やること
- csvファイルのデータセットをpickle化
- pickleファイルを別のnotebookで読み込む
pickleってなんなのよ?
pythonオブジェクトをバイナリデータで保存するやつ
https://docs.python.org/ja/3/library/pickle.html
なにがうれしくて?
読み込みが早い
バイナリデータなのでパーズ処理がいらんから早いんですって
学習済みモデルとかもpickle化してつかい回せる
こちらの検証記事がすばらしいです
Python: pandas の永続化フォーマットについて調べた
タイタニックのデータでやってみる
ひとまずtrain.csvをpickleにする
コードはこれだけ
# pickleは標準ライブラリなのでinstall不要
import pickle
import pandas as pd
train = pd.read_csv('../input/titanic/train.csv')
# 'wb'(write binary)を指定
with open('train.pickle', 'wb') as f:
pickle.dump(train, f)
Datasetとして保存
まずはcommit
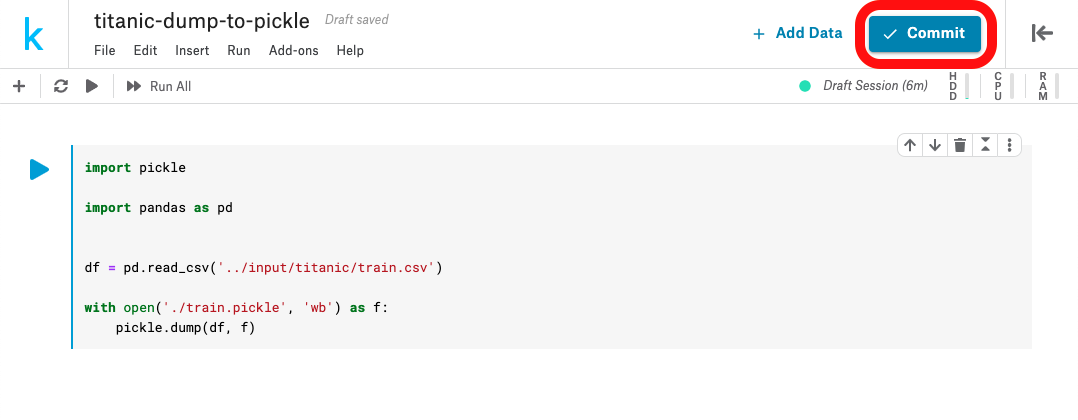
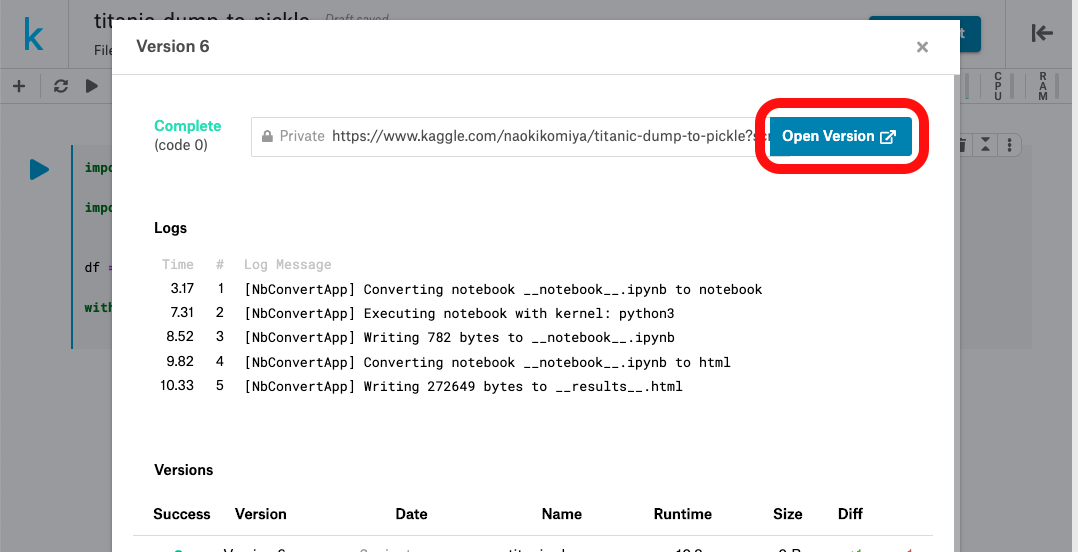
左上に緑のCompleteがでたらOpen Versionをポチ
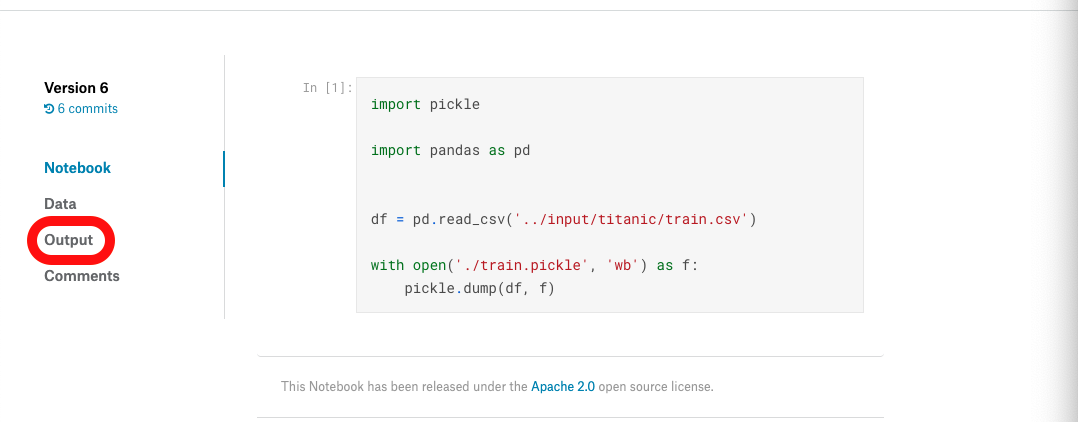
Outputの欄までスクロールして
train.pickleが確認できたらNew Dataset
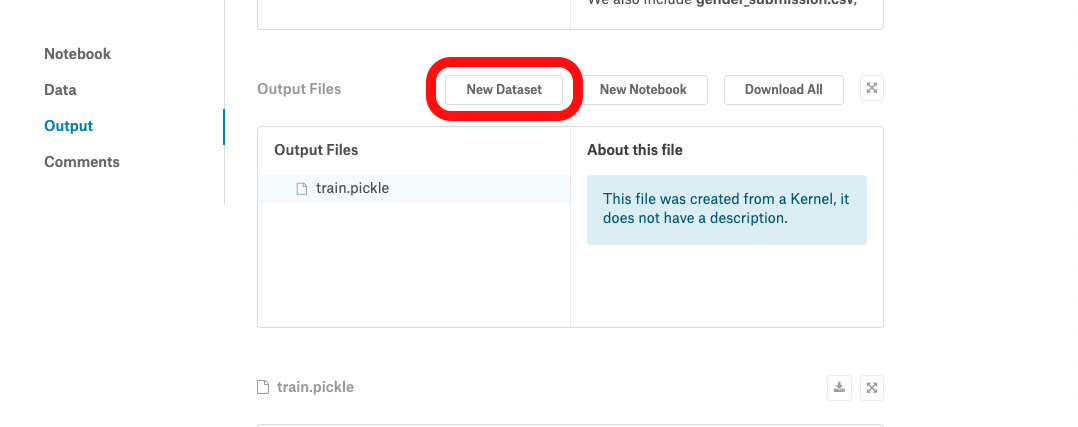
お好きなDatasetタイトルを入力してCreateすると
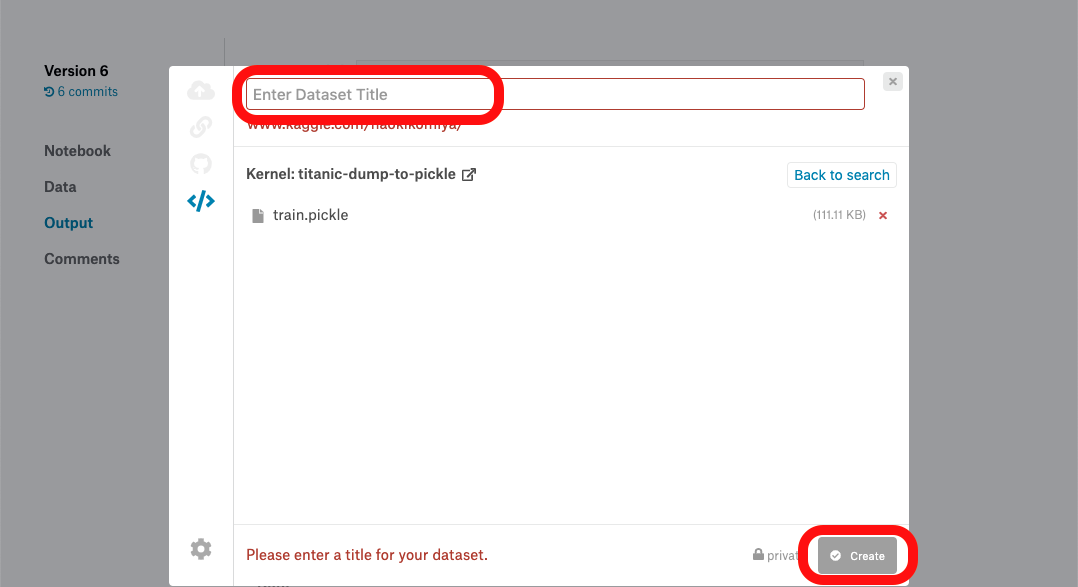
Datasetが完成
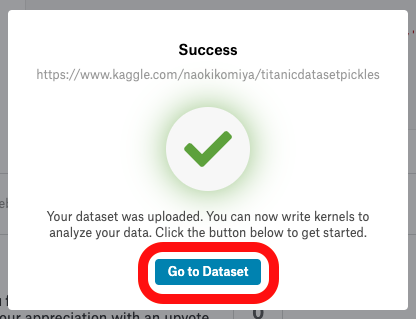
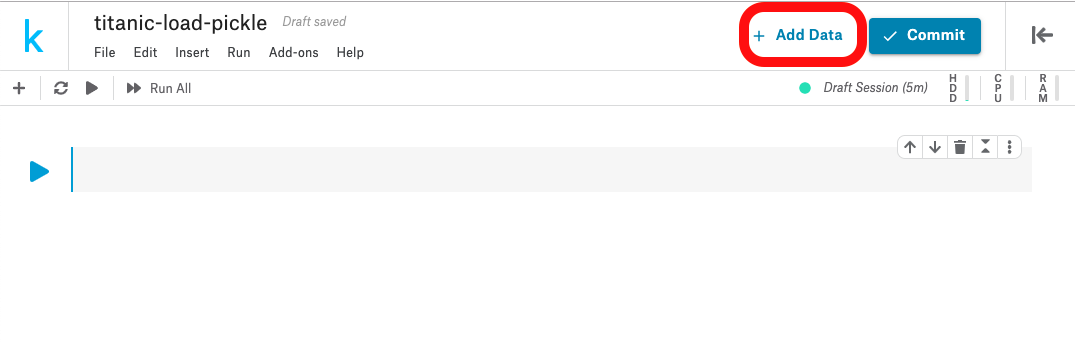
別のnotebookにもってくる
新しいnotebookをつくったら+ Add Data
Your Datasetsでフィルタリングして
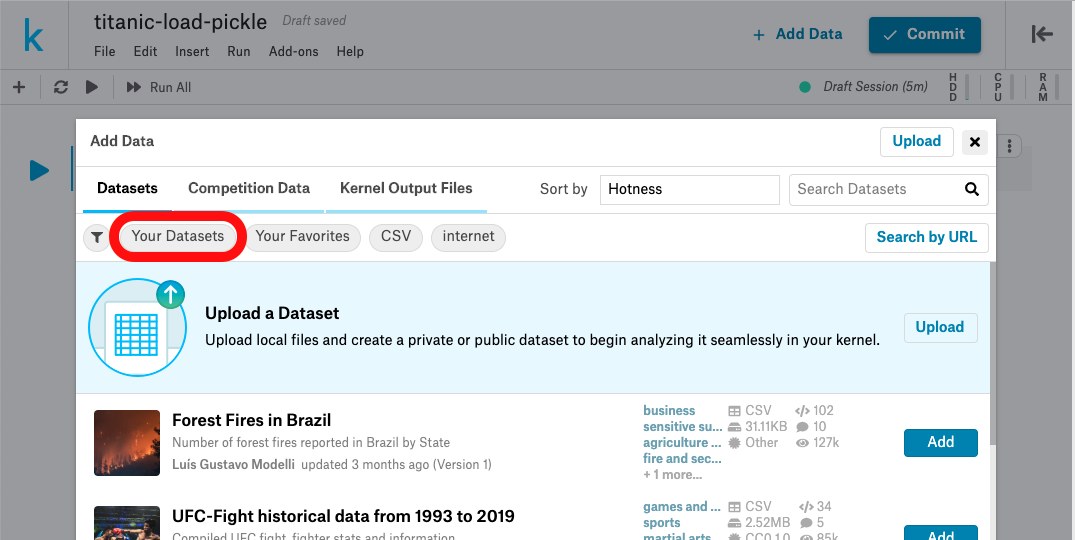
