この動画で使っているプログラムを、こちらの記事に転記しています。
記事の概要
こちらの記事で最後に作成している8パズルのハイパーパラメータを更新し、8パズルをクリア可能なプログラムに更新しました。(こちらの記事では、「学習を実行する」ためのプログラムを実装していますが、8パズルのクリア率が優れたAIを構築するプログラムではありません。)
ハイパーパラメータ更新後の8パズルの学習
上記で紹介したプログラムを実行すると、クリア率はそれほど高くありません。
そこで、ハイパーパラメータなどを更新したプログラムと、その更新箇所について説明します。
まず、以下にハイパーパラメータなどを更新したプログラムを記載します。
プログラムの所要時間は約10時間です。
import copy
from collections import deque
import random
import numpy as np
import matplotlib.pyplot as plt
from IPython import display
import torch
import torch.nn as nn
import torch.optim as optimizers
from torch.optim.lr_scheduler import StepLR
import torch.nn.functional as F
import time # 時間計測のために追加
# GPUが利用可能か確認し、利用可能なら使用する
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
class ReplayBuffer:
def __init__(self, buffer_size, batch_size):
self.buffer = deque(maxlen=buffer_size)
self.batch_size = batch_size
def add(self, state, action, reward, next_state, done):
# stateがタプルの場合、最初の要素のみを取り出す
if isinstance(state, tuple):
state = state[0]
if isinstance(next_state, tuple):
next_state = next_state[0]
data = (state, action, reward, next_state, done)
self.buffer.append(data)
def __len__(self):
return len(self.buffer)
def get_batch(self):
data = random.sample(self.buffer, self.batch_size)
state, action, reward, next_state, done = zip(*data)
return (torch.tensor(np.array(state), dtype=torch.float32),
torch.tensor(action),
torch.tensor(reward, dtype=torch.float32),
torch.tensor(np.array(next_state), dtype=torch.float32),
torch.tensor(done, dtype=torch.float32))
class QNet(nn.Module):
def __init__(self, action_size):
super().__init__()
self.fc1 = nn.Linear(9, 512)
self.dropout1 = nn.Dropout(p=0.2)
self.fc2 = nn.Linear(512, 512)
self.dropout2 = nn.Dropout(p=0.2)
self.fc3 = nn.Linear(512, 256)
self.dropout3 = nn.Dropout(p=0.2)
self.fc4 = nn.Linear(256, 128)
self.dropout4 = nn.Dropout(p=0.2)
self.fc5 = nn.Linear(128, 64)
self.dropout5 = nn.Dropout(p=0.2)
self.fc6 = nn.Linear(64, action_size)
def forward(self, x):
x = F.leaky_relu(self.fc1(x), 0.01)
x = self.dropout1(x)
x = F.leaky_relu(self.fc2(x), 0.01)
x = self.dropout2(x)
x = F.leaky_relu(self.fc3(x), 0.01)
x = self.dropout3(x)
x = F.leaky_relu(self.fc4(x), 0.01)
x = self.dropout4(x)
x = F.leaky_relu(self.fc5(x), 0.01)
x = self.dropout5(x)
x = self.fc6(x)
return x
class DQNAgent:
def __init__(self):
self.gamma = 0.98
self.lr = 0.0005
self.epsilon_start = 1 # 初期値
self.epsilon_end = 0.01 # 最小値
self.epsilon_decay = 0.9995 # 減衰率
self.epsilon = self.epsilon_start # 現在のepsilon値
self.buffer_size = 10000
self.batch_size = 32
self.action_size = 4 # 'up', 'down', 'left', 'right'
self.replay_buffer = ReplayBuffer(self.buffer_size, self.batch_size)
self.qnet = QNet(self.action_size).to(device)
self.qnet_target = QNet(self.action_size).to(device)
self.optimizer = optimizers.Adam(self.qnet.parameters(), self.lr, weight_decay=1e-5)
self.scheduler = StepLR(self.optimizer, step_size=100, gamma=self.gamma) # 100ステップごとに学習率を0.98倍にする
def sync_qnet(self):
self.qnet_target.load_state_dict(self.qnet.state_dict())
def get_action(self, state):
print('state:', state)
# stateがNumPy配列の場合、そのまま使用
if isinstance(state, np.ndarray):
