はじめに
mnist手書き文字を生成するチュートリアルから、実際に256x256pixの高精度画像を作るまでの過程をまとめた記事です。
DCGANの実装にはkerasを用います。
PGGANの実装にはpytorchを用います。
実装難易度はかなり高めなはずなので、そこだけ注意してください。
計算式の解説はしません。キーワードだけ置いておくので、うまく調べて理解してください。
この記事は他の寄稿者への恩返しの記事です。この記事を読んで、GANに興味を持つ方が増えていくことを私は願っています。
この長い長い記事の最終地点はこのような製品に行きつきます。
前提
python (目安としてクラスまで)
keras (画像識別モデルを自由に作れるくらい)
pytorch (上に同じく)(私はGANのために習得した)
numpy (調べて使えれば大丈夫です)
GANの基礎知識
諦めない心 (最重要)
時間
環境
推奨: colab環境
つよつよGPU持ってるならそれでも可
注意点
・もう一度言いますが初学者が踏み込んでいい領域じゃないです。
・一回のモデルの学習に多大な時間がかかります
・どこかミスると1日2日は無駄になります。コピペするなら堂々としてください。
・GANは不安定なので、うまくいかないことの方が多いです。
・病みます。ほどほどに。
GANの説明
GANとは
Generative Adversarial Network(敵対的生成ネットワーク)の略語
GANは、虚無から画像を生み出すことができるすごいやつ
構造はこんな感じ
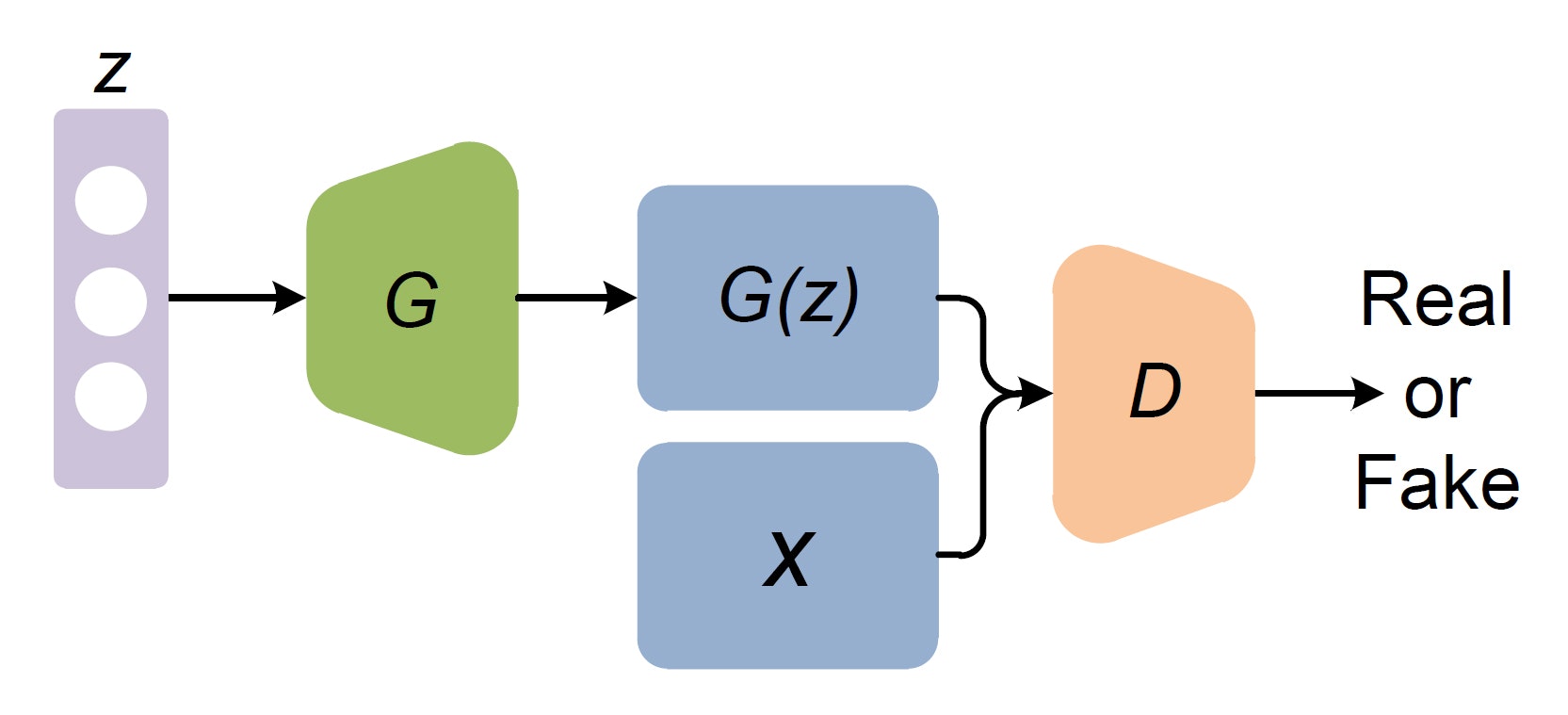
GはGenerator(生成機)、DはDiscriminator(識別機)の略です
zはノイズ(数学的にはベクトル)です
Xは教師データのことです
Gはノイズを基に画像を生成
Dは本物の画像(X)とfake画像(G(z))を判別する
誤差をGとDに伝える
一番上から繰り返す
こうすると、GはDをだませるような画像を生成できるようになっていきます。
GとDは互いに成長していくので、精度が少しずつ向上していくわけです。
このやりとりは、偽札を作る犯罪者とそれを見破る警察にたとえられます。
DCGANの仕組み
DCGANはGANのGとDに対して、CNNの構造を取り入れたネットワークです。
ほかの発展形のGANの祖と言える存在です。
最適化関数は一般的にAdam、lossは平均二乗誤差
普通ですね(白目)
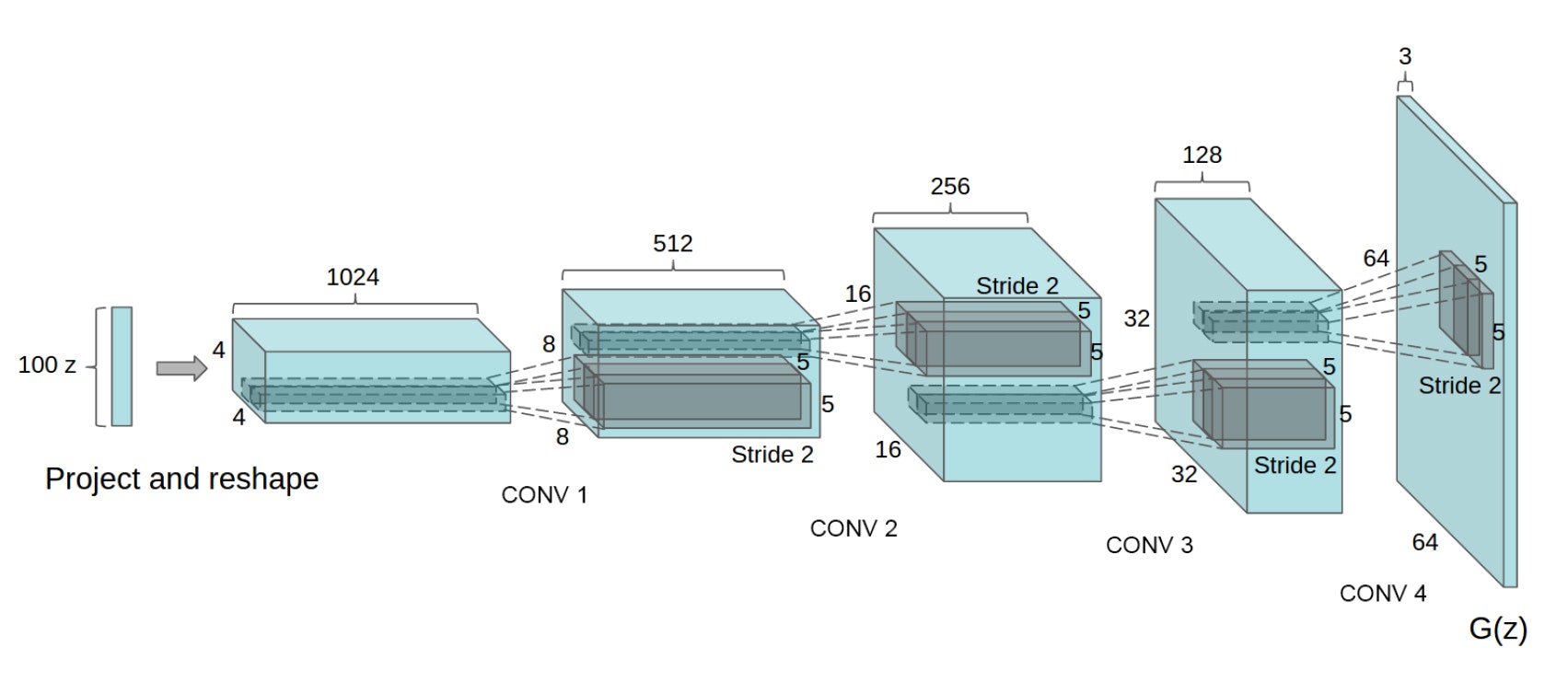
基本構造は上の画像の通り。解像度を少しずつ上げていく転置畳み込みをしています
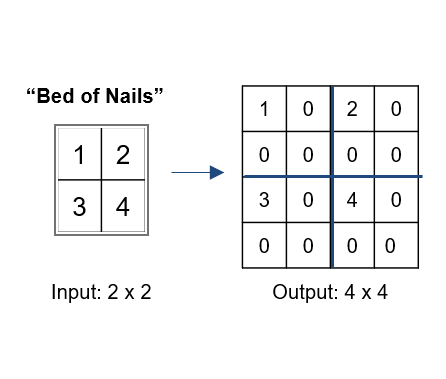
イメージです。0となっている部分にも値を当てはめる処理をすることもあるみたい
私からのDCGANの説明は以上です。いろいろ端折ってるのでわからないところは調べてください(他力本願)
PGGANの仕組み
PGGANは、低解像度から段階的に解像度を上げて、高解像度の画像を生成するGANです。
段階的に解像度を上げる仕組みのおかげで、安定して高解像度の画像を生成することに成功しています。DCGANでは解像度64x64程度が限度でしたが、PGGANでは解像度1024x1024まで生成することが可能です。
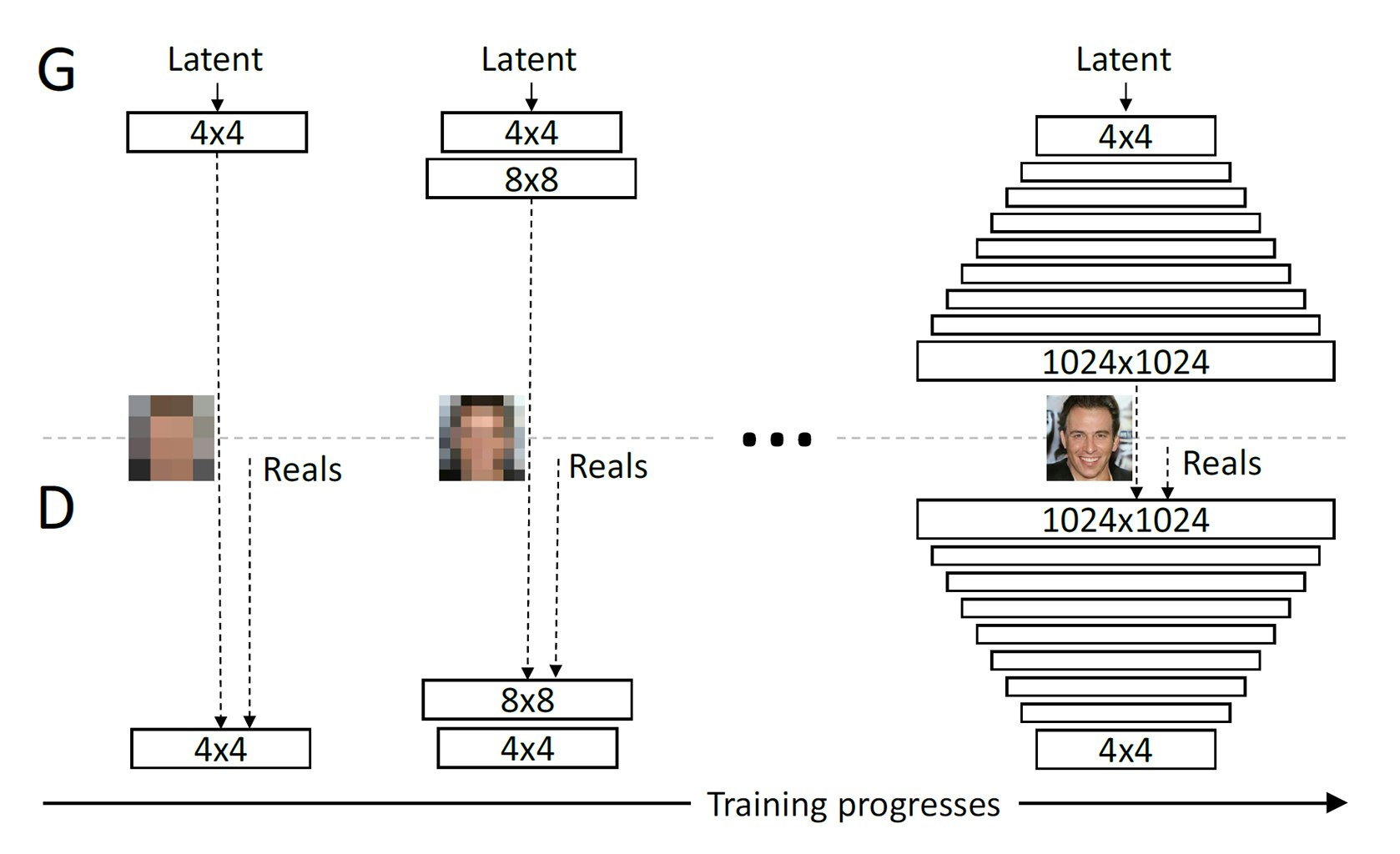
PGGANにはPixelwisenormalization、MinibatchStd、WGAN-GP loss、equalizedrateなどの工夫が施されているが、詳しい解説は省く(後述のソースコードには実装されている)
こういったサイトに解説が載っている。式が絡むのでここで詰むくらいならおとなしくコピペすることをお勧めする。
https://blog.negativemind.com/2020/06/27/progressive-growing-gan/
今回の演習は256x256の解像度で行います。
その他の主要なGAN
cGAN
条件付きGAN、画像の特徴をある程度決めて生成できる。どのGANにも組み込める
styleGAN
現状(2021/4/9)で最も自然で高精度な画像を生成できる。また、学習データ間に共通点がなくても高精度で生成できる(例として猫の画像と、人間の画像どちらを作るか指定して同じモデルで生成できる)
ただし一般的に学習コストが非常に重い。数千万円のGPU数機を動かしてようやくまともに学習できるほどなので、一般人は触れる機会すらない。
cycleGAN
二つのGAN構造を組み合わせて作られたモデル。deepfakeなどの技術に応用されている。

実装と考察
学習を始める前の注意点
GANの学習は不安定なので、Generatorが突然不安定な画像ばかり生成するようになることがある。ここではその事例を見ていく。
Mode Collapse
GANには通常のn値分類モデル学習で発生するような勾配消失問題の代わりとして、同じ画像しか生成しなくなる現象が報告されている。

上記は0~9の画像を生成するはずのモデルだったはずが、1と8しか出さなくなっている。
この現象が起きる理由は意外に単純で、1と8さえ出しとけばdiscriminatorをより楽にだませるということをGeneratorが知ってしまい怠けてしまっているような状態をになっている。
