はじめに
実際に使ったコマンドのメモです。
随時更新していきます。
詳細は公式リファレンスをご参照下さい。
INDEX
gcloudコマンド
$ gcloud init
現在のconfigurationを初期化 or 新たなconfigurationを作成
対話形式で以下を指定する
- 現在のconfigurationを初期化 or 別のconfigurationを初期化 or 新規作成
- configuration名を設定
- gcpアカウントを選択
- プロジェクトを選択
- ゾーンを選択
$ gcloud init
## $ gcloud auth ~ ### ログイン gcloudコマンドをつかってGCPへアクセスするための認証
$ gcloud auth login
ログアウト
$ gcloud auth revoke
## $ gcloud projects ~ ### プロジェクトの一覧 ```sh $ gcloud projects list ```
プロジェクト作成
$ gcloud projects create プロジェクトID --name プロジェクト名
プロジェクト削除
$ gcloud projects delete プロジェクトID
サービスアカウントへ権限付与 / 削除
$ gcloud projects add-iam-policy-binding プロジェクトID \
--member serviceAccount:サービスアカウントネーム@プロジェクトID.iam.gserviceaccount.com \
--role roles/storage.admin # <- 例えばストレージ管理者
$ gcloud projects remove-iam-policy-binding プロジェクトID \
--member serviceAccount:サービスアカウントネーム@プロジェクトID.iam.gserviceaccount.com \
--role roles/storage.admin # <- 例えばストレージ管理者

roleリスト
### プロジェクトに紐付いている権限を一覧表示
$ gcloud projects get-iam-policy プロジェクトID
## $ gcloud compute ~ ### GCEインスタンスの一覧 ```sh $ gcloud compute instances list ```
--filterオプションで絞り込み
$ gcloud compute instances list --filter="zone:(us-central1-a asia-northeast1-a)"
使用可能な公開OSイメージの一覧
$ gcloud compute images list
NAME PROJECT FAMILY DEPRECATED STATUS
centos-6-v20200714 centos-cloud centos-6 READY
centos-7-v20200714 centos-cloud centos-7 READY
...
OSイメージの詳細表示
Shielded VM(セキュリティ制御により強化されたGoogleCloud上の仮想マシン)に対応しているかなど確認可能。
# ここでは以下を指定
# イメージ名: debian-9-stretch-v20200805
# イメージプロジェクト: debian-cloud
$ gcloud compute images describe debian-9-stretch-v20200805 --project debian-cloud
archiveSizeBytes: '16262238720'
creationTimestamp: '2020-08-05T10:54:28.717-07:00'
description: Debian, Debian GNU/Linux, 9 (stretch), amd64 built on 20200805
diskSizeGb: '10'
family: debian-9
guestOsFeatures:
- type: VIRTIO_SCSI_MULTIQUEUE
id: '6709658075886210235'
kind: compute#image
labelFingerprint: 42WmSpB8rSM=
licenseCodes:
- '1000205'
licenses:
- https://www.googleapis.com/compute/v1/projects/debian-cloud/global/licenses/debian-9-stretch
name: debian-9-stretch-v20200805
rawDisk:
containerType: TAR
source: ''
selfLink: https://www.googleapis.com/compute/v1/projects/debian-cloud/global/images/debian-9-stretch-v20200805
sourceType: RAW
status: READY
storageLocations:
- eu
- eu
- us
- eu
- asia
- asia
- eu
- asia
- us
- asia
- us
- eu
- us
- us
- asia
- us
- asia
- asia
- us
- eu
- us
- us
- asia
- asia
GCEインスタンスの作成
$ gcloud compute instances create webserver(任意のインスタンス名) \
--image-family ubuntu-1804-lts \