state_array = state
# stateがリストの場合、NumPy配列に変換
elif isinstance(state, list):
state_array = np.array(state)
# stateがタプル形式の場合(NumPy配列と辞書)、最初の要素を使用
elif isinstance(state, tuple) and isinstance(state[0], np.ndarray):
state_array = state[0]
# それ以外の場合はエラー
else:
raise TypeError(f"Unrecognized state format: {state}")
# state_array = np.array(state) #tuple型をリスト型に変換
state_tensor = torch.from_numpy(state_array.flatten()).float().unsqueeze(0).to(device) # NumPy配列をTensorに変換
if np.random.rand() < self.epsilon:
print('random mode')
return np.random.choice(self.action_size)
else:
print('qnet mode')
qs = self.qnet(state_tensor)
return qs.argmax().item() # .item() を追加してPythonの数値に変換
def update(self, state, action, reward, next_state, done):
self.replay_buffer.add(state, action, reward, next_state, done)
if len(self.replay_buffer) < self.batch_size:
return None # バッチサイズに達していない場合はNoneを返す
state, action, reward, next_state, done = self.replay_buffer.get_batch()
state = state.view(self.batch_size, -1).to(device) # バッチ処理のために、状態をフラット化
action = action.to(device)
reward = reward.to(device)
next_state = next_state.view(self.batch_size, -1).to(device) # バッチ処理のために、状態をフラット化
done = done.to(device)
# ネットワークの出力と損失の計算
qs = self.qnet(state)
q = qs.gather(1, action.unsqueeze(1)).squeeze(1)
next_qs = self.qnet_target(next_state)
next_q = next_qs.max(1)[0]
target = reward + (1 - done) * self.gamma * next_q
loss = F.mse_loss(q, target)
# バックプロパゲーション
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
return loss # 損失の値を返す
# 学習率のスケジューラを更新する関数
def update_scheduler(self):
self.scheduler.step()
class TileSlidePuzzleEnv:
def __init__(self, size=3):
self.size = size
self.board = np.zeros((self.size, self.size), dtype=int)
self.last_state = None # 前回の状態を保存する変数
self.step_count = 0 # ステップカウンターを追加
self.reset()
def reset(self):
# ゴール状態を設定
self.board = np.arange(self.size**2).reshape(self.size, self.size)
self.last_state = None # 前回の状態をリセット
self.step_count = 0 # ステップカウンターをリセット
# 一定回数のランダムな動きでタイルを混ぜる
for _ in range(50): # 例えば50回のランダムな動き
action = np.random.choice(4)
self.slide_tile(action)
return self.board.flatten()
def step(self, action):
# タイルをスライドさせるロジックを実装
# actionはタイルを移動する方向(例: 0=上, 1=下, 2=左, 3=右)
print('action:', action)
# ステップカウントを更新
self.step_count += 1
# 現在の状態を保存
current_state = self.board.flatten()
moved = self.slide_tile(action)
self.display()
# 次の状態(フラット化されたボード)
next_state = self.board.flatten()
# 報酬の計算
if not moved:
reward = -1
elif self.last_state is not None and np.array_equal(self.last_state, next_state):
reward = -1 # 2回前と同じ動きの場合
elif self.step_count > 100:
reward = -0.1 # 100ステップを超えた場合
else:
reward = self.calculate_reward() * 0.1
# ゲーム終了条件のチェック
done = self.is_solved()
if done:
reward = 10
print('reward:', reward)
# 状態の更新
self.last_state = current_state
# 追加情報(空の辞書を返す)
info = {}
# next_state, reward, done, infoを返す
return next_state, reward, done, info
def slide_tile(self, direction):
# 空白タイルの位置を見つける
x, y = np.where(self.board == 0)
x, y = int(x), int(y)
moved = False # タイルが動いたかどうかを追跡する変数
if direction == 0 and x < self.size - 1:
self.board[x, y], self.board[x+1, y] = self.board[x+1, y], self.board[x, y]
