新型コロナウイルスの影響により、各スポーツ団体が選手選考大会の中止や無観客試合といった決断を強いられています。このような状況で東京オリンピックが開催できるのか否か、国民としては大変不安な思いです。ネットではこの状況ではオリンピックは延期にするべきといった意見や、経済的な理由もあるし開催するべきといった意見が挙げられており、各種メディアでもコメンテーターが様々な角度から意見を出しています。
今回はそういった状況も踏まえて、東京オリンピックに関するツイートは主にどのようなキーワードが含まれていて、どのような感情でツイートされているのかを Azure Cognitive Service で分析し、Power BI を用いて可視化してみたいと思います。
方法は以下です。
- Azure Cognitive Service のデプロイ
- Twitter の検索結果を CSV で出力
- Power BI で分析
- Power BI で可視化する
Azure Cognitive Service のデプロイ
今回使用する AI は Azure Cognitive Service の Text Analytics です。以下が Microsoft が公開している Docs に記載されている Text Analytics の説明です。
Text Analytics API は、未加工のテキストに対して高度な自然言語処理を実行できるクラウドベースのサービスであり、主要な機能として感情分析、キー フレーズ抽出、言語検出、名前付きエンティティの認識の 4 つを備えています。
この API は、機械学習と AI のアルゴリズムを開発プロジェクトで利用できるようクラウドに集めた Azure Cognitive Services に含まれます。
(参考) Text Analytics API とは
https://docs.microsoft.com/ja-jp/azure/cognitive-services/text-analytics/overview
今回実施するのは、ツイッターのテキストに含まれるキーフレーズの抽出と、テキストの感情分析なので、4つの機能のうち、「感情分析」、「キーフレーズ抽出」という機能を使用します。
まず、Azure Portal の 新しいリソースの作成から、「Text Analytics」を検索します。すぐに見つかると思いますので必要な項目を入力しで作成します。(今回試すことは無料の範囲で実施可能です)
