tl;dr
- SGDの亜種を理解する上で重要なのはモーメンタムとスケーリング
- Adagradの挙動に注意
| 手法名 | スケーリング | モーメンタム |
|---|---|---|
| MomentumSGD | O | |
| AdaGrad | O | |
| ADADELTA | O | |
| rmsprop | O | |
| Adam | O | O |
目的
SGDには様々な亜種が提案されていますが、正直自分のような数学音痴では数式を見せられても違いがわかりません。そこで、本記事では、1Dの、人工的な勾配に対して各手法がどのように振る舞うかをみることで、これらの手法を「なんとなく」理解することを目指します。
なお、今回は下記の最適化手法を対象とします。
Limitation(先に言い訳)
本実験では各亜種の性質を「不正確でもいいから腹落ちする」感覚で考えることを目標としています。問題を限界まで単純化しているので、ちゃんと数式だけでイメージできる人はそれを信じたほうが良いです。
数式から考えるSGD
各亜種の式を下記に示します。下記は、手法の違いを捉えやすくするため、 元論文などとは違う記号を使っている場合があります。 なお、下記記事では、 $ w_t \in \mathbb{R} $ は$t$イテレーション目におけるパラメータ1つを指すものとします。$g_t \in \mathbb{R} $は$w_t$における勾配を示します。
Vanilla SGD
w_{t+1} = w_t - \alpha g_t
普通のSGDです。 $\alpha$ は学習率です。
SGD with momentum
\begin{align}
m_t &= \beta r + (1 - \beta) g_t \\
w_{t+1} &= w_t - \alpha m_t
\end{align}
モーメンタム項つきのSGDです。通常SGDはガタガタと振動しながら進むので、特に勾配が歪んでいる(skewがある)時になかなか谷に落ちて行きません。
SGD without momentum5
そこで、勾配の指数移動平均を使うことで、ダンパのように振動をおさえつつ高速に谷方向におちてゆくことを可能にします。
SGD with momentum5
AdaGrad
AdaGrad (Adaptive Gradient) は各パラメータに対して適応的に異なる学習率を適応する手法であり、今回取り上げた亜種の中では(MomentumSGDを除き)最も古いものになります。
\begin{align}
G &= \sum^t_{\tau=0}{g_{\tau}^2} \\
w_{t+1} &= w_t - \frac{\alpha}{\sqrt{G} + \epsilon} g_t
\end{align}
$\epsilon$は除算を安定化させる$10^{-8}$程度の小さい値を指します。
分母に勾配の二乗和が入っています。$\frac{\alpha}{\sqrt{G} + \epsilon}$は勾配が大きい場合は小さく、勾配が小さい場合は大きくなります。つまり、どのパラメータでも勾配が近い値にスケーリングされます。これにより、深いネットワークで勾配が小さいパラメータでも高速に学習が進むというのがポイントです。ただ、$t$が増えれば増えるほど$G$は単調増加してゆくので、AdaGradには学習率が極端に速く減衰していくという問題があります。
rmsprop
AdaGradは深いネットワークの学習に大きなインパクトを与えましたが、学習率の極端な減衰が問題でした。これに対して異なるグループで独立に考えられたのがrmspropとADADELTAです。
\begin{align}
\nu_{t} &= \gamma \nu_{t-1} + (1 - \gamma) g_t^{2} \\
w_{t+1} &= w_t - \frac{\alpha}{\sqrt{\nu} + \epsilon} g_t
\end{align}