moved = True
elif direction == 1 and x > 0:
self.board[x, y], self.board[x-1, y] = self.board[x-1, y], self.board[x, y]
moved = True
elif direction == 2 and y < self.size - 1:
self.board[x, y], self.board[x, y+1] = self.board[x, y+1], self.board[x, y]
moved = True
elif direction == 3 and y > 0:
self.board[x, y], self.board[x, y-1] = self.board[x, y-1], self.board[x, y]
moved = True
return moved
def calculate_reward(self):
# 報酬の計算ロジック
# 例:正しい位置にあるタイルの数を報酬とする
correct_tiles = np.sum(self.board == np.arange(self.size**2).reshape(self.size, self.size))
return correct_tiles
def is_solved(self):
# パズルが解かれたかどうかをチェック
return np.array_equal(self.board, np.arange(self.size**2).reshape(self.size, self.size))
def display(self):
# パズルの現在の状態を表示
print(self.board)
def render(self):
print(self.board)
episodes = 20000
sync_interval = 20
limit_slide_count = 500
# タイルスライドパズル環境のインスタンス化
env = TileSlidePuzzleEnv()
agent = DQNAgent()
# 各エピソードの報酬を記録するリスト
reward_history = []
loss_history = []
start_time = time.time() # 開始時刻を記録
for episode in range(episodes):
print('----- ----- episode:', episode, ' ----- -----')
state = env.reset()
done = False
total_reward = 0
total_loss = 0
slide_count = 0
step_count = 0
while not done:
slide_count += 1
print('----- ----- episode:', episode, ' ----- -----')
print('slide _count:', slide_count)
# 行動をランダムで選択
action = agent.get_action(state)
# 行動後の状態を変数に代入
next_state, reward, done, info = env.step(action)[:4]
loss = agent.update(state, action, reward, next_state, done)
if loss is not None:
total_loss += loss.item() # 損失の合計を更新
state = next_state
total_reward += reward
step_count += 1
if done:
total_reward = 10000
print('total_reward:', total_reward)
if slide_count >= limit_slide_count:
done = True
# エピソード終了時にepsilonを更新
agent.epsilon = max(agent.epsilon_end, agent.epsilon_decay * agent.epsilon)
# エピソード終了時にスケジューラを更新
agent.update_scheduler()
if episode % sync_interval == 0:
agent.sync_qnet()
reward_history.append(total_reward)
loss_history.append(total_loss / step_count if step_count > 0 else 0)
print(f"Episode {episode}: Total Reward = {total_reward}, Average Loss = {loss_history[-1]}")
end_time = time.time() # エピソードの終了時刻を記録
episode_duration = end_time - start_time # エピソードの実行時間を計算
print(f"Duration = {episode_duration:.2f} seconds")
print(reward_history)
# エピソード番号のリストを生成
episodes = list(range(len(reward_history)))
# チェックポイントの保存
torch.save(agent.qnet.state_dict(), "dqn_tile_slide_model.pth")
# グラフの作成
plt.figure(figsize=(10, 6))
plt.plot(episodes, reward_history, marker='o')
plt.title('Episode vs Total Reward')
plt.xlabel('Episode')
plt.ylabel('Total Reward')
plt.grid(True)
plt.show()
以下に、紹介した記事のプログラムと、上記のプログラムの変更点を記載します。
■ニューラルネットワーク
①ニューラルネットワークの層を増幅(4層→6層)
②ドロップアウト層の追加
③活性化関数の変更(ReLU関数→Laeky ReLU関数)
■学習
④アクションのランダム率の減衰(固定→学習の進捗により減衰)
⑤学習率の変更(固定→学習の進捗により減衰)
⑥学習回数の増幅(10000→20000)
■報酬
⑦マイナスになる条件を追加
⑧報酬の値を、10000などの異常に大きな値にしない。(今回は結果をわかりやすくするため、学習に関係ない値を10000にしている)
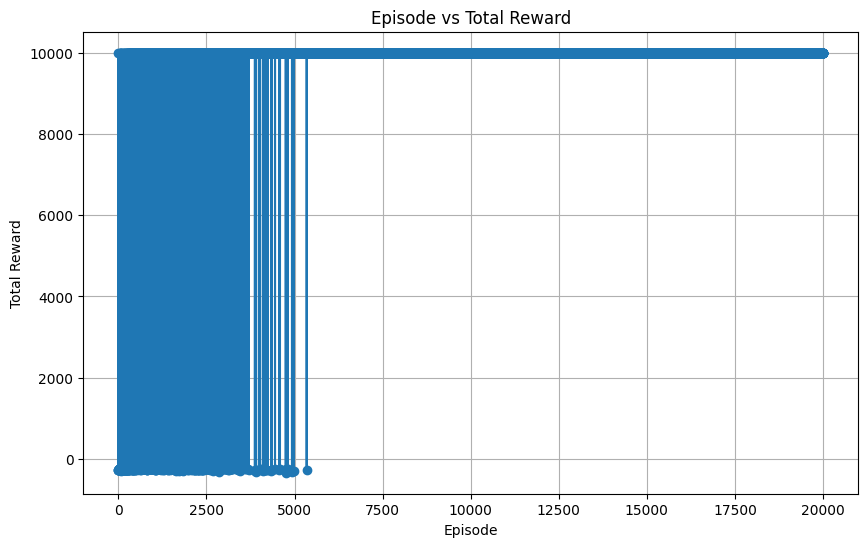
■結果
上記のプログラムを実行すると、以下の結果となった。
これは、右に行けば行くほど、学習が進んでおり、その時の報酬の総和をプロットしています。
また、10000にプロットされているケースは、ゲームをクリアしているケースです。
