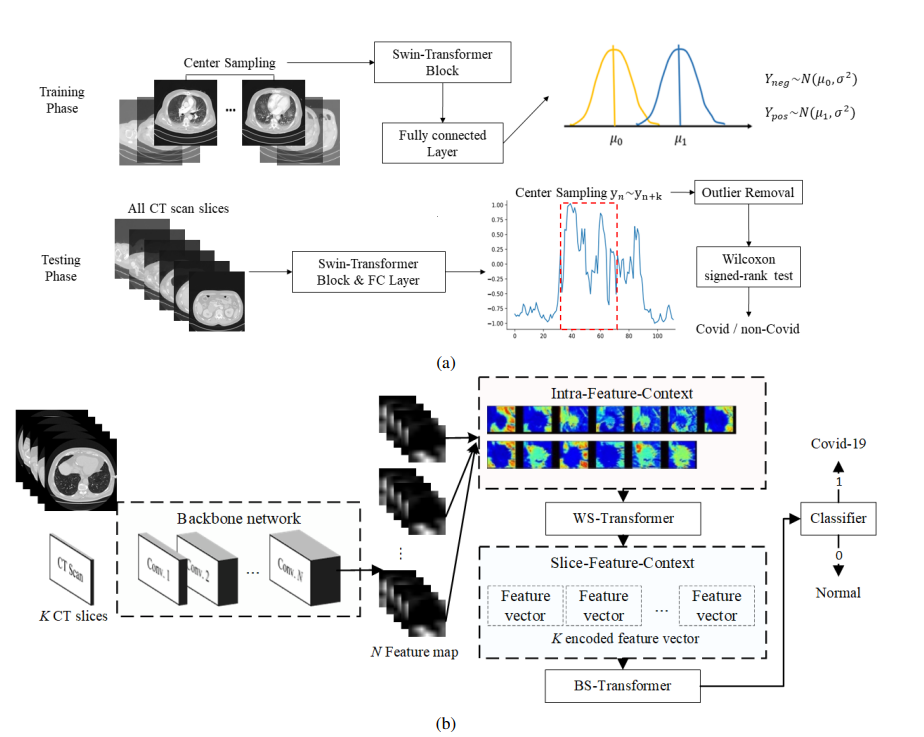
図の(a)がADL、(b)がCCATです。どちらも1枚のスキャン画像をバックボーンのネットワーク(ここではSwin Transformerや2DのCNNを使っています)を通し、各画像の特徴量を取っています。ADLとCCATの違いは異なるスキャン画像のまとめ方にあります。
ADLがウィルコクソンの符号順位検定を学習に入れた、統計的検定に基づく説明可能なモデルです。
CCATが1枚のスキャンの特徴量を、さらに2種類のTransformer(WS-Transformer、BS-Transformer)に入れ、End-to-endの学習を可能にしたモデルです。
Adaptive Distribution Learning(ADL)
まずは統計的検定に基づくモデル(ADL)からです。図を見ただけだと理解しづらいですが、コードを見るとそこまで難しくありません。
訓練コード
訓練ループを見てみましょう。1バッチ分を切り出しました。
for pos_img, neg_img in tqdm(zip(train_loaders['pos'], train_loaders['neg'])):
ct_b, img_b, c, h, w = pos_img.size()
pos_img = pos_img.reshape(-1, c, h, w).cuda()
neg_img = neg_img.reshape(-1, c, h, w).cuda()
optimizer.zero_grad()
pos_output = model(pos_img)
neg_output = model(neg_img)
pos_target = pos_dis.sample(sample_shape=torch.Size([pos_output.shape[0], 1])).cuda()
neg_target = neg_dis.sample(sample_shape=torch.Size([neg_output.shape[0], 1])).cuda()
pos_loss = criterion(pos_output, pos_target)
neg_loss = criterion(neg_output, neg_target)
Loss = pos_loss + neg_loss
Loss.backward()
optimizer.step()
train_loaderからPositive(COVID), Negative(non-COVID)な画像をそれぞれ取り出します。modelはバックボーンのネットワークで、Swin Transformerを使っています。pos_output, neg_outputが各スライスの特徴量です。
確率分布の学習
ここからがこの論文の大きな特徴です。よくあるやり方だと、Positiveなら1、Negativeなら0のように定数でラベルを学習させますが、ADLでは確率分布を学習させます。pos_dis, neg_disを見てみましょう。
criterion = nn.MSELoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=args.lr)
pos_dis = torch.distributions.Normal(1, 0.2)
neg_dis = torch.distributions.Normal(-1, 0.2)
Positiveは平均が1、Negativeは平均が-1の正規分布となるように学習させます。標準偏差はどちらも0.2です。訓練ループ内の
pos_target = pos_dis.sample(sample_shape=torch.Size([pos_output.shape[0], 1])).cuda()