--image-project ubuntu-os-cloud \
--zone asia-northeast1-b \
--machine-type n1-standard-4 \
--create-disk size=375GB,type=pd-ssd \
--metadata-from-file startup-script=./script.sh
[INSTANCE_NAME] は、新しいインスタンスの名前です。
[IMAGE_FAMILY] は、使用可能なイメージ ファミリーのいずれかです。
[IMAGE_PROJECT] は、イメージが属するイメージ プロジェクトです。
[DISK_IMAGE] は、セカンダリ ディスクのソースイメージです。使用可能なイメージのリストを表示するには、gcloud compute images list を実行します。空のディスクを作成する場合は、ディスク イメージやイメージ プロジェクトを指定しないでください。
[DISK_IMAGE_PROJECT] は、ディスク イメージが属するイメージ プロジェクトです。空のディスクを作成する場合は、ディスク イメージやイメージ プロジェクトを指定しないでください。
[SIZE_GB] は、セカンダリ ディスクのサイズです。
[DISK_TYPE] は、永続ディスクの種類(pd-standard または pd-ssd のいずれか)です。
ディスクを使用する前に、ディスクをフォーマットしてマウントします。
https://cloud.google.com/compute/docs/disks/add-persistent-disk?hl=ja#formatting
--metadata-from-file startup-script=./script.shを指定するとインスタンス起動時にスクリプト任意のスクリプトがはしる。
GCEインスタンスの削除
$ gcloud compute instances delete インスタンス名
GCEインスタンスの停止
複数指定可能
$ gcloud compute instances stop インスタンス名1 インスタンス名2
GCEインスタンスの起動
$ gcloud compute instances start インスタンス名
GCEインスタンスの詳細表示
$ gcloud compute instances describe インスタンス名
canIpForward: false
cpuPlatform: Intel Haswell
creationTimestamp: '2020-08-05T23:51:06.025-07:00'
deletionProtection: false
disks:
- autoDelete: true
...
GCEインスタンスのマシンタイプ変更
インスタンスが停止している必要があります。
$ gcloud compute instances set-machine-type インスタンス名 --machine-type マシンタイプ(e2-smallなど)
GCEインスタンスにネットワークタグを追加
$ gcloud compute instances add-tags db(インスタンス名) --tags mysqlserver(タグ名) --zone asia-northeast1-b
プロジェクトの詳細表示
$ gcloud compute project-info describe --project プロジェクト名
ファイル転送(ローカル -> インスタンス)
$ gcloud compute scp ローカルファイルパス インスタンス名:転送先ディレクトリパス (--zone ゾーン名)
scpコマンドでも可能 (転送先ディレクトリがない場合はエラー)
$ gcloud compute scp インスタンス名:ファイルパス ローカルパス (--zone ゾーン名)
ディレクトリ転送(ローカル -> インスタンス)
$ gcloud compute scp --recurse インスタンス名:転送先ディレクトリパス ローカルディレクトリパス
scpコマンドでも可能 (転送先ディレクトリがない場合は自動で作成される)
$ scp -r -i ~/.ssh/path/to/id_rsa ローカルディレクトリパス GCPログインユーザ名@インスタンス外部IP:転送先ディレクトリパス(配下にディレクトリごと格納)
GCEインスタンスにSSH接続
初回は自動でキーペアを生成してくれる。
パスフレーズの入力が必要(省略可)
$ gcloud compute ssh webserver(インスタンス名)
WARNING: The public SSH key file for gcloud does not exist.
WARNING: The private SSH key file for gcloud does not exist.
WARNING: You do not have an SSH key for gcloud.
WARNING: SSH keygen will be executed to generate a key.
Generating public/private rsa key pair.
Enter passphrase (empty for no passphrase): <- 任意のパスフレーズを登録
Enter same passphrase again: <- 確認のため再入力
...
Enter passphrase for key '/Users/ホームディレクトリ名/.ssh/google_compute_engine': <- さっき登録したパスフレーズを入力(秘密鍵にアクセス)
...
