本編はこちら中国広州市にあるリトルアフリカ、そこにやってくる彼らは実際どこからやってくるのかデータを集めて検証した
本編サマリ: 中国の広州にはアフリカやアラブ系の人が買い付けに来るリトルアフリカがあるらしいと本で読んだので実際に行ってきた。なるほど現地には黒人やアラブ人がたくさんいた。ところが本によるとタンザニアの人が多いと言う話だったが、正直誰がタンザニア人かどうかなんて区別がつかなかった。そこでリトルアフリカにタグ付けしてInstagramに写真を上げている人を追跡して統計データをとったところタンザニア人が多いということを確認した。(オレは一体何をしているんだ)
Qiitaのこの記事ではInstagramのスクレイピング方法を紹介する。
すげぇ雑に結果をプロットしたのはこんなの詳しくは本編へ
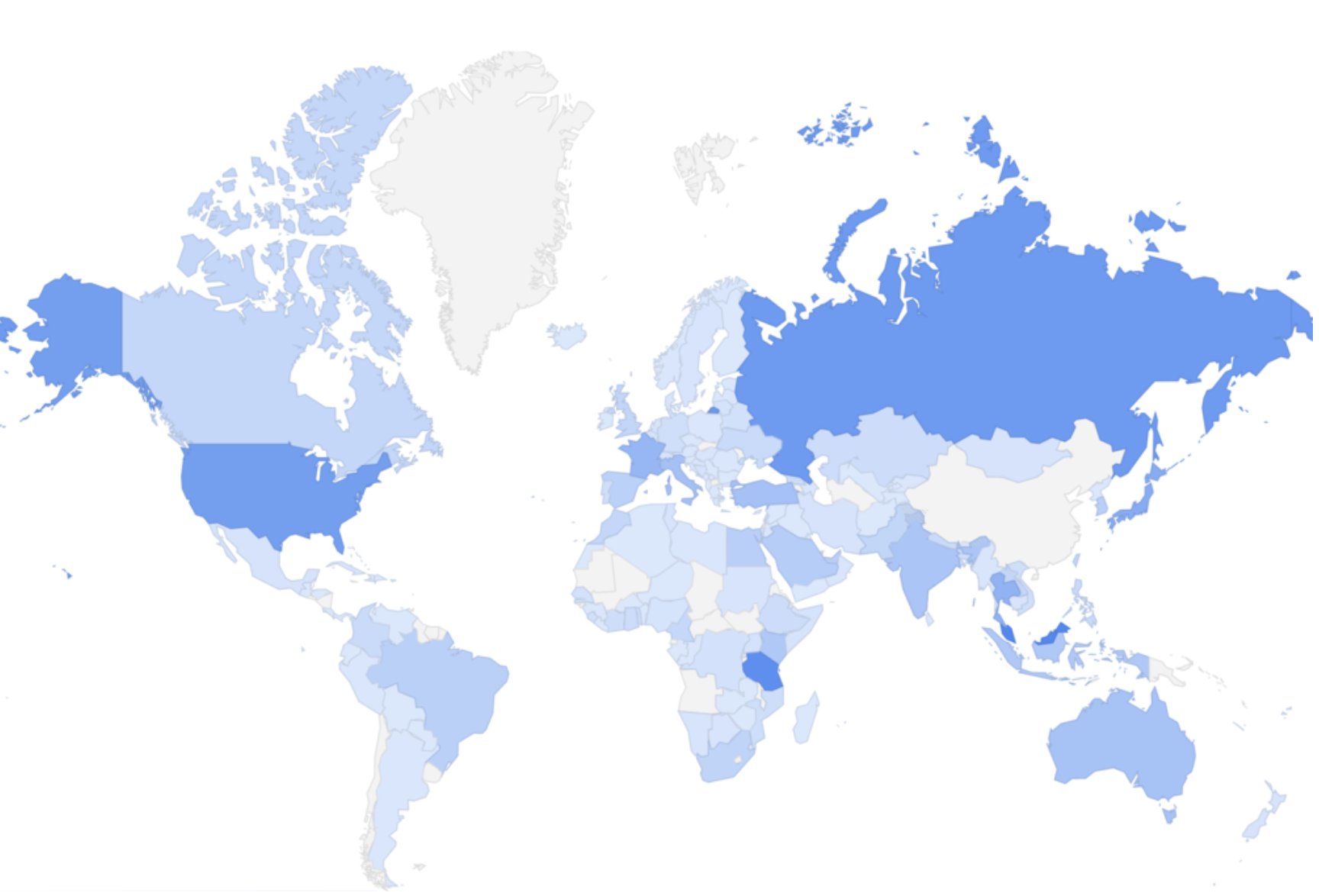
https://datastudio.google.com/embed/reporting/1RdZUJZ6MIXuPh6-hIqzknKyNVsfSsLr1/page/R60Y
 https://www.google.com/maps/d/embed?mid=1cm6NFsdHSo0M_r8U_mdzi_9Pjpu35s5f
https://www.google.com/maps/d/embed?mid=1cm6NFsdHSo0M_r8U_mdzi_9Pjpu35s5f
こっから先は技術編
InstagramのAPIは2018年の4月あたりで他の人のデータを取得できなくなってしまった。そこでInstagramの多分Web版スクレイピングするライブラリがPythonであったの利用してみることにした
instagram-scraperでインスタグラムをスクレイピング
instagram-scraperの画像をスクレイピングしてくれるライブラリ
pipでインストールできる
pip install instagram-scraper
instagram-scraper TARGET_USER_NAME -u USER_NAME -p PASSWORD
TARGET_USER_NAME: スクレイピングしたいユーザのユーザ名
USER_NAME 自分のインスタグラムのユーザ名
PASSWORD: 自分のインスタグラムのパスワード
パラメータはこんな感じのものがあり
最大DL枚数
--maximum
DLするファイル選択
-t or --media-types
none #DLしないでメタデータだけ取得できる
image #画像データだけ欲しい時(ビデオは含まない)
メタデータが欲しい時
--media-metadata
メタデータに場所データを付ける
--include-location
locationIDで場所指定
--location
これでTARGET_USER_NAMEの画像をDLしないでJSON形式のメタデータを含んで取得できる
instagram-scraper TARGET_USER_NAME -u USER_NAME -p PASSWORD --maximum 150 --media-metadata --include-location -t none
これで取得できたデータのうち、位置情報は下記のように形式で取得できる。
ただし、対象の国にちゃんと住所があるかのほうが問題?ジンバブエとか変なデータが多い
"location": {
"address_json": "{\"street_address\": \"\", \"zip_code\": \"\", \"city_name\": \"Aberdeen, Hong Kong\", \"region_name\": \"\", \"country_code\": \"HK\"}",
