はじめに
本記事は流体シミュレーションの手法のひとつである格子ボルツマン法をVRChat上で実装してみたお話
VRChatの制約上、スクリプトやComputeShaderは使用できないのでCustomRenderTexture+Shaderのみでの実装
多分VRChatに持ち込めるものとしては、もっとも計算効率が良い実装のはず (未検証)
【Air Flow Cyclone】
— じゃき@邪気眼GPGPUptr (@konchannyan) March 22, 2020
三次元の流体シミュレーションで遊べるワールドをアップロードしたよ!!
VRでベクトル場の中に!
「Cyclone」で検索!
[BGM by ayato sound create]#VRC #VRChat #MadeWithVRChat#Unity #shader #CustomRenderTexture#CFD #LBM #AirFlowhttps://t.co/mQv4MbgxsW pic.twitter.com/N2yBLyhs3R
本記事の要約
- 格子ボルツマン法(LBM: Lattice Boltzmann Method)とは
- 数値流体力学の手法の1つで、シミュレーション空間を等間隔の格子に区切り、格子毎に計算を行う手法
- 格子毎に計算が独立しているため、GPUによる並列計算に適している
- VRChatと格子ボルツマン法の相性の悪さ
- ComputeShaderが使えない
- 3DのCustomRenderTextureの実装が良くない
- 今回の実装
- 計算格子は64x64x64
- 2DのCustomRenderTexture上に3次元の格子
- CustomRenderTextureでGeometryShaderを利用する
- 魅せ方
- パーティクルの軌跡によって流れを可視化
1. 格子ボルツマン法(LBM: Lattice Boltzmann Method)とは
格子ボルツマン法(LBM: Lattice Boltzmann Method)
格子ボルツマン法は数値流体力学を解く手法のひとつで、計算を行う空間を格子状に分割して計算を行う。流体に見立てた多数の粒子を格子間で行き来きさせ、粒子の動きを流体の流れとして近似する。格子毎に計算が独立しているため並列化しやすく、GPUでの並列計算に有利な手法である。