この現象は開発する際の大きな障壁となるので、しっかり覚えておいたほうがいい。すべてのGANで起こりうる問題である。例外はあるが、これが起こってしまう原因として、学習率が高すぎることがあげられることがある。予兆はなく突然起こるので、対策は容易ではない。PGGANの実装では、一応対策してあるのでその点はご心配なく。
Discriminator強すぎ問題
discriminatorが強すぎると、generatorがdiscriminatorの学習速度に追いつかず、学習が崩壊してしまう。一般的に、単に2値分類であるdiscriminatorのほうが強くなりやすい性質があるため、discriminatorのモデルをあえて弱くするなどして対応することがある。
今回実装するPGGANでは、この問題は起こらない。そもそもPGGANはこの問題の解決のために生み出されたものである。この問題は最高精度に大きく関わってくる。
強力な追加手法
GANの論文などで多く紹介される強化手法を紹介します
・ノイズには一様分布ではなく、正規分布を使うこと
・Reluの代わりにLeakyRelu(alpha=0.2)を使うこと
・最適化手法はAdam一択
・学習がうまくいかないからと言って、人為的介入をしないこと
kerasでmnist手描き文字を使ったチュートリアル(DCGAN)
この演習では、DCGANを使います。簡単な方です。
colab環境前提でコードを書きます。環境が違う方は適時頑張って対応してください。
また、pathなども自身で合わせていただけると幸いです。コードは読みづらいかもです。
今回はよくあるmnist+DCGANの実装と、筆者の気分でresnetによる実装の両方を用意しました。resnetを使っているipynbファイルはgithubに上げてあるのでそちらを参照ください。
実装
# colab環境にgdriveをマウント
from google.colab import drive
drive.mount('/content/drive')
# mnist手書き文字のデータセットの用意と軽い準備
import numpy as np
from keras.datasets import mnist
import cv2
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# -1~+1に正規化
X_train = (X_train.astype(np.float32) - 127.5)/127.5
# チュートリアル
from __future__ import print_function, division
from keras.datasets import mnist
from keras.layers import Input, Dense, Reshape, Flatten, Dropout,Reshape,Add
from keras.layers import BatchNormalization, Activation, ZeroPadding2D,MaxPooling2D,GlobalAveragePooling2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import UpSampling2D, Conv2D
from keras.models import Sequential, Model
from keras.optimizers import Adam
import cv2
import matplotlib.pyplot as plt
import sys
import numpy as np
class DCGAN():
def __init__(self):
# Input shape
self.input_img_rows = 28
self.input_img_cols = 28
self.input_channels = 1
self.input_img_shape = (self.input_img_rows, self.input_img_cols, self.input_channels,)
self.latent_dim = 100
optimizer = Adam(0.00001, 0.5)
# 2値分類のための識別モデルを作成
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
# Build the generator
self.generator = self.build_generator()
z = Input(shape = self.latent_dim)
img = self.generator(z)
# discriminatorのパラメータ固定
self.discriminator.trainable = False
valid = self.discriminator(img)
self.combined = Model(z, valid)#並列結合
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
def build_generator(self):
model = Sequential()
model.add(Dense(512*7*7, input_shape=[self.latent_dim]))