neg_target = neg_dis.sample(sample_shape=torch.Size([neg_output.shape[0], 1])).cuda()
これは各分布の乱数ですが、Positive, Negativeの乱数値を正しい値として学習させます。損失関数はL2 lossです。これを繰り返すことで、Positiveなスライスは最終層の値が1の近傍、Negativeなスライスは-1の近傍に集まるように学習されます。
なぜラベルではなく、分布として学習させるかというと、分布外(OOD)のスキャンや外れ値のパフォーマンスへの影響を最小限に抑えるためです。乱数を使うのはVAEや、2つの分布の学習というとWGANを連想しますが、普通の分類問題でも乱数を使うのがADLの大きな特徴です。
CTスキャンのサンプリング
CTスキャンの中央部のデータのみ使います。これは中央部のデータがCOVID-19の判定に有用であることが経験的にわかっているからです。
DataLoaderの中のgetitemを見てみましょう。
def __getitem__(self, index):
img_path_l = os.listdir(self.data_list[index])
img_list = [int(i.split('.')[0]) for i in img_path_l]
index_sort = sorted(range(len(img_list)), key=lambda k: img_list[k])
ct_len = len(img_list)
start_idx = int(round(ct_len / 10 * 3, 0))
end_idx = int(round(ct_len / 10 * 7, 0)) + 1
if self.mode == 'train':
img_sample = torch.zeros((self.img_batch, 3, 224, 224))
sample_idx = random.sample(range(start_idx,end_idx), self.img_batch)
else:
img_sample = torch.zeros((min(end_idx-start_idx, self.img_batch), 3, 224, 224))
sample_idx = random.sample(range(start_idx, end_idx),min(end_idx-start_idx, self.img_batch))
ここでは30~70%の範囲内のスライスを使っていますね。訓練時は範囲内からバッチサイズ数の画像を、評価テスト時には範囲内の全体の画像をランダムサンプリングしています。いずれもrandom.sampleなのは、ADLは分布の学習をしているからで、CTスキャンの順序は見なくて良いからです。これはウィルコクソンの符号順位検定が、サンプルに対し独立であることを仮定していることと関係している、とも考えられます。
ウィルコクソンの符号順位検定のを実装から理解する
ウィルコクソンの符号順位検定の理論はWikipediaに譲るとして、ここではざっくりとした実装の理解を見ていきましょう。
import numpy as np
from scipy.stats import wilcoxon
w, p = wilcoxon(array, alternative='greater')
ADLの実装ではこのようなコードを使っています。これは、arrayの中央値が0より大きいかどうかの有意性を検定するものです。p値が低いほど有意になります。例えば
>>> wilcoxon(np.array([0, 0.1, 0.2, 0.1, 0.2, 0.3]), alternative="greater")
WilcoxonResult(statistic=15.0, pvalue=0.020613416668581838)