シンプルな格子ボルツマン法の実装は単相流である。つまり、空気だけ、水だけ、のような感じであり、空気と水が入り混じった二相流(混相流)は別途実装が必要となる。今回はあくまで「VR上で流れ場を感じたい!」という目的を達成するため、空間内に空気だけが満たされている想定となる。
格子ボルツマン法の計算単位である格子には、格子内に存在する粒子の量とその平均速度ベクトルを持つ。1ステップ後のそれらは、自身および周囲の格子の状態をもとに計算される。つまり、格子をセルに見立てれば、各セルに粒子量と流速を持つ、一種のセルオートマトンとしてイメージができる。
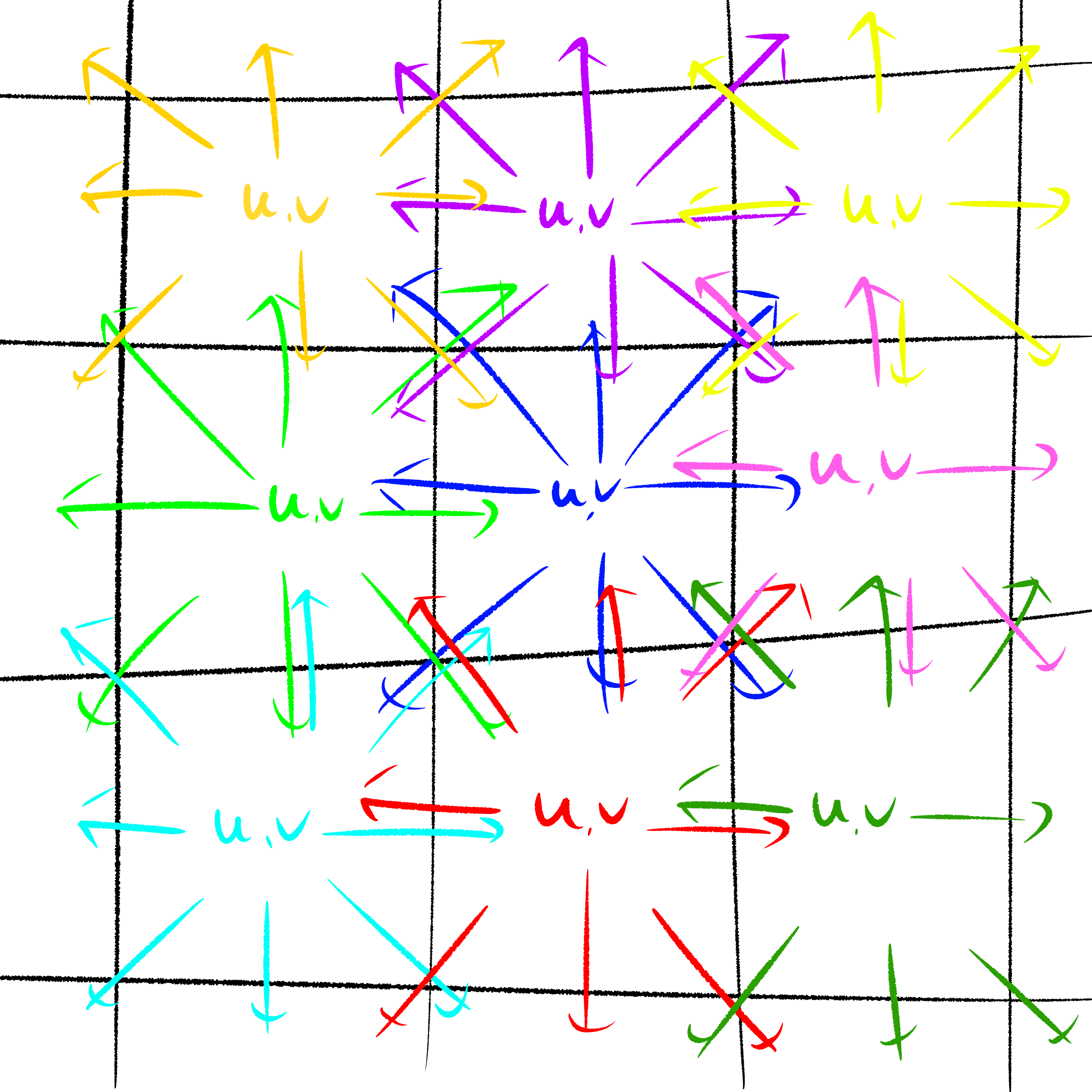
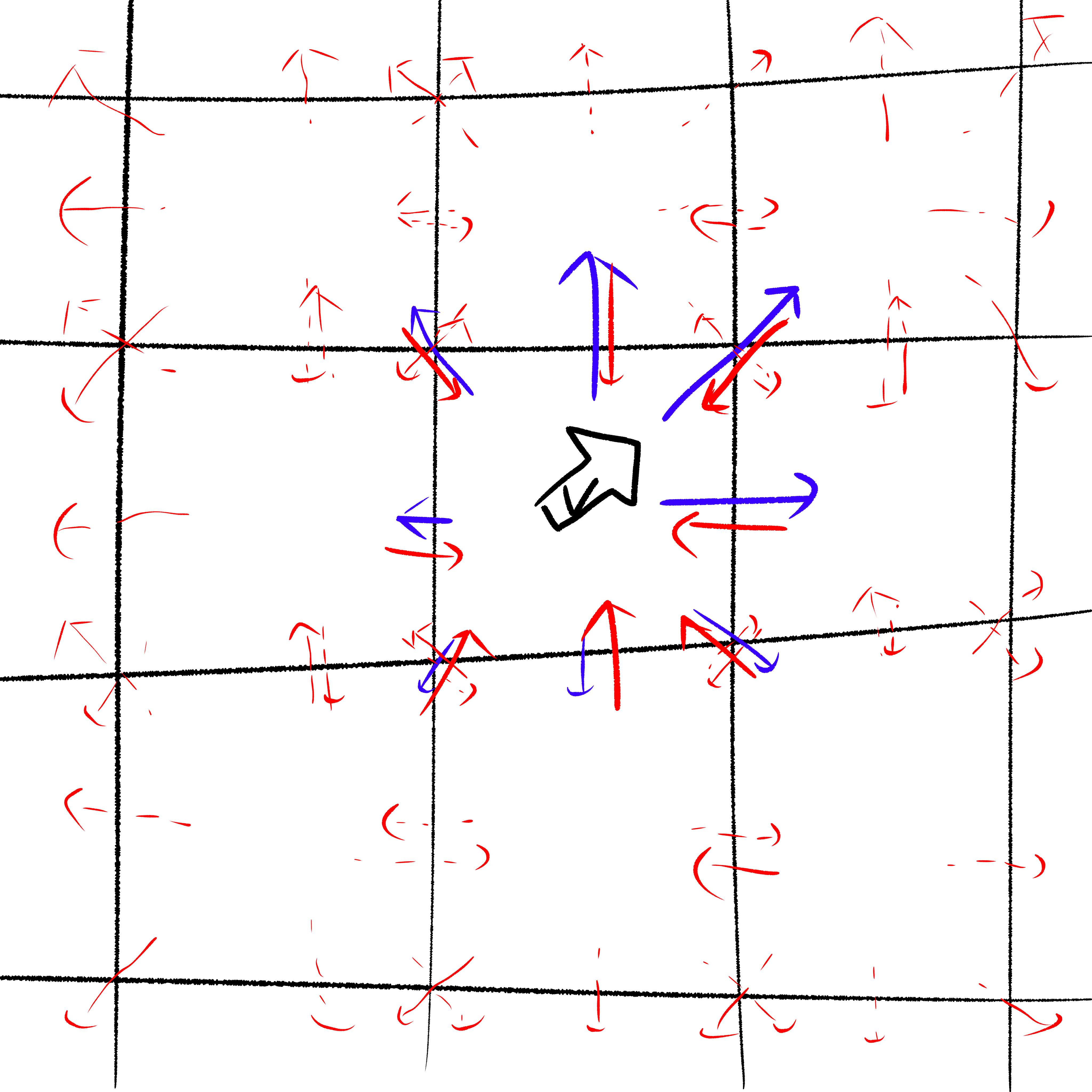
計算1ステップごとに2回の計算を行う。1つ目の計算にはある格子内の流速及び粒子量をもとに、周囲の格子それぞれへ移動する粒子量を求める計算である。流速のベクトルにより、周囲の格子へそれぞれどれだけの粒子が移動するかを決定する(衝突と呼ぶ)。中央の格子における衝突は、下図では青矢印となる。流速が右上へ向いているため、移動する粒子の量に偏りが現れる。2つ目の計算は周囲の格子から移動してきた粒子をまとめる計算であり、移動してきた粒子を合計したものが粒子量に、各格子の方向に粒子量を重み付けしたものが流速となる(並進と呼ぶ)。中央の格子における衝突は、下図では赤矢印が示す。赤矢印(破線)は、周囲の格子における衝突による粒子の移動を示す。
格子ボルツマン法の実装
ComputeShaderを使わない実装では、GPU Gems 2に書かれている手法が一番効率が良いと思われる。その方法を完結にまとめる。
まず前提として、GPUで計算を行うためテクスチャの1テクセルを格子1つと対応させて計算を行う。
計算のおおまかな流れとしては、2回のレンダリングで行われる。衝突を行うレンダリングでは、現在の流速及び粒子の量を元に、周囲の各格子へ移動する粒子の量をテクスチャへと書き出しを行う。並進を行うレンダリングでは、衝突で生成されたテクスチャが周囲の各格子から移動してくる粒子量となるため、その平均を取ることで1ステップ後、つまり更新された流速および粒子の量を求めることができる。