GCEのファイアウォールルールを作成
$ gcloud compute firewall-rules create mysql-remote-access(ファイアウォールルール名) \
--allow tcp:3306 \
--source-ranges 150.164.20.10 \ # 接続許可するIPを指定できる(指定しない場合0.0.0.0/0となる)
--source-tags mysqlclient(接続元インスタンスに付与したネットワークタグ名) \ # ローカルマシンなど外部から接続する場合は指定不要
--target-tags mysqlserver(接続先インスタンスに付与したネットワークタグ名)
GCEイのファイアウォールルールを変更
$ gcloud compute firewall-rules update default-allow-ssh(ファイアウォールルール名) \
--allow tcp:80
静的IPアドレス一覧を表示
$ gcloud compute addresses list
NAME ADDRESS/RANGE TYPE PURPOSE NETWORK REGION SUBNET STATUS
hoge 32.72.200.100 EXTERNAL asia-northeast1 IN_USE
fuga 32.72.106.216 EXTERNAL asia-northeast1 IN_USE
## $ gcloud app ~ ### GAEインスタンスの一覧 ```sh $ gcloud app instances list ```
## $ gcloud sql ~ ### Cloud SQLインスタンスの一覧 ```sh $ gcloud sql instances list ```
## $ gcloud config ~
アカウントの切り替え
$ gcloud config set account アカウントID(Googleアカウント)
プロジェクトの切り替え
$ gcloud config set project プロジェクトID
リージョン設定
$ gcloud config set compute/region us-central1
ゾーン設定
$ gcloud config set compute/zone us-central1-a
configuration一覧を表示
$ gcloud config configurations list
NAME IS_ACTIVE ACCOUNT PROJECT COMPUTE_DEFAULT_ZONE COMPUTE_DEFAULT_REGION
default True example@gmail.com pj-name asia-northeast1-b asia-northeast1
configurationをアクティベート
$ gcloud config configurations あcちゔぁて コンフィグレーション名
configurationを削除
$ gcloud config configurations delete コンフィグレーション名
$ gcloud config configurations activate nkomiya-pj-komiya
Cloud ML Engineの設定
ローカルで予測/トレーニングジョブに使用するPythonインタープリタ
$ gcloud config set ml_engine/local_python $(which python3)
設定解除
$ gcloud config unset ml_engine/local_python
プロジェクトのプロパティを表示
$ gcloud config list
# [compute]
# region = us-central1
# zone = us-central1-a
# [core]
# account = anata_no_address@gmail.com
# disable_usage_reporting = True
# project = anata_no_project_id
#
# Your active configuration is: [default]
$ gcloud config list project
# [core]
# project = anata_no_project_id
#
# Your active configuration is: [default]
$ gcloud config list project
# [core]
# project = anata_no_project_id
#
# Your active configuration is: [default]
ログイン中のアカウントリスト
$ gcloud config list account
# [core]
# account = anata_no_address@gmail.com
#
# Your active configuration is: [default]
$ gcloud alpha ~
