はじめに
この記事は、バーチャルYoutuberに関するデータ解析を行った以下の記事、
データで見るバーチャルYoutuber-”四天王”の過去と現在
において行った、Youtube Data APIを用いたデータ収集方法に関して解説するものです。
各バーチャルYoutuberが投稿したすべての動画タイトル、投稿日、再生回数、高/低評価数、コメント数、再生時間を収集対象としています。
前準備-環境設定
本データ解析ではPythonを用いてYoutube Data APIを利用します。
また、一連の解析はすべてJupyter-notebook形式で筆者のGitHubリポジトリで公開しています。
VtuberDataScraping - Youtube Data APIを用いたバーチャルYoutuberのデータ収集
PythonとJupyterのインストールは以下のサイトを参考にしてください。
また、必要となるパッケージと環境のバージョンは以下の通りです。
- Python >= 3.6.5
- numpy >= 1.14.5
- google-api-python-client >= 1.7.11
- tqdm >= 4.23.4
- ipywidgets >= 7.2.1
- widgetsnbextension >= 3.2.1
Jupyter上でtqdmを使うためには、コマンドプロンプト上で以下のように入力し、拡張機能を有効にしてください。
jupyter nbextension enable --py --sys-prefix widgetsnbextension
前準備-API KEYの取得
Youtube Data APIのAPI_KEYは以下の方法で参考に取得してください。
Google APIキー/OAuth2.0-IDの取得方法
【動画まとめサイト】2019版 youtube API 詳しい簡単な取得方法【実践】 #拡散RTお願いします
API_KEYの取得にはGoogleアカウントの作成とGCP(Google Cloud Platform)のプロジェクト作成が必要になります。
GCPプロジェクトの作成方法は以下を参照してください。
Google Cloud Platform(GCP)にプロジェクトを作成する
データ取得の流れ
本プログラムでは、以下の流れでYoutubeチャンネル内の全ての投稿動画のデータを取得します。
- YoutubeチャンネルIDから、チャンネル内の全ての動画を含むプレイリストのIDを取得(Channels: list)
- プレイリストIDから、動画タイトルと投稿時間、および動画IDを取得(PlaylistItems: list)
- 動画IDから、動画の再生回数及びその他の情報を取得(Videos: list)
YoutubeチャンネルIDは、チャンネルのURLから確認できます。
https://www.youtube.com/channel/[チャンネルID] ← これがID
プレイリストIDの取得
以下の関数を用います。
def YoutubeChannelDetails(id_, API_KEY):
API_SERVICE_NAME = "youtube"
API_VERSION = "v3"
youtube = build(API_SERVICE_NAME, API_VERSION, developerKey=API_KEY)
search_response = youtube.channels().list(
part= 'snippet,contentDetails',
id=id_,
).execute()
return search_response['items'][0]
引数のid_にはプレイリストIDを、API_KEYにはAPIキーを入力してください。
戻り値の例は以下のようになります。
{'kind': 'youtube#channel',
'etag': '"..."',
'id': 'チャンネルID',
'snippet': {'title': 'チャンネルタイトル',
'description': 'チャンネル概要文',
'publishedAt': '2018-04-27T05:01:07.000Z',
'thumbnails': {...},
'localized': {'title': 'チャンネルタイトル',
'description': 'チャンネル概要文'},
'country': '国名'},
'contentDetails': {'relatedPlaylists': {'uploads': 'プレイリストID',
'watchHistory': '...',
'watchLater': '...'}}}
この中のプレイリストIDが、チャンネル内の全ての動画が含まれるプレイリストのIDとなります。
これを以下のように取得します。
ChannelDetails = YoutubeChannelDetails(id_,API_KEY)
uploads = ChannelDetails['contentDetails']['relatedPlaylists']['uploads']
動画IDの取得
動画タイトル、投稿時間およびIDの取得は以下の関数で行います。
引数Id_にはプレイリストIDを入力します。
def YoutubePlaylistContents(id_, API_KEY):
responses = []
nextPageToken = 'start'
counts = 0
while(nextPageToken is not None):
API_SERVICE_NAME = "youtube"
API_VERSION = "v3"
youtube = build(API_SERVICE_NAME, API_VERSION, developerKey=API_KEY)
if(nextPageToken == 'start'):
search_response = youtube.playlistItems().list(
part= 'snippet',
playlistId=id_,
maxResults = 50,
).execute()
nextPageToken = search_response['nextPageToken']
else:
search_response = youtube.playlistItems().list(
part= 'snippet',
playlistId=id_,
maxResults = 50,
pageToken = nextPageToken
).execute()
try:
nextPageToken = search_response['nextPageToken']
except:
nextPageToken = None
responses.extend(search_response['items'])
counts += len(search_response['items'])
print('load '+str(counts)+' videos...')