model.add(Reshape((7,7,512)))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(512, kernel_size=3, strides=1, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(256, kernel_size=3, strides=1, padding="same"))
model.add(UpSampling2D((2,2)))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(256, kernel_size=3, strides=1, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(128, kernel_size=3, strides=1, padding="same"))
model.add(UpSampling2D((2,2)))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(128, kernel_size=3, strides=1, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(128, kernel_size=3, strides=1, padding="same"))
model.add(Dense(self.input_channels))
model.add(Activation('tanh')) #-1 ~ 1 に分散してくれるやつ
model.summary()
img = Input(shape=self.latent_dim)
validity = model(img)
return Model(img,validity)
def build_discriminator(self):
model = Sequential()
model.add(Conv2D(512, kernel_size=3, strides=1, input_shape=self.input_img_shape, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Conv2D(256, kernel_size=3, strides=1, input_shape=self.input_img_shape, padding="same"))
model.add(LeakyReLU(alpha=0.2))
#model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(128, kernel_size=3, strides=1, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Conv2D(64, kernel_size=3, strides=1, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
model.summary()
img = Input(shape=self.input_img_shape)
validity = model(img)
return Model(img, validity)
def train(self, epochs, batch_size=128, save_interval=500):
print("実行1")
# Adversarial ground truths
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
#コンスタントなノイズ
imagegennoise = np.random.uniform(-1, 1, (32,self.latent_dim))
for epoch in range(epochs):
# 本物の画像をbatchの数だけランダムで持ってきます
idx = np.random.randint(0, len(X_train), batch_size)
true_imgs = X_train[idx]
# batchの数だけノイズを生成し、generatorに画像を生成させる
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
gen_imgs = self.generator.predict(noise)
# 本物の画像とフェイク画像を識別機に学習させます。
d_loss_real = self.discriminator.train_on_batch(true_imgs, valid)
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# 誤差を伝搬させて、generatorを学習させます
g_loss = self.combined.train_on_batch(noise, valid)
print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
if epoch % 50 == 0:
testimg = self.generator.predict(imagegennoise)
dst = np.array((testimg * 0.5 + 0.5) * 255, np.int32) #0~255(人間に見やすく)
