はじめに
8/1より、ゆるキャラグランプリがはじまりました!
10/25までネット上で投票(1日1回投票可能)が行われ、ご当地および企業キャラクターがそれぞれ得票数を競います。
得票数は定期的にネット上で公開され、推しのゆるキャラがいま何位ぐらいかがわかるようになっているみたいです。
しかし、Webサイトの情報にアクセスしにくい(個人的な感想)うえ、票数や順位の時間的な推移を確認することができません。
そこで、今回はPythonを使ったWebスクレイピングで情報を引っ張ってくることにしました。
スクレイピングの前準備
プログラムを書く前に、以下のことを確認する必要があります。
- Webページのソースコード中のどの部分に欲しい情報が書かれているか
- ページのURLがどのような構造になっているか
今回は、この過程も簡単に解説していきます。
タグの確認
まず、スクレイピングをする前にどんな情報が欲しいかを確認します。
例えば、以下のゆるキャラグランプリ企業部門の検索画面
"https://www.yurugp.jp/jp/vote/result.php?enterprise=1"
では、ゆるキャラの順位、得票数、名前、地域、そして所属が確認できます。
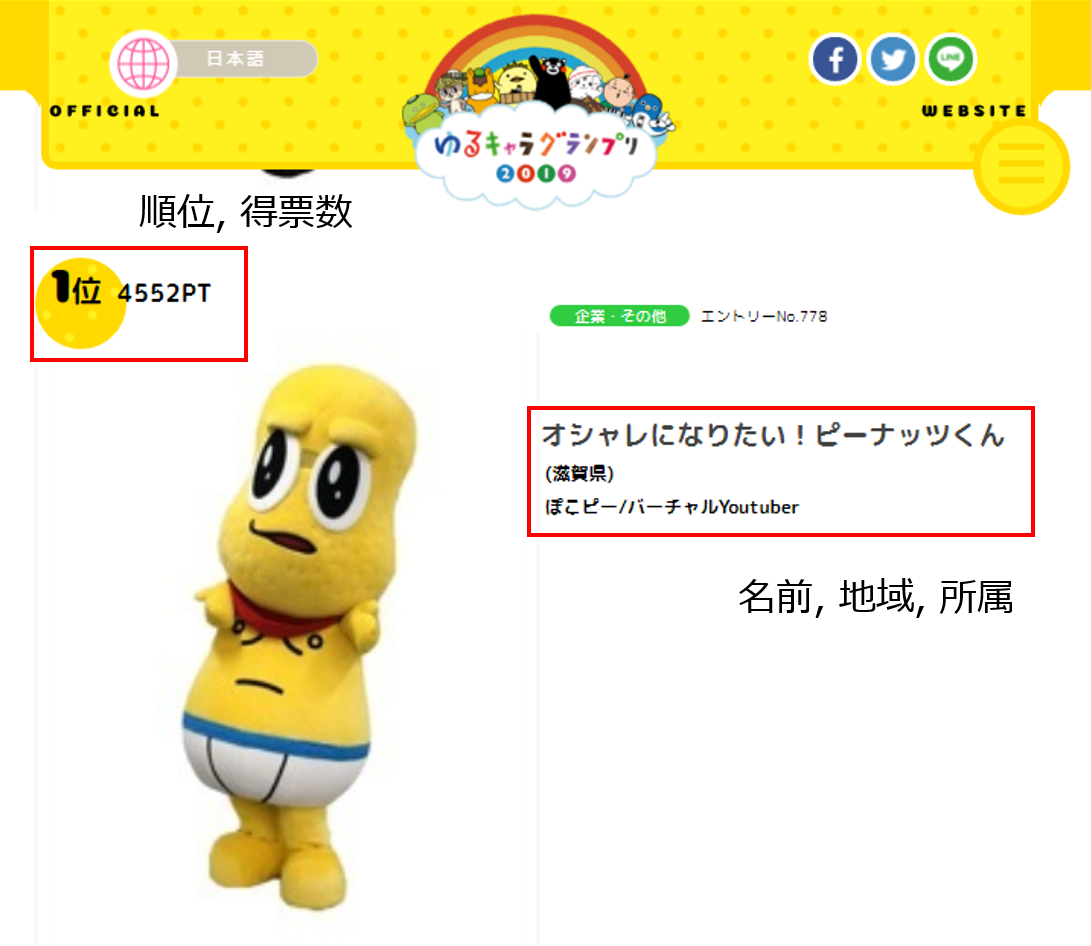
今回はこの情報だけで十分なので、個別ページに飛ぶ必要はなさそうです。
次に、この情報が表示されている部分のhtmlタグを確認します。
自分はChromeを使っているので、タグを見たい部分を右クリック→検証でソースが見えます。