作成したモデルの確認(8パズル)
以下のプログラムを実行し、モデルを検証する。
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
# GPUが利用可能か確認し、利用可能なら使用する
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class QNet(nn.Module):
def __init__(self, action_size):
super().__init__()
self.fc1 = nn.Linear(9, 512)
self.dropout1 = nn.Dropout(p=0.2)
self.fc2 = nn.Linear(512, 512)
self.dropout2 = nn.Dropout(p=0.2)
self.fc3 = nn.Linear(512, 256)
self.dropout3 = nn.Dropout(p=0.2)
self.fc4 = nn.Linear(256, 128)
self.dropout4 = nn.Dropout(p=0.2)
self.fc5 = nn.Linear(128, 64)
self.dropout5 = nn.Dropout(p=0.2)
self.fc6 = nn.Linear(64, action_size)
def forward(self, x):
x = F.leaky_relu(self.fc1(x), 0.01)
x = self.dropout1(x)
x = F.leaky_relu(self.fc2(x), 0.01)
x = self.dropout2(x)
x = F.leaky_relu(self.fc3(x), 0.01)
x = self.dropout3(x)
x = F.leaky_relu(self.fc4(x), 0.01)
x = self.dropout4(x)
x = F.leaky_relu(self.fc5(x), 0.01)
x = self.dropout5(x)
x = self.fc6(x)
return x
class TileSlidePuzzleEnv:
def __init__(self, size=3):
self.size = size
self.board = np.zeros((self.size, self.size), dtype=int)
self.reset()
def reset(self):
# ゴール状態を設定
self.board = np.arange(self.size**2).reshape(self.size, self.size)
# 一定回数のランダムな動きでタイルを混ぜる
for _ in range(50): # 例えば50回のランダムな動き
action = np.random.choice(4)
self.slide_tile(action)
return self.board.flatten()
def step(self, action):
# タイルをスライドさせるロジックを実装
# actionはタイルを移動する方向(例: 0=上, 1=下, 2=左, 3=右)
print('action:', action)
moved = self.slide_tile(action)
self.display()
# 次の状態(フラット化されたボード)
next_state = self.board.flatten()
# 報酬の計算(例:正しい位置にあるタイルの数)
reward = self.calculate_reward()
print('reward:', reward)
# ゲーム終了条件のチェック
done = self.is_solved()
# 追加情報(空の辞書を返す)
info = {}
# next_state, reward, done, infoを返す
return next_state, reward, done, info
def slide_tile(self, direction):
# 空白タイルの位置を見つける
x, y = np.where(self.board == 0)
x, y = int(x), int(y)
if direction == 0 and x < self.size - 1:
self.board[x, y], self.board[x+1, y] = self.board[x+1, y], self.board[x, y]
elif direction == 1 and x > 0:
self.board[x, y], self.board[x-1, y] = self.board[x-1, y], self.board[x, y]
elif direction == 2 and y < self.size - 1:
self.board[x, y], self.board[x, y+1] = self.board[x, y+1], self.board[x, y]
elif direction == 3 and y > 0:
self.board[x, y], self.board[x, y-1] = self.board[x, y-1], self.board[x, y]
def calculate_reward(self):
# 報酬の計算ロジック
# 例:正しい位置にあるタイルの数を報酬とする
correct_tiles = np.sum(self.board == np.arange(self.size**2).reshape(self.size, self.size))
return correct_tiles
def is_solved(self):
# パズルが解かれたかどうかをチェック
return np.array_equal(self.board, np.arange(self.size**2).reshape(self.size, self.size))
def display(self):
# パズルの現在の状態を表示
print(self.board)
def render(self):
print(self.board)
def play_with_model(env, model):
state = env.reset()
env.display()
done = False
total_reward = 0
while not done:
state_tensor = torch.from_numpy(state.flatten()).float().unsqueeze(0).to(device)
with torch.no_grad():
action = model(state_tensor).argmax().item()
next_state, reward, done, _ = env.step(action)
# env.display()
state = next_state
total_reward += reward
if done:
print("Puzzle solved!")