テクスチャは1テクセルあたり、rgbaの4チャンネルがあるためfloatを4つ格納できる。3次元D3Q19では自身を含む周囲19格子への流出量を格納する必要があるため、5枚のテクスチャを利用し、格納が可能である。それに加え格子内の粒子量および流速を1枚のテクスチャに格納する。また、計算には更新元と更新先の2組が必要となるため計12枚のテクスチャが必要になる。
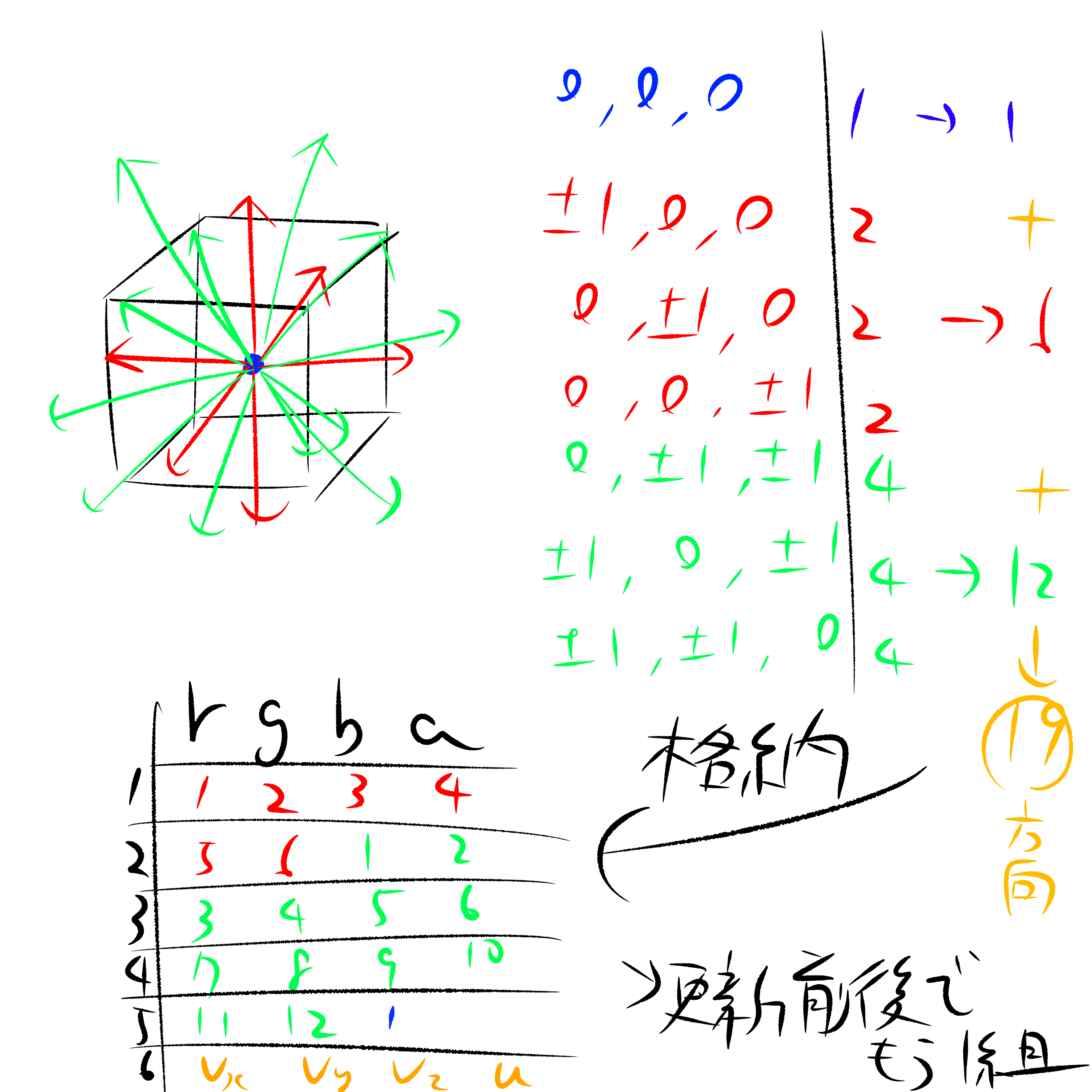
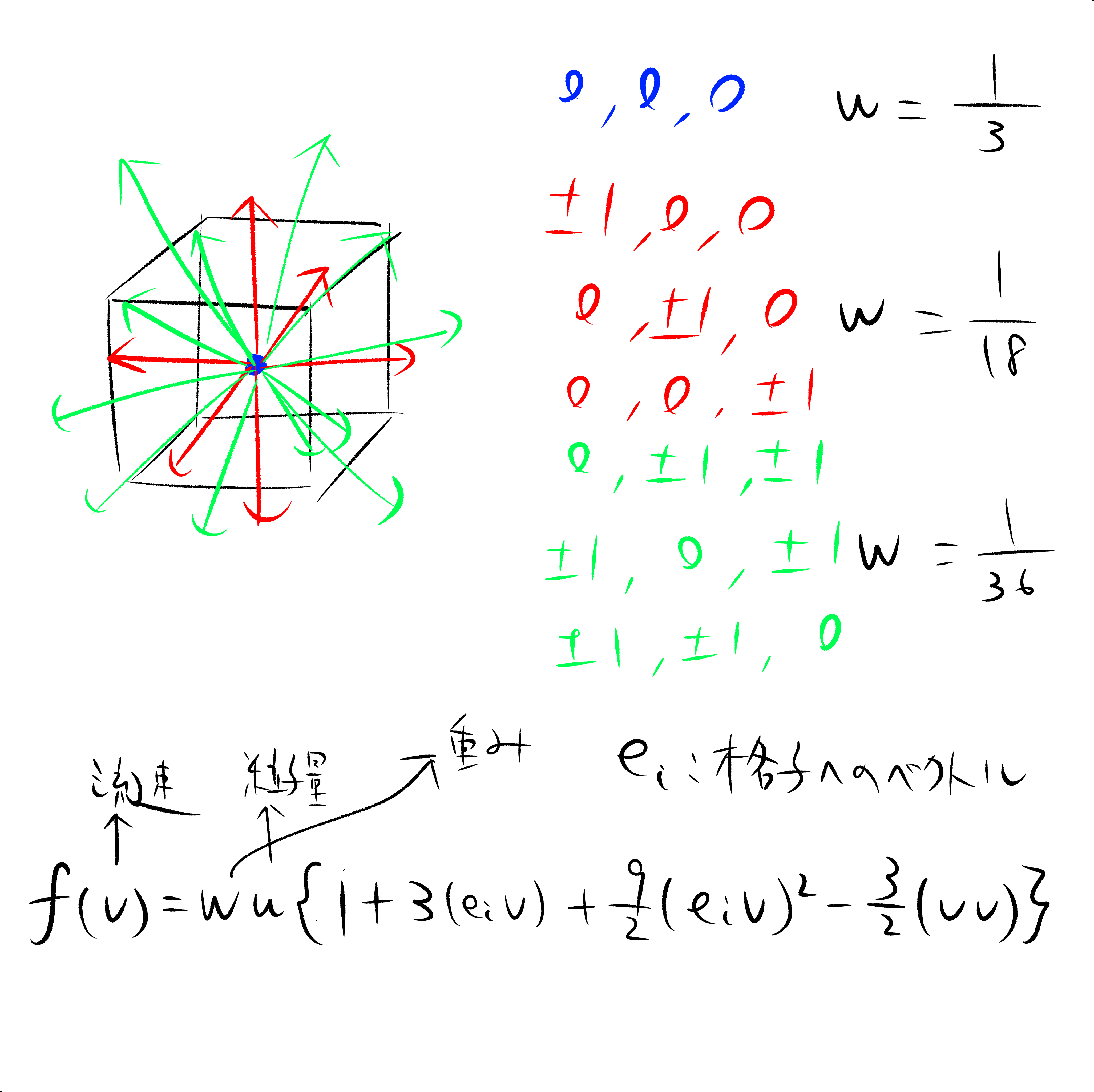
計算は並進・衝突の2つのステップに分かれる。1つ目のステップである並進では、ある格子に含まれる粒子が周囲の格子へそれぞれどれだけ移動するか求める。各格子への移動量は局所平衡分布関数と呼ばれる関数によって求められる。簡略するとおおよそ下図のように表され、各格子への移動方向と流速との内積、および移動方向による重み付けで求められる。重み付けは青色が0成分で留まるもの、赤色が1成分で6近傍のもの、緑色が2成分12近傍のものであり19方向となる。
2つ目の衝突は容易で、並進により周囲の格子から移動してきた粒子を元に流速を更新するだけである。移動してきた粒子の量を重み付けとし、移動方向のスカラー積を取り、その平均をとることで流速が求められる。
これらの計算は格子毎に独立しているため、テクセル毎に計算が独立していると言える。紹介した実装ではPixelShaderの1ピクセルと1格子を対応させている。そして、ある特定の格子の計算=特定の1ピクセルの計算より6テクスチャ分の色情報が吐き出されるが、MultiRenderTargetを使用すれば1DrawCallで6テクスチャに対して書き出しが可能である。つまり、格子数とテクスチャ解像度を対応させた、3DのRenderTextureを2組計12枚使用すれば、たった2回のレンダリングで計算を行うことが可能である。
実装上での要約
- シミュレーション空間は等間隔な格子状に区切られている → 1テクセルに対応させてGPU上で計算を行う
- 各格子は粒子の量(密度場)と粒子の平均速度(速度場)を持つ
- 計算1ステップ毎に2回のレンダリングを要する
- 1回目は、格子の流速ベクトルより格子内に存在する粒子を隣接する周囲の格子へ移動する量を求める計算 (衝突)
