Databricksデータをインポートする方法
はじめに
本記事はDatabricksを初めて触る人向けに作成されたものです。ここではDatabricksにデータをインポートする方法を紹介します。
詳細は以下の内容となっています。
-
Databricksとは
- Databricksの用途
-
Databricks操作方法
-
クラスター作成方法
-
データのインポート方法
-
Databricksとは
Databricksとは今北欧で一番の使用率を誇り、世界的にも注目され採用されているクラウド型の統合データ分析基盤です。DatabricksはAI/機械学習に特化しており、ビッグデータを扱うことに長けています。そのため、データエンジニアリング、データサイエンス、機械学習、データ分析の領域に強みがあるのが特徴です。
つまりDatabricksとは、大量のデータを高速に、簡単に分析できる機能をもつサービスということができます。
そんなDatabricksの操作は直感的で、クリックベースを中心に簡単に操作することが可能です。まずは最初の一歩とも言えるデータのインポートについて紹介します。
Databricks操作方法
今回インポートするために使用するデータは下記のデータ(.CSV)になります。
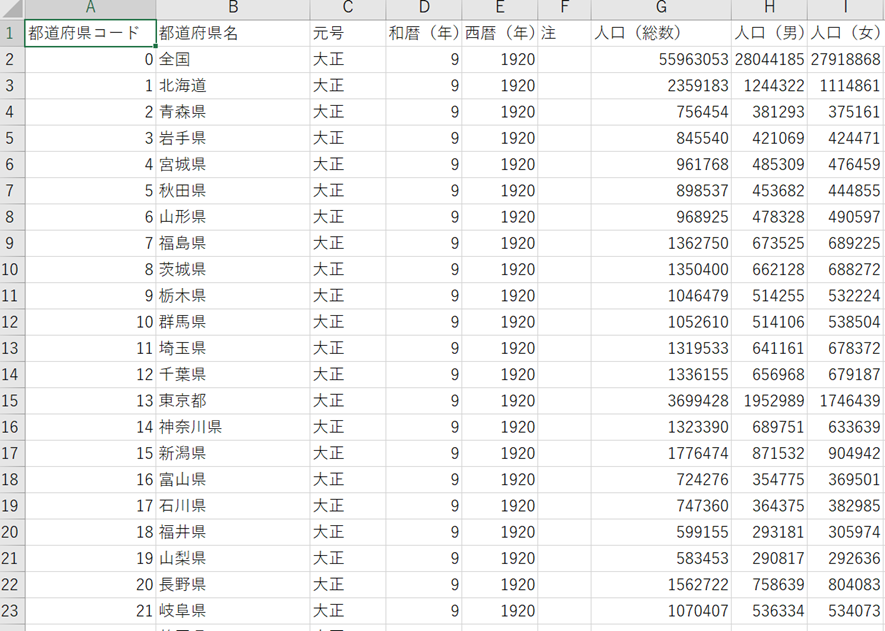
Databricksではホーム画面からでも、コードを書くワークスペース上でもインポートすることが可能です。今回紹介するのはUpload Data UIを使用したデータのインポートです。
まずは前準備として cluster を作成する必要があります。clusterを作成していないと、ワークスペースにおいてクエリを実行することができないので注意が必要です。
クラスター作成方法
主な手順は以下になります。
-
ホーム画面左タブからComputeを選択しCreate clusterを選択
-
自分の必要な環境に応じて設定
-
Createを押して作成
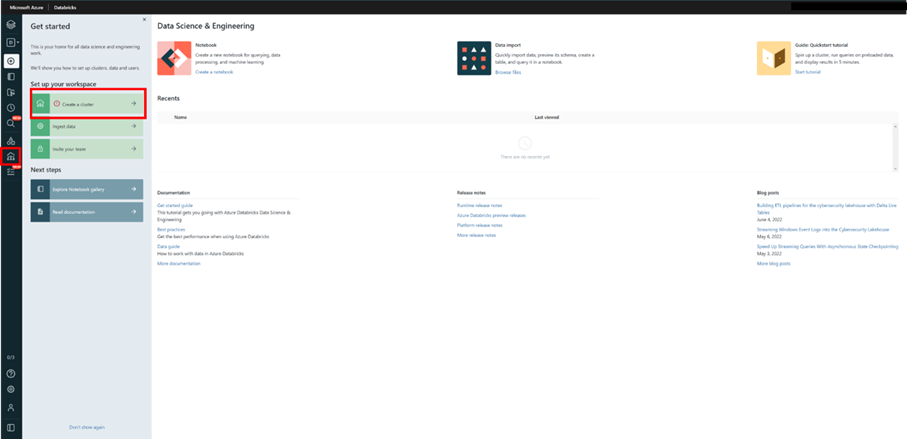
