tl; dr
- NIPS2018に採択された、DeepMindによる Leike et al. 2018. Reward learning from human preferences and demonstrations in Atari. NIPS. 1を紹介。
- 模倣学習で報酬関数、ひいてはpolicyを学習し、その後、良し悪しのフィードバックで更にpolicyを改善する深層学習手法を提案。
- 模倣学習と良し悪しのフィードバックの両方を組み合わせることで、片方ずつより性能が向上することを確認。2ゲームではゲームのスコアを使わずに人を超える性能を実現。
目的
近年、強化学習が注目されています。強化学習には報酬関数の設計が必要ですが、報酬関数を定義することが難しい問題は非常に多いです。そこで、報酬関数を陽に設計することなく、ユーザのフィードバックから行動方策 (policy)を学習することが近年注目されています。
しかし、ユーザフィードバックを報酬としてナイーブに強化学習を行うのは、必要な報酬の回数から考えて現実的ではありません。そこで、ユーザフィードバックからまず報酬関数を学習し、その報酬関数を用いて強化学習を行う手法が多数提案されています。報酬関数を学習するために与えることができるフィードバックには2種類あり、それぞれ次のような利点・欠点をもっています。
-
行動の良し悪しのフィードバック (2つの行動から良かった方を選ぶ) から報酬関数を学習
- ✓ 人間への負荷が少ない
- ✗ 良し悪しのフィードバックを元に、広大な報酬関数を探索するのは難しい。
-
人(expert)のデモンストレーションから報酬関数を学習 (模倣学習 (imitation learning)、逆強化学習 (inverse reinforcement learning) などと呼ばれる)
- ✓ 良し悪しのフィードバックに比べ情報量が多い
- ✗ フィードバックを与えるユーザに経験が求められる
- ✗ 模倣しているだけでは人間を超えることはできない
上記に記載したとおり、2つのアプローチにはそれぞれ良し悪しがあります。そこで、本研究では、模倣学習で報酬関数、ひいてはpolicyを学習し、その後、良し悪しのフィードバックで更にpolicyを改善することで、良いとこ取りをした深層学習手法を提案します。
手法
模倣学習部分