- 2回目は、1回目の計算結果より、周囲から移動してきた粒子のアンサンブル平均を取り、粒子量と粒子の平均速度を更新する計算 (並進)
- それらの計算は、計算する格子および隣接する格子のデータを取得&計算する→画像処理におけるフィルター処理に近いイメージ
2. VRChatと格子ボルツマン法の相性の悪さ
さて、このような記載をしなければならないということは、上記で紹介した実装とVRChatとの相性が非常に悪いということである。
前提としてVRChatではスクリプトやComputeShaderが使えない。そうなると必然的にRenderTextureかCustomRenderTextureで実装することになる。
まずCustomRenderTextureを使わない方法としてはCameraやGrabpassを使う方法があるが、float精度のテクスチャフォーマットが使えないという都合上、より大きなテクスチャが必要になり、必然的に読み書きするテクセル数が増えるため効率が落ちる。その上、数値をエンコードして書き出して、読み出してはデコードして…と対応する必要もある。Grabpassに至っては画面解像度等に依存する問題があり、さらに安定性も低いため実用的ではない。
そうなるとCustomRenderTexture一択となるのであるが、CustomRenderTextureでの実装に関していくつかの課題がある。そのひとつとして、そもそも3DのCustomRenderTextureの実装が良くない点である。
まず3DのCustomRenderTextureについてInitializationModeをRealtimeにしても初期化が行われないことである。実はこれに関しては大した問題ではない。なぜならばCustomrenderTextureで初期化を毎フレーム行うことが稀であるため、そもそも毎フレーム初期化する必要が無いからである。(なぜ3DのCustomRenderTextureに限って初期化されないか、という謎は残るが)
