やりたいこと
今、はやりのDCGANの中身については、以前個人的に勉強してなんとなく中身は理解できているので、
ちょっと使ってみたいけど、実装を自前でするのはつらい...
とか思ってたら、chainerさんのgithubのexampleの中にあるではないか!?
これは使ってみるしかない!と思い使ってみたのと、少し自分なりに使いやすいように
改良(いや、改悪?)してみました。
DCGANについては、いろいろと解説しているページがあるのでそちらを見てください
DCGANの学習
chainerさんのインストールをして、学習
自前のデータセットはchainerのバージョンが1.2とかそんくらいに
「あ」「い」「う」「え」「お」の認識をしようと思って作ったものを利用
python -h train_dcgan.pyとすると、-iオプションでデータセットを指定できる!すばらしい
ということで、早速開始
python train_dcgan.py -g 0 -i ../mydataset/ --snapshot_interval 500 --display_interval 100
実行すると、なんと今、全体のうちどれくらい学習が終わっているかとか、
あとどのくらいで学習が終わりそうかなどが出力される
これまた感動...!
そして、学習が終わるとresult/previewフォルダに画像が

おおお!
上記、ちょっとソースをのぞいてみると、どうやら下記の部分で10×10のイメージ画像を、
一定のインターバルで出力している模様
101 trainer.extend(
102 out_generated_image(
103 gen, dis,
104 10, 10, args.seed, args.out),
105 trigger=snapshot_interval)
ということは、out_generated_imageを参考にすればできそう!
ということで、Let's try!
学習したGeneratorから任意の枚数の画像を個別に出力する
コードはgithubにコードおいてます。
https://github.com/komorin0521/chainer_myexample/tree/master/dcgan_generator
まず、generatorは、train_dcgan.pyの-rのコードを参考に、Generatorをロードするようにしてます。
出力はサンプルのvisualize.pyを参考にさせてもらいました。
そうすると、任意の枚数の画像が生成できた!
下記、サンプルです。
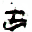
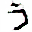
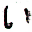
うおおお!すごい。と感動しっぱなしでした。笑