break
print(f"Total Reward: {total_reward}")
# 環境とモデルの初期化
env = TileSlidePuzzleEnv()
model = QNet(action_size=4).to(device)
# 学習済みモデルの読み込み
model_path = "dqn_tile_slide_model.pth"
model.load_state_dict(torch.load(model_path))
model.eval() # 推論モードに設定
# ゲームの実行
play_with_model(env, model)
15パズルの学習
8パズルほどのクリア率は担保できないですが、8パズルを15パズルに変更し、ハイパーパラメータを更新したプログラムを紹介します。(学習にかかる時間を短縮するため、一部プログラムをコメントアウトしています。)
プログラムの所要時間は約22時間です。
import copy
from collections import deque
import random
import numpy as np
import matplotlib.pyplot as plt
from IPython import display
import torch
import torch.nn as nn
import torch.optim as optimizers
from torch.optim.lr_scheduler import StepLR
import torch.nn.functional as F
import time # 時間計測のために追加
# GPUが利用可能か確認し、利用可能なら使用する
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
class ReplayBuffer:
def __init__(self, buffer_size, batch_size):
self.buffer = deque(maxlen=buffer_size)
self.batch_size = batch_size
def add(self, state, action, reward, next_state, done):
# stateがタプルの場合、最初の要素のみを取り出す
if isinstance(state, tuple):
state = state[0]
if isinstance(next_state, tuple):
next_state = next_state[0]
data = (state, action, reward, next_state, done)
self.buffer.append(data)
def __len__(self):
return len(self.buffer)
def get_batch(self):
data = random.sample(self.buffer, self.batch_size)
state, action, reward, next_state, done = zip(*data)
return (torch.tensor(np.array(state), dtype=torch.float32),
torch.tensor(action),
torch.tensor(reward, dtype=torch.float32),
torch.tensor(np.array(next_state), dtype=torch.float32),
torch.tensor(done, dtype=torch.float32))
class QNet(nn.Module):
def __init__(self, action_size):
super().__init__()
self.fc1 = nn.Linear(16, 512) # 入力サイズを16に変更(15パズル用)
self.dropout1 = nn.Dropout(p=0.2)
self.fc2 = nn.Linear(512, 512)
self.dropout2 = nn.Dropout(p=0.2)
self.fc3 = nn.Linear(512, 256)
self.dropout3 = nn.Dropout(p=0.2)
self.fc4 = nn.Linear(256, 256)
self.dropout4 = nn.Dropout(p=0.2)
self.fc5 = nn.Linear(256, 128)
self.dropout5 = nn.Dropout(p=0.2)
self.fc6 = nn.Linear(128, 128)
self.dropout6 = nn.Dropout(p=0.2)
self.fc7 = nn.Linear(128, 64)
self.dropout7 = nn.Dropout(p=0.2)
self.fc8 = nn.Linear(64, 64)
self.dropout8 = nn.Dropout(p=0.2)
self.fc9 = nn.Linear(64, action_size)
def forward(self, x):
x = F.leaky_relu(self.fc1(x), 0.01)
x = self.dropout1(x)
x = F.leaky_relu(self.fc2(x), 0.01)
x = self.dropout2(x)
x = F.leaky_relu(self.fc3(x), 0.01)
x = self.dropout3(x)
x = F.leaky_relu(self.fc4(x), 0.01)
x = self.dropout4(x)
x = F.leaky_relu(self.fc5(x), 0.01)
x = self.dropout5(x)
x = F.leaky_relu(self.fc6(x), 0.01)
x = self.dropout6(x)
x = F.leaky_relu(self.fc7(x), 0.01)
x = self.dropout7(x)
x = F.leaky_relu(self.fc8(x), 0.01)
x = self.dropout8(x)
x = self.fc9(x)
return x
class DQNAgent:
def __init__(self):
self.gamma = 0.98
self.lr = 0.0005
self.epsilon_start = 1 # 初期値
self.epsilon_end = 0.01 # 最小値
self.epsilon_decay = 0.9999 # 減衰率
self.epsilon = self.epsilon_start # 現在のepsilon値
self.buffer_size = 30000
self.batch_size = 32
self.action_size = 4 # 'up', 'down', 'left', 'right'
self.replay_buffer = ReplayBuffer(self.buffer_size, self.batch_size)
self.qnet = QNet(self.action_size).to(device)
self.qnet_target = QNet(self.action_size).to(device)
self.optimizer = optimizers.Adam(self.qnet.parameters(), self.lr, weight_decay=1e-4)
self.scheduler = StepLR(self.optimizer, step_size=100, gamma=self.gamma) # 100ステップごとに学習率を0.9倍にする
def sync_qnet(self):
self.qnet_target.load_state_dict(self.qnet.state_dict())
