できたもの

なにやってるのか
- モデルを作成
- GCPにモデルをデプロイ
- GCP上で予測
※ タイタニックの「年齢」「性別」を学習データとしています。
※ XGBoostで生存できるかの2クラス分類モデルを作っています。
※ GCPのAI-Platformにモデルをデプロイし予測します。
GoogleColab
notebookにしましたので、もし
※ 2020/02/16 時点での情報及び動作確認となります。
手順
notebookとほぼ同じ内容を記載しています。
Colabを開くのがめんどくさい方はこちらを御覧頂ければと思います。
GCP アカウント登録
【画像で説明】Google Cloud Platform (GCP)の無料トライアルでアカウント登録
Google Cloud SDK のインストール
Google Cloud SDK のインストール ~ 初期化
SDK認証
gcloudコマンドをつかってGCPをいじるためGoogleアカウントで認証します。
$ gcloud auth login
プロジェクト作成
ID はカブり禁止です。
$ PROJECT_ID=anata-no-pj-id
$ PROJECT_NAME=anata-no-pj-name
$ gcloud projects create $PROJECT_ID \
--name $PROJECT_NAME
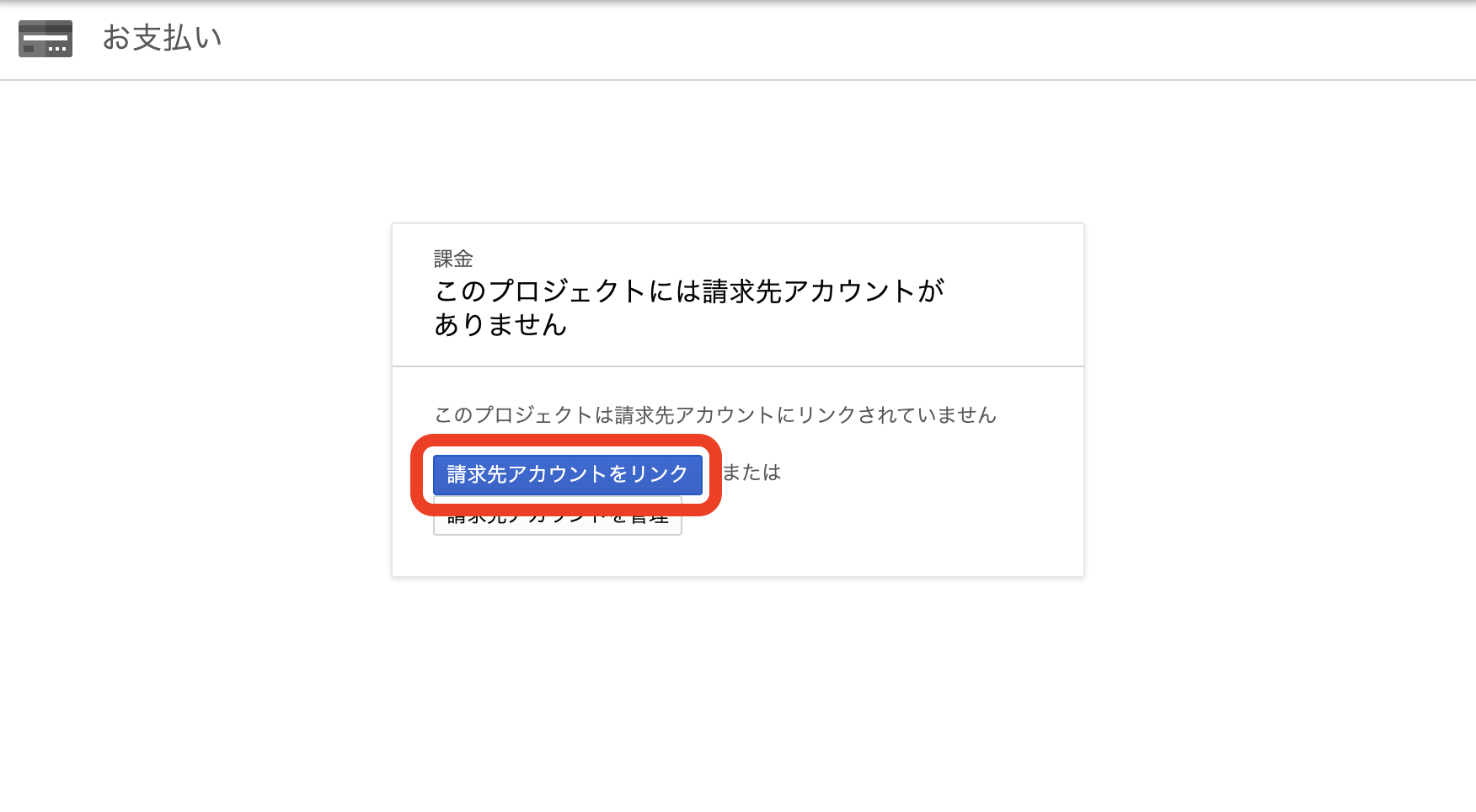
請求先アカウントの設定
設定しておかないとバケットにアクセスする際などで403エラーになります。
以下のポップアップが出なければ、請求先アカウント設定済みなのでスキップしてOKです。
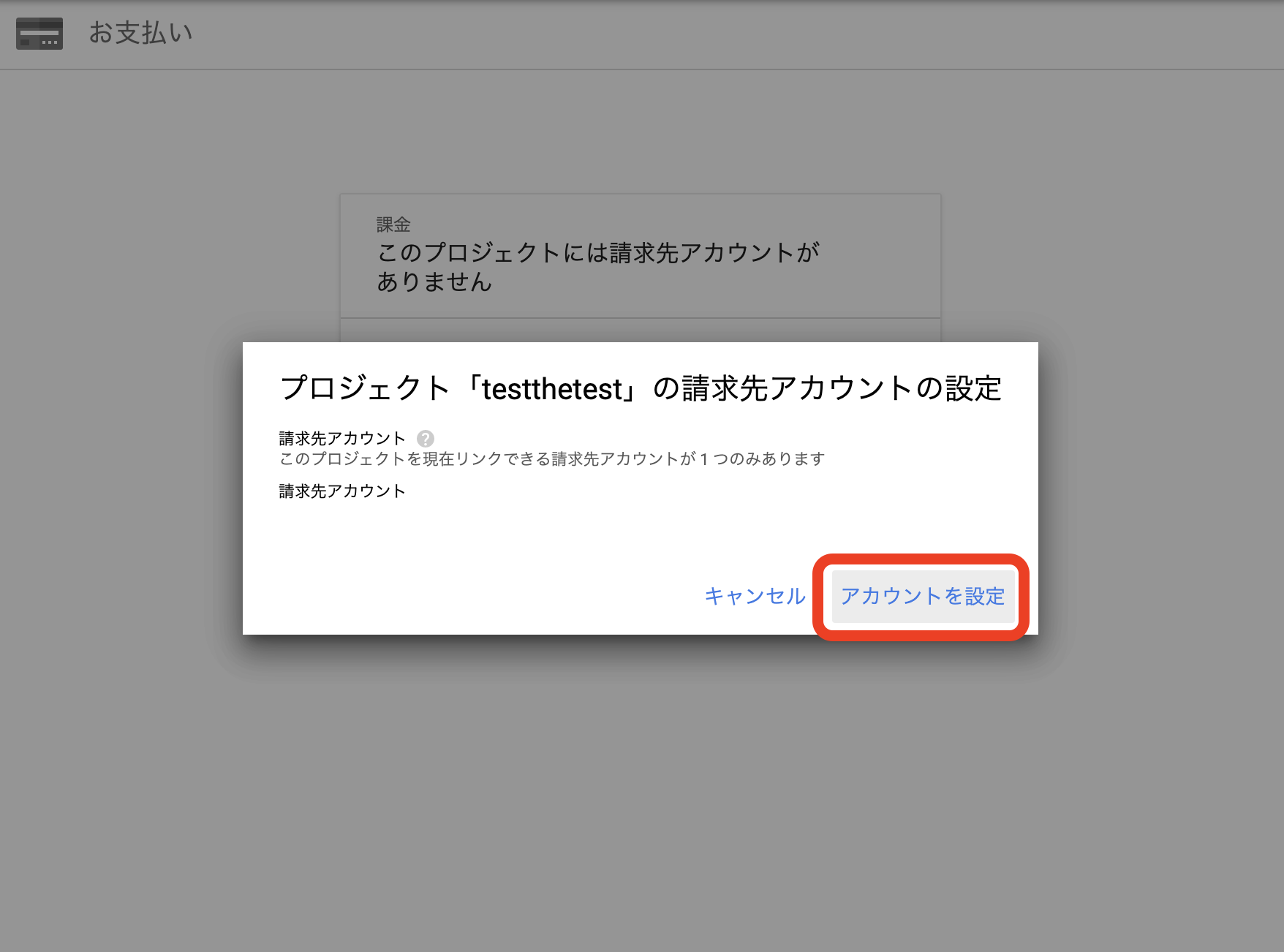
プロジェクトをアクティブに
コマンド操作の対象プロジェクトに設定する。
$ gcloud config set project $PROJECT_ID
確認
! gcloud config list
# [component_manager]
# disable_update_check = True
# [compute]
# gce_metadata_read_timeout_sec = 0
# [core]
# account = anata-no-address@gmail.com
# project = anata-no-pj-id
#
# Your active configuration is: [default]
- project = anata-no-project-id
となっていればOK
リージョン、ゾーン、インタープリタを設定
REGION=us-central1
ZONE=us-central1-a
$ gcloud config set compute/region $REGION
$ gcloud config set compute/zone $ZONE
$ gcloud config set ml_engine/local_python $(which python3)
AI Platform のオンライン予測が使えるリージョンは以下、、
- us-central1
- us-east1
- us-east4
- asia-northeast1
- europe-west1
インタープリタはローカルトレーニングの際にpython3系を使うように指定。
確認
$ gcloud config list
# [component_manager]
# disable_update_check = True
# [compute]
# gce_metadata_read_timeout_sec = 0
# region = us-central1
# zone = us-central1-a
# [core]
# account = anata-no-address@gmail.com
# project = anata-no-pj-id
# [ml_engine]
# local_python = /usr/bin/python3
#
# Your active configuration is: [default]
- region = us-central1