次が深刻で、1スライス毎に1回のレンダリングを要する点である。例えば64(w)x64(h)x64(d)の3DのCustomRenderTextureであれば、(d)の64回分ドローコールが走ることになる。本来であれば3Dテクスチャに対して1ドローコールで描画することは可能なため非効率である。CustomRenderTextureが少なくとも1枚の板ポリを描画するのであれば、無理やりすべてのスライスに対して描画するシェーダーを書くことは可能であるため、試してみたが不可能であった(SV_RenderTargetArrayIndexで指定すれば良い)。恐らくドローコールに対して描画対象のスライスのみ描画できるようにViewPortを指定しているものと思わる。つまり1ドローコール内で別スライスに描画することを禁じられているのと同じである。その仕様に干渉する方法は恐らく無いため、計算効率という点で3DのCustomRenderTextureの使用は控えた方が良いということになる。
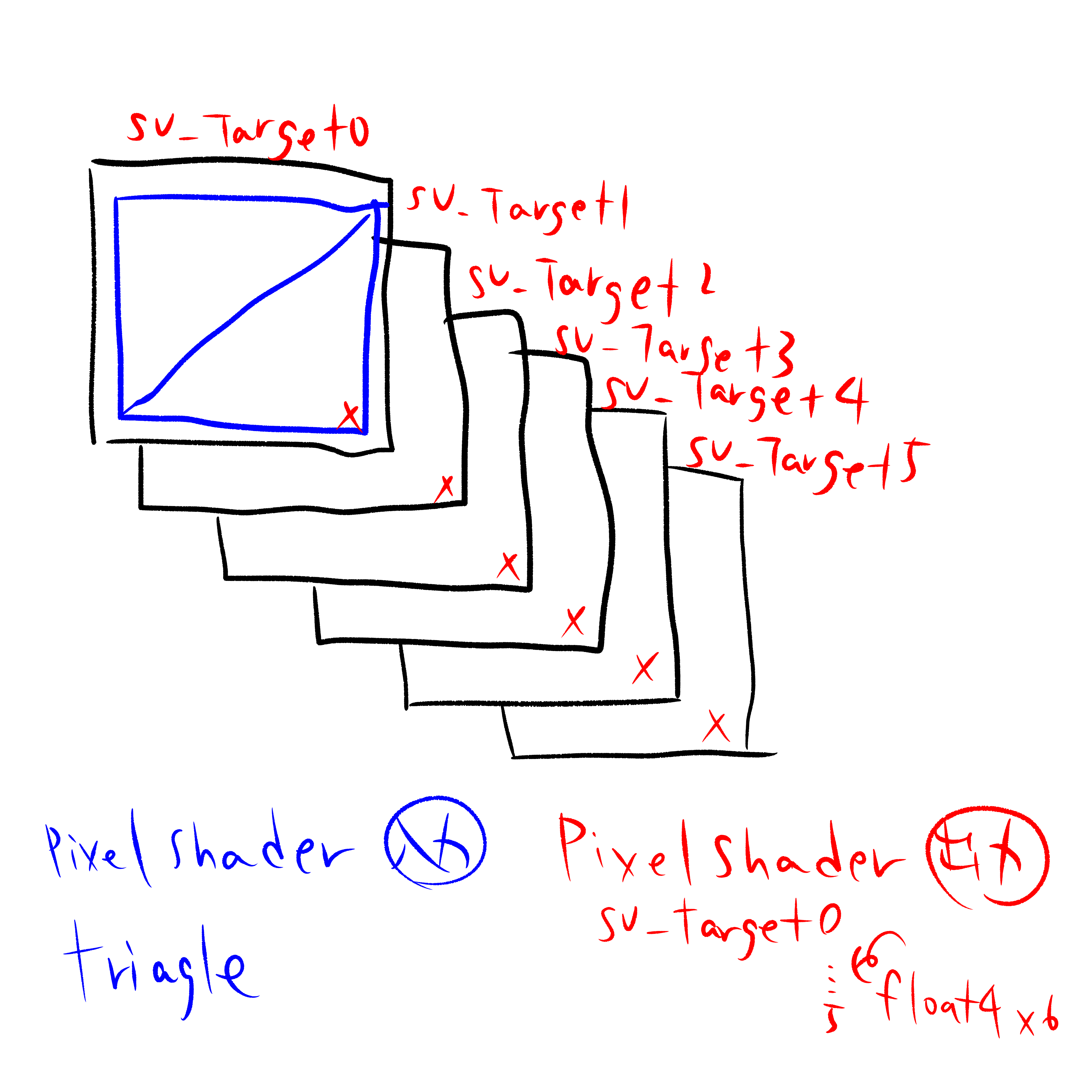
であれば、必然的に2DのCustomRenderTextureにデータを格納することになる。だが、2DのCustomRenderTextureを使うにしても、UnityのCustomRenderTextureにおいて、MultiRenderTargetが使えない。MultiRenderTargetはRenderTargetを複数指定することが可能で、簡単に言えばピクセルシェーダー(フラグメントシェーダー)にて、複数のテクスチャに対してそれぞれ別の色(=データ)を出力することができる機能である。つまり1つ目のrgbaをテクスチャ1へ、2つ目のrgbaをテクスチャ2へ…6つ目のrgbaをテクスチャ6へ…というようなシェーダーが書けるため、1格子が出力する数値を1ピクセルで書き出すことが可能になる。下図がそれを説明しており、2Dのテクスチャを描画する青色のメッシュによってラスタライズされたある1ピクセルに対し、PixelShaderが1回の計算で6枚のテクスチャへ数値を書き出すことができる。しかしながらこの機能が使えないため、PixelShaderだけで実装を行うためにはrgba4成分1組を書き出すために1ピクセルを割り当てる必要がある。そのため6組分のデータを書き出すためには「各ピクセルで6組分の数値を計算した上で、そのうちの1組を選択して書き出す」ような実装が必要となる。
