背景
PrometheusとGrafanaを使ってリソース監視を始めてみたはいいものの、Grafana Dashboards | Grafana Labsにあるダッシュボードはなんかしっくり来ない。しかも、どれも微妙にクエリが違っててどれが正しいのかわからない!
ならば自分でちゃんとクエリを書いてみよう!ということで書いてみます。ここで紹介する3種類のクエリをマスターすれば、だいたい応用が効くと思います。
参考
基本的なことですが、Grafanaでグラフを書くときに入力するクエリ文は、PrometheusのPromQLです。(最初Grafanaのクエリ構文だと思ってた…)
node-exporterのメトリクスは、curlしてみるとヘルプもついてきます。デモサイトもあるのでこちらでもOK
Grafana Templating
GrafanaのTemplating機能を使って、クエリに変数を埋め込みます。以下の変数を定義している前提で記述します。
| 変数名 | 説明 | サンプル値 |
|---|---|---|
node |
クエリの対象とするノード。Prometheusが自動的に付けるinstanceラベルに対して使用することを想定 |
localhost:8080 |
interval |
クエリで表示する値の単位時間 | 5m |
CPUの使用率
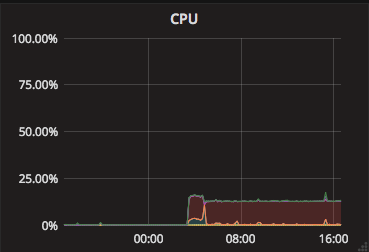
クエリ
avg(irate(node_cpu{instance="$node",mode!="idle"}[$interval])) without(cpu)
概要
指定インスタンス($node)の、単位時間($interval)内での1秒ごとのCPU使用率の平均を表示します。また、idleに関しては空きを示すため表示しません。
Prometheusの生データ抜粋
# HELP node_cpu Seconds the cpus spent in each mode.
# TYPE node_cpu counter
node_cpu{cpu="cpu0",instance="docker104:9100",job="node",mode="iowait"} 1.57
node_cpu{cpu="cpu0",instance="docker104:9100",job="node",mode="system"} 42.51
node_cpu{cpu="cpu0",instance="docker104:9100",job="node",mode="user"} 74.37
node_cpu{cpu="cpu1",instance="docker104:9100",job="node",mode="iowait"} 5.13
node_cpu{cpu="cpu1",instance="docker104:9100",job="node",mode="system"} 34.1
node_cpu{cpu="cpu1",instance="docker104:9100",job="node",mode="user"} 72.7
node_cpuメトリクスには、各インスタンスのCPUごとにCPU使用時間(秒)がmode単位で格納されています。
クエリ解説
- 欲しいデータは指定インスタンスの
modeがidleでないCPUの使用時間の直近$interval分間のデータですnode_cpu{instance="$node",mode!="idle"}[$interval]- この時点で、
modeの数 x CPUコア数 のレコードが返り、valueとして$interval分間のデータが配列で格納されています
- 返ったデータを、1秒ごとの平均増加値に直します
irate()- この時点で、
modeの数 x CPUコア数 のレコードが返り、valueが1秒ごとの平均増加値に変換されます
- すべてのCPUの平均を取ります
avg() without(cpu)-
without句には、集計関数を適用するときに無視したいラベルを指定します。今回はcpu,instance,job,modeというラベルがあり、cpuを無視してモードごとの平均を取ります。結果的に、すべてのcpuの平均を取ることになります
avg
avg演算子は、レコードごとに格納されたスカラー値の平均値を返します。レコードのvalueが配列(Range Vector)の場合は適用できません。
rate()とirate()
rate()とirate()関数はどちらも、ある時間範囲で取得したデータが、1秒あたり平均どれだけ増加しているかを計算します。
あくまで増加量のため、この関数を適用すべきメトリクスはnode_cpuやhttp_requests_totalなど、何らかの合計値を保持するもののみになります。
rate(v range-vector) calculates the per-second average rate of increase of the time series in the range vector.