本研究では、まず模倣学習を行い、それを良し悪しのフィードバックで改善してゆきますが、模倣学習の手法自体はDeep Q-learning from Demonstration (DQfD)という先行研究2を使っています。DQfDはその名のとおりDeep Q-learningの拡張ですが、expertによるデモンストレーションで得られる報酬は、それ以外の行動よりも常に良いという形で、expertによるデモンストレーションとそれ以外の行動のそれぞれの報酬のマージン最大化を行います。本研究でもそれを踏襲し、次のような損失を使っています。
J(Q) = J_{PDDDQ_n}(Q) + \lambda_2J_E(Q) + \lambda_3J_{L2}(Q)
第1項目は強化学習に係る損失、2項目が前述した模倣学習に係る損失です。
良し悪しのフィードバックからの学習
報酬関数$\hat{r}:o_t \mapsto r_{t+1} \in \mathbb{R}$を考えます。$o_t$は時刻tの状態+行動で、ゲーム画像4フレーム分に相当します。ゲーム全体から切り出したclip (1.7秒程度の行動) $\sigma = {o_t, o_{t+1}, \cdots}$を考えます。2つのclip$(\sigma^1, \sigma^2)$と、それに対する評価$\mu$ ($\sigma^1$が良ければ$(1, 0)$)が与えられたときに、次のように学習します。
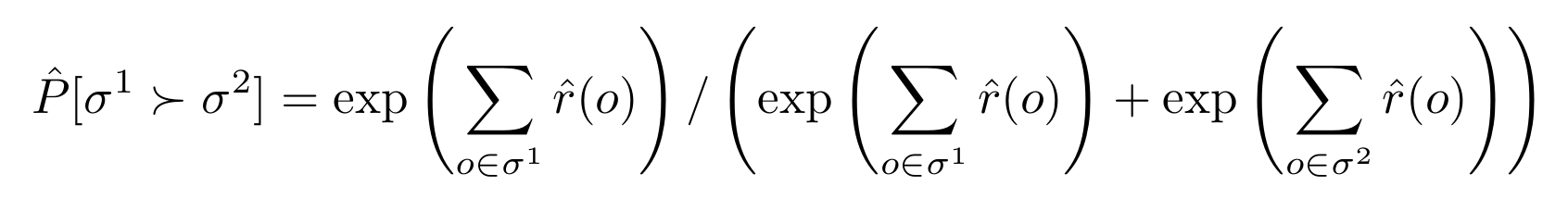
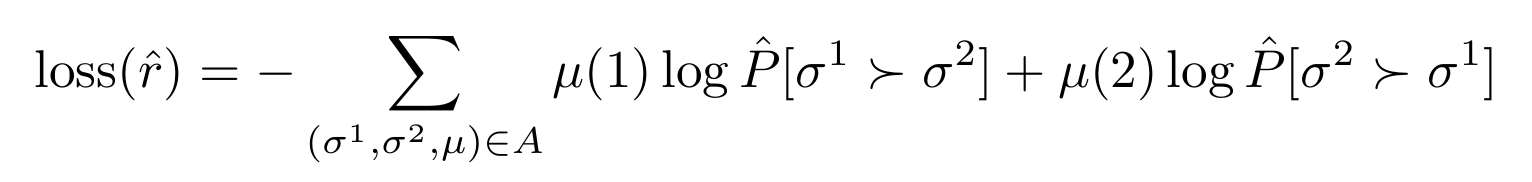
これは各clipで得られる報酬の和のsoftmax cross-entropy lossと等価な式になっています。
提案手法では、デモンストレーションよる教師データも与えられます。これを模倣学習だけで使うのはもったいないです。そこで、デモンストレーションの行動列は、1試行目でエージェントがとった行動よりも常によいという疑似フィードバックを作成し、学習で使います (autolabelsと呼んでいます)。
提案手法の全体像
上記の2つの学習を次のように組み合わせて学習します。入力としてexpertによるデモンストレーションが複数試行分 (3〜9プレイ分。10899〜75472行動分に相当)
- expertによるデモンストレーションの報酬とそれ以外の行動の報酬のマージン最大化
- エージェントの行動から、複数のclip (行動列)をランダムに抽出します。各clipは実時間で1.7秒程度です。(一回目は500clip組、二回目は1000 clip組。フィードバックを減らした対照実験ではこの数を減らす。)
- あのテータは前述した良し悪しのフィードバックを各clipに対して行います。
- (一回目だけ)expertによるデモンストレーションから疑似的に良し悪しのフィードバックを作成します (前述したautolabels)。