(RenderTextureでMultiRenderTargetの指定は可能ではあるそうだが、確実にスクリプトの記載が必要であるためVRChat上での実現は不可能である。未来永劫VRChat上でその機能が使えることは無いと思う、という期待を込めた希望的フラグ立て発言をしておく)
3. 今回の実装
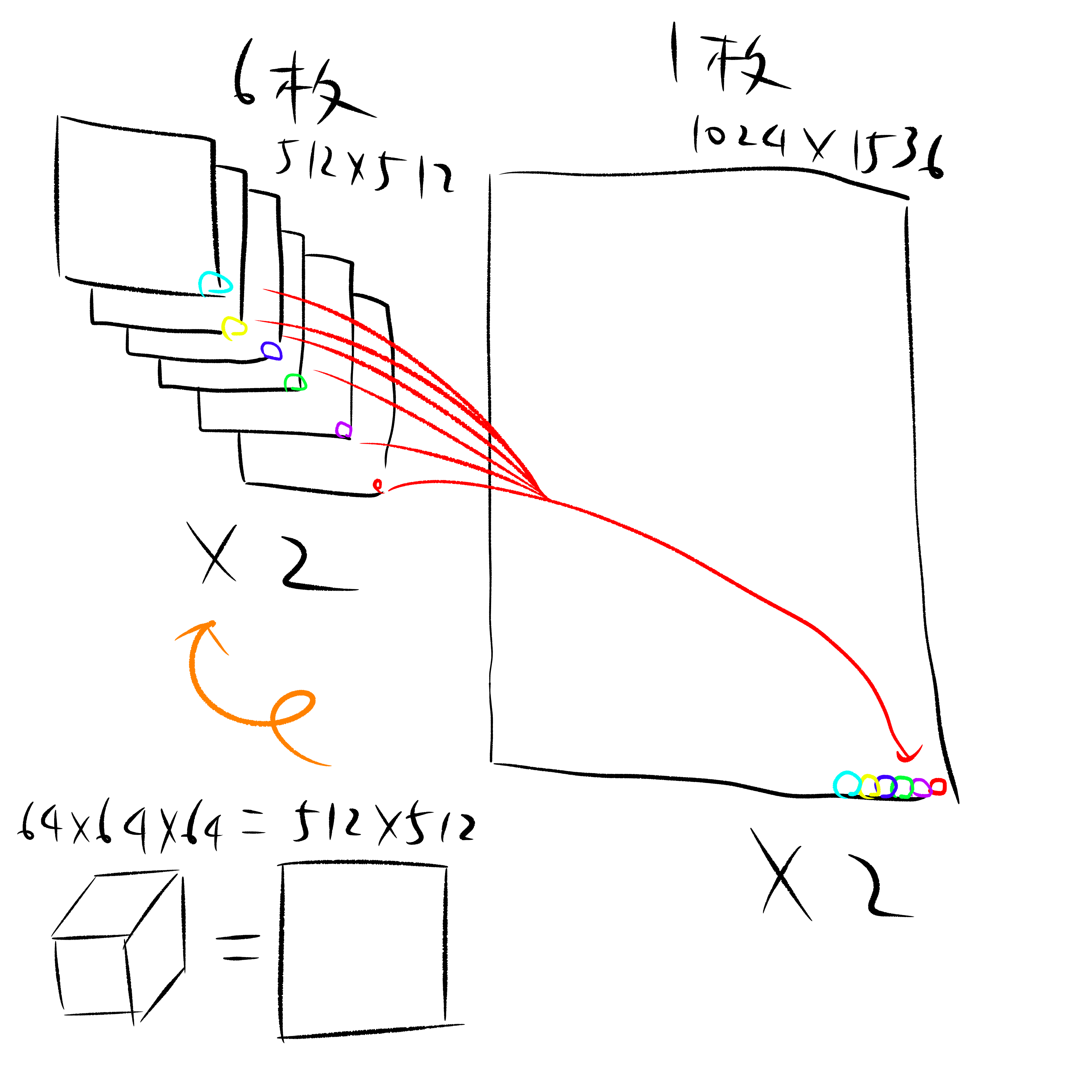
前述の通り3DのCustomRenderTextureでの実装は難しいと考え、2DのCustomRenderTextureを2組用いて計算を行う。また、1組あたり1格子6テクセルが必要になるが、6枚のテクスチャに分割するのではなく、1枚のテクスチャに格納し実装した。
格子の数は1辺64voxel → 64x64x64=512x512より、2Dテクスチャであれば1辺512pixel相当である。これが6枚分必要となるため2x3に並べた1024x1536のテクスチャにデータが格納できる。計算は2ステップのため、ARGBFloat1024x1536のCustomRenderTextureが2枚必要となる。
データの並べ方に関しては、キャッシュ効率を上げるために幾つかの方法が考えられる。計算ステップにより読み書きに適した並べ方が異なるため、最も効率的な並べ方を絞り込めなかった。本実装では下図の通り、特定の格子に対して6枚分に分割されるテクセルが連続して現れるように並べた。
テクスチャの構成が決定したところで、ピクセルシェーダーのみでの実装が可能か考える。CustomRenderTextureではMultiRenderTextureの指定ができないため、1つのPixelShaderから6枚分の計算結果を出力することができない。そのため、6枚分のテクセルすべてにおいて同様の計算を行い、その結果の1つだけを出力する必要があるため「計算結果を破棄しなければならない」という懸念がある。
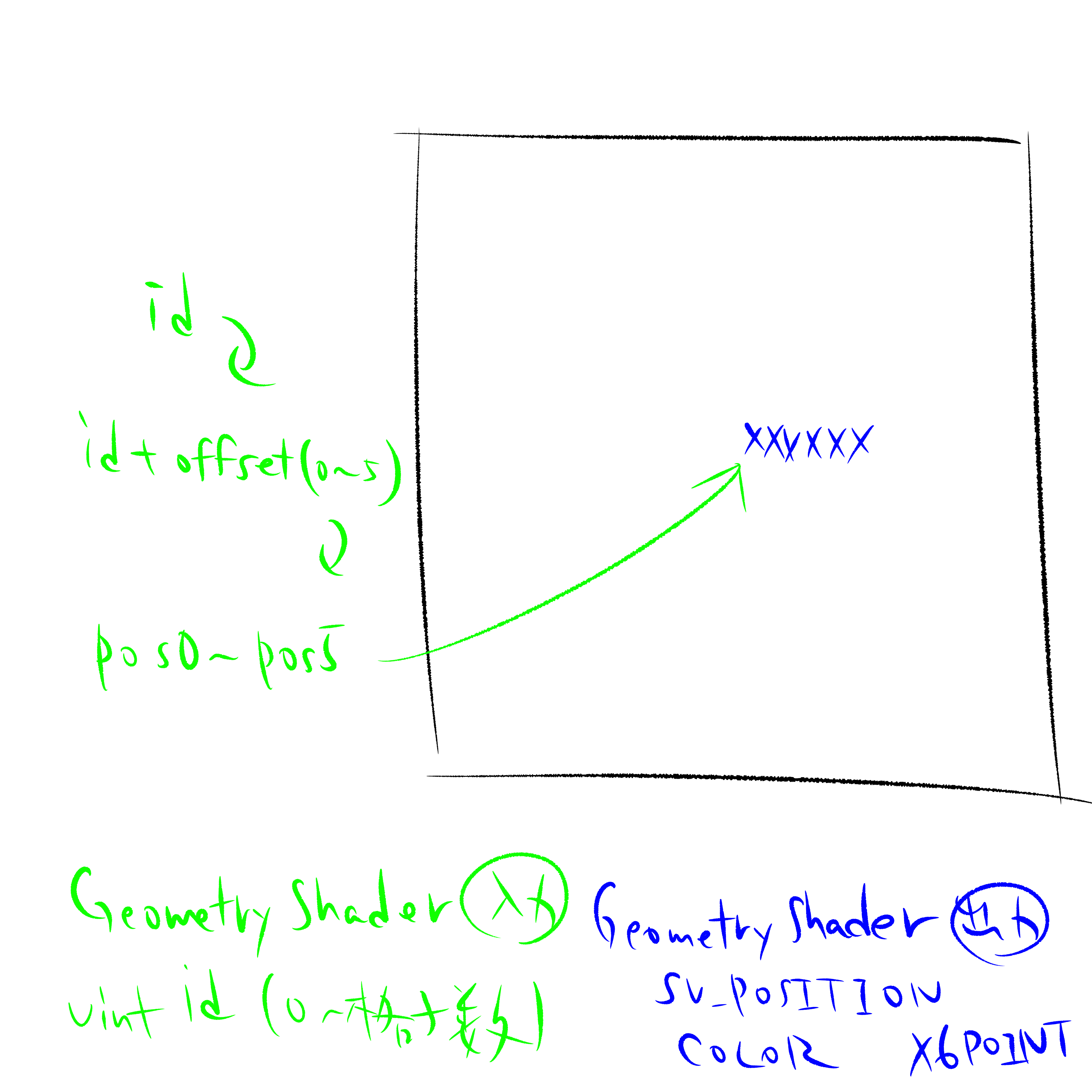
そこでCustomRenderTexture内でGeometryShaderを利用(CustomRenderTextureだけでボリュームレンダリングしてみる!!)することで効率化を行う。下図にGeometryShader以降の処理の概要を下示す。GeometryShaderへの入力はidであり、id毎に計算する1格子を決定し、GeometryShader内で書き出すデータ(float4を6つ分)の計算を行う。GeometryShaderより6ピクセル分のpointを書き出す座標をSV_POSITIONとして出力すれば、PixelShaderでは色情報をそのまま書き出すだけで計算が実装できる。