プロジェクト名の変更
$ gcloud alpha projects update anatano_pj_id --name=atarashii_pj_name
$ gcloud iam ~
サービスアカウント作成
※ サービスアカウントネームとサービスアカウントディスプレイネームに注意
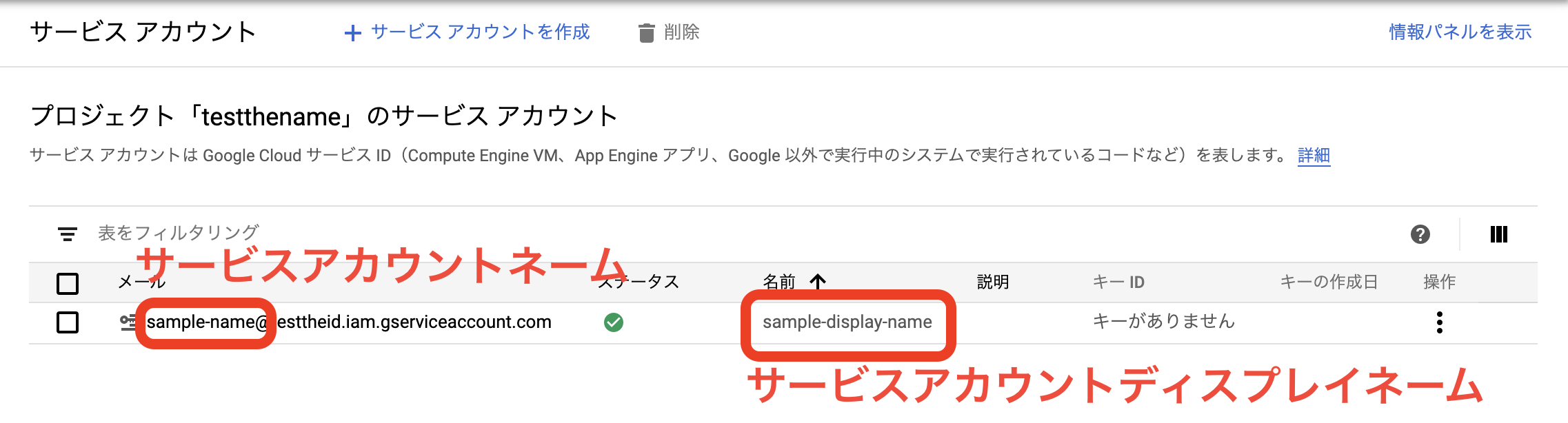
$ gcloud iam service-accounts create サービスアカウントネーム \
--display-name サービスアカウントディスプレイネーム \
--description 説明文
サービスアカウント削除
$ gcloud iam service-accounts delete サービスアカウントネーム@プロジェクトID.iam.gserviceaccount.com
サービスアカウントキー作成
$ gcloud iam service-accounts keys create path/to/キー名.json \
--iam-account サービスアカウントネーム@プロジェクトID.iam.gserviceaccount.com
$ gcloud services ~
API(サービス)のリストを表示
プロジェクトで利用可能なAPIのリスト
$ gcloud services list --available
プロジェクトで有効になっているAPIのリスト
$ gcloud services list --enabled
API(サービス)を有効化
$ gcloud services enable ml.googleapis.com # <- APIネーム
API(サービス)を無効化
$ gcloud services disable ml.googleapis.com # <- APIネーム
$ gcloud ai-platform ~
ローカルでトレーニング
$ gcloud ai-platform local train \
--package-path working \ # トレーニングのファイルが入ったディレクトリのパス
--module-name working.predict \ # ディレクトリ名.ファイル名(--package-pathを指定していない場合は、ターミナル上のカレントディレクトリから記述。指定した場合はターミナル上のカレントディレクトリ配下から記述。)
--job-dir local-training-output # プログラム内で利用する場合に使う。
※ モジュールファイル内に記述したsys.path[0]にモジュールファイルのディレクトリではなく、ターミナルのカレントディレクトリが入ってくる。import時にfromのパスに注意
トレーニングジョブの送信
$ gcloud ai-platform jobs submit training $JOB_NAME \
--package-path working/ \
--module-name working.predict \
--region us-central1 \
--python-version 3.5 \
--runtime-version 1.13 \
--job-dir gs://バケット名/ディレクトリ名 \
--stream-log
モデルリソース作成
$ gcloud ai-platform models create モデルリソース名 \
--regions us-central1 \
モデルリソース削除
$ gcloud ai-platform models delete モデルリソース名 \
バージョンリソース作成
$ gcloud ai-platform versions create バージョンリソース名 \
--model モデルリソース名 \
--runtime-version 1.14 \
--python-version 3.5 \
--framework xgboost \
--origin gs://バケット名/path/to/dir/ # <- model.pklなどがあるディレクトリ
ローカルで予測
$ gcloud ai-platform local predict \
--model-dir path/to/local/models/dir/ \
--json-instances path/to/local/jsondir/predict.json \ # <- 予測対象となるインプットデータ
--framework xgboost \
--signature-name model.pkl
.pycファイルでエラー吐くのでこうしておくと便利
$ rm /usr/local/Caskroom/google-cloud-sdk/latest/google-cloud-sdk/lib/googlecloudsdk/command_lib/ml_engine/*.pyc && \
