はじめに
「List や配列などに対する、いわゆる top-k selection を Java で効率的に実現する方法について、問題に年に 2〜3 回ぐらいの頻度で悩まされています。なにかいい top-k selection の実装はありませんか?」
(東京都 / 34歳 / 男性)
プログラムを書くお仕事をしていると、いろんな場面で top-k selection をしなきゃいけない状況にちょくちょく出くわすことがあるかと思います。もちろん RDBMS を使っていれば、ORDER BY sort_column LIMIT k とすることでさくっと top-k selection が実現できるわけですが、RDBMS の外で top-k selection をしなきゃいけない状況だって (年に 2〜3 回もあるかは個人差がありますが)、人生の中で 1〜2 回は遭遇するんじゃないかと思います。
ところで最近、Guava: Google Core Libraries for Java にこの top-k selection の実装 があることを知ったので、この実装が果たして使えるものなのか、そしてその性能がどれくらいのものなのかが気になってベンチマークをとってみました。さて、その性能はいかに。
Guava の top-k selection 実装
今回ベンチマーク対象とする Guava の top-k selection アルゴリズムは、次のような実装になっています。
- List の大きさと top-k の
kを比較し、kが List の半分の大きさ以上の場合にはArrays.sort()(つまりは TimSort) して top-k を求める -
kがInteger.MAX_VALUE / 2以上であれば、Collections.sort()(こちらも TimSort) して top-k を求める - 上記のどちらにも当てはまらない場合は、List から得られる
Iteratorに対して次のアルゴリズムで top-k を求める-
k * 2のサイズでバッファリングしながら、 - バッファが満杯になったら quickselect してバッファを減らし、
- 最後に
Arrays.sort()する
-
ベンチマーク条件
- jmh で測定します
-
Collections.sort()とOrdering#leastOf()のスループットを比較します-
Collections.sort()の実装は TimSort です - 比較条件がそこそこ等しくなるように、
Collections.sort()による top-k selection の実装では、ソート後に top-k 件だけを抽出して新たな ArrayList を生成するまでの処理を測定対象としています
-
- List のサイズは 20, 320, 5120 の 3 パターンを試してみます
- Top-k の
k(選出する個数) は、List サイズに対する割合から算出します- 割合は 0.05, 0.1, 0.2, 0.4, 0.8 の 5 パターンを試してみます
以下がベンチマークに使ったプログラムです
import com.google.common.collect.Ordering;
import org.openjdk.jmh.annotations.Benchmark;
import org.openjdk.jmh.annotations.Param;
import org.openjdk.jmh.annotations.Scope;
import org.openjdk.jmh.annotations.Setup;
import org.openjdk.jmh.annotations.State;
import org.openjdk.jmh.infra.Blackhole;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Random;
@State(Scope.Benchmark)
public class GuavaOrderingBenchmark {
@Param({"0.05", "0.1", "0.2", "0.4", "0.8"})
public double sortingRatio;
@Param({"20", "320", "5120"})
public int size;
private int k;
private List<Double> data;
@Setup
public void prepare() {
k = (int) (size * sortingRatio);
Random r = new Random(12345L);
data = new ArrayList<>(size);
for (int i = 0; i < size; i++) {
data.add(r.nextDouble());
}
}
@Benchmark
public void collectionsSort(Blackhole bh) {
bh.consume(leastK(data, k));
}
@Benchmark
public void guavaOrdering(Blackhole bh) {
bh.consume(Ordering.natural().leastOf(data, k));
}
private List<Double> leastK(List<Double> data, int k) {
Collections.sort(data);
return new ArrayList<>(data.subList(0, k));
}
}
ベンチマーク結果
ベンチマーク結果をグラフで見みましょう。いずれもスループットを表すので、バーが長ければ長いほどよい性能であることを示します。
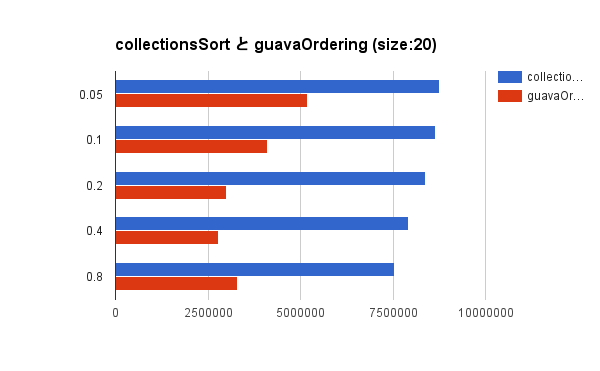
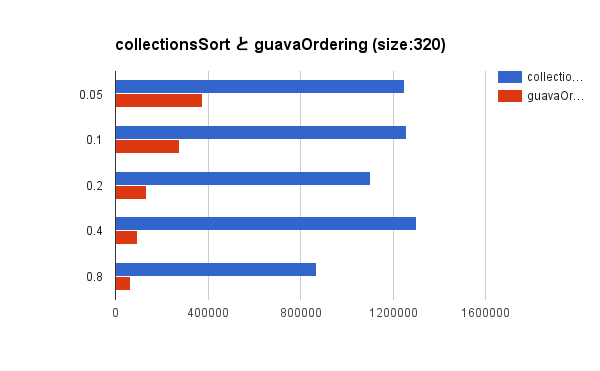
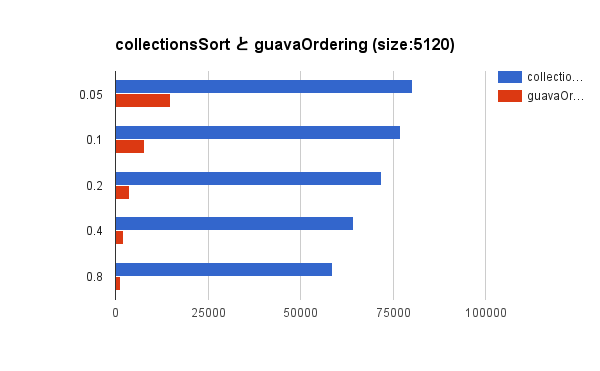
いずれの結果を見ても、単純に Collections.sort() でソートしてから top-k selection した方が良いことがわかりますね。あまりにも想定していない結果過ぎてショックでした。Guava とはなんだったのか。
まとめ
想定していたような結果 (Guava の方がよい) が得られず、あまりの Guava の惨敗っぷりに追加でベンチマークをとる気力を失ってしまいました。多分、超巨大な List に対してごくごく小さい k のもとで Guava の実装を使う分には性能がでるんじゃないかと思います。多分。