- zone = us-central1-a
- local_python = /usr/bin/python3
となっていればOK
トレーニング用のコード一式をクローン
$ git clone https://github.com/komiyakomiyakomiya/titanic_prediction_on_gcp.git
modelを保存するディレクトリを作成
import os
os.makedirs('./titanic_prediction_on_gcp/working/models/', exist_ok=True)
ローカルでトレーニング & モデルを保存
トレーニング済モデルが ./titanic_prediction_on_gcp/working/models/model.pkl として保存されます。
$ gcloud ai-platform local train \
--package-path titanic_prediction_on_gcp/working/ \
--module-name working.predict_xgb
バケットの作成
保存したモデルをアップロードするため、GCSにバケットを作ります。
※ 請求先アカウントを設定していないと403エラーになります。
BUCKET_NAME=anata-no-bkt-name
$ gsutil mb -l $REGION gs://$BUCKET_NAME
確認
$ gsutil ls -la
# gs://anata-no-bkt-name/
保存したモデルをGCSへアップロード
$ gsutil cp ./titanic_prediction_on_gcp/working/models/model.pkl gs://$BUCKET_NAME/models/model.pkl
確認
$ gsutil ls gs://$BUCKET_NAME/models/
# gs://anata-no-bkt-name/models/model.pkl
APIを有効化
AI-Platform APIを使うためには以下の2つを有効化。
- ml.googleapis.com
- compute.googleapis.com
$ gcloud services enable ml.googleapis.com
$ gcloud services enable compute.googleapis.com
確認
$ gcloud services list --enabled
# NAME TITLE
# bigquery.googleapis.com BigQuery API
# bigquerystorage.googleapis.com BigQuery Storage API
# cloudapis.googleapis.com Google Cloud APIs
# clouddebugger.googleapis.com Stackdriver Debugger API
# cloudtrace.googleapis.com Stackdriver Trace API
# compute.googleapis.com Compute Engine API
# datastore.googleapis.com Cloud Datastore API
# logging.googleapis.com Stackdriver Logging API
# ml.googleapis.com AI Platform Training & Prediction API
# monitoring.googleapis.com Stackdriver Monitoring API
# oslogin.googleapis.com Cloud OS Login API
# servicemanagement.googleapis.com Service Management API
# serviceusage.googleapis.com Service Usage API
# sql-component.googleapis.com Cloud SQL
# storage-api.googleapis.com Google Cloud Storage JSON API
# storage-component.googleapis.com Cloud Storage
- compute.googleapis.com Compute Engine API