#32,28,28,1
dst = dst.reshape(4,8,1,28,28)
dst = dst.transpose(0,3,1,4,2)
dst = dst.reshape(4*28,8*28,1)
cv2.imwrite(f'/content/drive/MyDrive/GANstudy/2.12/createimages/test{str(epoch)}.jpg', dst)
if __name__ == '__main__':
dcgan = DCGAN()
dcgan.train(epochs=100000, batch_size=128, save_interval=500)
長いですね...重要なところだけ上から順に説明していきます。
import類
いるものを適当に入れてるだけ。多分余計なのも入ってる。若干コピペだから許してください。
init関数
画像のサイズとか指定してます。
GeneratorとDiscriminatorを定義して、コンパイルしてます。このあたりは、筆者自身過去に変な説明を受けて、理解が余計難しくなったので、今回はあえて解説はしません。コードを読んで理解するほうが早いのでそちらをお勧めします。
self.latent_dim = 100
この部分はほかのサイトでも見たことがある人もいると思いますが、100次元のノイズのことを表しています。ノイズについての説明は後で行います。
build_generator関数
generatorモデルを作成するための関数
model.add(Conv2D(256, kernel_size=3, strides=1, padding="same"))
model.add(UpSampling2D((2,2)))
この部分がいわゆる転置畳み込みの部分である。転置畳み込みは、簡単に言えばレイヤー数を下げて、特徴量マップを増やす処理である。この処理をすることで、100次元のノイズから28x28x1の一枚の画像までもっていくことが可能になる。
model.add(Dense(self.input_channels))
model.add(Activation('tanh')) #-1 ~ 1 に分散してくれるやつ
画像のチャンネル数は黒or白の一色なので、レイヤーの数を1(self.input_channelsは1)にして、28x28x1の特徴マップを作っている。(RGBを出力したいなら3になる)
画像を出力する必要があるので、出力層には-1~1を出力できる、tanh関数を使用する。
build_discriminator関数
この部分はただのCNNなので説明は省きます。強いて言うならleakyReluを使っているだけです。
train関数
学習する部分の関数
正直一個一個紹介していたらきりがないので、コードを読んで理解してください。
私はコピペしたので普通にコピペだけして理解しなくても構わないかと思います。そこまで重要なことは書いてないです。
結果と考察
まずこのモデルを動かしたときの結果から紹介します





上から順に0,500,2000,5000,18000です
5000と18000あんまり差がないですよね、これ実は精度自体の差がほぼないです。
モデルがくそ雑魚なので、限界がこんなものという感じですね
ちなみにgithubに公開されてるresnetの例では30000epoch目で

このくらいの精度を出せます。おそらくこれくらいが極限に近い精度です。
GANにはresnetが刺さりやすいです。
pytorchで本格的な生成モデルを作ってみよう(PGGAN)
この演習では、PGGANを使います。難しい方です。
正直なことを言うと、筆記時点での私の実力はここが限界なので、詳しい解説はできません。ただし、実装成功はしているので、参考になればと思います。PGGANの実装に成功している記事はほとんどないので、きっとこれだけでも誰かの役に立つと信じます。
まずはデータセットを収集します。
今回は以下のデータセットを使用しました。
https://www.kaggle.com/scribbless/another-anime-face-dataset
ときどき、明らかに使えないデータが混ざっているため、データの選別をする必要があるかもしれません。私は手動で30時間かけて90000枚すべての画像を見ました。3000枚くらいはごみデータでした。精度を上げるにはデータの選別は必須なので頑張りましょう。
厳しいよって方は人間の顔画像を使うといいでしょう。GAN 顔画像 とでも調べると、名前を忘れてしまいましたが高解像度の人間の顔画像のデータセットがヒットします。
人間の顔画像をGANで生成することは想像以上に容易なので、練習するならそっちでやるのをお勧めします。
次に、集めてきたデータを256x256(ここは任意のサイズで大丈夫ですが2の倍数が好ましいです)にreshapeしてまとめておきましょう。
そして、googledriveに収集したデータをzip形式でまとめて置いておきましょう。
ここまでの話を理解できない方はこの先に進むことをお勧めしません。応用力がためされる内容になっているので、無駄足の可能性があります。
以下、コードです。解説はありません。
from google.colab import drive
drive.mount('/content/drive')
!cp "/content/drive/My Drive/animefacemini.zip" .