- 前述した"良し悪しのフィードバックからの学習"で報酬関数を学習します。
- 学習した報酬関数を元にエージェントのpolicyを学習します。
- 2〜6を繰り返します。なお、良し悪しのフィードバックは毎回新しくするのではなく、FIFO (First in first out)な感じで使いまわします。
実験
Atariのゲームで実験を行います。なお、実験は一部の条件を除き、ゲームのスコアから疑似的に生成したユーザフィードバックを使っています。つまり、2つのclipが与えられた時に、ゲームのスコアが高い方のclipを「良い」と評価するようなフィードバックです。
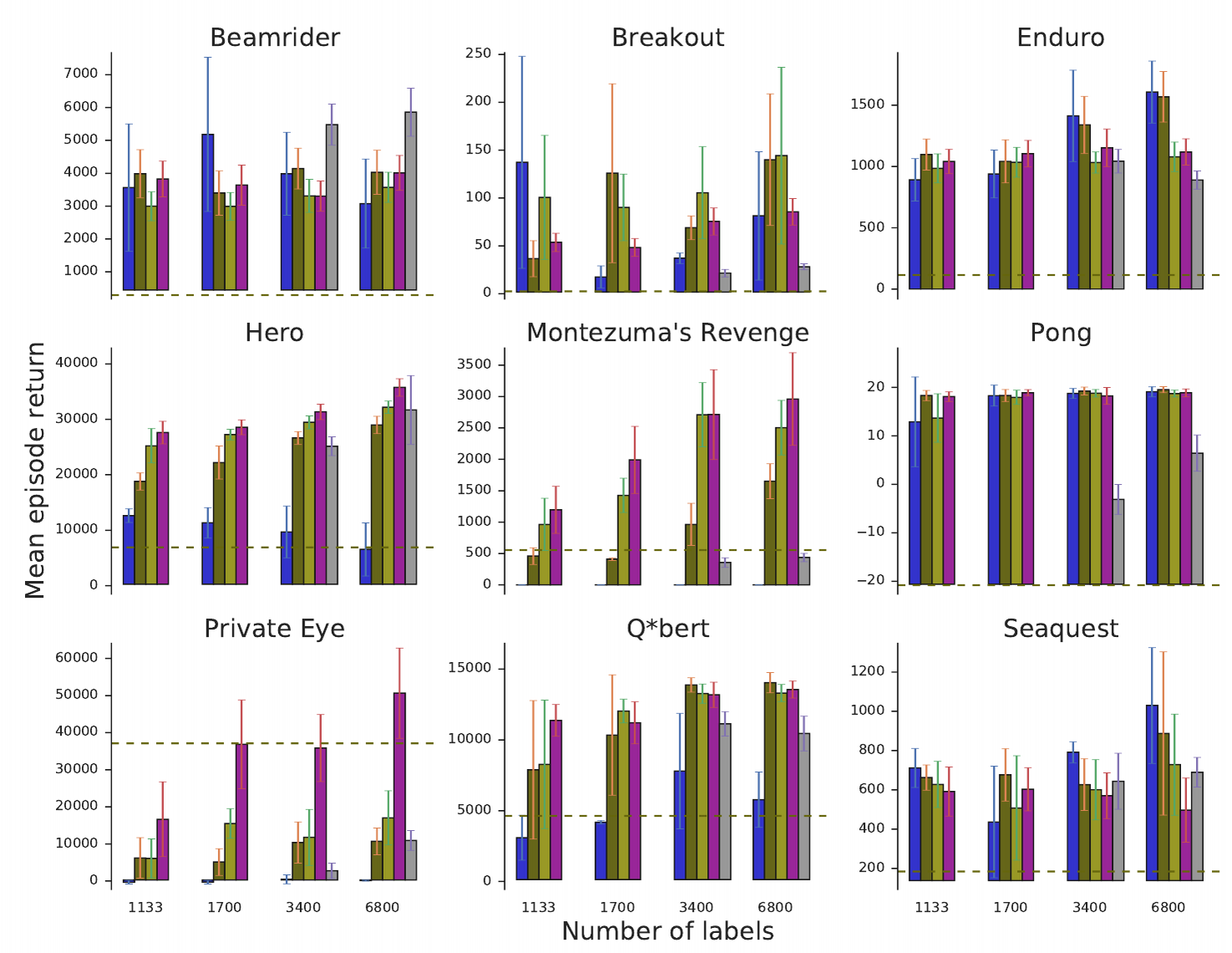

実験結果から次のことがわかります。
- 「良し悪しのフィードバックからの学習」を入れる効果はある? 1ゲームを除き全ゲームで効果がある(この1ゲームは模倣学習そのものがかなり強い)。たとえ量が少なくとも効果がある。
- 模倣学習の効果はある? 「良し悪しのフィードバックからの学習」だけでは、全く学習が進まないゲームがある。
- **ゲームのスコアから疑似的に生成したユーザフィードバックと本物の人のフィードバックは違う? ** やはりゲームのスコアから疑似的に生成したユーザフィードバックのほうが、本物の人のフィードバックより良い。色々と考察をしているので、詳しく知りたい人は元論文へGo。
- デモンストレーションからの良し悪しの疑似的フィードバックの効果はある?: あまり大きな改善は見られない。
うまく学習がいったエージェントの報酬関数を持ってきて、それをもとに1からpolicyを学習したところうまくいかなかったようです。このことから、報酬関数とエージェントを交互に学習することが重要であったと主張しています。報酬関数が固定されていると、ゲームのスコアは下がるが報酬が得られるような点 (Reward hacking)にハマってしまい、学習が進まなくなるからのようです。
コメント
- 「学習が安定しない」などの言葉が随所に見られ、苦労しただろうなということが伝わってくる。
- やはり人間のフィードバックを、ゲームのスコアをもとにした疑似フィードバックで置換しているところが気になる。
- 人は数秒の範囲しかみていないのに、疑似フィードバックはゲーム全体を見ているのではないだろうか?
編集可能な図はこちら。
-
NIPSとArXivで著者が違う... ↩
-
Hester et al. 2018. Deep Q-learning from Demonstrations. AAAI. ↩