さっきつくったやつをAdd
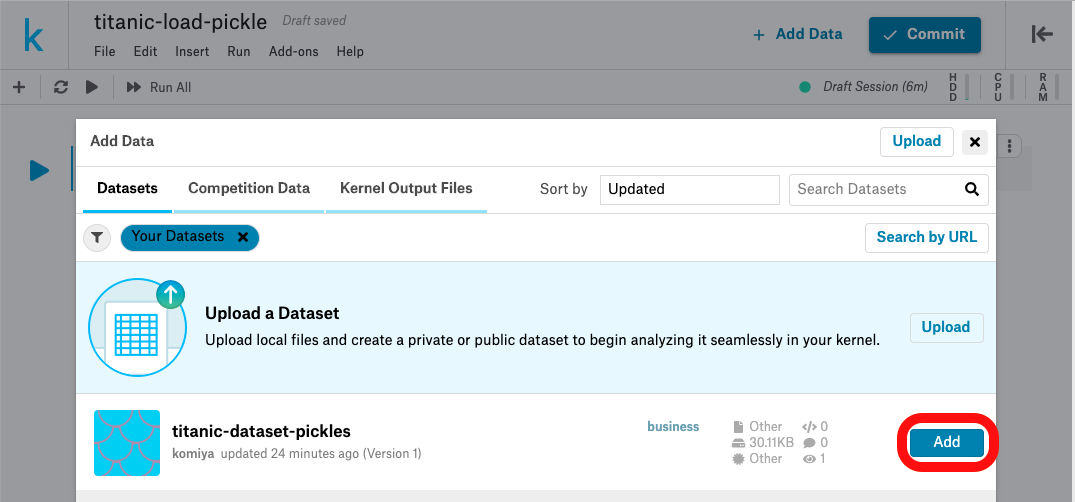
ここに表示されてれば優勝
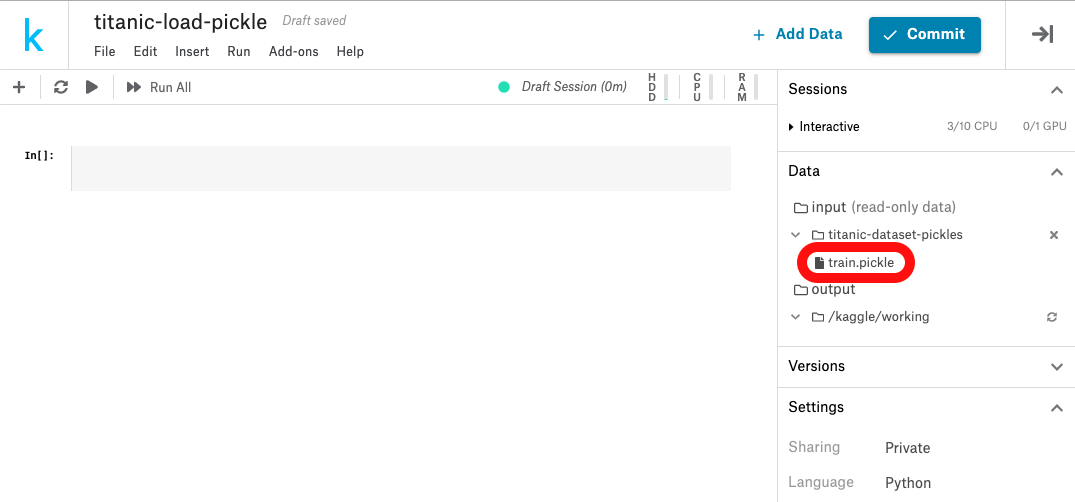
読み込んでみよう
コードはこれだけ
# 'rb'(read binary)を指定
with open('../input/titanicdatasetpickles/train.pickle', 'rb') as f:
train = pickle.load(f)
ちゃんとDataFrameとして読み込まれてますね
train.shape
# (891, 12)
ディレクトリ名は画面右に表示されてるものと違うことがあるのでお気をつけください `https://www.kaggle.com/anata-no-namae/data-set-no-namae` <- この表記がディレクトリ名になる `ls`コマンドで確認すると`-`ナシのディレクトリ名になっていることがわかります
!ls ../input
# titanicdatasetpickles
ファイル化してもよいかも
dumpの処理は使いまわせそう