- ml.googleapis.com AI Platform Training & Prediction API
があればOK
モデルリソース / バージョンリソースの作成
モデルリソースとバージョンリソースを作成し、アップロードしたmodel.pklと紐付けます。
モデルリソース
MODEL_NAME=model_xgb
MODEL_VERSION=v1
$ gcloud ai-platform models create $MODEL_NAME \
--regions $REGION
バージョンリソース
! gcloud ai-platform versions create $MODEL_VERSION \
--model $MODEL_NAME \
--origin gs://$BUCKET_NAME/models/ \
--runtime-version 1.14 \
--framework xgboost \
--python-version 3.5
インプットデータの確認
あらかじめ用意していたデータで予測をしてみます。
まずは中身を確認。
! cat titanic_prediction_on_gcp/input/titanic/predict.json
# [36.0, 0] <- 36歳, 男性
[年齢, 性別]という形式で、性別は男性:0, 女性:1とします。
AI-Platformで予測
! gcloud ai-platform predict \
--model model_xgb \
--version $MODEL_VERSION \
--json-instances titanic_prediction_on_gcp/input/titanic/predict.json
[0.44441232085227966] こんな予測値が返ってくればOK。
サービスアカウントの作成
次はpythonからAI-Platformにアクセスし、予測を取得します。
サービスアカウントキーが必要になるので、まずはサービスアカウントを作成。
SA_NAME=anata-no-sa-name
SA_DISPLAY_NAME=anata-no-sa-display-name
$ gcloud iam service-accounts create $SA_NAME \
--display-name $SA_DISPLAY_NAME \
サービスアカウントに権限を付与
$ gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:anata-no-sa-name@anata-no-pj-id.iam.gserviceaccount.com \
--role roles/iam.serviceAccountKeyAdmin
$ gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:anata-no-sa-name@anata-no-pj-id.iam.gserviceaccount.com \
--role roles/ml.admin
サービスアカウントキーの生成
$ gcloud iam service-accounts keys create titanic_prediction_on_gcp/service_account_keys/key.json \
--iam-account anata-no-sa-name@anata-no-pj-id.iam.gserviceaccount.com
key.jsonのパスを環境変数として読み込む
.envファイルを生成し環境変数とパスを記述
$ echo GOOGLE_APPLICATION_CREDENTIALS=/content/titanic_prediction_on_gcp/service_account_keys/key.json > /content/titanic_prediction_on_gcp/.env
