最近、Computer Vision API を触っていて使い方を把握できてきたと共に、予想以上の性能の高さに驚いたのでせっかくだからまとめてみることにしました。
Computer Vision API とはそもそも何なのか、なぜすごいのか、実際使ってみるとどれほどの実力を叩きだすのかをご紹介した後、コードもお見せしたいと思います。
この記事を通して、コードを数行書くだけで手軽にこんなにパワフルな画像認識機能が使えるんだということが伝わり、ぜひ試していただけたらと思います。
そもそも、Computer Vision APIって何?
Microsoft が出している、REST で画像を投げると JSON 形式で画像を分析した結果を返してくれる API サービスのことです。
画像に写っている物体を認識しタグを出力するのはもちろん、画像上の物体の状態や状況を動詞や形容詞でタグとして出力してくれます。
(ex. water, sport, swimming, man)
さらに、それらをベースに画像に1文でもっともらしいキャプションを付けてくれます。
(ex. a man swimming in a pool of water)
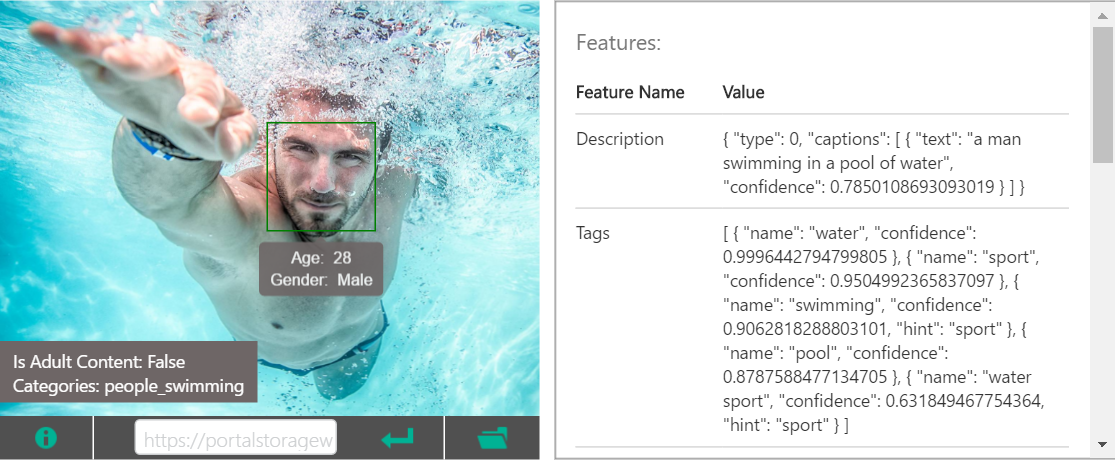
(公式ページ参照)
裏では Microsoft Research の最先端の研究成果を盛り込んだ最新の画像認識エンジンが動いており、それが一般ユーザー向けに開放されています。
Computer Vision API のバックで活躍する Microsoft Research の実力
最先端のといっても、そもそも Microsoft Research がどれほどこの分野に強いのかというのが気になります。
画像認識の分野では ImageNet という、膨大な量の画像と付随するアノテーションをオープンなデータセットとして公開しているプロジェクトがあります。そこが主催の Large Scale Visual Recognition Challenge というざっくり言うと大量の画像データの画像認識精度を競い合うコンペティションがあって、その一番最新の大会(ILSVRC 2015)で、MSRA (Microsoft Research Asia)は、Google 等の研究部門や海外トップ大学の研究チームがこぞって競い合う中、多数のタスクで1位を取ってるんですね。

(ILSVRC2015 Resultsからの引用)
学生時代にこの分野に近めな研究室にいたので、MS は"強い論文"をよく出しているというイメージはぼんやり持っていましたが、今回調べることで具体的な状況を知れてよかったです。
この記事の最後に Computer Vision API に使われている関連論文も引用していますが、そちらを見てみると普通に最新の研究成果が使われていたりするので、だからすごいのかと納得です。
どれぐらいの精度なの?