まずは下記画像のように、ホーム画面左タブに現れるマーク(Compute)を選択します。
初めてclusterを作成する場合はこのような画面が出てくるので、Create a clusterを選択します。
作成から次の画面は以下のようになるので、自分の環境にあったものを選択します。
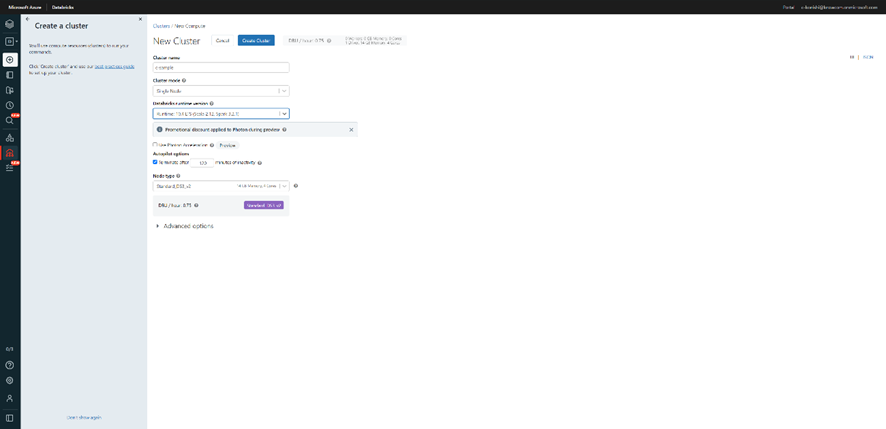
選択し終えた後は上部にあるCreate a clusterを選択し作成することが可能です。
クラスターを作成したら、次はデータをDatabricks上にアップロードします。
データのインポート方法
データをインポートする手順は以下になります。
-
ホーム画面のData importまたは左タブ(Data)を選択
-
アップロードするファイルを選択
-
ファイルのアップロード完了を確認し、テーブルを作成、データをインポート
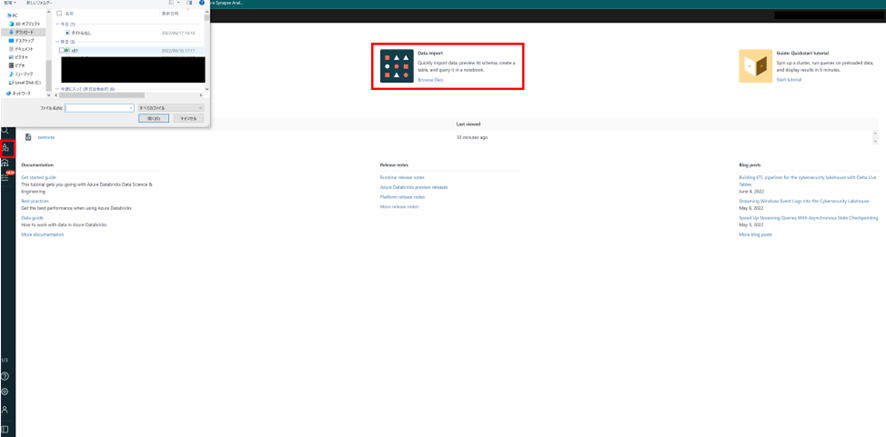
まずは、ホーム画面のData Importまたは、左側のタブに下記の画像のようなマーク(Data)があるので選択します。
ホーム画面のData Importを選択すると、ファイルが自動的に開かれるので、インポートしたいデータを選択します。
ファイルを下記画像のようにアップロードできたことを確認したら、そのままCreate Table in Notebookを押すことで、インポートしたデータに対してNotebook上でクエリを走らせることができる画面に行きます。
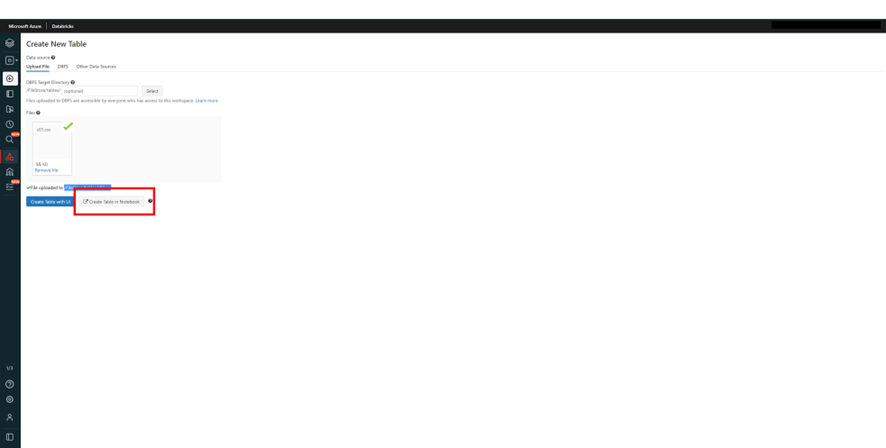
下記画像の場所で、クラスターをNotebookに割り当てることができます。
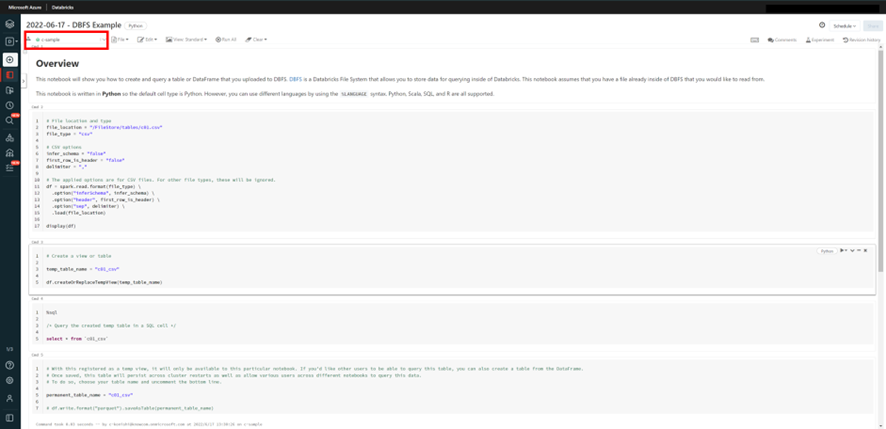
いかがでしたでしょうか。本記事ではDatabricks内でデータをインポートする方法について紹介しました。次回はNotebookにインポートしたデータを表示させる方法について紹介します。お楽しみに!