計算格子を1辺64voxelとした理由についてだが、主な理由としてはVRが動作するGPUにおいてこの解像度であればおおよそ快適に動作するであろう、という見込みからである。また、CustomRenderTexture内でGeometoryShaderを使用した場合にGeometryShaderを発行できる上限が64x64x32(厳密には65x65x32)であり、これを64x64x64にするために1つのGeometryShader毎に2格子分の計算を割り当てることを妥協したためである。単純に計算時間が2倍になるが、1辺32voxelだとやや荒いのでは無いかという懸念があったため解像度を優先した。もちろん、GeometryShaderで16格子分の計算を行えば1辺128voxel、128格子分の計算を行えば1辺256voxelで計算を行うことが可能である。しかしながら、並列化できる処理を逐一処理せざるを得ないため、並列化の効率が格段に落ちる。
ただし「果たしてそこまでして『計算結果を破棄しなければならない』という点を回避する必要があるのか」「逆に割当処理の負荷が過剰にならないか」という懸念があるが、前述した「各ピクセルで6組分の数値を計算した上で、そのうちの1組を選択して書き出す」方法は「無駄を感じる」という曖昧で個人的な理由で実装を見送った。
4. 魅せ方
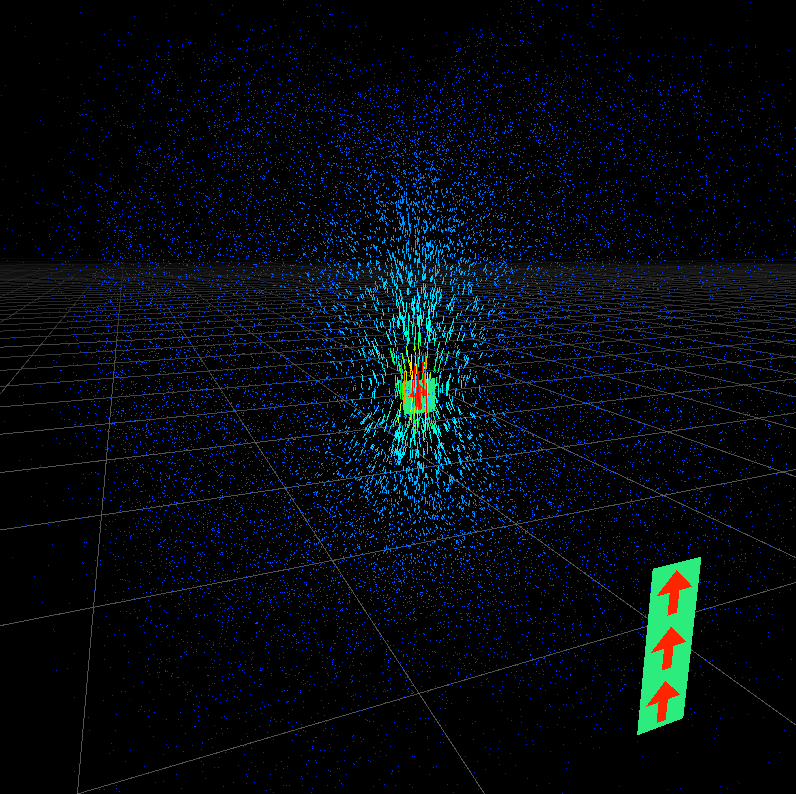
流体に影響を与える入力媒体は、単純に矢印が書かれたPickup可能な板ポリとした。予め計算領域内にシンプルな配置を行うことで、初めてワールドにjoinしたプレイヤーに視覚的な誘導を提供し、説明抜きにワールドの趣旨を伝えることができる。(できているはず)
メインとなる出力(描画)はパーティクルベースでその軌跡とした。CustomRenderTextureを用い空間にGPUパーティクルを実装し、流れ場によって移動させる。2Dのテクスチャに三次元の流れ場を格納しているため専用のサンプラーを実装する必要があった。そしてパーティクルの現在の座標と直前の座標をLineで結び描画する。Lineが連続して移動しているように見えるため、視覚的に流れを認識しやすい。同時に静止画でもある程度流れを把握することができる。流速が小さいところではLineが短くなることで視認しづらくなる=流れが弱い、と認識できる効果もある。