def get_action(self, state):
# print('state:', state)
# stateがNumPy配列の場合、そのまま使用
if isinstance(state, np.ndarray):
state_array = state
# stateがリストの場合、NumPy配列に変換
elif isinstance(state, list):
state_array = np.array(state)
# stateがタプル形式の場合(NumPy配列と辞書)、最初の要素を使用
elif isinstance(state, tuple) and isinstance(state[0], np.ndarray):
state_array = state[0]
# それ以外の場合はエラー
else:
raise TypeError(f"Unrecognized state format: {state}")
# state_array = np.array(state) #tuple型をリスト型に変換
state_tensor = torch.from_numpy(state_array.flatten()).float().unsqueeze(0).to(device) # NumPy配列をTensorに変換
if np.random.rand() < self.epsilon:
# print('random mode')
return np.random.choice(self.action_size)
else:
# print('qnet mode')
qs = self.qnet(state_tensor)
return qs.argmax().item() # .item() を追加してPythonの数値に変換
def update(self, state, action, reward, next_state, done):
self.replay_buffer.add(state, action, reward, next_state, done)
if len(self.replay_buffer) < self.batch_size:
return None # バッチサイズに達していない場合はNoneを返す
state, action, reward, next_state, done = self.replay_buffer.get_batch()
state = state.view(self.batch_size, -1).to(device) # バッチ処理のために、状態をフラット化
action = action.to(device)
reward = reward.to(device)
next_state = next_state.view(self.batch_size, -1).to(device) # バッチ処理のために、状態をフラット化
done = done.to(device)
# ネットワークの出力と損失の計算
qs = self.qnet(state)
q = qs.gather(1, action.unsqueeze(1)).squeeze(1)
next_qs = self.qnet_target(next_state)
next_q = next_qs.max(1)[0]
target = reward + (1 - done) * self.gamma * next_q
loss = F.mse_loss(q, target)
# バックプロパゲーション
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
return loss # 損失の値を返す
# 学習率のスケジューラを更新する関数
def update_scheduler(self):
self.scheduler.step()
class TileSlidePuzzleEnv:
def __init__(self, size=4):
self.size = size
self.board = np.zeros((self.size, self.size), dtype=int)
self.last_state = None # 前回の状態を保存する変数
self.step_count = 0 # ステップカウンターを追加
# self.reset(mix_count)
def reset(self, mix_count=1):
# ゴール状態を設定
self.board = np.arange(self.size**2).reshape(self.size, self.size)
self.last_state = None # 前回の状態をリセット
self.step_count = 0 # ステップカウンターをリセット
# 指定された回数だけランダムな動きでタイルを混ぜる
for _ in range(mix_count):
action = np.random.choice(4)
self.slide_tile(action)
return self.board.flatten()
def step(self, action):
# タイルをスライドさせるロジックを実装
# actionはタイルを移動する方向(例: 0=上, 1=下, 2=左, 3=右)
# print('action:', action)
# ステップカウントを更新
self.step_count += 1
# 現在の状態を保存
current_state = self.board.flatten()
moved = self.slide_tile(action)
# self.display()
# 次の状態(フラット化されたボード)
next_state = self.board.flatten()
# 報酬の計算
if not moved:
reward = -1
elif self.last_state is not None and np.array_equal(self.last_state, next_state):
reward = -1 # 2回前と同じ動きの場合
elif self.step_count > 100:
reward = -0.1 # 100ステップを超えた場合
else:
reward = self.calculate_reward() * 0.01
# ゲーム終了条件のチェック
done = self.is_solved()
if done:
reward = 50
elif self.step_count == limit_slide_count:
reward = -10
# print('reward:', reward)
# 状態の更新
self.last_state = current_state
# 追加情報(空の辞書を返す)
info = {}
# next_state, reward, done, infoを返す
return next_state, reward, done, info
def slide_tile(self, direction):
# 空白タイルの位置を見つける
x, y = np.where(self.board == 0)
x, y = int(x), int(y)
moved = False # タイルが動いたかどうかを追跡する変数
if direction == 0 and x < self.size - 1:
self.board[x, y], self.board[x+1, y] = self.board[x+1, y], self.board[x, y]
moved = True
elif direction == 1 and x > 0:
self.board[x, y], self.board[x-1, y] = self.board[x-1, y], self.board[x, y]
