この記事はKaggle1位の解法を解説しているだけで、筆者が1位を取ったわけではありません。
実際に1を取ったCSTORM3000氏を崇めましょう。
前置き
自然言語処理処理職人の皆様こんにちは、いかが処理処理されていますでしょうか。
筆者はインターン先でタイ語の自然言語処理で遊んでいますが、タイ語自然言語処理界の金字塔pythainlpのチュートリアルに面白い極性分類の方式があったので紹介し、日本語で試したいと思います。
その名も、 TFIDFロジスティック回帰 です。
極性分析とは
テキストが与えられて、それが喜んでいる「ポジティブ」か、憎悪に満ち溢れた「ネガティブ」のどちらかに区分けすることです。
- 「俺の彼女はアスナに似てるw」というテキストには
positiveを、 - 「オレンジ今日も食べてみたけどまだ酸っぱくて泣いた」というテキストには
negativeを
返すような、モデルを作りたいわけです。
通常の方法では、単語ごとの極性辞書を作り、その割合で、(あるいはうまいこと機械学習で)文全体の極性を算出するという方法がとられます。
TFIDFロジスティック回帰
チュートリアルで見たときは天才かと驚きましたが、検索すると文書分類の手法としてやっている方がいますね。
TFIDFとは
sklearnのTfidfVectorizerを使用すると、TFIDFという数値が一つ一つの単語に計算されます。
その数値の意味は、 その文章の中でその単語がどれほど特徴付けているか(≒重要か) といわれています。
「 オレンジ 今日 も 食べ てみたけどまだ 酸っぱく て 泣い た」というような感じですね。この文章の中で「オレンジ」「今日」「食べ」「酸っぱく」「泣い」が、この文章を特徴づける重要な単語ということです。
TFIDFロジスティック回帰とは
TfidfVectorizerを用いることにより、文章が単語ベクトル化され、それぞれの数値は その単語の重要度 です。
これで回帰してみたら、すなわちそれぞれの単語に適切な重みを算出すると、どうでしょうか。
「嬉しい」という単語は当然ポジティブなので、かなり重みが付けられることになるのでしょうが、「嬉しい」が重要単語になっている文章はこれによりポジティブになるようにドッとポイントが上がるのです。
その「適切な重み」を出すのがロジスティック回帰というわけです。
日本語でやってみよう!
タイ語のまま紹介しても誰にもわかってもらえないでしょうので、普通に日本語の自然言語処理を扱います。
本プロジェクトのgithubです:https://github.com/konbraphat51/AmazonJP-Sentiment
扱うデータ
日本語を極性別に区分けしたデータセットが意外となかったので、Amazonが出してるレビューのデータセットを使います。
レビューの星の数を極性代わりにするって寸法ですね。
形式はこんな感じです。(関谷 侑希さんの記事から引用)

今回使うのは、テキスト本体のreview_bodyと、極性のstar_ratingですね。
前処理
import pandas as pd
import numpy as np
#もともとのデータ
df_all = pd.read_table("data")
##1
#POSitive
df_pos = df_all[df_all["star_rating"] == 5]
df_pos["label"] = "pos"
#NEGative
df_neg = df_all[df_all["star_rating"] == 1]
df_neg["label"] = "neg"
##2
#POSをNEGと同数になるまで減らす
df_pos = df_pos.sample(df_neg.shape[0], random_state=334)
#pos + neg
df_mix = pd.concat([df_pos, df_neg])
#学習用とテスト用にわける(比率=8.5:1.5)
from sklearn.model_selection import train_test_split
train_df, valid_df = train_test_split(df_mix, test_size=0.15, random_state=334)
train_df = train_df.reset_index(drop=True)
valid_df = valid_df.reset_index(drop=True)
#ラベル(pos, neg)
y_train = train_df["label"]
y_valid = valid_df["label"]
1:データ数は十分あるので、中途半端な星2~4は置いておいて、あからさまにポジティブな星5と、あからさまにネガティブな星1のみを学習データに使います。
2:Positiveなレビュー数が90%以上とかなり偏っていて、このまま学習するとPositiveを過学習してNegativeの検知率がかなり悪くなりました。(github参照)
TFIDFを計算
計算します。
from sklearn.feature_extraction.text import TfidfVectorizer
from MeCab import Tagger
#textを形態素に分解して返す
def tokenize(text):
tagger = Tagger("-O wakati")
return tagger.parse(text).split()
vectorizer = TfidfVectorizer(tokenizer=tokenize, ngram_range = (1,2 ), min_df=10, sublinear_tf=True)
#TFIDFを計算、単語ベクトルを作成
tfidf_fit = vectorizer.fit(df_all["review_body"])
##各データをTFIDF行列に直す
#全データ(星1~5)
text_all = tfidf_fit.transform(df_all["review_body"])
#訓練データ(星1、5)
text_train = tfidf_fit.transform(train_df["review_body"])
#検証データ(星1,5)
text_valid = tfidf_fit.transform(valid_df["review_body"])
TFIDF行列とは、行が文章番号、列が単語の番号、その数値がTFIDF値の行列のことです。
もしその文章に単語がなかったら0が代入されています。(すなわち、ほぼ0です)
学習
from sklearn.linear_model import LogisticRegression
#spycy型を普通の配列に直す
x_train = text_train.toarray()
x_valid = text_valid.toarray()
model = LogisticRegression(C=2, penalty="l2", solver="liblinear", dual=False, multi_class="ovr")
model.fit(x_train,y_train)
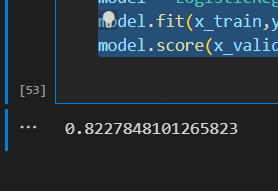
# 検証データの精度を返す
print(model.score(x_valid,y_valid))
結果、82%でした。かなり良い。(全文章でやるとパソコンが破裂するので1万件をランダム抽出しているので、人によって数値がことなると思います)
予測
#予測
label_all = model.predict(text_all)
#記録
df_all["predicted_label"] = label_all
#表示
def get_ratio(df, stars_n, sentiment):
return df[(df["predicted_label"]==sentiment) & (df["star_rating"]==stars_n)].shape[0] / df[df["star_rating"]==stars_n].shape[0]
result = pd.DataFrame(
data = [[get_ratio(df_all, cnt, "pos"), get_ratio(df_all, cnt, "neg")]
for cnt in range(1, 6)],
index = [str(cnt)+"-stars" for cnt in range(1,6)],
columns = ["pos", "neg"]
)
result
その結果、
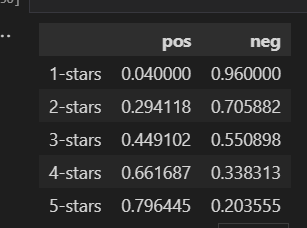
星1ネガティブの検出率がすごく高いのはネガティブ全件を学習データに用いているからですね。星3がポジティブ文章ネガティブ文章が半々になっているのも、なんかすごい。