!unzip "animefacemini.zip"
モデル定義
import torch
from torch import nn
from torch.nn import functional as F
import torchvision
import torchvision.transforms as transforms
import cv2
import numpy as np
import random
from time import sleep
# PixelNormalization Module
class PixelNorm(nn.Module): # 修正点1
def forward(self, x):
eps = 1e-8
return x / ((torch.mean(x**2, dim=1, keepdim=True) + eps) ** 0.5)
# equalized larning rate
class WeightScale(nn.Module): # 修正点2
def forward(self, x, gain=2):
c = ( (x.shape[1] * x.shape[2] * x.shape[3]) / 2) **0.5
return x / c
# バッチの多様性を考慮
class MiniBatchStd(nn.Module):
def forward(self, x):
std = torch.std(x, dim=0, keepdim=True)
mean = torch.mean(std, dim=(1,2,3), keepdim=True)
n,c,h,w = x.shape
mean = torch.ones(n,1,h,w, dtype=x.dtype, device=x.device)*mean
return torch.cat((x,mean), dim=1)
# 畳み込み処理回りが煩雑だからモジュール化
class Conv2d(nn.Module):
def __init__(self, inch, outch, kernel_size, padding=0):
super().__init__()
self.layers = nn.Sequential(
WeightScale(),
nn.ReflectionPad2d(padding),
nn.Conv2d(inch, outch, kernel_size, padding=0),
)
nn.init.kaiming_normal_(self.layers[2].weight) #Heの初期化
def forward(self, x):
return self.layers(x)
class ResBlock(nn.Module):
def __init__(self, inch, outch, kernel_size, padding=0):
super().__init__()
self.conv1 = Conv2d(inch, outch, 3, padding=1)
self.relu1 = nn.LeakyReLU(0.2, inplace=False)
self.pixnorm1 = PixelNorm()
self.conv2 = Conv2d(outch, outch, 3, padding=1)
self.relu2 = nn.LeakyReLU(0.2, inplace=False)
self.pixnorm2 = PixelNorm()
self.relu3 = nn.LeakyReLU(0.2, inplace=False)
self.shortcut = nn.Conv2d(inch, outch, kernel_size=(1, 1), padding=0)
def forward(self, x):
h = self.conv1(x)
h = self.relu1(h)
h = self.pixnorm1(h)
h = self.conv2(h)
h = self.relu2(h)
h = self.pixnorm2(h)
x = self.shortcut(x)
y = self.relu3(h + x)
return y
# Generatorの連結モデルを定義
class ConvModuleG(nn.Module):
'''
Args:
out_size: (int), Ex.: 16 (resolution)
inch: (int), Ex.: 256
outch: (int), Ex.: 128
'''
def __init__(self, out_size, inch, outch, first=False):
super().__init__()
if first:
layers = [
Conv2d(inch, outch, 3, padding=1),
nn.LeakyReLU(0.2, inplace=False),
PixelNorm(),
Conv2d(outch, outch, 3, padding=1),
nn.LeakyReLU(0.2, inplace=False),
PixelNorm(),
]
else:
layers = [
nn.Upsample((out_size, out_size), mode='nearest'),
Conv2d(inch, outch, 3, padding=1),
nn.LeakyReLU(0.2, inplace=False),
PixelNorm(),
Conv2d(outch, outch, 3, padding=1),
nn.LeakyReLU(0.2, inplace=False),
PixelNorm(),
]
self.layers = nn.Sequential(*layers)
def forward(self, x):
return self.layers(x)
class ConvModuleD(nn.Module):
'''
Args:
out_size: (int), Ex.: 16 (resolution)
inch: (int), Ex.: 256
outch: (int), Ex.: 128
'''
def __init__(self, out_size, inch, outch, final=False):
super().__init__()
if final:
layers = [
MiniBatchStd(), # final block only
Conv2d(inch+1, outch, 3, padding=1),
nn.LeakyReLU(0.2, inplace=False),
PixelNorm(),
Conv2d(outch, outch, 4, padding=0),
nn.LeakyReLU(0.2, inplace=False),
PixelNorm(),
nn.Conv2d(outch, 1, 1, padding=0),
]
else:
layers = [
Conv2d(inch, outch, 3, padding=1),
nn.LeakyReLU(0.2, inplace=False),
PixelNorm(),
Conv2d(outch, outch, 3, padding=1),
nn.LeakyReLU(0.2, inplace=False),
PixelNorm(),
nn.AdaptiveAvgPool2d((out_size, out_size)),
]
self.layers = nn.Sequential(*layers)
def forward(self, x):
return self.layers(x)
class Generator(nn.Module):
def __init__(self):
super().__init__()
# conv modules & toRGBs
scale = 1
inchs = np.array([512/16,512,512,512,512,256,128], dtype=np.uint32)*scale # inputするレイヤー数(追加分)
outchs = np.array([512,512, 512,512,256,128,64], dtype=np.uint32)*scale # outputするレイヤー数(追加分)
sizes = np.array([4,8,16,32,64,128,256], dtype=np.uint32)
firsts = np.array([True, False, False, False, False, False,False], dtype=np.bool)
blocks, toRGBs = [], []
for s, inch, outch, first in zip(sizes, inchs, outchs, firsts):