実際に自分の画像を投げて分析結果を見てみましょう。
今回は、Computer Vision API の画像認識機能の中で特に個人的に有用で面白いと思った、キャプション生成機能とタグ生成機能をご紹介します。
勉強のために、今回は画像を上げて分析結果を表示する簡易 Web サービスを作って Azure 上に展開してみました。
(コードを Git に上げて次回はそれについてもまとめたい)
以下、スクショと感想です。
まずは カフェで取ったコーヒーとパウンドケーキの写真

ケーキ1ピースとカップに入ったコーヒー1つ、と見事に正解を当てられました。
タグを見てみると、テーブルやチョコレートや、食べかけを示す eaten まで入っていてびっくり。
次は 旅先で取った何気ない写真

生成されたキャプションを見ると、教会の前に車が停められている、とまたまた見事に当てられました。
画像内での物体の位置関係までキャプション内で表現されているのには感動しました。
こうやって出力されるタグを活用して、アプリや Web サービスに画像検索機能をつけたり、グルーピングを行ったりというのは簡単に実装できそうです。また Web サービス内に大量の画像が存在する場合は分析をかけてタグ総数でランキング付けをしてみるのも新たな洞察が得られて面白そう。
どう実装するの?
どのようなコード、どれぐらいのコード量でこれが実現できるのかをお見せしたいと思います。
Python2 系で書いてみました。Python3 系やC#, Java, JavaScript, Objective-C, PHP, Rubyの実装サンプルはこちらの下部に載っています。
import httplib
import urllib
image_url = ''
headers = {
# Request headers
'Content-Type': 'application/json',
# 'Content-Type': 'application/octet-stream',
'Ocp-Apim-Subscription-Key': 'Your key',
}
params = urllib.urlencode({
# Request parameters
'visualFeatures': 'Description',
# 'visualFeatures': 'Categories,Tags, Description, Faces, ImageType, Color, Adult',
# 'details': 'Celebrities'
})
conn = httplib.HTTPSConnection('api.projectoxford.ai')
body = """{'url': '%s'}""" % (image_url)
conn.request("POST", "/vision/v1.0/analyze?%s" % params, body, headers)
response = conn.getresponse()
caption_data = response.read()
conn.close()
上記の例では画像URLを投げていますが、
直接画像データを投げることも可能です。
切り替えは、headersの中のContent-Typeの値を変更することで可能です。
'Content-Type': 'application/json' 画像URLを与える場合
'Content-Type': 'application/octet-stream' 直接画像データを与える場合
なので、直接データを投げる場合はoctet-streamを指定して、
下記の部分を
body = """{'url': '%s'}""" % (image_url)
conn.request("POST", "/vision/v1.0/analyze?%s" % params, body, headers)
を下記に変更でいけます。
file_name = ''
img = open(file_name, 'rb').read()
conn.request("POST", "/vision/v1.0/analyze?%s" % params, img, headers)
paramsでは欲しい分析結果をパラメータで指定します。
visualFeaturesに指定できる値は現段階では以下の7つです。
- Categories