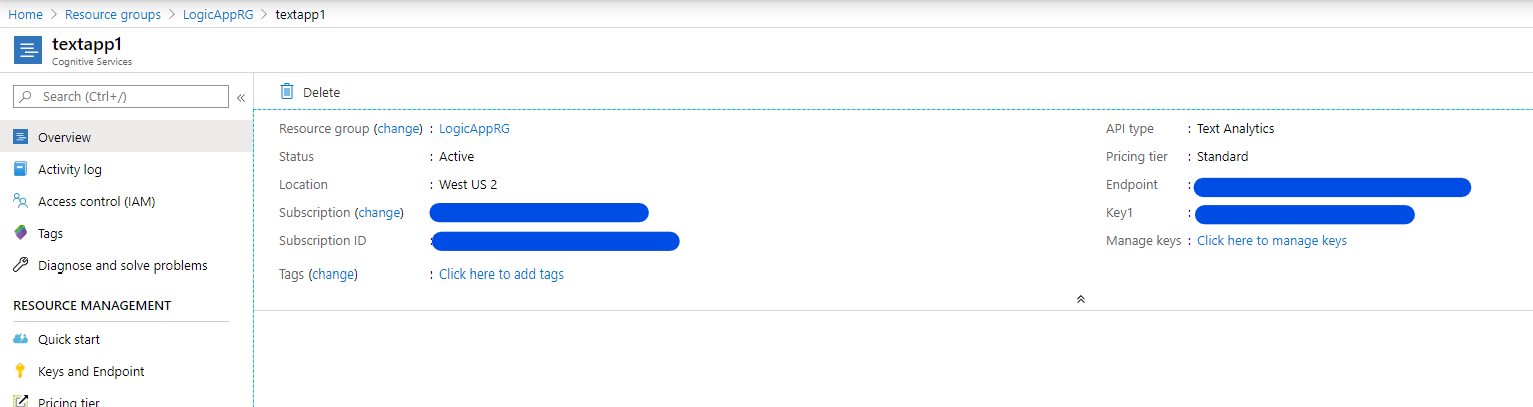
しばらくすると Text Analytics リソースが作成されるので、作成されたリソースのページで Endpoint と Access Key をコピペしておきます。この二つはあとで PowerBI でクエリを作成する際に使用します。問題なくリソースの作成とコピペが出来たら Cognitive Service 側の準備は完了です。
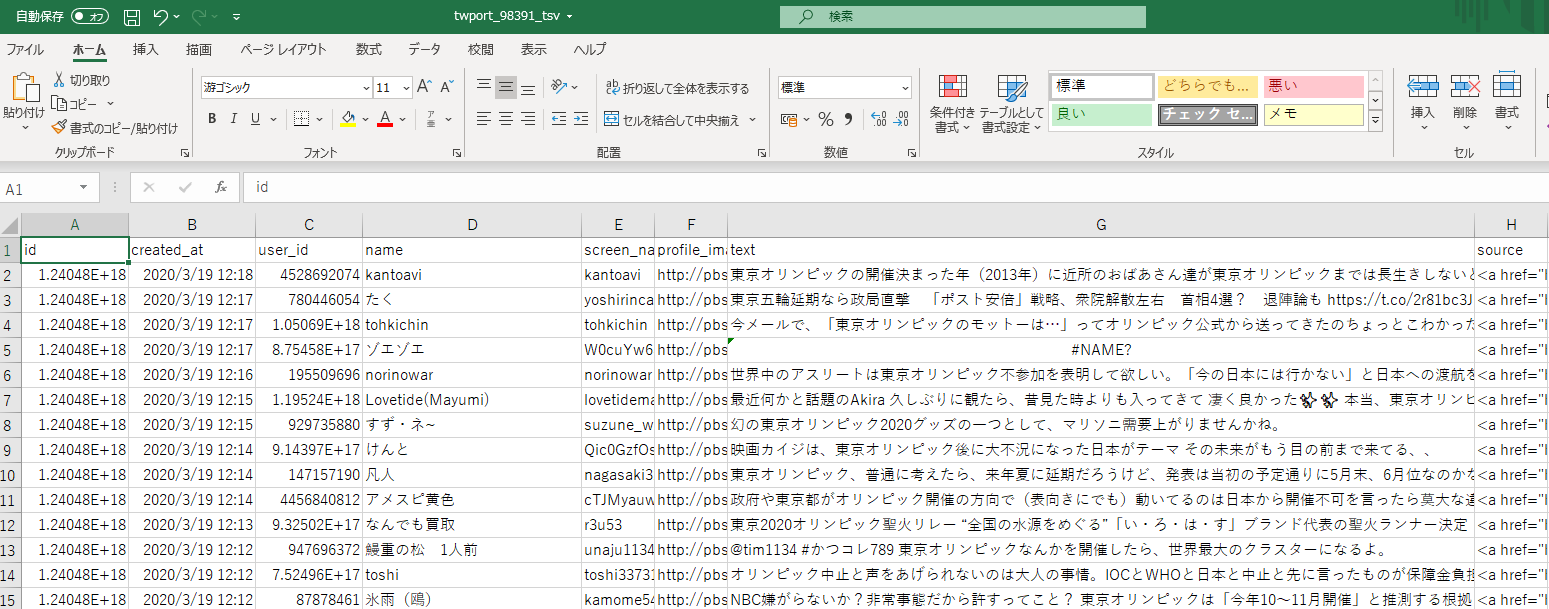
Twitter の検索結果を CSV で出力する
2年前に Twitter の API の大幅なアップデートがあってから、Twitter 独自の機能を用いて CSV に出力することができなくなりました。Python の API を用いて Twitter の検索結果を CSV に出力する方法もありますが、今回は UI 的に非常に分かりやすい以下のサイトを使用します。
ツイポーート/twport
https://twport.com/
こちらのサイトでご自身のツイッターのアカウントにてログインすることで、ツイッター検索した内容を保存し CSV 形式で出力してくれます。※ TLS の件で対応を狭まれた時に他の類似サイトは動かなくなってしまいましたが、このサイトは管理者がアップデートしたため生存しています。(管理者の努力に涙)
こちらのサイトで検索する際にたたく API は Twitter API そのままの仕様になっています。今回は東京オリンピックに関するツイートを検索するので、「東京オリンピック」と検索します。しかしこれではリツイートも含まれてしまうため、以下の様な検索文を入力します。
東京オリンピック exclude:retweets
その他にも Twitter API の仕様に従うことで様々な検索方式を試すことが可能です。
Search Tweets
https://developer.twitter.com/en/docs/tweets/search/api-reference/get-search-tweets
出力した結果を CSV にエクスポートし、ローカルの任意の場所に保存しておきます。これで Twitter の CSV を準備することができました。