このように、例えば順位、得票数はrankdetailクラスのdivタグで、名前、地域、所属はnameクラスのdivタグで囲まれていることが分かります。
ここまでがわかればスクレイピングには十分です。
次に、URLの確認をしていきます。
URLの確認
例えば、企業のゆるキャラの検索画面のURLは以下のようになっています。
page=nの部分がn = 2,3... となると次ページのURLとなります。
非常にわかりやすいURLなので、簡単にスクレイピングできそうです。
また、nの値が大きすぎた場合、例えば
のようなURLはどうなるのかというと、404エラーが返ってくるのではなく、空のページに飛ばされるようです。
今回はこの仕様を利用して、ぱぱっとプログラムを書いていきます。
HPの情報をスクレイピングするコード
以下は、企業ゆるキャラの情報をスクレイピングするコードです。
今回はPythonのurllibとBeautifulSoupを使いました。
import urllib.request
from bs4 import BeautifulSoup
import numpy as np
import time
dataset = []
n = 1
isContinue = True
while(isContinue):
url_pref = "https://www.yurugp.jp/jp/vote/result.php?page="+str(int(n))+"&enterprise=1"
# urllibで読み込み、BeautifulSoupでパースする
nem = urllib.request.urlopen(url_pref).read()
soup = BeautifulSoup(nem,"html.parser")
# rankdetail, nameクラスのdivタグの部分を抽出
rank = soup.find_all("div",class_="rankdetail")
name = soup.find_all("div",class_="name")
# 情報を抽出してリストに保存
ranks = [[j.text.split('位')[0],j.text.split('位')[1].replace("PT",""),
i.find_all("h4")[0].text.replace("(","").replace(")",""),
i.find_all("span",class_="country")[0].text.replace("(","").replace(")",""),
i.find_all("span",class_="biko")[0].text] for i,j in zip(name,rank)]
if(len(ranks) == 0):
# 空のページに行くとrankdetail, nameのdivタグの部分がないので
# ranksは空のリストとなる。ここで繰り返し処理を終了する。
isContinue = False
else:
# ranksの長さが0より多きければdatasetに追加してnに1を足す
dataset.extend(ranks)
n += 1
time.sleep(1)
dataset_ent = np.array(dataset)
たったこれだけです、簡単ですね!
ちなみにdataset_entの中身はこんな感じになっています。
array([['36', '142', 'よりぞう', '東京都', 'JAバンク(農林中央金庫)'],
['65', '75', 'でんのすけ', '香川県', '四電エナジーサービス株式会社'],
['25', '196', 'ミクちゃん', '兵庫県', '株式会社タツミコーポレーション'],
...,
['161', '16', 'えひめれっちゃくんすまいるえきちゃん', '愛媛県', 'JR四国'],
['133', '25', 'かがわれっちゃくんすまいるえきちゃん', '香川県', 'JR四国'],
['210', '8', 'こうちれっちゃくんすまいるえきちゃん', '高知県', 'JR四国']], dtype='<U35')
左から順に順位、得票数、名前、地域、所属です。
データを分析して遊ぶ
目的のデータが得られたので、さっそく解析してみます!
まずは基礎データですが、現在の企業ゆるキャラの総数は362名、総票数は29162票でした。
上位50名のゆるキャラとその得票数のプロットは以下になります。

ダントツの1位がバーチャルYoutuberのオシャレになりたい!ピーナッツくん、2位が株式会社宇佐美鉱油のうさっぴぃ、3位がNEXCO生日本のみちまるくん・・・と続いています。
上位の得票数が全体に占める割合が非常に多そうなので、得票率が1%以上の候補を円グラフで可視化してみましょう。

すると、上位陣が全体の票数のほとんどを独占していることがよくわかります。
中でも1位のオシャレになりたい!ピーナッツくんは一人で15%以上の得票率をたたき出しています。
Youtubeチャンネルの登録者数が8.4万人ぐらいなので、その5%程度が投票していると考えればおかしな数字ではありませんが、ゆるキャラ界(あるのか?)に大きな衝撃を与えていることでしょう。
おまけ
ご当地のゆるキャラをスクレイピングするプログラムはこんな感じです。
県ごとに検索ページが分かれているのが違いですが、数が増えることはない(48個)ので、対応はそんなに難しくないです。
dataset = []
search_list = np.linspace(1,48,48)
for i in search_list:
n = 1
isContinue = True
while(isContinue):
url_pref = "https://www.yurugp.jp/jp/vote/result.php?page="+str(int(n))+"&prefectures="+str(int(i))
nem = urllib.request.urlopen(url_pref).read()
soup = BeautifulSoup(nem,"html.parser")
rank = soup.find_all("div",class_="rankdetail")
name = soup.find_all("div",class_="name")
ranks = [[j.text.split('位')[0],j.text.split('位')[1].replace("PT",""),
i.find_all("h4")[0].text.replace("(","").replace(")",""),
i.find_all("span",class_="country")[0].text.replace("(","").replace(")",""),
i.find_all("span",class_="biko")[0].text] for i,j in zip(name,rank)]
if(len(ranks) == 0):
isContinue = False
else:
dataset.extend(ranks)
n += 1
time.sleep(1)
最後に
この記事を書いた目的の3/4ぐらいは、技術的な内容にかこつけてバーチャルYoutuberのオシャレになりたい!ピーナッツくんと、その相方のぽんぽこさんの応援です!
(ぽんぽこさんも着ぐるみ化してエントリーしたけど落選してしまった模様)
バーチャルYoutuberなのに身銭切って着ぐるみ化してゆるキャラグランプリに出るとか面白すぎでしょ。
10/25まで先は長いぞ!
一日一票! ピーナッツくんの応援よろしくね!
konkon