moved = True
elif direction == 2 and y < self.size - 1:
self.board[x, y], self.board[x, y+1] = self.board[x, y+1], self.board[x, y]
moved = True
elif direction == 3 and y > 0:
self.board[x, y], self.board[x, y-1] = self.board[x, y-1], self.board[x, y]
moved = True
return moved
def calculate_reward(self):
# 報酬の計算ロジック
# 例:正しい位置にあるタイルの数を報酬とする
correct_tiles = np.sum(self.board == np.arange(self.size**2).reshape(self.size, self.size))
return correct_tiles
def is_solved(self):
# パズルが解かれたかどうかをチェック
return np.array_equal(self.board, np.arange(self.size**2).reshape(self.size, self.size))
def display(self):
# パズルの現在の状態を表示
print(self.board)
def render(self):
print(self.board)
episodes = 100000
sync_interval = 20
limit_slide_count = 200
# タイルスライドパズル環境のインスタンス化
env = TileSlidePuzzleEnv()
agent = DQNAgent()
# 各エピソードの報酬を記録するリスト
reward_history = []
loss_history = []
start_time = time.time() # 開始時刻を記録
for episode in range(episodes):
# エピソードごとにタイルを混ぜる回数を計算
mix_count = min(1 + (episode // 100), 50)
print('----- ----- episode:', episode, ' ----- -----')
state = env.reset(mix_count)
done = False
total_reward = 0
total_loss = 0
slide_count = 0
step_count = 0
while not done:
slide_count += 1
# print('----- ----- episode:', episode, ' ----- -----')
# print('slide _count:', slide_count)
# 行動をランダムで選択
action = agent.get_action(state)
# 行動後の状態を変数に代入
next_state, reward, done, info = env.step(action)[:4]
loss = agent.update(state, action, reward, next_state, done)
if loss is not None:
total_loss += loss.item() # 損失の合計を更新
state = next_state
total_reward += reward
step_count += 1
if done:
total_reward = 10000
# print('total_reward:', total_reward)
if slide_count >= limit_slide_count:
done = True
# エピソード終了時にepsilonを更新
agent.epsilon = max(agent.epsilon_end, agent.epsilon_decay * agent.epsilon)
# エピソード終了時にスケジューラを更新
agent.update_scheduler()
if episode % sync_interval == 0:
agent.sync_qnet()
reward_history.append(total_reward)
loss_history.append(total_loss / step_count if step_count > 0 else 0)
print(f"Episode {episode}: Total Reward = {total_reward}, Average Loss = {loss_history[-1]}")
end_time = time.time() # エピソードの終了時刻を記録
episode_duration = end_time - start_time # エピソードの実行時間を計算
print(f"Duration = {episode_duration:.2f} seconds")
print(reward_history)
# エピソード番号のリストを生成
episodes = list(range(len(reward_history)))
# チェックポイントの保存
torch.save(agent.qnet.state_dict(), "dqn_tile_slide_model.pth")
# グラフの作成
plt.figure(figsize=(10, 6))
plt.plot(episodes, reward_history, marker='o')
plt.title('Episode vs Total Reward')
plt.xlabel('Episode')
plt.ylabel('Total Reward')
plt.grid(True)
plt.show()
以下に、紹介した記事のプログラムと、上記のプログラムの変更点を記載します。
■ニューラルネットワーク
①アクションサイズの変更(9→16)
②ニューラルネットワークの層を増幅(6層→9層)
■学習
③アクションのランダム率の減衰率を変更(0.9995→0.9999)
④重み減衰(L2正則化)の変更(1e-5→1e-4)
⑤学習当初の盤面の難易度調整(50ステップシャッフル→1ステップシャッフルから上昇)
⑥学習回数の増幅(20000→100000)
⑦1episodeごとのstep数を変更(500→200)
■報酬
⑧報酬の条件を変更
■結果
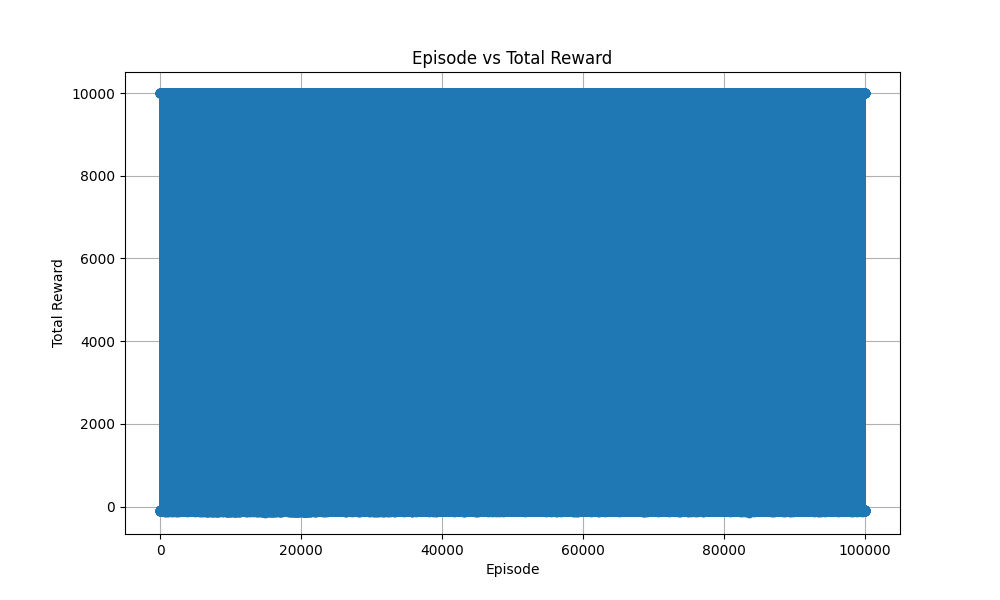
上記のプログラムを実行すると、以下の結果となった。
これは、右に行けば行くほど、学習が進んでおり、その時の報酬の総和をプロットしています。
また、10000にプロットされているケースは、ゲームをクリアしているケースです。
(10ステップ前後でクリアできるような盤面はクリアできるって感覚です。)
作成したモデルの確認(15パズル)
以下のプログラムを実行し、モデルを検証する。
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
# GPUが利用可能か確認し、利用可能なら使用する
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class QNet(nn.Module):
def __init__(self, action_size):
super().__init__()
self.fc1 = nn.Linear(16, 512) # 入力サイズを16に変更(15パズル用)
self.dropout1 = nn.Dropout(p=0.2)
self.fc2 = nn.Linear(512, 512)
self.dropout2 = nn.Dropout(p=0.2)