rmspropではAdaGradの二乗和の部分が指数移動平均になっています。和ではなく平均ですので、AdaGradのような減衰効果はありません。$\gamma$ は過去の勾配による影響を減衰させるパラメータです。
ADADELTA
\begin{align}
\nu_t &= \gamma \nu_{t-1} + (1 - \gamma) g_t^{2} \\
\Delta w_t &= - \frac{\sqrt{s_{t-1} + \epsilon}}{\sqrt{\nu_t + \epsilon}} g_t\\
w_{t+1} &= w_t + \Delta w_t\\
s_t &= \gamma s_{t-1} + (1 - \gamma) \Delta w_t^{2}
\end{align}
ADADELTAはrmspropとまったく同じように、分母に二乗平均平方根が入っています。ADADELTAではこれに加え、パラメータ変更量の二乗平均平方根を学習率の設定につかいます。作者は、これを更新量とパラメータの単位をそろえるためとしています。パラメータの単位が$u$だとすると、分母の単位も$u$のため、AdaGradではこれらが打ち消し合って単位がなくなってしまっています。更新量の二乗平均平方根(単位はu)を掛けあわせることで単位がそろいます。これによって学習率をきめるということなので、ADADELTAは学習率$\alpha$を持ちません。
Adam
\begin{align}
\nu_t &= \gamma \nu_{t-1} + (1 - \gamma) g_t^{2} \\
m_t &= \beta r + (1 - \beta) g_t \\
\hat{\nu}_t &= \frac{\nu_t}{1 - \gamma^t}\\
\hat{m}_t &= \frac{m_t}{1 - \beta^t}\\
w &\leftarrow w - \frac{\alpha}{\sqrt{\hat{\nu}_t} + \epsilon} \hat{m}_t
\end{align}
Adamは基本的にはrmsprop+Momentumです。
rmspropでもそうなのですが、$\nu_0$(初期値)を$0$とすると、$\gamma$が1に近い場合$\nu$はとても小さい値になり、学習率としてはとても大きくなってしまいます。また、逆にモーメンタムはとても小さくなってしまいます。これでは不安定になりかねないので、Adamでは$\nu$と$m$をそれぞれの維持率で補正しています。
実験で理解するSGD
以上で、数式からこれらのアルゴリズムを何を意図しているのかがわかりました。次に、上記解釈があっているか実験でたしかめます。ハイパーパラメータはChainerのデフォルトを使いました。勾配g_tは表記しませんので、SGDの値を基準値としてみてください。
なお、本実験の全ソースコードはgistにあげてあります。
定常入力
まずは、簡単な定常入力 ($g_t = 1.0$) です。
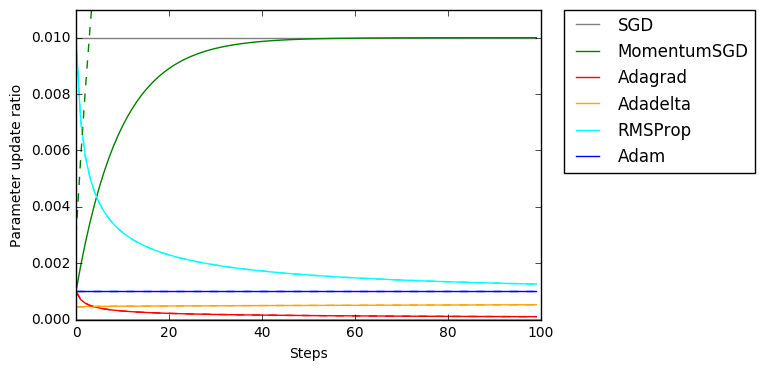
上記で説明したとおり、AdaGradはどんどん減衰していること、rmspropは初期に値が大きくなることがよくわかります。なお、定常な入力だと、AdaGrad以外はすべて1つの値に落ち着きます。
また、完全に見切れていてわかりにくいのですが、この図には破線で$g_t = 3.0$の場合が重ねてあります。MomentumSGDは勾配の大きさによって値がかわることがよくわかるのですが、他の最適化手法では破線と線が重なっている=勾配の大きさによらず更新量が不変なことがわかります。
疎な入力
自然言語処理のように勾配が疎にしか生じない場合です。
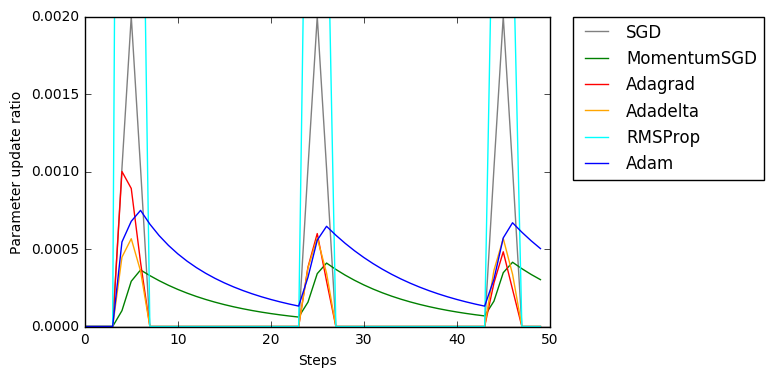
AdamとMomentumSGDではモーメンタムの効果がでていることがわかります。rmspropは吹っ飛んでいってしまっていますが、更新量の総量は増えているので意図どおりなのでしょうか?
