どんなものか
A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification
自然言語処理における畳み込み層が1層のモデルを用いた文書分類にて、ハイパーパラメータやアーキテクチャの選択がどう影響するかを検証した研究。
下記について検証しています。
- 埋め込み層へ埋め込む学習済みの単語埋め込みベクトルの種類
- 畳み込み層のフィルタの窓幅と種類数
- 畳み込み層の出力特徴マップ数
- 畳み込み層の活性化関数
- プーリングの手法と、窓の大きさ
- 正則化
検証するモデル
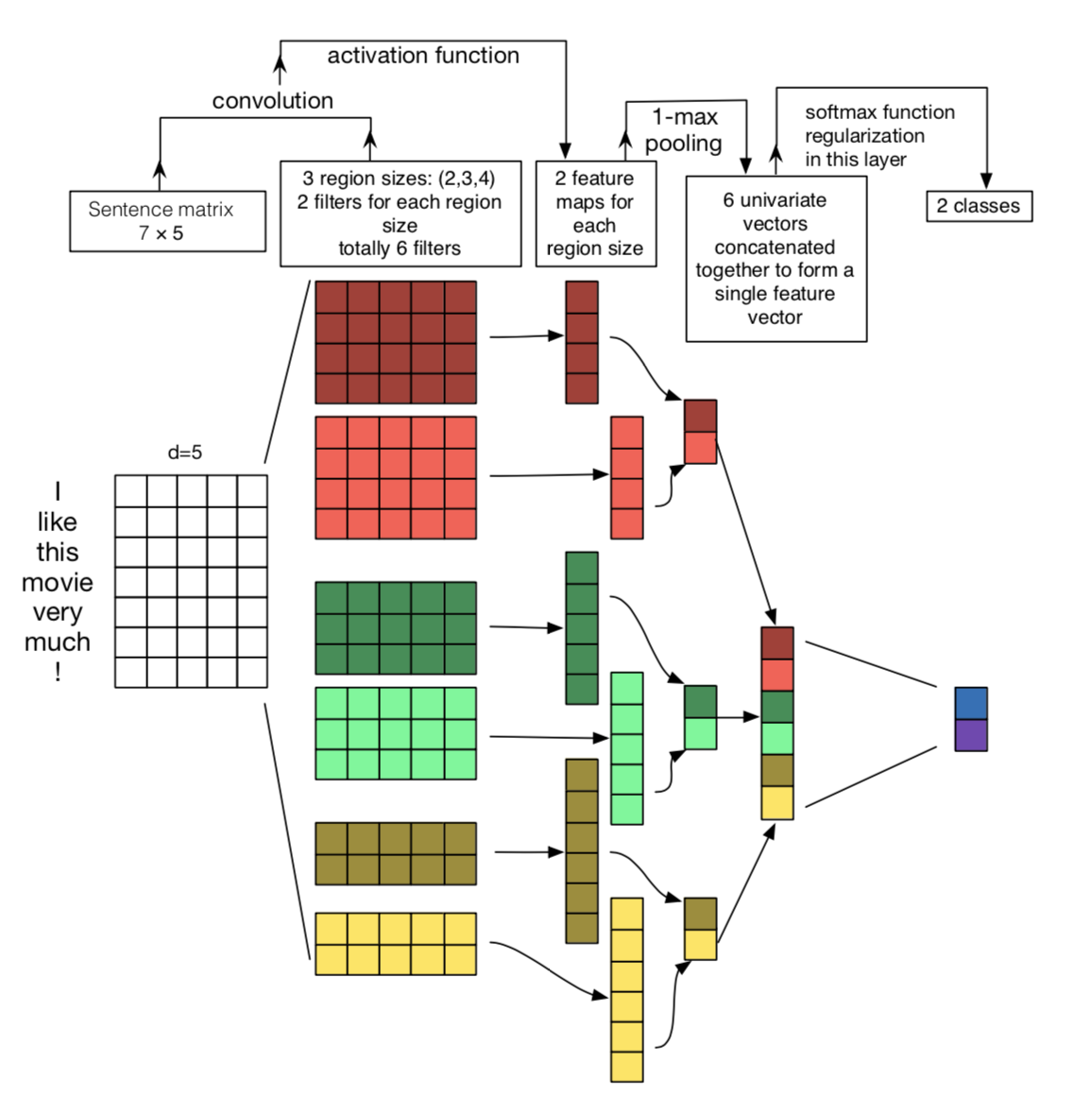
上図のように畳み込み層→プーリング層→全結合層のモデル。Kimのモデルがベースとなっています。
論文では以下の表のようにハイパーパラメータのベースラインを設定します。検証したいハイパーパラメータを選択し、それ以外は固定して変更した際の影響を調べます。
実験では正解率を算出する際に、10分割交差検証を複数回実行し最大、最小、平均値を求めています。

実験に使うデータセットはKimらの論文にもある
MR、SST-1、SST-2、subj、TREC、CR、MPQA、Opi、Ironyの9種類です。
検証結果
埋め込み層へ埋め込む学習済みの単語埋め込みベクトルの種類
結論としては
- 入力文をone-hot表現に変換して畳み込み層に入力するより、学習済みの単語埋め込みベクトルを埋め込み層に埋め込む方が正解率が上がる。
word2vec、GloVeの学習済みの単語埋め込みベクトル(300次元)を埋め込み層に埋め込み実験を行なっています。学習中に埋め込み層の更新をします。
結果は以下の表のようになっています(Non-static GloVe+word2vecは両者を連結した600次元のベクトル)。各セルは「平均正解率(最小正解率, 最大正解率)」で表記されています。