self.fc3 = nn.Linear(512, 256)
self.dropout3 = nn.Dropout(p=0.2)
self.fc4 = nn.Linear(256, 256)
self.dropout4 = nn.Dropout(p=0.2)
self.fc5 = nn.Linear(256, 128)
self.dropout5 = nn.Dropout(p=0.2)
self.fc6 = nn.Linear(128, 128)
self.dropout6 = nn.Dropout(p=0.2)
self.fc7 = nn.Linear(128, 64)
self.dropout7 = nn.Dropout(p=0.2)
self.fc8 = nn.Linear(64, 64)
self.dropout8 = nn.Dropout(p=0.2)
self.fc9 = nn.Linear(64, action_size)
def forward(self, x):
x = F.leaky_relu(self.fc1(x), 0.01)
x = self.dropout1(x)
x = F.leaky_relu(self.fc2(x), 0.01)
x = self.dropout2(x)
x = F.leaky_relu(self.fc3(x), 0.01)
x = self.dropout3(x)
x = F.leaky_relu(self.fc4(x), 0.01)
x = self.dropout4(x)
x = F.leaky_relu(self.fc5(x), 0.01)
x = self.dropout5(x)
x = F.leaky_relu(self.fc6(x), 0.01)
x = self.dropout6(x)
x = F.leaky_relu(self.fc7(x), 0.01)
x = self.dropout7(x)
x = F.leaky_relu(self.fc8(x), 0.01)
x = self.dropout8(x)
x = self.fc9(x)
return x
class TileSlidePuzzleEnv:
def __init__(self, size=4):
self.size = size
self.board = np.zeros((self.size, self.size), dtype=int)
self.reset()
def reset(self):
# ゴール状態を設定
self.board = np.arange(self.size**2).reshape(self.size, self.size)
# 一定回数のランダムな動きでタイルを混ぜる
for _ in range(50): # 例えば50回のランダムな動き
action = np.random.choice(4)
self.slide_tile(action)
return self.board.flatten()
def step(self, action):
# タイルをスライドさせるロジックを実装
# actionはタイルを移動する方向(例: 0=上, 1=下, 2=左, 3=右)
print('action:', action)
moved = self.slide_tile(action)
self.display()
# 次の状態(フラット化されたボード)
next_state = self.board.flatten()
# 報酬の計算(例:正しい位置にあるタイルの数)
reward = self.calculate_reward()
print('reward:', reward)
# ゲーム終了条件のチェック
done = self.is_solved()
# 追加情報(空の辞書を返す)
info = {}
# next_state, reward, done, infoを返す
return next_state, reward, done, info
def slide_tile(self, direction):
# 空白タイルの位置を見つける
x, y = np.where(self.board == 0)
x, y = int(x), int(y)
if direction == 0 and x < self.size - 1:
self.board[x, y], self.board[x+1, y] = self.board[x+1, y], self.board[x, y]
elif direction == 1 and x > 0:
self.board[x, y], self.board[x-1, y] = self.board[x-1, y], self.board[x, y]
elif direction == 2 and y < self.size - 1:
self.board[x, y], self.board[x, y+1] = self.board[x, y+1], self.board[x, y]
elif direction == 3 and y > 0:
self.board[x, y], self.board[x, y-1] = self.board[x, y-1], self.board[x, y]
def calculate_reward(self):
# 報酬の計算ロジック
# 例:正しい位置にあるタイルの数を報酬とする
correct_tiles = np.sum(self.board == np.arange(self.size**2).reshape(self.size, self.size))
return correct_tiles
def is_solved(self):
# パズルが解かれたかどうかをチェック
return np.array_equal(self.board, np.arange(self.size**2).reshape(self.size, self.size))
def display(self):
# パズルの現在の状態を表示
print(self.board)
def render(self):
print(self.board)
def play_with_model(env, model):
state = env.reset()
env.display()
done = False
total_reward = 0
while not done:
state_tensor = torch.from_numpy(state.flatten()).float().unsqueeze(0).to(device)
with torch.no_grad():
action = model(state_tensor).argmax().item()
next_state, reward, done, _ = env.step(action)
# env.display()
state = next_state
total_reward += reward
if done:
print("Puzzle solved!")
break
print(f"Total Reward: {total_reward}")
# 環境とモデルの初期化
env = TileSlidePuzzleEnv()
model = QNet(action_size=4).to(device)
# 学習済みモデルの読み込み
model_path = "dqn_tile_slide_model.pth"
model.load_state_dict(torch.load(model_path))
model.eval() # 推論モードに設定
# ゲームの実行
play_with_model(env, model)
このプログラムはGPUがなくても動作します。
ハイパーパラメータを更新して、15パズルもどんな盤面でもクリアできるAIを作成してみてください。
(現在、手元で70パターン試しましたが、まだ完成していません。)