return responses
APIへのリクエストでは一度に50件までしか取得できないので少し工夫をしています。
結果として、以下のような動画情報を含むリストが得られます。
例として、バーチャルYoutuber「神楽すず」さんの最新動画の情報は以下のようになります。
{'kind': 'youtube#playlistItem',
'etag': '"p4VTdlkQv3HQeTEaXgvLePAydmU/JmIHjWgl9faHA_LwBwfIkOOdRBQ"',
'id': 'VVVVWjVBbEMzclRsTS1yQTJjajVSUDZ3Lm9yQnp3eDdjRDhZ',
'snippet': {'publishedAt': '2019-10-06T12:39:50.000Z',
'channelId': 'UCUZ5AlC3rTlM-rA2cj5RP6w',
'title': '【雑談】サムネ作り忘れてました。',
'description': 'サムネ毎月変えるとか言ってたのに忘れてました。\n本日もお付き合いいただけると嬉しいです。よろしくお願いいたします。\n\n【チャンネル登録】\nhttp://www.youtube.com/channel/UCUZ5AlC3rTlM-rA2cj5RP6w?sub_confirmation=1\n\n【Twitter】\n神楽すず\u3000https://twitter.com/kagura_suzu\n.LIVE\u3000https://twitter.com/dotLIVEyoutuber\n\n【Twitter実況タグ】\n全体\u3000#アイドル部\n個人\u3000#神楽すず\n\n毎週(できる限り)水曜、金曜、日曜の夜と土曜の昼に配信しています。\n良かったらまた見に来てください。',
'thumbnails': { ... },
'channelTitle': '神楽すず',
'playlistId': 'UUUZ5AlC3rTlM-rA2cj5RP6w',
'position': 0,
'resourceId': {'kind': 'youtube#video', 'videoId': 'orBzwx7cD8Y'}}}
ここから、動画タイトル、投稿日時、動画IDを以下のように取得します。
投稿時間は、ここでstrからdatetime型に変換しておきます。
dic_total = []
for t in total_contents:
date_list = t['snippet']['publishedAt'].split('T')
year, month, date = date_list[0].split('-')
hour, minute, sec = date_list[1].split(':')
sec = sec[:2]
dic = {'title':t['snippet']['title'],
'date':datetime.datetime(int(year),int(month),int(date),int(hour),int(minute),int(sec)),
'Id':t['snippet']['resourceId']['videoId']}
dic_total.append(dic)
動画の詳細情報の取得
動画IDから、動画の詳細情報(再生数、評価数、コメント数、再生時間)を取得します。
引数id_には動画IDを与えます。
def YoutubeVideoDetails(id_, API_KEY):
API_SERVICE_NAME = "youtube"
API_VERSION = "v3"
youtube = build(API_SERVICE_NAME, API_VERSION, developerKey=API_KEY)
search_response = youtube.videos().list(
part= 'statistics,contentDetails',
id=id_,
).execute()
hoge = search_response['items'][0]
details = {'viewCount':int(hoge['statistics']['viewCount']),
'likeCount':int(hoge['statistics']['likeCount']),
'dislikeCount':int(hoge['statistics']['dislikeCount']),
'commentCount':int(hoge['statistics']['commentCount']),
'duration':ConvertDuration(str(hoge['contentDetails']['duration']))}
return details
def ConvertDuration(string):
string = string.replace('PT', '')
strings = re.split('\D',string)[:-1]
if(len(strings) == 3):
delta = datetime.timedelta(hours=int(strings[0]),
minutes=int(strings[1]),
seconds=int(strings[2]))
elif(len(strings) == 2):
delta = datetime.timedelta(minutes=int(strings[0]),
seconds=int(strings[1]))
elif(len(strings) == 1):
delta =datetime.timedelta(seconds=int(strings[0]))
else:
delta = datetime.timedelta(seconds=0)
return delta.seconds
二つ目のConvertDurationは、動画再生時間をdatetime.timedeltaで変換する関数です。
以下のように、すべての動画の情報をリストに辞書型で格納し、numpy形式に変換してから.npy形式で保存します。
for n,d in enumerate(tqdm(np.array([i['Id'] for i in dic_total]))):