また以下の表は入力文をone-hot表現に変換し学習した結果です。

word2vec、GloVeのどちらを使うべきかはデータによって異なりますが、one-hot表現に変換した場合より正解率は上がると述べています。
畳み込み層のフィルタの窓幅と種類数
結論としては
- まずフィルタが1種類の場合で検討し、その窓幅は1~10が適切である。
- 上記の適切な窓幅付近のサイズでフィルタの種類を増やすと正解率が上がりやすい。
フィルタの種類が1種類の場合の結果は以下の表の通りです。
例えばMRデータセットであれば窓幅が7の時に最も平均正解率が高くなっています。

ですが長文が含まれるCRのようなデータセットでは窓幅をより大きくすることで正解率が上がる可能性があると述べています。以下の表は各データセットの文の長さの平均値と最大値についてです。

以下の表はMRデータセットでフィルタの種類を複数用意した場合の実験結果になります。
MRデータセットでは窓幅が7のフィルタが適切でした。その窓幅7のフィルタを4種類(7, 7, 7, 7)に増やした場合の正解率が最も高いことが分かります。逆に7から離れた窓幅のフィルタ3種類(3, 4, 5)の場合は、フィルタの種類が増えているにも関わらず、窓幅7のフィルタ1種類を用いた場合よりも正解率が下がっていることが分かります。

畳み込み層の出力特徴マップ数
結論としては
- 各フィルタの出力特徴マップの枚数は100~600の中で検討する。
出力特徴マップ数を変化させた場合の実験結果は以下の図の通りです。ベースラインの100枚と比較し正解率の変化率をプロットしています。
適切な枚数はデータセットによって異なりますが、どれも600を超えると精度が上がりにくいこと、枚数が増えれば計算時間も増えることから100~600が適切と述べています。

畳み込み層、全結合層の活性化関数
結論としては
- relu、tanh、Idenを用いるのが良い。
以下は各データセットと活性化関数ごとの正解率の結果です。

MPQAデータセットのみSoftPlusの正解率が最も高いですが、そのほかのデータセットではrelu、tanh、Idenのいずれかの正解率が高くなりました。
プーリングの手法と、窓幅の大きさ
結論としては
- 最大値プーリングの場合は1-max poolingがよい。
- k-max poolingを検証した結果1-max poolingが最も良い。
- 平均値プーリングと最大値プーリングでは最大値プーリングの方が良い。
以下の表はプーリング層の窓幅を変化させた場合の実験結果です。
各フィルタごとの出力特徴マップ全体を窓幅とし最大値を1つ選ぶ1-max poolingがどのデータセットでも高い正解率を出しています。

以下の表はk-max poolingのkの値を変化させた場合の実験結果です。
例えば5-max poolingであれば出力特徴マップから最大値を5つ選ぶことになります。
出力特徴マップから最大値を1つえらぶ1-maxがどのデータセットでも高い正解率を出しています。

また、論文では最大値でなく平均値プーリングを適用した実験もしています。平均値プーリングを用いると時間がかかるため全てのデータセットでの実験が完了していませんが、CRとTRECデータセットにおいて最大値プーリングよりも正解率が低くなったと述べています。
正則化
結論としては
- dropout、l2 norm constraintによる正則化を強くしてもあまり正解率に影響を与えなかった。
- dropoutは0.0~0.5に設定する。畳み込み層のフィルタ数を増やして正解率が下がった場合、dropoutを上げると正解率が上がる可能性がある。
以下の図は、全結合層のdropoutが0.5の場合をベースラインとして0~1.0で変更した際の正解率の変化率を表しています。Noneとあるのはdropoutとl2 norm constraintによる正則化を行なっていない場合です。
dropoutを0.1~0.5に設定することでデータセットによっては正解率がわずかに向上することが分かります。

以下は畳み込み層のフィルタの数を100から500に増やした場合です。dropoutが0.7の時SST-1で正解率が上がっていますが、これはフィルタ数を増やしたことによる過学習を正則化することで抑えられたためと述べています。

以下の図はベースラインを3として、l2 norm constraintを変化させた際の正解率の変化率を表しています。Opiでは1に設定した場合に正解率の変化率が0.5%ですが、他のデータセットでは制限を強くすると正解率が下がるものが多いです。

以下は畳み込み層のdropoutが0.5の場合をベースラインとして0~1.0で変更した際の正解率の変化を表しています。
dropoutを上げると正解率が下がりやすいことが分かります。

最後に
論文の結論では今回の実験より1層のCNNモデルを文書分類に適用する際のアドバイスがのっています。
- まずは本研究でベースラインとして設定したハイパーパラメータで実験を始める。入力文をone-hot表現に変換したものを畳み込み層に入力するよりは、埋め込み層にword2vecやgloveの学習済みの単語埋め込みベクトルを埋め込んで学習させた方が良い。学習中に埋め込み層を更新した方が良い。(学習データが多い場合はone-hot表現を用いても良い精度が出るかもしれない)
- 畳み込み層のフィルタはまず1種類で実験し、1~10の間で適切な窓幅を探す。CRデータセットのように長文が含まれる場合は窓幅を大きくして探すことも考える。適切な窓幅が決まったら、それに近い窓幅のフィルタで種類を増やす。
- 出力特徴マップ数は100~600で適切なものを探す。探す際は正則化を弱くしておく。枚数を増やし精度が下がった場合は正則化を強くしてみる。出力特徴マップ数が増えると学習時間も増えていくので注意。
- 活性化関数はrelu、tanh、Idenから選ぶと良い。
- プーリング層には1-max poolingを用いると良い。
- モデルの評価を行う際には交差検証を複数回行い、精度の分散や平均を考慮する。