尚、このサイトで検索できる上限が 100 件となっているため、それ以上の数のツイートを見てみたいという方はご自身で Python を使用して検索をかける必要があります。参考までに Python のサンプルスクリプトを以下に記載します。
import tweepy
import csv
from config import CONFIG
CONSUMER_KEY = CONFIG[""]
CONSUMER_SECRET = CONFIG[""]
ACCESS_TOKEN = CONFIG[""]
ACCESS_SECRET = CONFIG[""]
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)
auth.set_access_token(ACCESS_TOKEN, ACCESS_SECRET)
api = tweepy.API(auth)
tweet_data = []
for tweet in api.search(q="#東京オリンピック exclude:retweets",tweet_mode='extended',count=10):
try:
tweet_data.append([tweet.id, tweet.user.screen_name, tweet.created_at, tweet.full_text.replace('\n',''), tweet.favorite_count, tweet.retweet_count, tweet.user.followers_count, tweet.user.friends_count])
except Exception as e:
print(e)
with open('tweet_test.csv', 'w',newline='',encoding='utf-8') as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerow(["id","user","created_at","text","fav","RT","follower","follows"])
writer.writerows(tweet_data)
pass
Power BI でツイートのキーフレーズと感情を分析する
Power BI Desktop を開きます。もしインストールされていない環境の場合は以下から無料でダウンロードすることが可能です。
Download Power BI tools and apps
https://powerbi.microsoft.com/ja-jp/downloads/
まず初めに、ホームタブにある「データを取得」から「テキスト/CSV」を選び先ほどエクスポートし保存した CSV ファイルを開きます。
次にホームタブにある「データの変換」を選択しクエリエディアを立ち上げます。クエリエディタは別ウィンドウで立ち上がります。
ホームタブの「新しいソース」を選択し、空のクエリを作成します。空のクエリを作成すると、右側のメニューに新しいクエリが出現します。これを選択し、クエリに以下を入力します。endpoint と apikey は最初に Cognitive Service のポータルページからコピペした値を入力します。
(text) => let
apikey = "",
endpoint = "https://XXXXXX.cognitiveservices.azure.com/text/analytics" & "/v2.1/keyPhrases",
jsontext = Text.FromBinary(Json.FromValue(Text.Start(Text.Trim(text), 5000))),
jsonbody = "{ documents: [ { language: ""ja"", id: ""0"", text: " & jsontext & " } ] }",
bytesbody = Text.ToBinary(jsonbody),
headers = [#"Ocp-Apim-Subscription-Key" = apikey],
bytesresp = Web.Contents(endpoint, [Headers=headers, Content=bytesbody]),
jsonresp = Json.Document(bytesresp),
keyphrases = Text.Lower(Text.Combine(jsonresp[documents]{0}[keyPhrases], ", "))
in keyphrases