という明らかに正によっているケースはp値が0.02と低く出ますし(より高い有意水準にあることを示します)、
>>> wilcoxon(np.array([0, 0.1, 0.2, -0.1, -0.2, -0.3]), alternative="greater")
WilcoxonResult(statistic=5.0, pvalue=0.7518787627778685)
このように正にも負にも寄っているケースは、p値は0.75と有意ではないことを示しています。
ADLでは各スキャンの画像が、Positiveなら1周辺、Negativeなら-1周辺の値を出力するように学習します。つまり、すべてのスキャン画像の出力ベクトルyに対し、wilcoxon(y, alternative='greater')を実行すれば、COVID-19がPositiveかどうかの検定を行えるわけです。またp値を吐き出せるため、どの程度の有意水準かも同時に計測できます。これが統計的検定により説明可能なモデルのキーとなる要素です。
ウィルコクソンの符号順位検定の実装
ADL内のウィルコクソンの符号順位検定の実装は以下の通りです。
def wilcoxon_rank_test(pop):
postive_pop = pop[(pop >= 1 - np.sqrt(0.16) * 2) & (pop <= 1 + np.sqrt(0.16) * 2)]
negative_pop = pop[(pop >= -1 - np.sqrt(0.16) * 2) & (pop <= -1 + np.sqrt(0.16) * 2)]
total_pop = len(postive_pop) + len(negative_pop)
if total_pop == 0:
return 1.0
else:
w, p = wilcoxon(np.concatenate((postive_pop, negative_pop)), alternative='greater')
return p
検定に行く前に外れ値の除去を行っています。$(\mu-2\sigma, \mu+2\sigma)$の範囲外を外れ値とみなして除去します(もしかするとこのコードの√0.16は0.2が正しいかもしれません)。このコードでは「出力がPositveかどうか」の検定のみ行っています。テスト時はこれでOKです。
評価(Validation)時は、False PositiveとFalse Negativeの両方を考えるため、PositiveとNegativeの画像に対し、
for pos_img in val_loaders['pos']:
pos_img = pos_img.cuda().squeeze(0)
pos_output = model(pos_img)
pop = pos_output.cpu().flatten().detach().numpy()
p_value = wilcoxon_rank_test(pop)
if p_value < 0.01:
pos_acc += 1 # こっちが正しい
pred_label.append(1)
else:
pred_label.append(0)
for neg_img in val_loaders['neg']:
neg_img = neg_img.cuda().squeeze(0)
neg_output = model(neg_img)
pop = neg_output.cpu().flatten().detach().numpy()
p_value = wilcoxon_rank_test(pop)
if p_value < 0.01:
pred_label.append(1)
else:
neg_acc += 1 # こっちが正しい
pred_label.append(0)
としています。PositiveとNegativeの有意水準1%で評価していますね。この水準は5%などでもいいと思います。