- Tags
- Description
- Faces
- ImageType
- Color
- Adult
(詳しくはこちらのRequest parameters 参照)
自分の写真を分析した上記の例は、visualFeatures に Description のみ(キャプション生成機能とタグ生成機能)を指定した場合の結果となっています。
visualFeatrues にすべて指定した場合は以下のようなJSONが返ってきます。
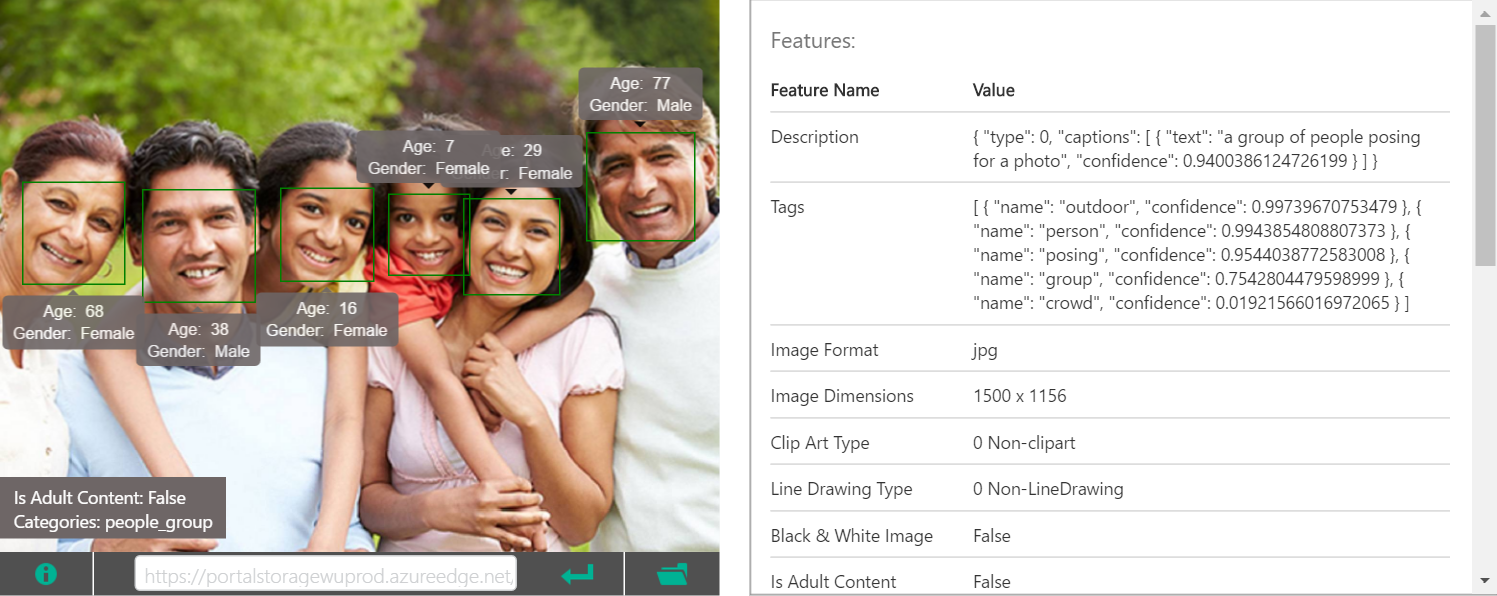
公式ページ上で使われている画像を使用した場合の結果を見てみましょう。
各タグごとの確信度やアダルト画像かのチェック、映り込んでいる人の顔の位置や性別と年齢等も得られるようになっています。
| 分析画像 |
|---|
 |
{
"categories": [
{
"name": "people_swimming",
"score": 0.98046875
}
],
"adult": {
"isAdultContent": false,
"isRacyContent": false,
"adultScore": 0.14750830829143524,
"racyScore": 0.12601403892040253
},
"tags": [
{
"name": "water",
"confidence": 0.99964427947998047
},
{
"name": "sport",
"confidence": 0.95049923658370972
},
{
"name": "swimming",
"confidence": 0.90628182888031006,
"hint": "sport"
},
{
"name": "pool",
"confidence": 0.87875884771347046
},
{
"name": "water sport",
"confidence": 0.631849467754364,
"hint": "sport"
}
],
"description": {
"tags": [
"water",
"sport",
"swimming",
"pool",
"man",
"riding",
"blue",
"top",
"ocean",
"young",
"wave",
"bird",
"game",
"large",
"standing",
"body",
"frisbee",
"board",
"playing"
],
"captions": [
{
"text": "a man swimming in a pool of water",
"confidence": 0.78501081244404836
}
]
},
"requestId": "your request Id",
"metadata": {
"width": 1500,
"height": 1155,
"format": "Jpeg"
},
"faces": [
{
"age": 29,
"gender": "Male",
"faceRectangle": {
"left": 748,
"top": 336,
"width": 304,
"height": 304
}
}
],
"color": {
"dominantColorForeground": "Grey",
"dominantColorBackground": "White",
"dominantColors": [
"White"
],
"accentColor": "19A4B2",
"isBWImg": false
},
"imageType": {
"clipArtType": 0,
"lineDrawingType": 0
}
}
基本的には返ってくるタグは汎用的なものになっていますが(ex. プードルではなく犬)有名人に関しては、個人特定まで出来るようになっています。
その機能を ON にしたい場合は、params 中の details で
'details' : 'Celebrities'
を指定すれば分析結果を JSON に含んでくれるようになります。
有名人判定は、約20万もの人を特定できるらしく、他の触った人から聞くとなんとデーモン小暮にも対応しているらしいです!(年齢は何歳と判定されるのだろう…?)
どうやって始めるの?