このクエリは選択されたテキストを Cognitive Service の Text Analytics API になげ、キーフレーズ分析を実施し、出力結果を入力するクエリとなっています。
同じ手順で新しいクエリをもう一つ作成します。同様に選択し、詳細エディターで以下のクエリを入力します。
(text) => let
apikey = "",
endpoint = "https://XXXXXX.cognitiveservices.azure.com/text/analytics" & "/v2.1/sentiment",
jsontext = Text.FromBinary(Json.FromValue(Text.Start(Text.Trim(text), 5000))),
jsonbody = "{ documents: [ { language: ""ja"", id: ""0"", text: " & jsontext & " } ] }",
bytesbody = Text.ToBinary(jsonbody),
headers = [#"Ocp-Apim-Subscription-Key" = apikey],
bytesresp = Web.Contents(endpoint, [Headers=headers, Content=bytesbody]),
jsonresp = Json.Document(bytesresp),
sentiment = jsonresp[documents]{0}[score]
in sentiment
このクエリは選択されたテキストを Cognitive Service の Text Analytics API になげ、感情分析を実施し、出力結果を入力するクエリとなっています。
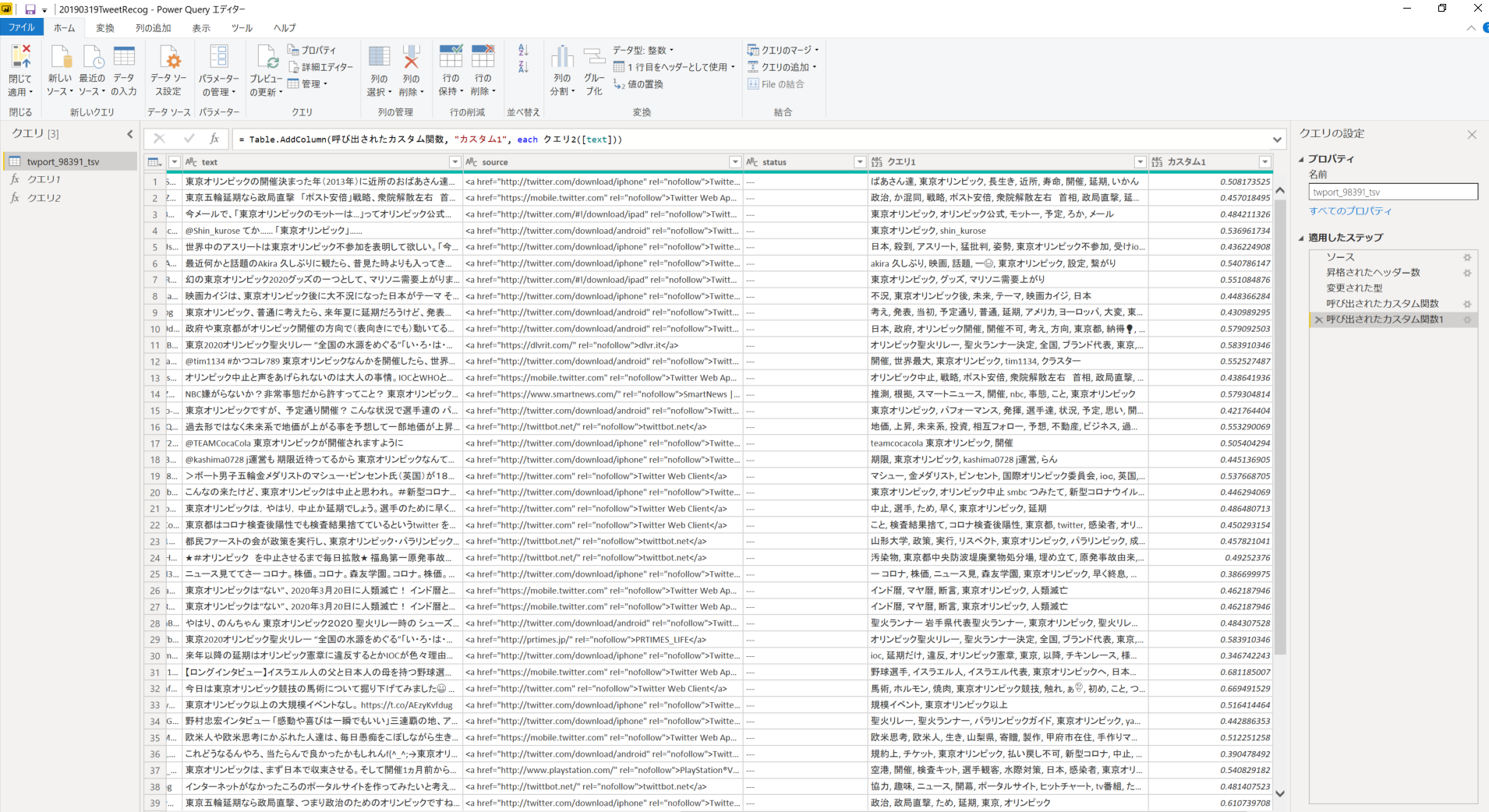
クエリが完成したら、「列の追加」タブの「カスタム関数の呼び出し」を選択します。このカスタム関数の呼び出しで先ほど作成したクエリを選択し、分析対象としては、ツイートのテキストが入力されている「text」を選びます。クエリ1 と クエリ 2 どちらも同様の手順で実行します。実行が成功すると、クエリエディタの一番右側に新しい二つの列が挿入されています。これが Cognitive Service により実行されたキーワード抽出と感情分析の結果です。
Power BI で可視化する