定常入力 + ノイズ小
それぞれ0.5(実線)、1.0(破線)を中心に正規分布からノイズを添加しています。
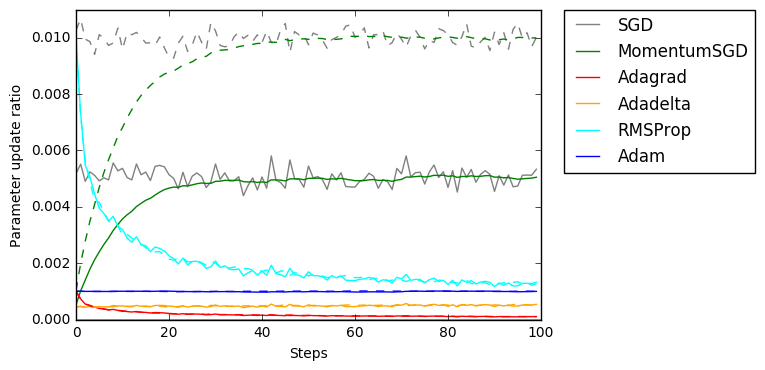
AdamとADADELTAの圧倒的ブレなさが目立ちます。AdaGradも勾配の大きさをうまくスケーリングできているのですが、値が急速に減衰していることがわかります。
定常入力 + ノイズ大
0.2を中心に正規分布からノイズを添加しています。
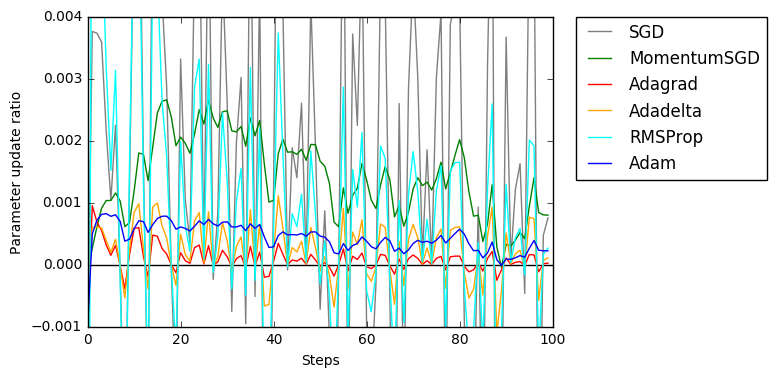
モーメンタム項がつくとかなり安定化します。
参考文献
各手法の全体感の理解のために5を参考にしています。上記の記事は5の受け売りの部分が結構あります。式の整理のために6を参照しました。各実装やパラメータはChainerを参考にしています。
-
Duchi, Hazan and Singer. 2011. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. JMLR ↩
-
[Zeiler. 2013. ADADELTA: AN ADAPTIVE LEARNING RATE METHOD. Google TR] (http://www.matthewzeiler.com/wp-content/uploads/2017/07/googleTR2012.pdf) ↩
-
Tieleman and Hinton. 2012. In Corsera Course. ↩
-
Kingma and Ba. 2015. Adam: a Method for Stochastic Optimization. ICLR ↩
-
Ruder, An overview of gradient descent optimization algorithms. In blog post ↩ ↩2 ↩3 ↩4
-
skitaoka. 2017. AdaGrad, RMSProp, AdaDelta, Adam, SMORMS3. In Qiita post ↩