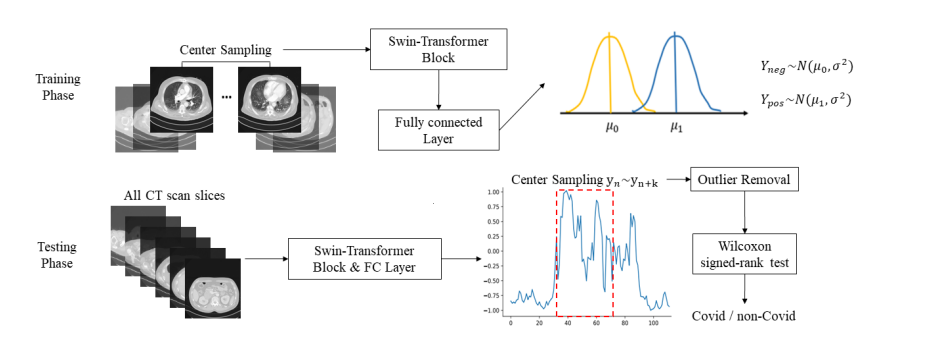
これが実装のADLのアウトラインになります。
Convolutional CT-Aware Transformer(CCAT)
ADLが統計的検定を使った説明可能なモデルでした。2つ目のCCATは、2つのTransformerを使ったEnd-to-Endのアーキテクチャです。こちらはとにかく全部のスライスを使って、空間方向とスライス方向の2つのTransformerで組み合わせるというパワープレイです。こちらのほうがわかりやすいかなと個人的に思います。
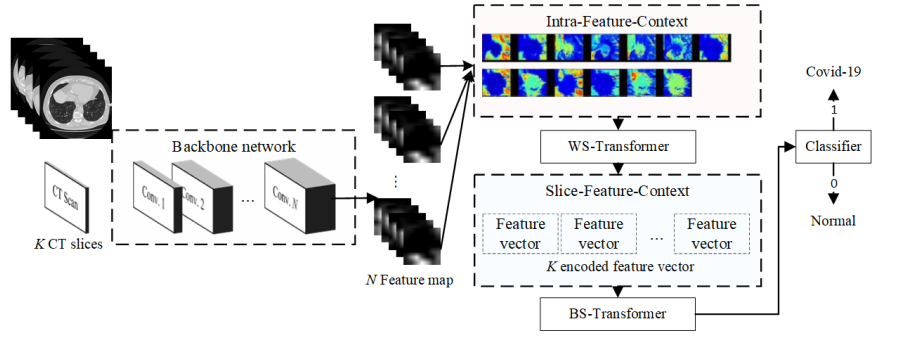
Within-Slice-Transformer(WS-Transformer)と Between-Slice-Transformer(BS-Transformer)
CCATではWS-TransformerとBS-Transformerの2つが登場します。前者は空間方向、後者はスライス方向のTransformerです。
論文読んでもよくわからなかったので、コードを見たら理解できました。このリポジトリは訓練時のコードが見つからなかったのですが、モデルの定義にそれっぽいものがありました。簡略化して書きます。
lstm_i, module_outputs = [], []
for k in range(len(X['img'])):
# self.encoder : バックボーンのネットワーク
x = self.encoder(X['img'][k].to(self.device, non_blocking=True))
# WS-Transformer : 空間方向
# self.reshape : 'b c h w -> b (h w) (c)'
x = self.spatial_transformer(self.reshape(x))
# lstm_i : スライス方向の特徴量を集める
lstm_i.append(x)
module_outputs.append(x)
feat = torch.stack(lstm_i)## time-seq x batch x feat-dim
feat = feat.permute(1,0,2) # batch x time-seq x feat-dim
# BS-Transformer : スライス方向
feat = self.transformer(feat)
module_outputs.append(feat)
# Concatenate current image CNN output
X = torch.cat(module_outputs, dim=-1)
X = self.inter_feat(X)
このコードでの、self.spatial_transformerがWS-Transformer、self.transformerがBS-Transformerにあたるモデルです。最初にサンプル単位でTransformerで特徴量を取ったら、それをスライスごとに積み重ねて軸を入れ替え、スライス方向のTransformerをしたというだけです。コードで見るとシンプルですね。
Transformerの後はMLPを連続させます。先程のコードには出てきませんでしたが、self.inter_featのあとにself.clsを入れます。
self.inter_feat = nn.Sequential(
nn.Linear(in_feat_dim*args.FRR+in_feat_dim, args.n_features, bias=False),
nn.LeakyReLU(inplace=True),
)
self.cls = nn.Sequential(
nn.Linear(args.n_features, args.n_features//2),