blocks.append(ConvModuleG(s, inch, outch, first))
toRGBs.append(nn.Conv2d(outch, 3, 1, padding=0))
self.blocks = nn.ModuleList(blocks)
self.toRGBs = nn.ModuleList(toRGBs)
def forward(self, x, res, eps=1e-7):
# to image
n,c = x.shape
x = x.reshape(n,c//16,4,4)
# for the highest resolution
res = min(res, len(self.blocks))
# get integer by floor
nlayer = max(int(res-eps), 0)
#print(res,nlayer)
for i in range(nlayer):
x = self.blocks[i](x)
# high resolution
x_big = self.blocks[nlayer](x)
dst_big = self.toRGBs[nlayer](x_big)
if nlayer==0:
x = dst_big
else: # レイヤー変更時の負荷軽減
# low resolution
x_sml = F.interpolate(x, x_big.shape[2:4], mode='nearest')
dst_sml = self.toRGBs[nlayer-1](x_sml)
alpha = res - int(res-eps)
#print(alpha)
x = (1-alpha)*dst_sml + alpha*dst_big
#return x, n, res
return torch.sigmoid(x)
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.minbatch_std = MiniBatchStd()
# conv modules & toRGBs
scale = 1
inchs = np.array([512,512,512,512,256,128,64], dtype=np.uint32)*scale
outchs = np.array([512,512, 512,512,512, 256,128], dtype=np.uint32)*scale
sizes = np.array([1,4,8,16,32,64,128], dtype=np.uint32)
finals = np.array([True, False, False, False, False, False,False], dtype=np.bool)
blocks, fromRGBs = [], []
for s, inch, outch, final in zip(sizes, inchs, outchs, finals):
fromRGBs.append(nn.Conv2d(3, inch, 1, padding=0))
blocks.append(ConvModuleD(s, inch, outch, final=final))
self.fromRGBs = nn.ModuleList(fromRGBs)
self.blocks = nn.ModuleList(blocks)
def forward(self, x, res):
# for the highest resolution
res = min(res, len(self.blocks))
# get integer by floor
eps = 1e-8
n = max(int(res-eps), 0)
# high resolution
x_big = self.fromRGBs[n](x)
x_big = self.blocks[n](x_big)
if n==0:
x = x_big
else:
# low resolution
x_sml = F.adaptive_avg_pool2d(x, x_big.shape[2:4])
x_sml = self.fromRGBs[n-1](x_sml)
alpha = res - int(res-eps)
x = (1-alpha)*x_sml + alpha*x_big
for i in range(n):
x = self.blocks[n-1-i](x)
return x
def gradient_penalty(netD, real, fake, res, batch_size, gamma=1):
device = real.device
alpha = torch.rand(batch_size, 1, 1, 1, requires_grad=True).to(device)
x = alpha*real + (1-alpha)*fake
d_ = netD.forward(x, res)
g = torch.autograd.grad(outputs=d_, inputs=x,
grad_outputs=torch.ones(d_.shape).to(device),
create_graph=True, retain_graph=True,only_inputs=True)[0]
g = g.reshape(batch_size, -1)
return ((g.norm(2,dim=1)/gamma-1.0)**2).mean()
学習
# 写真数90000
if __name__ == '__main__':
device = 'cuda' if torch.cuda.is_available() else 'cpu'
#Gparam = torch.load('/content/drive/MyDrive/GANstudy/PGGAN/models5/6-netG.pth')
netG = Generator().to(device)
try:
netG.load_state_dict(Gparam,strict=False)
except:
pass
netD = Discriminator().to(device)
netD.load_state_dict(torch.load('/content/drive/MyDrive/GANstudy/PGGAN/models5/6-netD.pth'))
#Gparam = torch.load('/content/drive/MyDrive/GANstudy/PGGAN/models5/6-netG_mavg.pth')
netG_mavg = Generator().to(device) # moving average
try:
netG_mavg.load_state_dict(Gparam,strict=False)
except:
pass
lr = 0.001
optG = torch.optim.Adam(netG.parameters(), lr = lr, betas=(0.0, 0.99))
optD = torch.optim.Adam(netD.parameters(), lr = lr, betas=(0.0, 0.99))
criterion = torch.nn.BCELoss()
batch_size = 4
# dataset
transform = transforms.Compose([transforms.ToTensor(),transforms.Resize((256,256))])
trainset = torchvision.datasets.ImageFolder(root="/content/animefacemini", transform=transform)
train_loader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True, drop_last=True)
# training
res_steps = [30000,30000,30000,50000,100000,200000,500000
#[4,8,16,32,64,128,256]
losses = []
j = 9873200 #学習深度-pixあたり
res_i = 6 # 学習深度-pix
nepoch = 3000
res_index = 6 #学習深度-pix
# constant random inputs
r = random.randint(0,99999999999)
torch.manual_seed(256)
z0 = torch.randn(16, 512).to(device) #16次元のconstノイズをn個排出
z0 = torch.clamp(z0, -1.,1.)