せっかく Power BI を使用したので、これを可視化させてみます。クエリエディターで編集が終了したので、「閉じて適用」を選択し元のページに戻ります。
右のメニューに「視覚化」という項目があります。そこに WordCloud があればそれを選択します。なければ「視覚化」の下のメニューを選択するとストアから WordCloud をインストールします。※ほんの数秒で終わります。
WordCloud にクエリ1で分析した結果を表示させてみます。表示する際には検索したワードである「東京オリンピック」を除外させます。(オプションで設定させることが出来ます。) 表示させた結果は以下のようになりました。

本来であればメダルの数や選手の名前といった前向きな話題が多くなると想定されますが、新型コロナウイルスの影響もあり、延期や中止、さらに安倍政権への批判といったキーフレーズが抽出されました。せっかくのオリンピックなのに悲しいばかりです、、。
次に感情スコアを散布図に表示させてみます。シンプルに、x軸に時間、y軸に Score というような形で設定します。以下のような出力結果になりました。
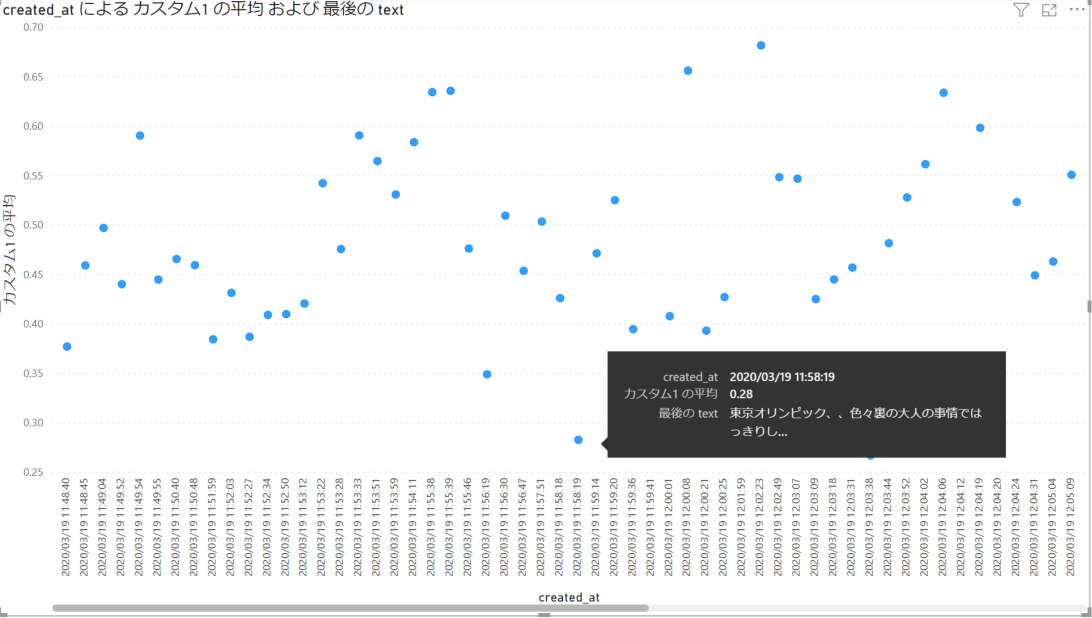
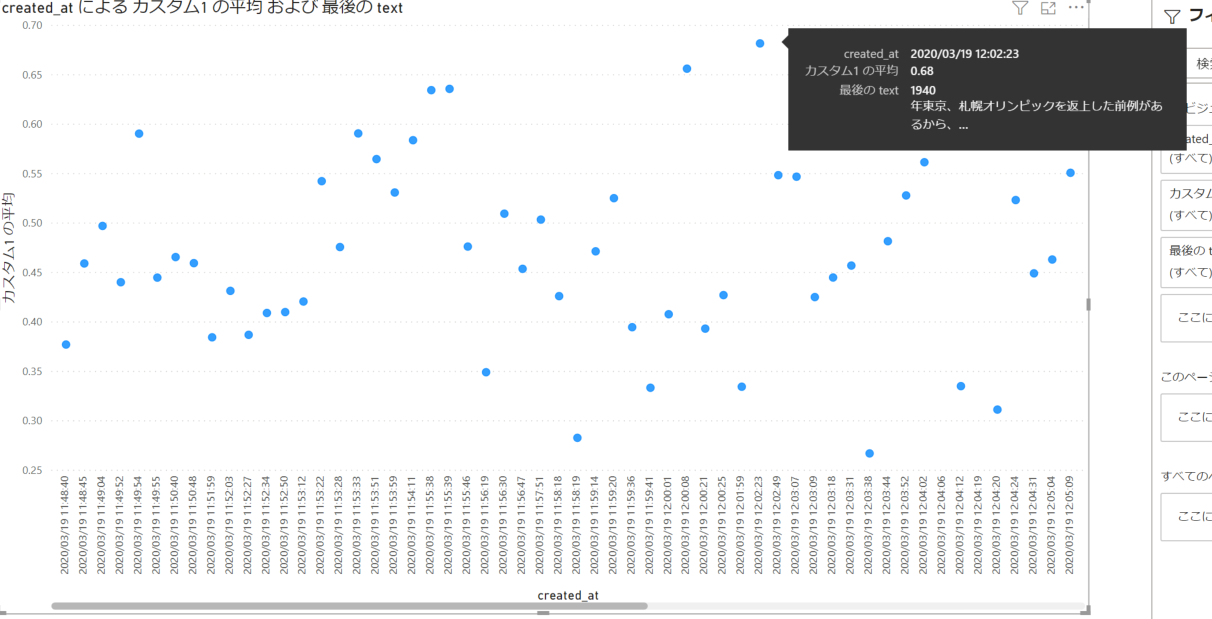
散布図で高い位置にあるのが Positive なツイート、下にあるのが Negative なツイートとなります。Power BI の場合、マウスを点に置くことでそのツイートの内容をみることができます。今回の例では、ネガティブなツイートではオリンピック開催が不可能だというもの、ポジティブなツイートでは場所を移したりしてオリンピックを実行させてほしい、といった内容が含まれていました。
まとめ
今回は Text Analytics の感情分析が日本語対応したことを受けて、このような形で感情分析試してみました。100件のツイートの分析でしたがキーフレーズ、感情を分析することで様々なことが視覚的に発見できました。簡単にデプロイできるサービスなので非常に便利ですね!
ただ、4年に一度の素晴らしいスポーツの祭典であるオリンピックがあと4か月に迫っているにも関わらず、新型コロナウイルスによってネガティブなツイートが多いのは残念です。予定通りの開催にせよ、延期した開催を調整するにせよ、万全の形でみんなが楽しめる様にベストな方法を考えてほしいです。