nn.Dropout(0.5),
nn.LeakyReLU(inplace=True),
nn.Linear(args.n_features//2, args.n_features//4),
nn.Dropout(0.5),
nn.LeakyReLU(),
nn.Linear(args.n_features//4, 2)
)
最終層が2層なのでPositive、Negativeの両方で推論しているのでしょうか1。WS-Transformer、BS-TransformerともにVision Transformerを使っていました。
定量評価
ADL
ADL(ウィルコクソンの符号順位検定を使う方)ではスライスの幅が重要なハイパーパラメータになっています。AUCでは20%のスライスが最高となりましたが、十分なサンプルサイズを確保するために40%としたそうです。
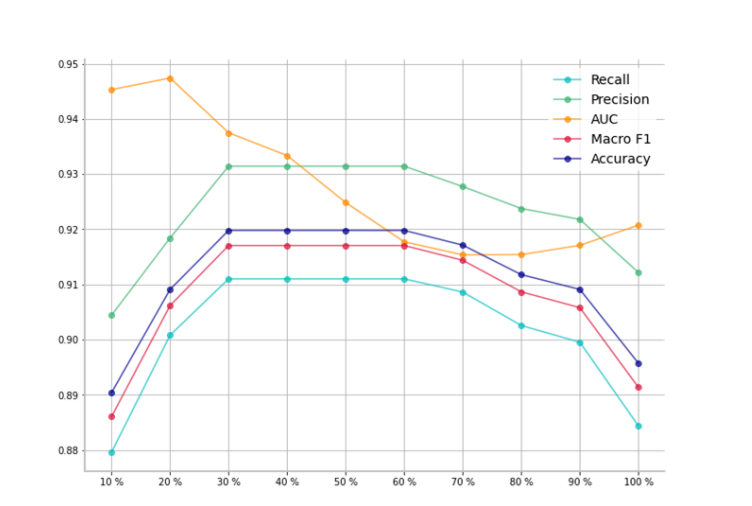
スライスの幅を取りすぎるとPrecision、Recallともに悪化します。これはCTスキャンの両サイドのスライスがCOVID-19に関係なく、分布の検定にとってはノイズデータになってしまっているからだと思われます。
CCAT vs ADL
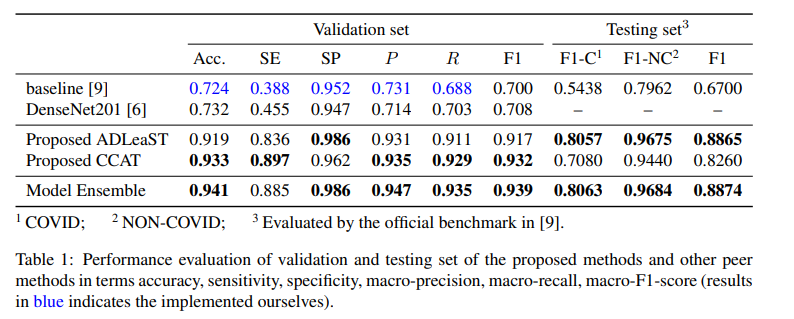
Validation setではCCATがADL(ADLeaST)をわずかに上回りましたが、テストデータではCCATの性能が大幅に悪化しました。この理由は、CCATではCTスキャンのスライス選択をしていないためと書かれていました2。適切なスライス範囲の選択と、統計的な検定をしたADLのほうがテストデータに対してロバストであったことが示されています。
ベースラインやDenseNet201を大きく超えた性能になっているのが良いです。
外れ値(OOD)による可視化の失敗
ADLのモデルをベースにEeign-CAMで可視化したものがこちら。
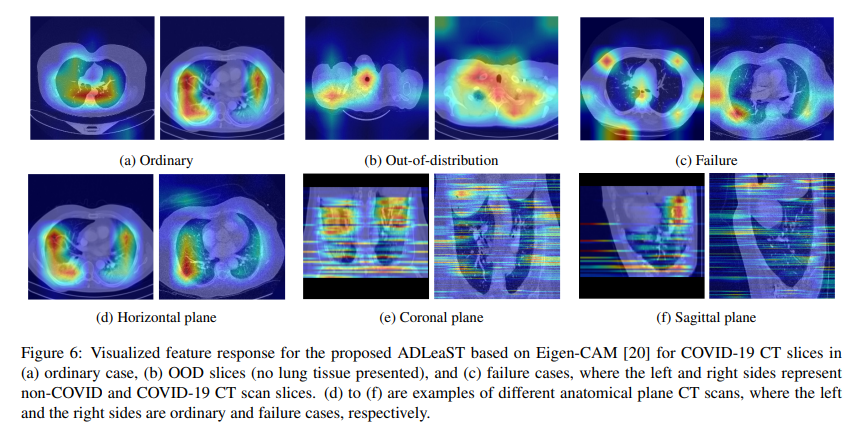
(a)~(c)は左がnon-COVID、右がCOVIDです。外れ値対策が重要で、外れ値が増えるとb, cのように可視化が失敗してしまいます。(d)~(f)は異なる断面です。左が可視化に成功したケース、右が失敗例です。
まとめと感想
この論文ではADLとCCATという2つの手法を紹介しました。CCATはCTスキャンや動画のような、複数のフレームにまたがるジャンルで汎用的に使える手法でしょう3。一方でADLは外れ値対策や統計的検定による説明が必要になったときに、ディープラーニングの手法に落とし込む画期的な方法ではないかと思われます。特にp値が出てくるとありがたいことが多々あります。
時事ネタとしてもTransformerの応用としても、伝染病の枠を超えて非常に活用しやすい研究と言えるでしょう。
告知
このアドベントカレンダーが本になりました!
https://koshian2.booth.pm/items/3595424
Amazonでも扱いあります詳しくは👉 https://shikoan.com
-
自分の注釈。もしかしたらスレッショルドチューニング的なことをやっているのかもしれない。訓練コードがなかったり、2層で出力しててもテスト時に使っているのは1層だったりと、CCATのコードはやや雑。ADLのコードはしっかりしていたが、作者が異なるらしい。あんまり深く考えないでおこう。 ↩
-
自分の注釈。CCATはスライスを全部使うのがメリットなのに、なぜスライスの選択の問題が出てくるのか謎。もしかしたらValとTestでスキャンしている範囲が異なるなどの、データミスマッチの問題があったのかもしれない。 ↩
-
バックボーンでスライス単位の特徴量を取っているので、空間方面のTransformerはひょっとしたら冗長かもしれない。スライス方面のTransformerは意義あると思う。 ↩