総論
現在運用しているAITuber"読書家AIみにこねこ"のシステム概要について述べる。
開発の経緯
元々自身がYoutubeにて本紹介の動画を5年に渡り投稿していた。
しかし、自身で動画を撮ることに対する時間の制約、および「可愛いキャラクターが本紹介をした方が伸びるのではないか」という思いがあった。
そんな折、OpenAI社よりchatGPT(GPT3.5)が世に輩出され、AITuberの実現性がいよいよ高くなったように感じた。私自身はExcelVBAくらいしか書けなかったが、chatGPTによりPython等のプログラミング言語を学びやすくなったことで、技術的なハードルも下がった。
以上の理由により、2023年1月頃よりAITuberの開発を始め、いくつかのバージョンを経た上で、現在に至っている。
AITuberシステムの構成
AITuberシステムの構成は、大別して以下に分かれる。
- テキスト生成
- AITuberのコントロール
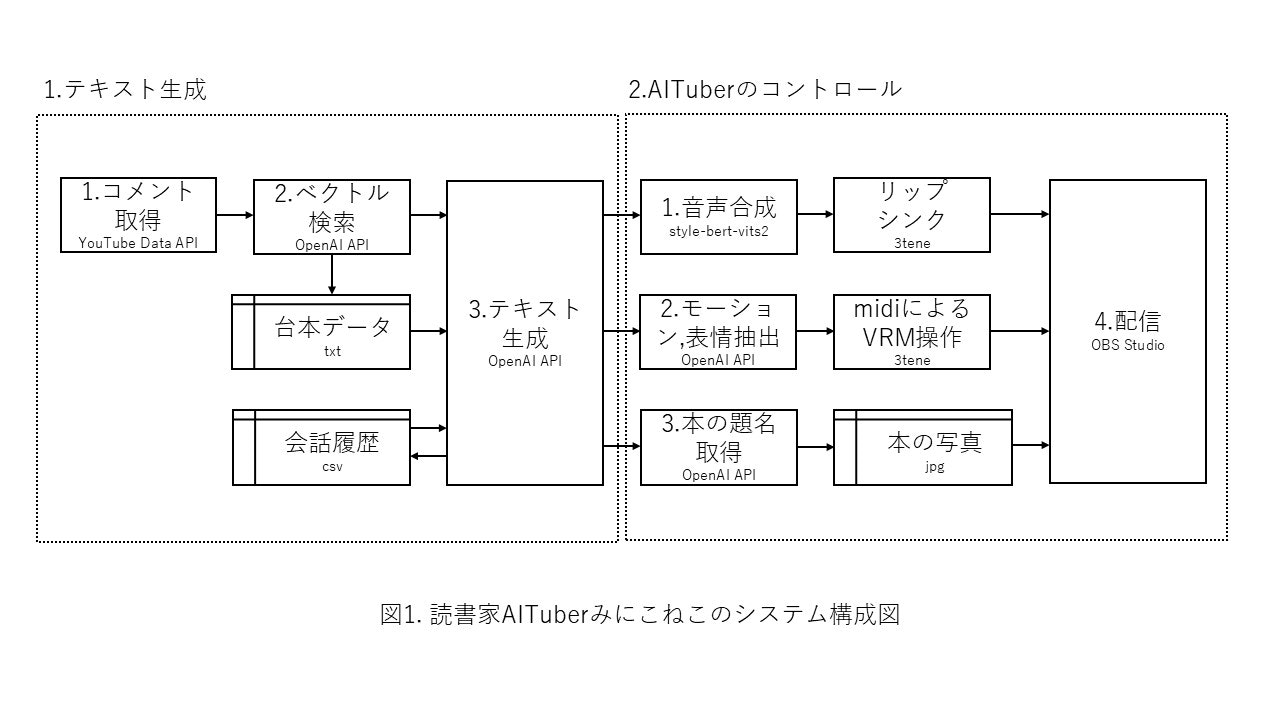
以下それぞれについて記載する。
なお、システムはPythonでローカルに構築されている。
- テキスト生成
- コメント取得
Youtube Data APIより視聴者のコメントを取得する。
なお、視聴者のコメントがない場合は、「オススメの本について教えて」「読んだ本について教えて」等の仮想コメントが定期的に作られるようになっている。 - ベクトル検索
視聴者コメントを元に、OpenAI社の"text-embedding-3-small"を用いてベクトル検索を用いて、自身のYoutube動画の台本である約1400のtxtファイルから、最大8つ選択して取得する。
なお台本データは1ファイルにつき4000文字程度である。 - テキスト生成
視聴者のコメント、取得した台本データ、会話履歴(過去10回分)、およびAITuberの性格情報をプロンプトに組み込み、OpenAI社の"gpt-4o-mini"を用いてテキストを生成する。
生成されたテキストは会話履歴に格納される。
- コメント取得
- AITuberのコントロール
- 音声合成
生成されたテキストを元に、"style-bert-vits2"を用いて音声合成を行う。
VRMを操作可能なソフトウェアである"3tene"を用いて、合成された音声を元にリップシンクを行う。
なお、VRMは"VRoid Studio"を用いて作成した。 - モーション、表情抽出
生成されたテキストから、OpenAI社の"gpt-4o-mini"のFunction Callingを用いて、モーション(speech,dance等)および表情(happy,angry等)を抽出する。
抽出したモーション、表情を仮想midiの入力に変換し、"3tene"上でVRMを操作する。
3teneでは100近いモーションや5種類の表情があらかじめ登録されており、キーボードやJoyPad、midiなどで操作可能なため、AITuberのコントロールに非常に有用である。 - 本の題名取得
生成されたテキストから、OpenAI社の"gpt-4o-mini"のFunction Callingを用いて、本の題名を抽出する。それを元に本の写真データを表示する。 - 配信
音声、VRM、本の写真、その他のデータを配信ソフトである"OBS Studio"にまとめて配信する。
- 音声合成
今後の課題
ニッチなターゲット
ターゲットを「海外古典文学」and「AITuber」に置いているが、そもそも両分野が共に狭いため、掛け合わされたものが非常にニッチになってしまっている。
「海外古典文学」or「AITuber」をターゲットとできるような成果物を作成していく必要がある。
真の価値提供
現在提供できている価値は「本についてのお喋りを楽しむ」「オススメの本を知ることができる」であると思われるが、AITuberが提供する価値として、それが正しいか疑問である。
AITuberだからこそ提供できる本質的な価値、を見極めて、それを成果物に反映させていく必要がある。
最後に
硬く書きましたが、AITuberについて考えている時(+良書を読んでいる時)が、一番楽しいです。今後も試行錯誤しながら、理想のAITuberの開発に勤しんでいきたいと思います。
また、ここに至るまでに、いろんな先人の皆様方のサイトを参考にさせていただきました。本記事が、AITuberの普及に少しでも役立てば幸いです。