details = YoutubeVideoDetails(d,API_KEY)
dic_total[n].update(details)
dic_total = np.array(dic_total)
np.save('ChannelTitle-data.npy',dic_total) #.npy形式で保存
最終的に、各動画のデータが以下のような形式で得られます。
サンプルは以下の通りになります(例. APE OUT やる 02 - 神楽すず)
{'title': 'APE OUT やる 02',
'date': datetime.datetime(2019, 3, 29, 12, 10, 6),
'Id': 'ijauZ-6ZdJ4',
'viewCount': 30327,
'likeCount': 2910,
'dislikeCount': 7,
'commentCount': 29,
'duration': 3550}
繰り返しになりますが、ここまでのすべての内容は以下でJupyter-notebook形式で公開されています。
VtuberDataScraping - Youtube Data APIを用いたバーチャルYoutuberのデータ収集
取得したデータの解析例
まとめたデータからは以下のように各情報を取り出します。
dates = np.array([i['date'] for i in dic_total]) # 投稿日時
viewCount = np.array([i['viewCount'] for i in dic_total]) # 再生回数
再生数推移
普通に再生数推移を表示するとめちゃくちゃになるので、移動平均も一緒にプロットすることをお勧めします。
下の図は、散布図が各動画の再生回数、実戦が7日単位での移動平均です。
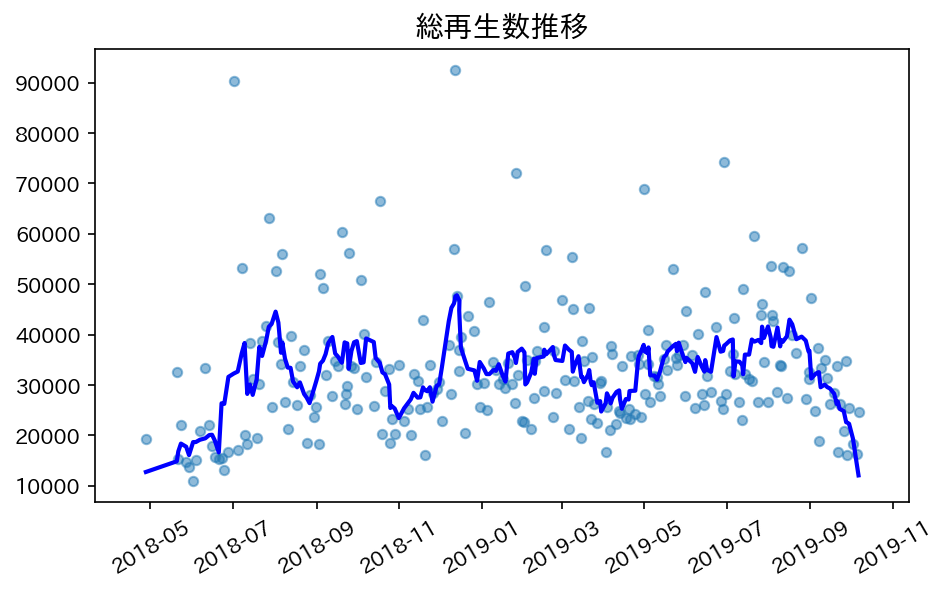
コードは以下の通り。
fig = plt.figure(figsize=(7,4),dpi=200)
# 散布図表示
plt.scatter(dates,viewCount,s=20,alpha=0.5)
# 移動平均をプロット
plt.plot(dates,np.convolve(viewCount,np.ones(7)/7.0,mode='same'),lw=2,c='b')
# 日時ラベルを30度傾斜
labels = plt.gca().get_xticklabels()
plt.setp(labels,rotation=30)
plt.title('総再生数推移',fontsize=14)
plt.show()
再生数ランキング
ranking = dic_total[np.argsort(viewCount)[::-1]]
print(ranking[:5]) # 上位5タイトルを表示
結果は以下のようになります。
これは、Youtubeチャンネル上で動画を人気順に並べ替えた結果と同じになります。
[{'title': '【2分半でわかる?】神楽すずです。よろしくお願いします【アイドル部】', 'date': datetime.datetime(2018, 12, 12, 12, 0, 6), 'Id': 'qRsB_miOR6I', 'viewCount': 92581, 'likeCount': 6263, 'dislikeCount': 18, 'commentCount': 659, 'duration': 141}
{'title': '【ETS2】運転知識皆無トラック運転シミュ【アイドル部】', 'date': datetime.datetime(2018, 7, 1, 14, 40, 46), 'Id': 'tAW-mEj6OAs', 'viewCount': 90219, 'likeCount': 2072, 'dislikeCount': 37, 'commentCount': 68, 'duration': 116}
{'title': '【ドリクラZERO】ギャンブルドリクラ #02', 'date': datetime.datetime(2019, 6, 29, 5, 37, 16), 'Id': 'g84VbU7Qduc', 'viewCount': 74223, 'likeCount': 3977, 'dislikeCount': 35, 'commentCount': 83, 'duration': 6515}
{'title': '全滅させたけど本気で全員生存を目指す2周目Detroit #01', 'date': datetime.datetime(2019, 1, 26, 5, 51, 2), 'Id': 'ehQY_XTbfIk', 'viewCount': 71986, 'likeCount': 3577, 'dislikeCount': 33, 'commentCount': 43, 'duration': 7681}
{'title': '【ETS2】無免許だけど令和までに無事故で荷物を届ける', 'date': datetime.datetime(2019, 4, 30, 16, 18, 15), 'Id': 'cazST-XDPrM', 'viewCount': 68862, 'likeCount': 4639, 'dislikeCount': 33, 'commentCount': 46, 'duration': 5925}]
まとめ
以上、PythonでYoutube Data APIを用いてデータを収集する方法を紹介しました。
Youtube Data APIには1日のデータ要求数に限りがあります。これはGoogle Cloud Platform => IAMと管理 => 割り当てで確認ができます。
リクエストを投げた時にquotaExceededエラーが出た場合は、この割り当て上限に達してしまったことを意味します。
動画数の多いYoutuberの動画収集を行うとあっという間に1日の上限に達してしまうので、お気を付けください。
最後となりますが、この手法で収集したデータを用いた簡単なデータ解析の結果を以下の記事で公開していますので、よろしければどうぞ。
データで見るバーチャルYoutuber-”四天王”の過去と現在
それでは!