Cognitive Services の利用の際には Subscription Key が必要になります。無料試用が可能なのでこちらからご登録ください。Microsoft Account でのログインが必要となります。
登録して得られた Subscription Key をサンプルコード上の Ocp-Apim-Subscription-Key で指定してください。
有料プランもあるのでお試しではなくしっかり使いたい方は次の使用プランの項目をご覧ください。
自分でコードを書く前にまずはどんなものか試してみたいという場合は、公式解説ページを見てもらうと準備されている画像を選ぶ or 自分の画像をアップロードして確認できるようになっているのでおすすめです。
使ってみてここもっとこうすればいいのに等色々と意見やアイデアが生まれた場合は、
Give your apps a human side (Computer Vision API 開発チームが参考にするフィードバック共有ページ)をご利用ください。
こういうふうにユーザーサイドの意見を直接開発チームに届けられるのはいいですね。
各改善アイデアには投票ができるようになっていて、投票が集まれば上位に来るのでより注目を集めやすくなります。一緒に使い込んで良くしていきましょう!
使用プラン (2016/8/5 追記)
本日より、以前のお試しプラン Free に加え Standard plan が追加されました!
まだ Cognitive Services 全体が Preview 段階なので SLA やサポートはありませんが、
ビジネスユースでもご検討いただけるのではないかと思います。
| Plan | Description | Price |
|---|---|---|
| Free | 5,000 transactions per month | Free |
| Standard | 10 transactions per second | $ 1.50 per 1000 transactions |
こちらからダイレクトに Standard Plan のアカウントを立てることができます。
Standard Plan をお使いいただく場合は、Microsoft Azure の Subscription が必要となるので、もしお持ちでない方はこちらから 1か月 ¥20.500 の無料試用アカウント等もぜひお試しください。
またこちらの API を使ったビジネスインパクトのあるような使い方があればコメントでも個人的に連絡でもいいので教えてください。
個人的にとても興味があります!笑
参考 (The research behind Computer Vision API)
最後に公式ページからそのまま引っ張ってきた Computer Vision API の裏に使われている研究成果群のご紹介です。(参照公式URL)
一つ目の論文は CVPR 2015 に採択された論文ですね。CVPR はコンピュータビジョン系の国際会議でトップカンファレンスなので、かなり質とレベルが高い研究だといえます。一年前に発表されたばかりの最先端の研究がもう一般利用可能なサービスとして展開されているのは、かつてないスピード感で非常に面白いと思います。
-
Hao Fang, Saurabh Gupta, Forrest Iandola, Rupesh Srivastava, Li Deng, Piotr Dollar, Jianfeng Gao, Xiaodong He, Margaret Mitchell, John Platt, Lawrence Zitnick, and Geoffrey Zweig, From Captions to Visual Concepts and Back, CVPR, June 2015 (won 1st Prize at the COCO Image Captioning Challenge 2015)
-
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep Residual Learning for Image Recognition. arXiv (won both ImageNet and MS COCO competitions 2015)
-
Yandong Guo, Lei Zhang, Yuxiao Hu, Xiaodong He, Jianfeng Gao, MS-Celeb-1M: Challenge of Recognizing One Million Celebrities in the Real World, IS&T International Symposium on Electronic Imaging, 2016
-
Xiao Zhang,Lei Zhang, Xin-Jing Wang, Heung-Yeung Shum, Finding Celebrities in Billions of Web Images, accepted by IEEE Transaction on Multimedia, 2012
参考2 (Computer Vision API の MS 内での位置づけ)
Computer Vision API は、Microsoft の Cognitive Services というクラウドベースの API サービス群の1つで
下記5つのカテゴリのうちの Vision カテゴリに属する API です。
- Vision
- Speech
- Language
- Knowledge
- Search
Vision カテゴリ内の API は下記のようになっています。
- Computer Vision (今回はこれ)
- Emotion (画像、動画に写った人の感情を推定)
- Face (画像に写った人の年齢と性別を推定)
- Video (動画の手ぶれ補正、顔のトラッキング、動作検出、ビデオから短時間のビデオサムネイルを作成)
Computer Vision API では画像認識を含んだ以下の機能が提供されています。
- 画像認識 (今回はこれ)
- OCR (画像上の文字をテキストとして抽出)
- 画像上の注視点(ROI)を中心として指定したサイズの画像サムネイルを作成(スマホとPC向けに異なるサイズの画像を準備したい場合に使えそう)