import pickle
import pandas as pd
# Kaggle上と別環境でpathを切り替え
if '/kaggle/working' in _dh:
input_path = '../input'
else:
input_path = './input'
# コンペごとにココだけ書き換える
data_sets = {
'train': f'{input_path}/titanic/train.csv',
'test': f'{input_path}/titanic/test.csv',
'gender_submission': f'{input_path}/titanic/gender_submission.csv'
}
for name, path in data_sets.items():
df = pd.read_csv(path)
with open(f'{name}.pickle', 'wb') as f:
pickle.dump(df, f)
pandasでも同じことできる
# これは
with open('./train.pickle', 'wb') as f:
pickle.dump(train, f)
# こう
train.to_pickle('./train.pickle')
# これは
with open('../input/titanicdatasetpickles/train.pickle', 'rb') as f:
df_ss = pickle.load(f)
# こう
train = pd.read_pickle('../input/titanicdatasetpickles/train.pickle')
こんなエラーでる時ある
ModuleNotFoundError: No module named 'pandas.core.internals.managers'; 'pandas.core.internals' is not a package
とか言われたらpandasのバージョンの問題らしい
pip install -U pandas
で解決
※ Kaggleの公式dockerイメージ(kaggle/python)はpandas==0.23.4でエラーが出たので注意(2019/12/09現在)
こちらの記事に救っていただきました
pickleとpandasの不整合
おしまい
最後まで読んでいただいてありがとうございました