torch.manual_seed(r)
beta_gp = 10.0
beta_drift = 0.001
#lr_decay=0.87 #レイヤー変更時の減衰
# attenuation_rate = 0.99 #lr減衰率
#attenuation_timing = 200 #この回数ごとに減衰する(lossの値を監視して規定以上なら)
torchvision.datasets.ImageFolder
for iepoch in range(nepoch):
for i, data in enumerate(train_loader):
x, y = data
x = x.to(device)
res = ((j/res_steps[res_index]) * 1.25 + res_i)
res = min(res,res_i+1)
### train generator ###
z = torch.randn(batch_size, 512).to(x.device)
x_ = netG.forward(z, res)
del z
d_ = netD.forward(x_, res) # fake
lossG = -d_.mean() # WGAN_GP
del d_
optG.zero_grad()
lossG.backward()
optG.step()
# update netG_mavg by moving average
momentum = 0.995 # remain momentum
alpha = min(1.0-(1/(j+1)), momentum)
for p_mavg, p in zip(netG_mavg.parameters(), netG.parameters()):
p_mavg.data = alpha*p_mavg.data + (1.0-alpha)*p.data
### train discriminator ###
z = torch.randn(x.shape[0], 512).to(x.device)
x_ = netG.forward(z, res)
del z
x = F.adaptive_avg_pool2d(x, x_.shape[2:4])
d = netD.forward(x, res) # real
d_ = netD.forward(x_, res) # fake
loss_real = -1 * d.mean()
loss_fake = d_.mean()
loss_gp = gradient_penalty(netD, x.data, x_.data, res, x.shape[0])
loss_drift = (d**2).mean()
del d_
del d
lossD = loss_real + loss_fake + beta_gp*loss_gp + beta_drift*loss_drift
optD.zero_grad()
lossD.backward()
optD.step()
print('ep: %02d %04d %04d lossG=%.10f lossD=%.10f' %
(iepoch, i, j, lossG.item(), lossD.item()))
losses.append([lossG.item(), lossD.item()])
j += 1
#解像度の切り替わり条件
if res_steps[res_index] == j:
PATH = "/content/drive/MyDrive/GANstudy/PGGAN/models5/"
torch.save(netG.state_dict(), PATH + f"{res_index}-last-netG.pth")
torch.save(netD.state_dict(), PATH + f"{res_index}-last-netD.pth")
torch.save(netG_mavg.state_dict(), PATH + f"{res_index}-last-netG_mavg.pth")
j = 0
res_index += 1
res_i += 1
if j%50 == 0:
try:
sleep(1)
netG_mavg.eval()
z = torch.randn(16, 512).to(x.device)
z = torch.clamp(z, -1.,1.)
x_0 = netG_mavg.forward(z0, res)
x_ = netG_mavg.forward(z, res)
dst = torch.cat((x_0, x_), dim=0)
del z,x_0,x_
dst = F.interpolate(dst, (256, 256), mode='nearest')
dst = dst.to('cpu').detach().numpy()
n, c, h, w = dst.shape
dst = dst.reshape(4,8,c,h,w)
dst = dst.transpose(0,3,1,4,2)
dst = dst.reshape(4*h,8*w,3)
dst = np.clip(dst*255., 0, 255).astype(np.uint8)
dst = cv2.cvtColor(dst, cv2.COLOR_BGR2RGB)
cv2.imwrite(f'/content/drive/MyDrive/GANstudy/PGGAN/images5/image{res_index}-{j}-.jpg', dst)
netG_mavg.train()
except:
print("error")
if j%100 == 0:
PATH = "/content/drive/MyDrive/GANstudy/PGGAN/models5/"
torch.save(netG.state_dict(), PATH + f"{res_index}-netG.pth")
torch.save(netD.state_dict(), PATH + f"{res_index}-netD.pth")
torch.save(netG_mavg.state_dict(), PATH + f"{res_index}-netG_mavg.pth")
if j%5000 == 0:
PATH = "/content/drive/MyDrive/GANstudy/PGGAN/models5/"
torch.save(netG.state_dict(), PATH + f"{res_index}-{j}-netG.pth")
torch.save(netD.state_dict(), PATH + f"{res_index}-{j}-netD.pth")
torch.save(netG_mavg.state_dict(), PATH + f"{res_index}-{j}-netG_mavg.pth")
解説がなくて申し訳ないです。pathは各自入れ替えてください。
ちなみにこの実装は論文で実装されていた構成のほぼ丸パクリです。
一応個人的にぐちゃぐちゃになっている学習のところだけ解説します
jは学習深度。初期値0
res_i,res_indexはどの解像度にいるか。初期値0
res_stepsは各解像度でどれくらいの回数学習するかを決めてます。
batch_sizeはコード上は4ですが、初期値は256とかです。メモリに乗らなくなったら減らしていく感じです。
lrも初期値は0.001ですが、解像度が上がっていくにつれて不安定になっていくので、手動で減らしていきます。
学習に時間がかかるため、定期的にモデルの保存をしてます。colabでやる以上必須です。
コードを見ればわかると思いますが、ノイズ(ベクトル)は512次元です。
正直この辺りはPGGAN githubと調べて、すでに実装しやすいように準備されているコードを使ったほうがいいです。自由度こそ下がりますが、普通に実装しようとすると意味が分からないくらい難易度が高いのでお勧めしません。
結果と考察
先ほど紹介したデータセットでの学習成果を紹介

...一見すると失敗してるように見えますよね。ではここからある技を使ってこのモデルを使えるようにしていきましょう
精度向上の秘密
結果から言います。

これくらいのレベルの画像がほとんどになるほど精度向上します。
まずこの精度向上の秘密を語るためには、まずはベクトル移動について学ぶ必要があります。
ベクトル移動
先ほどからノイズzという謎の存在をモデル内に入れていましたが
ノイズzというのは数学的なベクトルと同意だと思ってください。
数学味がありますが、意外に単純なのでご安心を。
ベクトルという存在について超簡単に説明するなら、
「消しゴムがあります。消しゴムは白いです。消しゴムは鉛筆で描いた文字を消すことができます。なので消しゴムは『白色』と『消す』ベクトルを持っています」
「消しゴムは「白い」です。雲も「白い」です。ですが、雲は「消す」をもっていません
なので、消しゴムと雲は同じものではないですが、ベクトル的には近しい部分があります」
このような、そのものが持つ抽象的な要素、特性を数値化したものを「ベクトル」といいます。
そしてこれがどう関係するのかというと、GANの内部構造と関係しています。GANの内部では、画像が持つ特徴量を抽出して、保存する動きがあります。
「髪の毛の色」「顔の向き」「目の色」「目の形」...数えられないくらい沢山の要素があり、それらの特徴を与えられたベクトルzをもとに結果を出していくという構造をしています。
この部分に関しては以下の記事が参考になるのでぜひこちらのほうをご覧ください。非常にわかりやすい記事になっています。
GANについて概念から実装まで ~DCGANによるキルミーベイベー生成~
小難しい話は抜きにして、とりあえずこれをご覧ください。

この画像群は全てPGGANで作成されたものです。
画像が動いてますよね。これは内部的にはただベクトルzが動いてるだけで、PGGANは単純にベクトルに応じたデータを返しているだけです。
少しわかりにくいかもしれませんが、ベクトル演算をすることで、複数の画像の間の画像を生成できます。
そしてこれができるとなぜ精度が高くなるのかについて話を戻します。先程お見せしたキャラクター複数人の画像、ありましたよね。あの状態でそのまま出すの
あまりよろしくないので、とりあえず「使える画像のベクトル」をなんらかの形で保存しておきます。
ベクトル検索、保存の仕方はなんでも構いません。私は眼で見て綺麗に作れてるなと思った画像のseed値をメモ帳に書き出して保存してました。多分この辺りも機械学習で自動化できます。
一応私が使っていたコードを置いておきます。pytorchです。
# checkimgs/shift-img-{seed}~{seed+30}.jpgとして保存
# 複数枚のランダム画像
device = 'cuda' if torch.cuda.is_available() else 'cpu'
width = 10
height = 3
netG_mavg = Generator().to(device) # moving average
netG_mavg.load_state_dict(torch.load('/content/drive/MyDrive/GANstudy/PGGAN/models5/5-last-netG_mavg.pth'))
optG = torch.optim.Adam(netG_mavg.parameters(), lr=0.001, betas=(0.0, 0.99))
def visualizeInterpolation(s):
vectors = []
#値をすこしずつshift
for mis in range(s,s+30):
np.random.seed(seed=mis)
z = np.random.randn(512)
vectors.append(z)
vectors = np.array(vectors)
vectors = torch.from_numpy(vectors.astype(np.float32)).to(device)
vectors = torch.clamp(vectors, -1.,1.)