確認
$ cat ./titanic_prediction_on_gcp/.env
# GOOGLE_APPLICATION_CREDENTIALS=/content/titanic_prediction_on_gcp/service_account_keys/key.json
## python-dotenvをインストール Colabに入っていないので
$ pip install python-dotenv
予測を取得するための関数を定義
import googleapiclient.discovery
from dotenv import load_dotenv
# 環境変数設定
load_dotenv('/content/titanic_prediction_on_gcp/.env')
def main(input_data):
input_data = [input_data]
PROJECT_ID = 'anata-no-pj-id'
VERSION_NAME = 'v1'
MODEL_NAME = 'model_xgb'
service = googleapiclient.discovery.build('ml', 'v1')
name = 'projects/{}/models/{}'.format(PROJECT_ID, MODEL_NAME)
name += '/versions/{}'.format(VERSION_NAME)
response = service.projects().predict(
name=name,
body={'instances': input_data}
).execute()
if 'error' in response:
print(response['error'])
else:
pred = response['predictions'][0]
return pred
年齢と性別のドロップダウンメニューを作成
import ipywidgets as widgets
from ipywidgets import HBox, VBox
age = [i for i in range(101)]
sex = ['男性', '女性']
dropdown_age = widgets.Dropdown(options=age, description='年齢: ')
dropdown_sex = widgets.Dropdown(options=sex, description='性別: ')
variables = VBox(children=[dropdown_age, dropdown_sex])
VBox(children=[variables])
予測
import numpy as np
from IPython.display import Image
from IPython.display import display_png
input_age = float(dropdown_age.value)
input_sex = 0 if dropdown_sex.value == '男性' else 1
test_input = [input_age, input_sex]
pred = main(test_input)
# print(pred)
pred_binary = np.where(pred > 0.5, 1, 0)
# print(pred_binary)
print('\nあなたがタイタニックに乗ると...')
if pred_binary == 1:
display_png(Image('/content/titanic_prediction_on_gcp/images/alive.png'))
else:
display_png(Image('/content/titanic_prediction_on_gcp/images/dead.png'))
公式リファレンス
まとめ
最後まで読んで頂きありがとうございました。
36歳のおじさんである私は死ぬようなので、タイタニックに乗る際には細心の注意をはらおうと思います。