色はパーティクルの移動量に応じた疑似カラー(下図)と、時間で変動する色相環の2つを用意した。
終わりに
実装した方法は効率は良いはずだけれど、実行速度が優れているかは不明である。
3DのCustomRenderTextureは使うべからず。
「VRで流れ場を体感したい!」という目標を達成することができたので非常に満足です。
最近記事を書いていなかったので上手くまとめきれていません。ごめんなさい。日本語的におかしい箇所は見つけ次第修正します。
おまけ (やるべきだろう計算効率検証だけれど、やるのが面倒)
①ComputeShaderでの実装 (データは1次元のバッファ)
多分②と同じぐらい速い
メモリアクセス周りを完全に考慮できれば多分一番速い
Dispatch1回版(並進の完了を待って衝突を行う一連の処理で割当)とDispatch2回版(並進と衝突を別の処理で割当)が書ける
②RenderTargetを複数指定して、複数テクスチャに同時に書き出す実装 (データは2次元のテクスチャ6枚2組→12枚)
つまり1DrawCallで同時に6枚のテクスチャに描画する方法
SV_Target0, SV_Target1, ..., SV_Target5の構造体をフラグメントシェーダーで出力する
衝突とDrawCallは2
③本実装 (データは2次元のテクスチャ1枚2組→2枚)
②と同じぐらい速いと信じたいし、④よりは速いと信じたい
④GeometryShaderは使用せず、計算の重複を無視して、各ピクセルの色を決める (データは2次元のテクスチャ1枚2組→2枚)
あるピクセルの色を決めるために、6ピクセル分の計算が重複する
ピクセルシェーダーで計算するので、より大きなテクスチャで計算が可能になる
⑤3DのCustomRenderTextureを6枚分用意し④と同様の計算を行う
⑥並進と衝突の計算を、1DrawCallで行う
1ピクセルの計算のために数百Loadが走るので鬼のように重い
各ピクセルで重複した計算を行うので効率が悪い