"has_public_page": true,
"id": "234884489",
"name": "Aberdeen, Hong Kong",
"slug": "aberdeen-hong-kong"
},
instagram-scraperでの取得の仕方がわかった次は、ある特定の場所で投稿しているデータを集める
InstagramのlocationIDをしらべる
InstagramのWeb版で場所を検索して表示したURLは下記のように形式をしている
小米駅のURL: https://www.instagram.com/explore/locations/346112693/xiaobei-station/
このURLのlocationsの後ろの346112693がlocationID
locationIDを元に小米駅のデータをinstagram-scraperを使って下記コマンドで取得する
instagram-scraper --location 346112693 -u USER_NAME -p PASSWORD --maximum 1000 --media-metadata --include-location -t none
小米取得したJSONデータからショートコードを取得する
先のコマンドで取得したデータではユーザ名がわからないが、そのかわりshortcodeを取得することはできる
ショートコードを元にした1画像の詳細データ
jsonデータから、shortcodeを取得したらあるユーザの画像データを取得することができる。
https://www.instagram.com/p/BnxfaxpHcnP/?__a=1
instagram-scraperで取得した小米駅のメタデータのJSONをパースして、shortcodeを抜き出し、shortcodeを元に詳細データを取得して
画像をアップロードしたユーザ名のリストをテキスト取得(username_list.txt)
ユーザ名のリストをゲットしたので、そのユーザ名の画像のメタデータからlocation付きで取得していく
ユーザ名のリストを元に再びinstagram-scraper各ユーザごと最新151枚ずつ分のメタデータを取得していく
instagram-scraper -f username_list.txt -u USER_NAME -p PASSWORD --media-metadata --include-location -d images -t none --maximum 200
余談:maximumを100にすると何故か51枚の画像で終わる。maximumを200にすると何故か151枚の画像で終わる 多分1ページめの画像が50でプロフィール画像が1枚の仕様のせいだと思われる。
各ユーザのアップした画像のJSONデータを元にTSVを作成する
Googleスプレッドシートで加工しやすいように、下記のように各ユーザのJSONデータをパースしてTSVに変換した
- 画像のインスタグラムURL ショートコードプラスURLを結合したもの
- 画像の直のURL
- username
- user_id:
- 国コード 2レターコード USとかJPとか
- 住所: locationデータをいい感じに結合する
- 日付: UNIXタイム
スプレッドシートに貼り付けたデータはこんな感じ
TSVまで作ったらあとはGoogle Colabで読み込ませてPandasでゴニョゴニョやれば良い
詳細は下記のリンクから
中国広州市にあるリトルアフリカ、そこにやってくる彼らは実際どこからやってくるのかデータを集めて検証した