netG_mavg.eval()
dst = netG_mavg.forward(vectors, 6)
dst = F.interpolate(dst, (256, 256), mode='nearest')
dst = dst.to('cpu').detach().numpy()
n, c, h, w = dst.shape
dst = dst.reshape(height,width,c,h,w)
dst = dst.transpose(0,3,1,4,2)
dst = dst.reshape(height*h , width*w , 3)
dst = np.clip(dst*255., 0, 255).astype(np.uint8)
dst = cv2.cvtColor(dst, cv2.COLOR_BGR2RGB)
cv2.imwrite(f'/content/drive/MyDrive/GANstudy/PGGAN/checkimgs/shift5-img-{s}~{s+30}-mavg.jpg', dst)
for i in range(0,5000,30):
visualizeInterpolation(i)
このコードはただ単純にseed値0〜29番の時の画像、30〜59番の時の画像...を出していくだけのものです。
このコードを実行するとこんな感じの画像が出ます。
そして何も言わず次のコード
# checkimgs/shift-img-{seed}.jpgとして保存
# 画像を混ぜてみる
import random
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 画像シフトしていくシード値を二つ指定
# 3つくらいまでなら混ぜても大丈夫、4つからは怪しい
# 3つくらい混ぜると目がおかしくなりやすい
mixseeds = [2726,724]
mixnum = 2
mix = random.sample(mixseeds, mixnum)
filename = "image5"
netG_mavg = Generator().to(device) # moving average
netG_mavg.load_state_dict(torch.load('/content/drive/MyDrive/GANstudy/PGGAN/models4/5-last-netG_mavg.pth'))
optG = torch.optim.Adam(netG_mavg.parameters(), lr=0.001, betas=(0.0, 0.99))
def visualizeInterpolation(mix):
np.random.seed(seed=mix[0])
z = np.random.randn(1,512*16)
for seed in mix[1:]:
np.random.seed(seed=seed)
z2 = np.random.randn(1,512*16)
z = np.concatenate([z,z2],axis = 0)
z = np.clip(z,-1.,1.)
z[0] = z[0]*0.5
z[1] = z[1]*0.5
vectors = [z[0]]
#値をすこしずつshift
for mininoise in z[1:]:
vectors[0] = vectors[0]+mininoise
print(vectors)
vectors = np.array(vectors)
vectors = torch.from_numpy(vectors.astype(np.float32)).to(device)
netG_mavg.eval()
dst = netG_mavg.forward(vectors, 6)
dst = F.interpolate(dst, (256, 256), mode='nearest')
dst = dst.to('cpu').detach().numpy()
n, c, h, w = dst.shape
dst = dst.reshape(c,h,w)
dst = dst.transpose(1,2,0)
dst = np.clip(dst*255., 0, 255).astype(np.uint8)
dst = cv2.cvtColor(dst, cv2.COLOR_BGR2RGB)
cv2.imwrite(f'/content/drive/MyDrive/GANstudy/PGGAN/checkimgs/mix-{filename}-mavg.jpg', dst)
visualizeInterpolation(mix)
(ちょっとコードおかしいかもしれない)
このコードは、seed値①のベクトルをseed値②のベクトルに少しずつ近づけていき、それに応じた画像を出すだけのコードです。
このコードを実行するとこんな感じの画像が出ます。

これができると、seed値100個くらい保存しておくだけで、精度が保証されている画像を1〜10万枚以上(正確な数字はわからない)生成できるようになります。単純に決め打ちした画像を生成するときにも使えるので、ベクトルどうこうの話は覚えておきましょう。ちなみにベクトルの特性をフル活用したGANの種類にcGANがあります。まだ実装してませんがそこまで難しくないので、そのうちやります。
最後に
長くなってしまい申し訳ありません。また、力不足でPGGANの解説をしっかりとする自信がなかったので、今回の記事ではソースコードのみとなっています。
力を付けたらまた別の記事で書こうと思います。
それではまたどこかで。ついったーふぉろーLGTMよろしくね〜
2021/10/23追記
忘れていた補足ですが、この記事のPGGANの実装はpythonいぬさんのコードをほぼ丸コピしたものになっています。8割彼の功績で、一部式が間違えている部分と個人的に扱いやすいようになおしてあります。
私自身、今現在であってもDLについての知識は乏しく、とても誰かに教えられる実力も持ち合わせていません。
ですが、また近いうちに実装する日がやってくるので、その時にわかりやすいよう書き直します。
あ、あとね、githubに楽に実装できるやつ転がってた気がするんで、実運用したいならそれ使ってね。
(高校生には一回は挑戦して欲しいですけどね、ええ。)
thank you for reading...