gcloud ai-platform local predict \
--model-dir path/to/local/models/dir/ \
--json-instances path/to/local/jsondir/predict.json \
--framework xgboost \
--signature-name model.pkl
ai-platformで予測
$ gcloud ai-platform predict \
--model モデルリソース名 \
--version バージョンリソース名 \
--json-instances ローカルのjsonパス # <- 予測対象となるインプットデータ
$ gcloud sql ~
CloudSQL インスタンス作成
$ gcloud sql instances create anatano-instance-name \
--tier=db-f1-micro \
--region=us-central1 \
--storage-type=HDD
# 数分かかる
# Creating Cloud SQL instance...done.
# Created [https://sqladmin.googleapis.com/sql/v1beta4/projects/salck-visualization/instances/slash-cmd-api-instance].
# NAME DATABASE_VERSION LOCATION TIER PRIMARY_ADDRESS PRIVATE_ADDRESS STATUS
# anatano-instance-name MYSQL_5_7 us-central1-a db-f1-micro 34.69.9.99 - RUNNABLE
CloudSQL インスタンスの値を取得
$ gcloud sql instances describe anatano-instance-name
# backendType: SECOND_GEN
# connectionName: anatano-pj-name:us-central1:anatano-instance-name
# databaseVersion: MYSQL_5_7
# ...
# storageAutoResize: true
# storageAutoResizeLimit: '0'
# tier: db-f1-micro
# state: RUNNABLE
MySQLユーザーのパスワードを設定
$ gcloud sql users set-password root --host=% --instance [INSTANCE_NAME] --password [PASSWORD]
# gsutilコマンド [公式リファレンス](https://cloud.google.com/storage/docs/gsutil) ## $ gsutil mb ### バケット作成 ```sh $ gsutil mb -l us-central1 gs://バケット名 ``` ## $ gsutil rm ### バケット削除 ```sh $ gsutil rm -r gs://バケット名 ```
$ gsutil ls
バケット内を表示
$ gsutil ls -la gs://バケット名
$ gsutil cp
ファイルのアップロード
gcs上にディレクトリがない場合は作成される。
$ gsutil cp ローカルファイルのパス gs://バケット名/ディレクトリ名/ファイル名
-m オプションで複数ファイルをマルチスレッドで並列アップロード
$ gsutil -m cp local/path/*.csv gs://バケット名/ディレクトリ名/
ディレクトリのアップロード
$ gsutil cp -r ローカルディレクトリのパス gs://バケット名/親となるディレクトリ名/
ファイルのダウンロード
$ gsutil cp gs://バケット名/ディレクトリ名/ファイル名 ローカルファイルのパス
ディレクトリのダウンロード
$ gsutil cp -r gs://バケット名/ディレクトリ名 親となるローカルディレクトリパス/
ファイルのダウンロード
$ gsutil cp -r gs://バケット名/ディレクトリ名 親となるローカルディレクトリパス/
or
$ gsutil cp -r gs://バケット名/ディレクトリ名 ローカルファイルパス
ファイルの削除
$ gsutil rm -f gs://バケット名/ディレクトリ名/ファイル名
ディレクトリの削除
$ gsutil rm -r gs://バケット名/ディレクトリ名/
バケット内の全てのオブジェクトを一般公開
$ gsutil iam ch allUsers:objectViewer gs://バケット名
バケット内の任意のオブジェクトを一般公開
$ gsutil acl ch -u AllUsers:R gs://BUCKET_NAME/OBJECT_NAME
こんなエラー出たら
ml_engine/ 配下の.pycファイルを削除
※パスは環境により変わることがあります(下記はgoogle-cloud-sdkをbrew installしている場合)
ERROR: (gcloud.ai-platform.local.predict) RuntimeError: Bad magic number in .pyc file
↓
$ rm /usr/local/Caskroom/google-cloud-sdk/latest/google-cloud-sdk/lib/googlecloudsdk/command_lib/ml_engine/*.pyc
# bqコマンド [公式リファレンス](https://cloud.google.com/bigquery/docs/reference/bq-cli-reference?hl=ja)
$ bq mk
データセット作成
$ bq --location US mk --dataset(-d) プロジェクトID:データセットID
$ bq rm
データセット削除
$ bq rm --dataset(-d) プロジェクトID:データセットID
テーブル削除
$ bq rm --table(-t) データセットID.テーブル名
$ bq ls
データセットの確認
$ bq ls
プロジェクトの確認
$ bq ls -p
$ bq load
csv読み込み
--autodetect -> 自動でスキーマ設定
データセット名.テーブル名 -> テーブル名はファイル名と同じがよいか??
$ bq load \
--autodetect \
--source_format CSV \
データセット名.テーブル名 \
gs://バケット名/path/to/file.csv
bq query
GUIでクエリを発行する際はmaximum bytes billedを設定しておく
-> クエリが制限を超えたバイト数を読み取ると、課金されずにクエリが失敗する
※ limit句は表示を制御するだけなので費用は変わらない
BigQuery のおすすめの方法: 費用を抑える
クエリ結果からテーブル作成
デフォルト プロジェクト以外のプロジェクトにあるテーブルにクエリ結果を書き込むには、project_id:dataset.table の形式でプロジェクトIDを先頭に追記
$ bq query \
--destination_table データセット名.テーブル名 \
--use_legacy_sql=false \
'
SELECT
*
FROM
hoge
'