irate(v range-vector) calculates the per-second instant rate of increase of the time series in the range vector.
withoutとby
without句は上述の通り、指定したラベルを無視して集計関数を適用します。実際にwithout(cpu)を実行した場合の生データは以下のように、cpuラベルが欠落した状態になります。
{instance="docker104:9100",job="node",mode="user"} 0.0005000000000002558
by句は逆に、指定したラベルに絞って、つまり他のラベルを無視して集計関数を適用します。by(mode)を実行すると、mode以外のすべてのラベルが欠落した状態になります。
{mode="user"} 0.0005000000000002558
今回はラベルが4つで、instanceとjobラベルは固定です。つまり、cpuとmodeしか返されるレコード中で変化しないため、値だけ見ればwithout(cpu)とby(mode)は同じ結果になります
CPUのコア数
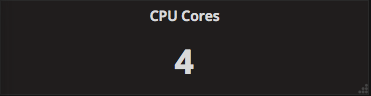
以下のクエリはどちらも同じ値を返します。
count(count (node_cpu{instance="$node"}) by(cpu))
count(node_cpu{instance="$node", mode="system"})
概要
CPUのコア数を直接返すメトリクスはありません。node_cpuメトリクスは上述の通り、CPUごとに使用率を返すため、これを利用して計算します。
クエリ解説
count(count (node_cpu{instance="$node"}) by(cpu))
- 指定インスタンスの直近の
node_cpuメトリクスを取得しますnode_cpu{instance="$node"}- この時点で、
modeの数 x CPUコア数 のレコードが返り、valueとして直近のデータがスカラー値で格納されています
- CPU単位で、メトリクスの数を取得します
count() by(cpu)- この時点で、
system,userなどのCPU使用率データの個数がCPUごとに返ります。この個数は目的の値でないので無視します
- CPUの数を数えます
count()
count(node_cpu{instance="$node", mode="system"})
- 指定インスタンスの
mode="system"となるメトリクスを取得しますnode_cpu{instance="$node", mode="system"}- この時点で、CPUコア数分の
system使用率が返ります
- CPUの数を数えます
count()
空きメモリ量
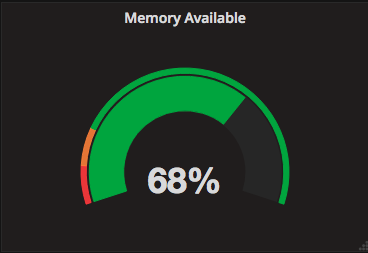
( avg_over_time(node_memory_MemFree{instance=~"$node"}[$interval])
+ avg_over_time(node_memory_Buffers{instance=~"$node"}[$interval])
+ avg_over_time(node_memory_Cached{instance=~"$node"}[$interval])
) / node_memory_MemTotal{instance=~"$node"} * 100
概要
空きメモリ量は、Linuxカーネル3.14以上であればnode_memory_MemAvailableメトリクスが使用可能ですが、そうでないホストがあることを考慮しています。
クエリ解説
繰り返しとなるため以下の部分のみ解説します。
avg_over_time(node_memory_MemFree{instance=~"$node"}[$interval])
- 指定インスタンスの直近の
$interval分間のnode_memory_MemFreeメトリクスを取得しますnode_memory_MemFree{instance=~"$node"}[$interval]- この時点で、1レコードのみ返り、valueに
$interval分間のすべてのデータが配列で格納されています
- 取得されたvalueの平均値を取得します
avg_over_time()
avg_over_time()
ある時間範囲で取得したデータの、それぞれのデータの平均を取りたい場合はavg_over_time()を使用します。上述のrate()系がサンプルでたくさん出てくることもあり、わかりにくいですが、こちらは単純に時間範囲の平均を計算できます。
まとめ
Prometheusのメトリクスにはデータ型があり、一口に「平均」といっても計算の仕方が複数あります。また、メトリクスも現在値を示すものと合計を示すものがあるため、このあたりを理解すればサクサク書けるようになれそうです。